
So far, in this series on cloud computing for beginners, we’ve seen some of the main components, features and functionality present in cloud computing. One of them, called server, is precisely what provides the functionality of programs and devices, called “clients”. It is thanks to servers that we can access services such as sharing data and resources with other customers, for example. In this third post of the series, we will discuss the evolution of cloud computing to what is known in the market as “serverless computing”, and its direct relation with the fast product release cycle, something fundamental for disruptive businesses in the digital economy.
Before we get to the bottom of the topic, we need to understand what a client-server system is; nowadays, these systems are more often implemented by the request-response model. It works like this: a client sends a request to the server, which performs some action and then sends a response back to the client, usually with a result or confirmation.
There are also different types of servers, depending on the type of service to be performed. The most popular servers are:

The serverless solution
Taking care of a server infrastructure is expensive and laborious. As a result, cloud computing has evolved gradually and increasingly towards what we now call “serverless computing”. The term “serverless” may seem a bit confusing, since there are servers providing back-end services, however in this model what happens is that all issues involving allocation of resources and infrastructure are handled by a third-party provider.
The term serverless, in this case, means that developers can do their job without worrying about servers, keeping the focus on other essential issues, such as: scaling, flexibility and fast product release cycle. Best of all, getting the most out of resource allocations at the lowest possible cost.
Some features that define serverless computing, as well as development resources and tools, include:
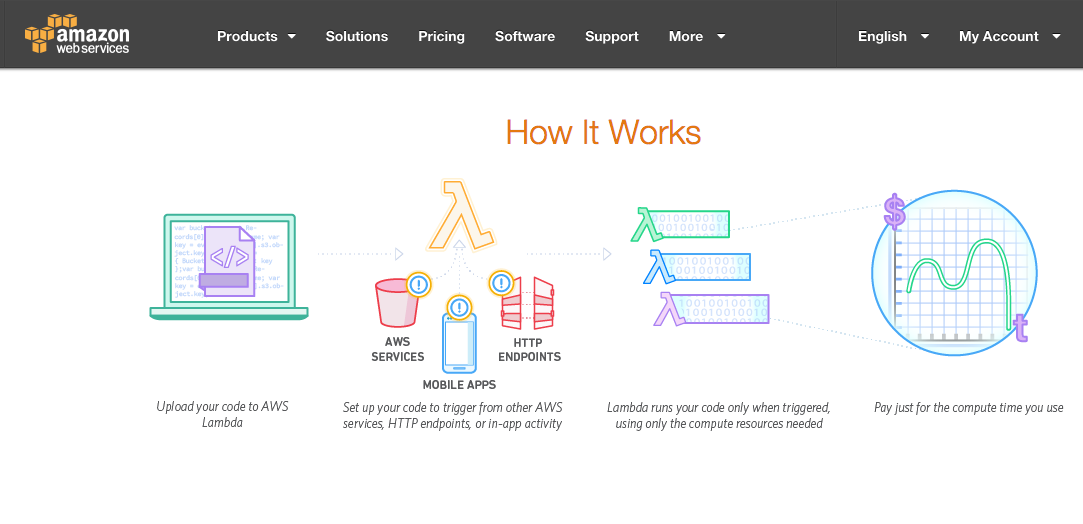
Function as a service (FaaS): AWS Lambda
In 2010, a startup called PiCloud launched the first serverless computing platform on the market, starting the Function-as-a-Service (FaaS) business model, with Python as its source programming language. In FaaS approach, there is no need to build and maintain the complex infrastructure normally associated with the development and release of a product: everything is in charge of a platform specially designated for this purpose, which allows its users to develop, execute and manage cloud resources in the most interesting way in terms of cost-benefit. The release of a product in the cloud following this approach ended up inaugurating the Containers x Microservices era, which we will address later in this post.
In November 2014, Amazon Web Services (AWS) started its FaaS offering, with the release of AWS Lambda services; since then, ads of new tools and services have become increasingly frequent in the cloud computing market. AWS Lambda, which spread rapidly among the DevOps teams, was followed by other offerings, such as Google Cloud Functions and Microsoft Azure Functions. Apache OpenWhisk was released in 2016 by IBM and Oracle Cloud Fn in 2017, both open source offerings, more secondary players in the cloud market.
However, what is AWS Lambda? It is a serverless computing service that executes code in response to events and automatically manages the underlying computing resources (at the abstraction layer) for the client. It runs the code on a highly available computing infrastructure and manages all computing resources, including server and operating system maintenance, capacity provisioning and automatic scaling, monitoring and log record. In other words, the complete package for a DevOps approach in the cloud.
The platform is deployed on top of two other more popular AWS platforms: EC2 and S3. AWS Lambda uses the user’s own setting to create a container and deploy it to an EC2 instance. The platform then executes the method that users have specified, in order of package, class and method.
Among the companies that use AWS Lambda to develop projects in the cloud are: Nubank, Trivago, Delivery Hero and Salesforce.
What is a container?
In an analogy, shipping containers in the transportation industry give us the idea what a technology container is. So, what does that mean, in practice? Containers, as a very popular one called Docker (which we will talk about later in this article) bring convenience in the development and movement between different infrastructures. This is because a container includes applications or services stored there as “packaged”, in such a way that the container orchestrator (manager) has no connection with the type of workload packaged there, because, as in the case of shipping containers, this work is done by developers at an earlier stage.
Container orchestration
Container orchestration is about managing the life cycle of containers, especially in large and dynamic computing environments. The orchestration automates the deployment, management, scaling and the network of containers, and also helps to deploy the same application in different environments without the need to redesign it; For this reason, container orchestration has become relevant for innovation in IT ecosystems, as it allows the automatic execution of massive workflows. It also works by minimizing redundancies and optimizing simplified repetition processes.
Basically, container orchestration ensures that the deployment and subsequent regular updating of the software happens faster and more accurately than in other approaches.
Development teams that practice a DevOps approach use container orchestration to manage and automate several types of tasks, such as:
- Provisioning and deployment
- Redundancy and availability
- Scaling up or removing containers to distribute the application load evenly across the host infrastructure
- Moving containers from one host to another if there is a lack of resources on a host, or if a host fails or is disabled
- Allocation of resources between containers
- Exposure of services running in a container with the outside world
- Load balancing of service discovery between containers
- Health checks of containers and hosts
- Configuration of an application in relation to the containers that run it
Main orchestrators
Kubernetes is one of the most popular container orchestration platforms at the moment, along with Amazon Web Services’ ECS, which owns it. Kubernetes is an open-source platform that enables DevOps development teams to create services for applications covering multiple containers. In addition to programming them to run in a cluster, they can also scale and manage their health checks over time, eliminating manual processes involved in deploying and scaling applications in containers. On the other hand, the ECS platform is a proprietary solution from Amazon Web Services to run and manage docker containers in the public cloud.
Docker Swarm is another well-known platform in the cloud market for container orchestration. Through the available tools, users manage several containers deployed on several host machines. One of the main benefits associated with using Docker Swarm is the high level of availability offered to applications. A fundamental difference between Kubernetes and Docker, however, is that while Kubernetes runs on a cluster, Docker runs on a single node. Therefore, Kubernetes is more extensive than Docker Swarm, capable of coordinating the scaling of cluster nodes in production efficiently.
OpenShift is a container orchestrator created by Red Hat in 2011. Initially proprietary, it became an open source project starting in May 2012. It is normally used for orchestrating containers in mixed cloud structures and on-premise applications, in SaaS format, or even installed in environments to be managed. OpenShift improves the work of DevOps teams by simplifying and automating processes such as provisioning and scaling, which are quite common in container management, leading to efficient orchestration.
In the next post, the 4th in the cloud series for beginners, we will cover the concept of microservices and their relation with the configuration and storage server.