Neste terceiro post vamos tratar da evolução da computação em nuvem para o que é conhecido no mercado como “serverless computing”, e sua relação mais que direta com o rápido ciclo de lançamento de produtos, algo fundamental para negócios disruptivos na economia digital.
Mas antes de entrarmos a fundo no tema, precisamos entender o que vem a ser um sistema cliente-servidor; hoje em dia, esses sistemas são mais frequentemente implementados pelo modelo de solicitação-resposta. Funciona assim: um cliente envia uma solicitação ao servidor, que por sua vez executa alguma ação e em seguida envia uma resposta de volta ao cliente, normalmente com um resultado ou uma confirmação.
Também existem diferentes tipos de servidores, a depender do tipo de serviço a ser executado. Os servidores mais conhecidos são:
- De banco de dados
- De arquivos
- De email
- De impressão
- De servidores web
- De servidores de jogos e
- De servidores de aplicativos

A solução “sem servidor”
Cuidar de uma infraestrutura de servidores é algo custoso e trabalhoso. Em razão disso, a computação em nuvem tem evoluído gradualmente e cada vez mais para o que hoje chamamos de “computação sem servidor” (do inglês “serverless computing”). O termo “sem servidor” pode parecer um pouco confuso, uma vez que existem servidores fornecendo serviços de back-end, porém neste modelo o que ocorre é que todas as questões envolvendo alocação de recursos e infraestrutura são tratadas por um provedor terceiro (conhecido aqui como “third-party”).
O termo “sem servidor”, no caso, significa que os desenvolvedores podem executar seu trabalho sem ter que se preocupar com servidores, mantendo o foco em outras questões essenciais, tais como: escalonamento, flexibilidade e rápido ciclo de lançamento de produtos. E o melhor de tudo isso: extrair o máximo das alocações de recursos a um custo (o mais) reduzido possível.
Algumas particularidades que definem a computação sem servidor, bem como recursos e ferramentas de desenvolvimento, incluem:
Function as a service (FaaS): AWS Lambda
Em 2010, uma startup chamada PiCloud lançou no mercado a primeira plataforma de computação sem servidor, dando início ao modelo de negócios Function-as-a-Service (FaaS), tendo o Python como linguagem de programação fonte. Na abordagem FaaS, não há a necessidade de se construir e manter a infraestrutura complexa normalmente associada ao desenvolvimento e lançamento de um produto: tudo fica a cargo de uma plataforma especialmente designada para este fim, que por sua vez permite a seus usuários desenvolver, executar e gerenciar os recursos da nuvem como for mais interessante em termos de custo-benefício. O lançamento de um produto na nuvem seguindo essa abordagem acabou por inaugurar a era Containers x Microsserviços, que abordaremos mais à frente neste post.
Em novembro de 2014 a Amazon Web Services (AWS) iniciou sua oferta FaaS, com o lançamento dos serviços AWS Lambda; desde então, anúncios de novas ferramentas e serviços passaram a se tornar cada vez mais frequentes no mercado de cloud computing. O AWS Lambda, que espalhou-se rapidamente entre as equipes DevOps, foi seguido por outras ofertas, como o Google Cloud Functions e o Microsoft Azure Functions. O OpenWhisk da Apache foi lançado em 2016 pela IBM e a Oracle Cloud Fn em 2017, ambas ofertas de código aberto, players mais secundários no mercado de cloud.
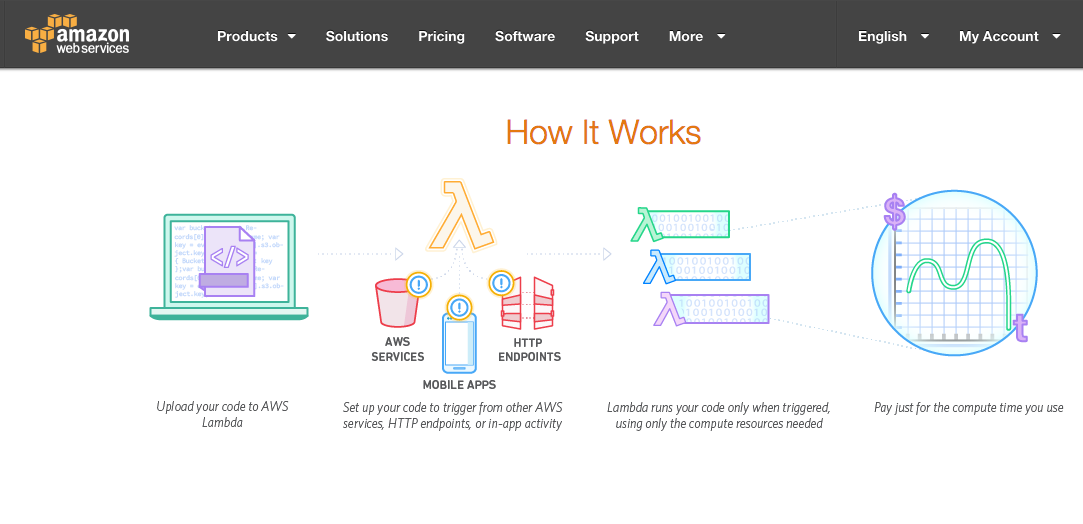
Mas, o que vem a ser o AWS Lambda? Trata-se de um serviço de computação sem servidor que executa um código em resposta a eventos e gerencia automaticamente os recursos de computação subjacentes (na camada de abstração) para o cliente. Ele executa o código em uma infraestrutura de computação de alta disponibilidade e faz toda a administração dos recursos de computação, incluindo a manutenção do servidor e do sistema operacional, provisionamento de capacidade e escalonamento automático, monitoramento e registro de log. Ou seja, o pacote completo para uma abordagem DevOps na nuvem.
A plataforma é implementada em cima de outras duas plataformas AWS mais populares: EC2 e S3. O AWS Lambda usa a configuração do próprio usuário para criar um container e implementá-lo em uma instância EC2. A plataforma então executa o método que os usuários especificaram, em ordem de pacote, classe e método.
Entre as empresas que usam o AWS Lambda para desenvolver projetos na nuvem, estão: Nubank, trivago, Delivery Hero e Salesforce.

O que é um container?
O transporte de cargas de grande volume em navios está para os containers na tecnologia. E o que isso quer dizer, na prática? Containers, como um bastante popular chamado Docker (sobre o qual falaremos mais adiante neste artigo) trazem praticidade no desenvolvimento e movimentação entre infraestruturas diversas. Isso porque um container contempla dentro dele aplicações ou serviços guardados ali como que “empacotados”, de tal forma que o orquestrador (gerenciador) de containers não possui vínculo com o tipo de carga empacotada ali dentro, pois, assim como no caso dos navios de carga, esse trabalho é feito pelos desenvolvedores em uma etapa anterior.
Orquestração de containers
A orquestração de containers trata do gerenciamento do ciclo de vida dos mesmos, especialmente em ambientes de computação grandes e dinâmicos. A orquestração automatiza a implementação, o gerenciamento, o escalonamento e a rede de containers, e de quebra ainda ajuda a implementar o mesmo aplicativo em diferentes ambientes sem a necessidade de reprojetá-lo; Por essa razão, a orquestração de containers tem se tornado relevante para a inovação em ecossistemas de TI, pois permite a execução automática de fluxos massivos de trabalho. Ela também funciona minimizando redundâncias e otimizando processos simplificados de repetição.
Basicamente, a orquestração de containers garante que a implementação e posterior atualização regular do software aconteça de forma mais rápida e precisa do que em outras abordagens.
Equipes de desenvolvimento que praticam uma abordagem DevOps usam a orquestração de containers para gerenciar e automatizar diversos tipos de tarefas, tais como:
- Provisionamento e implementação
- Redundância e disponibilidade
- Aumentar ou remover containers para distribuir a carga do aplicativo de maneira uniforme na infraestrutura do host
- Movimento de containers de um host para outro se houver falta de recursos em um host, ou se um host falhar ou for desativado
- Alocação de recursos entre containers
- Exposição de serviços executados em um container com o mundo exterior
- Balanceamento de carga do recurso service discovery entre containers
- Monitoramento de integridade (health-checks) de containers e hosts
- Configuração de um aplicativo em relação aos containers que o executam
Principais orquestradores
O Kubernetes é uma das plataformas de orquestração de containers mais populares do momento, juntamente com a ECS, da Amazon Web Services, que é proprietária. O Kubernetes é uma plataforma em código aberto que possibilita às equipes de desenvolvimento DevOps criarem serviços para aplicativos abrangendo vários containers. Além de programá-los para executar em um cluster, podem também escalonar e gerenciar suas verificações de integridade (health-checks) ao longo do tempo, eliminando processos manuais envolvidos na implementação e escalonamento de aplicativos em containers. Já a plataforma ECS é uma solução proprietária da Amazon Web Services para executar e gerenciar containers docker na nuvem pública.
Kubernetes gerenciado
Na AWS há o Amazon Elastic Kubernetes Service (EKS)
No Google há o Google Kubernetes Engine (GKE)
No Azure há o Serviço de Kubernetes do Azure (AKS)
O Docker Swarm é outra plataforma bastante conhecida no mercado de cloud para orquestração de containers. Através das ferramentas disponíveis, os usuários gerenciam vários containers implementados em várias máquinas host. Um dos principais benefícios associados ao uso do Docker Swarm é o alto nível de disponibilidade oferecido aos aplicativos. Uma diferença fundamental entre o Kubernetes e o Docker, entretanto, é que enquanto o Kubernetes é executado em um cluster, o Docker é executado em um único nó. Portanto, o Kubernetes é mais extenso do que o Docker Swarm, capaz de coordenar o escalonamento de nós de clusters em produção de maneira eficiente.
O OpenShift é um orquestrador de containers criado pela Red Hat em 2011. Inicialmente proprietário, tornou-se um projeto de código aberto a partir de maio de 2012. Ele é normalmente utilizado para a orquestração de containers em estruturas mistas de nuvem e aplicativos on-premise, no formato SaaS, ou mesmo instalado em ambientes a serem gerenciados. O OpenShift aprimora o trabalho de equipes DevOps ao simplificar e automatizar processos tais como provisionamento e dimensionamento, bastante comuns no gerenciamento de containers, levando a uma orquestração eficiente.

