Insights
Insights fornece uma visão abrangente dos dados históricos de uma organização permitindo que a liderança tome decisões informadas para aprimorar a maturidade operacional. Encontrado no menu lateral, o Insights é composto pelas seguintes abas:
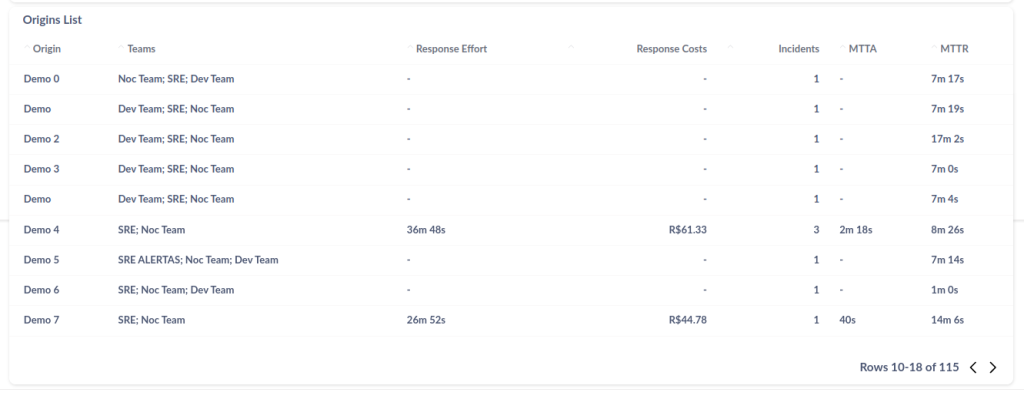
Incidents
Incidents oferece uma visualização geral do esforço de resposta ao longo do tempo de cada incidente que aconteceu em uma organização. Você pode filtrar os incidentes de acordo com intervalo de datas, severidade e origem do incidente.



- Total Incidents: o total de incidentes que a organização enfrentou em um determinado período;
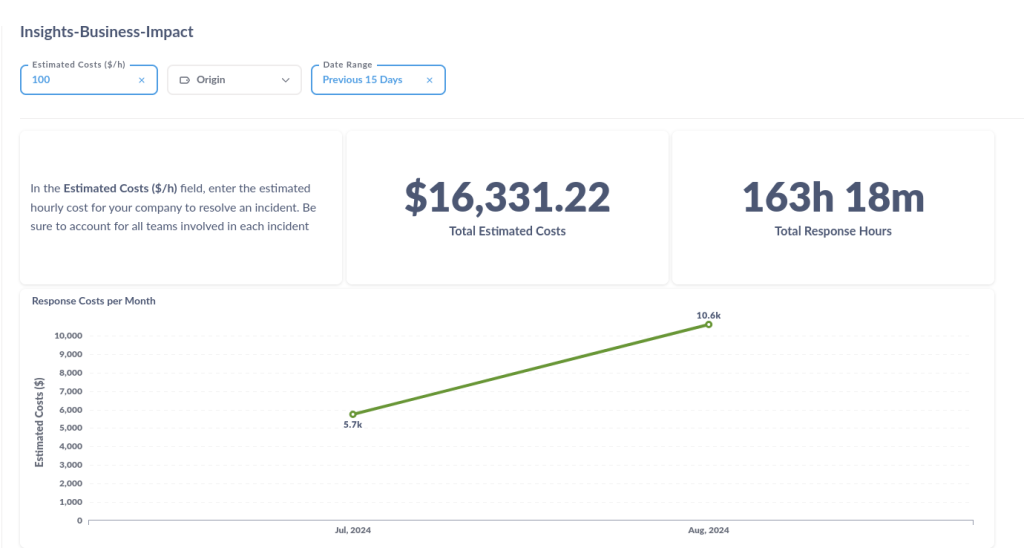
- Total Response Effort: somatório total do tempo de envolvimento em um incidente, medido a partir do acknowledge até sua resolução;
- MTTA (Mean Time to Acknowledge): média de tempo para reconhecimento de um incidente;
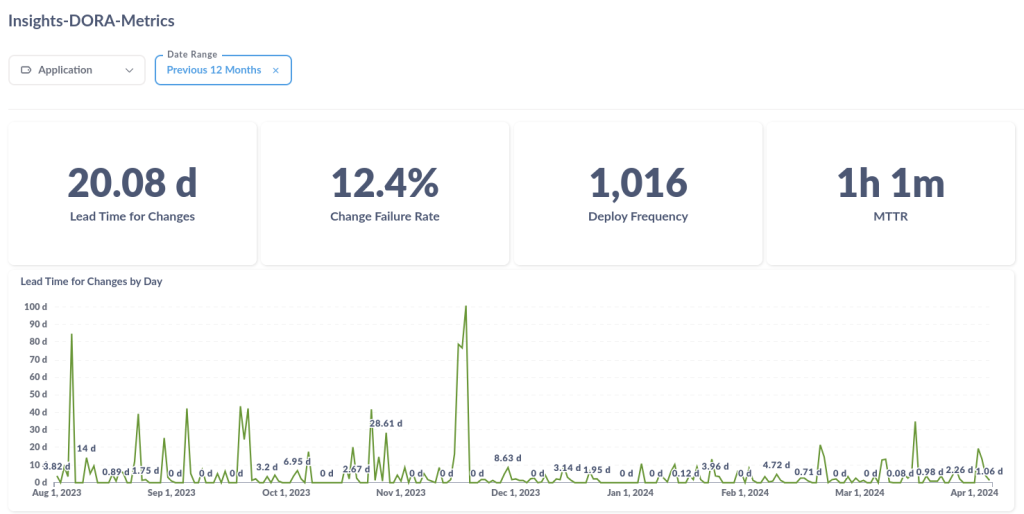
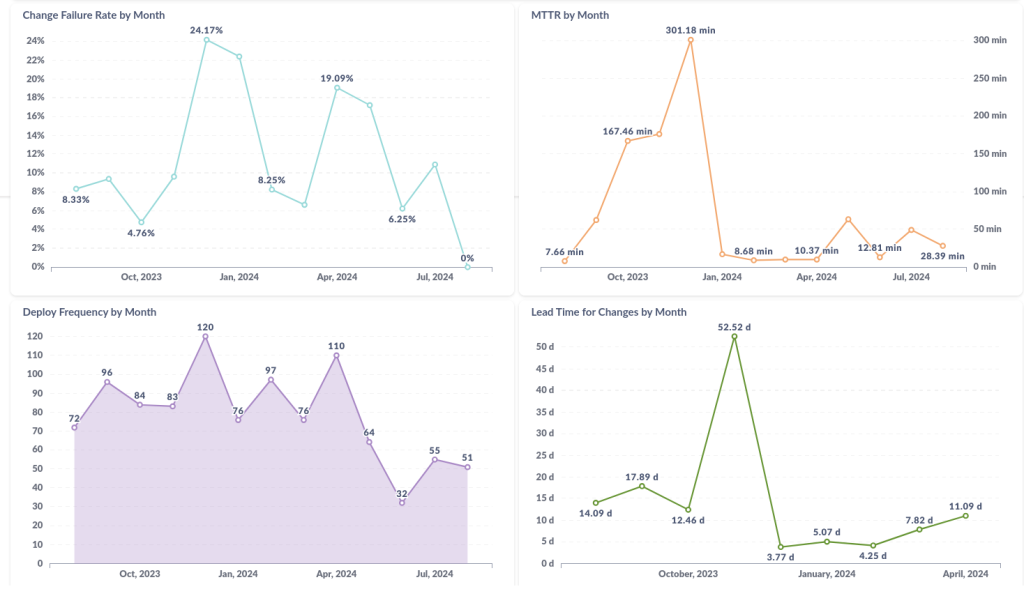
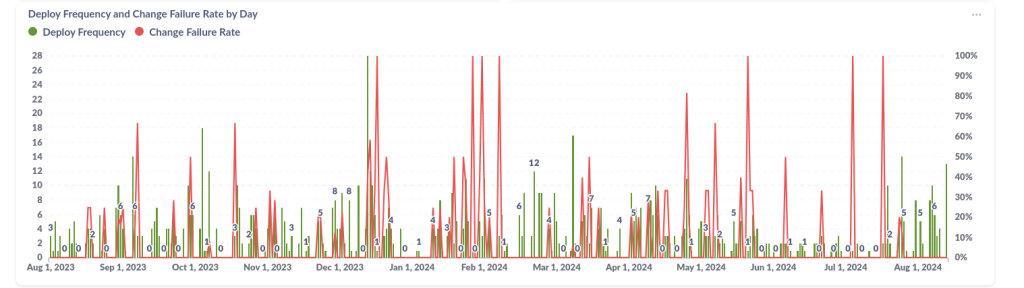
- MTTR (Mean Time to Resolve): média de tempo desde o gatilho de um incidente até a sua resolução;
- Time Cluster: grupo correspondente ao período em que o incidente ocorreu:
- Business Hour Interruptions: interrupções que ocorreram de segunda a sexta-feira, entre 8h e 18h;
- Off Hour Interruptions: interrupções que ocorreram de segunda a sexta-feira entre 18h e 22h, ou durante o final de semana entre 18h e 22h;
- Sleep Hour Interruptions: interrupções que ocorreram em de segunda-feira a domingo entre 22h e 8h.
- TTA (Time to Acknowledge): quantidade de tempo entre o gatilho do incidente até o seu reconhecimento.
- TTR (Time to Resolve): tempo desde o gatilho do incidente até a sua resolução.
Responders
O Responders fornece insights sobre o impacto dos incidentes em seus responders, além de trazer dados sobre como foi a sua resolução. Ele também inclui uma lista individual de incidentes baseado em cada responder. Você pode filtrar esse dashboard de acordo com intervalo de datas, severidade, responders, time cluster e MTTR.


- Total Incidents: o total de incidentes que a organização enfrentou em um determinado período;
- Total Response Effort: somatório total dos tempos de envolvimento dos responders com os incidentes, medido a partir do momento em que um responder dá o acknowledge até que o incidente seja resolvido;
- MTTA (Mean time to Acknowledge): média de tempo que um responder levou para o reconhecimento de um incidente;
- MTTR (Mean time to Resolve): média de tempo desde o gatilho de um incidente até o tempo sua resolução por um responder;
Monitoring Performance
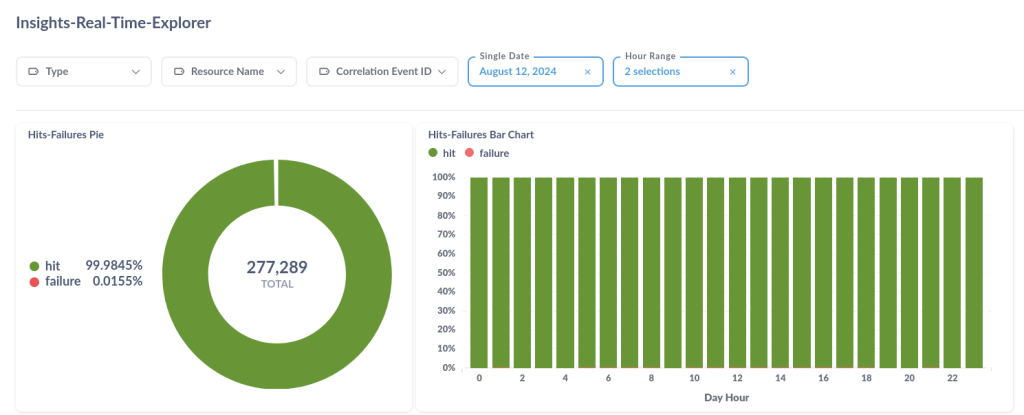
O Monitoring Performance possibilita acompanhar e entender o desempenho de monitoramentos realizados pela One Platform em tempo real. Ela oferece uma visão de dados relacionados à saúde dos produtos digitais, permitindo que os usuários identifiquem rapidamente tendências, padrões e anomalias.

-
Downtime: tempo de inatividade dos monitoramentos;
- Outages: quantas interrupções tiveram nos monitoramentos;
- Uptime: Percentual de disponibilidade do recurso monitorado;
- Maximum Response Time: tempo máximo de resposta (latência) do monitoramento;
- Minimum Response Time: tempo mínimo de resposta (latência) do monitoramento;
- Average Response Time: tempo médio de resposta (latência) do monitoramento;
- Uptime per Day: Percentual de disponibilidade do recurso monitorado em comparação aos dias;

- Latency per Hour
: tempo de inatividade dos monitoramentos;
- Top Downtime Resources: Recursos com maior tempo de inatividade, mostrando quantas horas cada recurso ficou indisponível.
- Top AVG Latencies per Resources: Latência média por recurso, mostrando o tempo médio de resposta em milissegundos (ms) para cada recurso monitorado.