Capítulo 4: Objetivos de Nível de Serviço
Escrito por Chris Jones, John Wilkes e Niall Murphy com Cody Smith
Editado por Betsy Beyer
É impossível gerenciar um serviço corretamente, muito menos bem, sem entender quais comportamentos realmente são importantes para esse serviço e como medir e avaliar esses comportamentos. Para tanto, gostaríamos de definir e entregar um determinado nível de serviço aos nossos usuários, independente do fato de usarem uma API interna ou um produto público.
Usamos intuição, experiência e a compreensão do que os usuários desejam para definir Indicadores de Nível de Serviço (SLIs), Objetivos (SLOs) e Acordos (SLAs). Essas medidas descrevem as propriedades básicas das métricas que importam, quais valores queremos que essas métricas tenham e como reagiremos se não pudermos fornecer o serviço esperado. Em última análise, a escolha de métricas adequadas ajuda a impulsionar a ação certa se algo der errado e também dá à equipe de SRE a confiança de que um serviço é saudável.
Este capítulo descreve a estrutura que usamos para lidar com os problemas de modelagem, seleção e análise métrica. Grande parte dessa explicação seria bastante abstrata sem um exemplo, então usaremos o serviço de Shakespeare descrito no capítulo 2 deste livro para ilustrar nossos pontos principais.
Terminologia de Nível de Serviço
Muitos leitores provavelmente estão familiarizados com o conceito de SLA, mas os termos SLI e SLO também merecem uma definição cuidadosa, porque, no uso comum, o termo SLA é subentendido e acabou assumindo vários significados, a depender do contexto. Preferimos separar esses significados para maior clareza a respeito do que estamos tratando neste livro.
Indicadores
Um SLI é um Indicador de Nível de Serviço – uma medida quantitativa cuidadosamente definida de algum aspecto do nível de serviço fornecido.
A maioria dos serviços considera a latência de solicitação – quanto tempo leva para retornar uma resposta a uma solicitação – como um SLI chave. Outros SLIs comuns incluem a taxa de erro, geralmente expressa como uma fração de todas as solicitações recebidas, e a taxa de transferência do sistema, normalmente medida em solicitações por segundo. As medições são frequentemente agregadas: ou seja, os dados brutos são coletados em uma janela de medição e, em seguida, transformados em uma taxa, média ou percentil.
Idealmente, o SLI mede diretamente um nível de interesse de serviço, mas às vezes apenas um proxy está disponível porque a medida desejada pode ser difícil de obter ou interpretar. Por exemplo, a latência do lado do cliente costuma ser a métrica mais relevante para o usuário, mas só é possível medir a latência no servidor.
Outro tipo de SLI importante para os SREs é a disponibilidade, ou a fração do tempo de uso de um serviço. Geralmente, é definido em termos da fração de solicitações bem formadas que são bem-sucedidas, às vezes chamada de rendimento. (Durabilidade – a probabilidade de que os dados sejam retidos por um longo período de tempo – é igualmente importante para sistemas de armazenamento de dados). Embora 100% de disponibilidade seja impossível, quase 100% de disponibilidade muitas vezes é facilmente alcançável, e a indústria comumente expressa valores de alta disponibilidade em termos do número de “noves” na porcentagem de disponibilidade. Por exemplo, disponibilidades de 99% e 99,999% podem ser referidas como disponibilidade de “2 noves” e “5 noves”, respectivamente, sendo que a meta atual para a disponibilidade do Google Compute Engine é “três e meio noves”, qual seja, 99,95% de disponibilidade.
Objetivos
Um SLO é um Objetivo de Nível de Serviço: um valor alvo ou intervalo de valores para um nível de serviço medido por um SLI. Uma estrutura natural para SLOs é, portanto, SLI ≤ alvo, ou limite inferior ≤ SLI ≤ limite superior. Por exemplo, podemos decidir que retornaremos os resultados da pesquisa de Shakespeare “rapidamente”, adotando um SLO de que nossa latência média de solicitação de pesquisa deve ser inferior a 100 milissegundos.
A escolha de um SLO apropriado é complexa. Para começar, nem sempre você pode escolher seu valor! Para solicitações HTTP de entrada do mundo externo para o seu serviço, a métrica de consultas por segundo (QPS) é essencialmente determinada pelos desejos de seus usuários, e você não pode definir um SLO para isso.
Por outro lado, você pode dizer que deseja que a latência média por solicitação seja inferior a 100 milissegundos, e definir essa meta poderia, por sua vez, motivá-lo a escrever seu frontend com comportamentos de baixa latência de vários tipos ou a comprar certos tipos de equipamento de baixa latência. (100 milissegundos obviamente é um valor arbitrário, mas em geral os números de latência mais baixos são bons. Há excelentes razões para acreditar que rápido é melhor do que lento, e que a latência experimentada pelo usuário acima de certos valores realmente afasta as pessoas.
Novamente, isso é mais sutil do que pode parecer à primeira vista, em que esses dois SLIs – QPS e latência – podem estar conectados nos bastidores: QPS mais alto geralmente leva a latências maiores, e é comum que os serviços tenham um declínio de desempenho além de alguns limites de carga.
A escolha e a publicação de SLOs para os usuários define as expectativas sobre o desempenho de um serviço. Essa estratégia pode reduzir reclamações infundadas aos proprietários do serviço sobre, por exemplo, a lentidão do serviço. Sem um SLO explícito, os usuários geralmente desenvolvem suas próprias crenças sobre o desempenho desejado, o que pode não estar relacionado às crenças das pessoas que projetam e operam o serviço. Essa dinâmica pode levar tanto ao excesso de confiança no serviço, quando os usuários acreditam incorretamente que um serviço estará mais disponível do que realmente está (como aconteceu com o Chubby), quanto à falta de confiança, quando os usuários em potencial acreditam que um sistema é mais instável e menos confiável do que realmente é.
A interrupção global planejada do Chubby
Escrito por Marc Alvidrez
Chubby é o serviço de bloqueio do Google para sistemas distribuídos fracamente acoplados. No caso global, distribuímos instâncias do Chubby de forma que cada replica esteja em uma região geográfica diferente. Com o tempo, descobrimos que as falhas da instância global do Chubby geravam interrupções de serviço consistentemente, muitas das quais eram visíveis aos usuários finais. Acontece que as verdadeiras interrupções globais do Chubby são tão raras que os proprietários de serviço começaram a adicionar dependências ao Chubby, presumindo que ele nunca seria desativado. Sua alta confiabilidade fornecia uma falsa sensação de segurança porque os serviços não funcionavam adequadamente quando o Chubby não estava disponível, embora isso raramente ocorresse.
A solução para esse cenário do Chubby é interessante: o SRE garante que o Chubby global atenda, mas não exceda significativamente, seu Objetivo de Nível de Serviço. Em qualquer trimestre, se uma falha verdadeira não tiver reduzido a disponibilidade abaixo da meta, uma interrupção controlada será sintetizada ao desligar intencionalmente o sistema. Dessa forma, podemos eliminar dependências sem sentido no Chubby logo após serem adicionadas. Fazer isso força os proprietários de serviços a reconhecer a realidade dos sistemas distribuídos mais cedo ou mais tarde.
Acordos de Nível de Serviço
Por fim, os SLAs são Acordos de Nível de Serviço: um contrato explícito ou implícito com seus usuários que inclui as consequências de atender (ou não cumprir) os SLOs que eles contêm. As consequências são mais facilmente reconhecidas quando são financeiras – um desconto ou uma penalidade – mas podem assumir outras formas. Uma maneira fácil de saber a diferença entre um SLO e um SLA é perguntar “o que acontece se os SLOs não forem atendidos?”: se não houver uma consequência explícita, é quase certo que você está olhando para um SLO. (A maioria das pessoas realmente querem dizer SLO quando dizem “SLA”. Uma dica: se alguém fala sobre uma “violação de SLA”, quase sempre está se referindo a um SLO perdido. Uma violação real do SLA pode desencadear um processo judicial por quebra de contrato).
SRE normalmente não tem envolvimento na construção de SLAs, porque os SLAs estão intimamente ligados às decisões de negócios e produtos. O SRE, no entanto, ajuda a evitar o desencadeamento das consequências de SLOs perdidos. Eles também podem ajudar a definir os SLIs: obviamente, é necessário haver uma forma objetiva de medir os SLOs no acordo, ou discordâncias irão surgir.
A Pesquisa Google é um exemplo de um serviço importante que não tem um SLA para o público: queremos que todos usem a Pesquisa da forma mais fluida e eficiente possível, mas não assinamos um contrato com o mundo todo. Mesmo assim, ainda existem consequências se a Pesquisa não estiver disponível – a indisponibilidade resulta em um impacto em nossa reputação, bem como em uma queda na receita de publicidade. Muitos outros serviços do Google, como o Google for Work, têm SLAs explícitos com seus usuários. Quer um determinado serviço tenha ou não um SLA, é importante definir SLIs e SLOs e usá-los para gerenciar o serviço.
Tanto para a teoria como para a experiência.
Indicadores na prática
Considerando que explicamos por que a escolha de métricas adequadas para medir um serviço é importante, como você deve identificar quais métricas são significativas para seu serviço ou sistema?
Com o quê você e seus usuários se importam?
Você não deve usar todas as métricas que pode rastrear em seu sistema de monitoramento como um SLI; uma compreensão do que seus usuários desejam do sistema informará a seleção criteriosa de alguns indicadores. A escolha de muitos indicadores torna difícil prestar o nível certo de atenção aos indicadores que importam, enquanto a escolha de poucos pode deixar comportamentos significativos do seu sistema sem o devido exame. Normalmente descobrimos que um punhado de indicadores representativos são suficientes para avaliar e razoabilizar sobre a saúde de um sistema.
Os serviços tendem a se enquadrar em algumas categorias amplas em termos dos SLIs que consideram relevantes:
- Sistemas de exibição voltados para o usuário, como os frontends de pesquisa de Shakespeare, geralmente se preocupam com a disponibilidade, latência e taxa de transferência. Em outras palavras: podemos responder à solicitação? Quanto tempo demorou para responder? Quantas solicitações podem ser tratadas?
- Os sistemas de armazenamento geralmente enfatizam latência, disponibilidade e durabilidade. Em outras palavras: quanto tempo leva para ler ou gravar dados? Podemos acessar os dados sob demanda? Os dados ainda estão lá quando precisamos deles? Acesse Data Integrity: What You Read Is What You Wrote (capítulo 26) para ler um debate extenso sobre esses problemas.
- Sistemas de Big Data, como pipelines de processamento de dados, tendem a se preocupar com a taxa de transferência e a latência de ponta a ponta. Em outras palavras: quantos dados estão sendo processados? Quanto tempo leva para os dados progredirem da ingestão até a conclusão? (Alguns pipelines também podem ter metas de latência em estágios de processamento individuais).
- Todos os sistemas devem se preocupar com a correção: a resposta certa foi retornada, os dados certos foram recuperados, a análise certa foi feita? A exatidão é importante rastrear como um indicador de integridade do sistema, embora muitas vezes seja uma propriedade dos dados no sistema em vez da infraestrutura em si e, portanto, geralmente não é uma responsabilidade atendida pelo SRE.
Coletando Indicadores
Muitas métricas do indicador são coletadas mais naturalmente no lado do servidor, usando um sistema de monitoramento como o Borgmon (veja capítulo 10 “Practical Alerting from Time-Series Data”) ou Prometheus, ou com análise periódica de log – por exemplo, respostas HTTP 500 como uma fração de todas as solicitações . No entanto, alguns sistemas devem ser instrumentados com coleta do lado do cliente, porque não medir o comportamento no cliente pode fazer com que se perca uma série de problemas que afetam os usuários, mas que não afetam as métricas do lado do servidor. Por exemplo, concentrar-se na latência de resposta do backend de pesquisa de Shakespeare pode fazer com que se perca a baixa latência do usuário devido a problemas com o JavaScript da página. Neste caso, medir quanto tempo leva para uma página se tornar utilizável no navegador é um indicador melhor para o que o usuário realmente experimenta.
Agregação
Para simplicidade e usabilidade, geralmente agregamos medidas brutas. Isso precisa ser feito com cuidado.
Algumas métricas são aparentemente simples, como o número de solicitações por segundo atendidas, mas mesmo essa medida aparentemente simples agrega dados implicitamente na janela de medição. A medição é obtida uma vez por segundo ou pela média das solicitações de um minuto? O último pode ocultar taxas de solicitação instantânea muito mais altas em picos que duram apenas alguns segundos. Considere um sistema que atende 200 solicitações em segundos pares e 0 nos demais. Ele tem a mesma carga média de um que atende a constantes 100 solicitações/s, mas tem uma carga instantânea duas vezes maior que a média. Da mesma forma, calcular a média das latências de solicitação pode parecer atraente, mas obscurece um detalhe importante: é inteiramente possível que a maioria das solicitações seja rápida, mas que uma longa cauda de solicitações seja muito, muito mais lenta.
A maioria das métricas é melhor concebida como distribuições do que como médias. Por exemplo, para um SLI de latência, algumas solicitações serão atendidas rapidamente, enquanto outras, invariavelmente, levarão mais tempo – às vezes, muito mais. Uma média simples pode obscurecer essas latências de cauda, bem como suas alterações. A figura abaixo fornece um exemplo: embora uma solicitação típica seja atendida em cerca de 50 ms, 5% das solicitações são 20 vezes mais lentas! Monitorar e alertar com base apenas na latência média não mostraria nenhuma alteração de comportamento ao longo do dia, quando na verdade há mudanças significativas acontecendo na latência da cauda (linha superior).
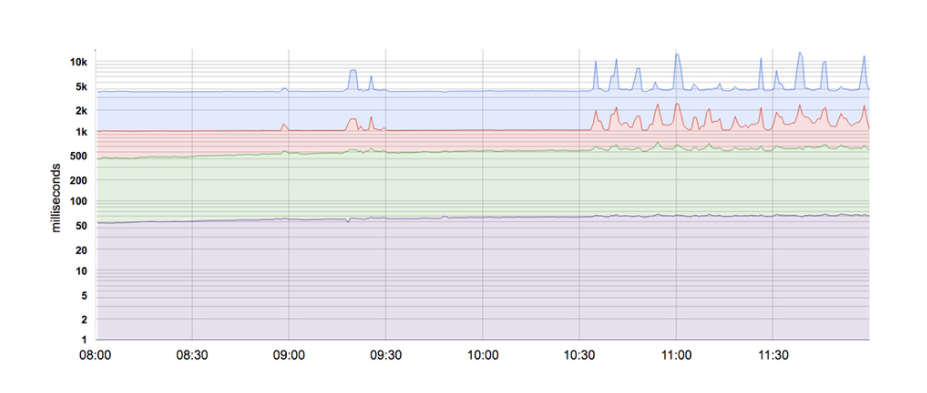
Usar percentis para indicadores permite considerar a forma da distribuição e seus atributos diferentes: um percentil de alta ordem, como o 99º ou 99,9º, mostra um valor plausível de pior caso, enquanto usar o 50º percentil (também conhecido como a mediana) enfatiza o caso típico. Quanto maior a variação nos tempos de resposta, mais a experiência típica do usuário é afetada pelo comportamento de cauda longa, um efeito exacerbado em alta carga por efeitos de enfileiramento. Estudos de usuários mostraram que as pessoas geralmente preferem um sistema ligeiramente mais lento a um com alta variação no tempo de resposta, então algumas equipes de SRE se concentram apenas em valores de percentil alto, com base no fato de que se o comportamento do percentil 99,9 é bom, então a experiência típica certamente também vai ser.
Uma nota sobre falácias estatísticas
Geralmente preferimos trabalhar com percentis em vez da média aritmética de um conjunto de valores. Isso torna possível considerar a longa cauda de pontos de dados, que geralmente têm características significativamente diferentes (e mais interessantes) do que a média. Devido à natureza artificial dos sistemas de computação, os pontos de dados costumam ser distorcidos – por exemplo, nenhuma solicitação pode ter uma resposta em menos de 0 ms, e um tempo limite de 1.000 ms significa que não pode haver respostas bem-sucedidas com valores maiores que o tempo limite. Como resultado, não podemos supor que a média e a mediana sejam iguais – ou mesmo próximas uma da outra!
Tentamos não assumir que nossos dados sejam normalmente distribuídos sem verificá-los primeiro, caso algumas intuições e aproximações padrão não sejam válidas. Por exemplo, se a distribuição não for a esperada, um processo que entra em ação quando encontra outliers (por exemplo, reiniciar um servidor com latências de solicitação altas) pode fazer isso com muita frequência ou não fazer o suficiente.
Padronizar indicadores
Recomendamos padronizar as definições comuns para SLIs para que não seja necessário raciocinar sobre os princípios delas todas as vezes. Qualquer feature que esteja em conformidade com os modelos de definição padrão pode ser omitida da especificação de um SLI individual, como por exemplo:
- Intervalos de agregação: “Média de 1 minuto”
- Regiões de agregação: “Todas as tarefas em um cluster”
- Com que frequência as medições são feitas: “A cada 10 segundos”
- Quais solicitações estão incluídas: “HTTP GETs de trabalhos de monitoramento black-box”
- Como os dados são adquiridos: “Através do nosso monitoramento, medido no servidor”
- Latência de acesso a dados: “Tempo até o último byte”
Para economizar esforços, crie um conjunto de modelos SLI reutilizáveis para cada métrica comum; isso também torna mais fácil para todos entenderem o que significa um SLI específico.
Objetivos em prática
Comece pensando (ou descobrindo!) o que interessa mais aos seus usuários, e não o que você pode medir. Muitas vezes, é difícil ou impossível medir os interesses dos usuários, então você acabará aproximando as necessidades dos usuários de alguma forma. No entanto, se você simplesmente começar com o que é fácil de medir, acabará com SLOs menos úteis. Como resultado, às vezes descobrimos que trabalhar a partir dos objetivos desejados de trás para frente para indicadores específicos funciona melhor do que escolher indicadores e, em seguida, chegar a metas.
Definindo Objetivos
Para maior clareza, os SLOs devem especificar como são medidos e as condições em que os objetivos são válidos. Por exemplo, podemos dizer o seguinte (a segunda linha é igual à primeira, mas depende dos padrões SLI da seção anterior para remover a redundância):
- 99% (em média 1 minuto) das chamadas Get RPC serão concluídas em menos de 100 ms (medido em todos os servidores de backend);
- 99% das chamadas Get RPC serão concluídas em menos de 100 ms.
Se a forma das curvas de desempenho for importante, você pode especificar várias metas SLO:
- 90% das chamadas Get RPC serão concluídas em menos de 1 ms;
- 99% das chamadas Get RPC serão concluídas em menos de 10 ms;
- 99,9% das chamadas Get RPC serão concluídas em menos de 100 ms.
Se você tiver usuários com cargas de trabalho heterogêneas, como um pipeline de processamento em massa que se preocupa com a taxa de transferência e um cliente interativo que se preocupa com a latência, pode ser apropriado definir objetivos separados para cada classe de carga de trabalho:
- 95% das chamadas de taxa de transferência Set RPC dos clientes serão concluídas em <1 s;
- 99% das chamadas de latência Set RPC dos clientes com payloads <1 kB serão concluídas em <10 ms.
É irreal e indesejável insistir que os SLOs serão atendidos 100% das vezes: fazer isso pode reduzir a taxa de inovação e implantação, exigir soluções caras e excessivamente conservadoras, ou ambos. Em vez disso, é melhor permitir um error budget – uma taxa na qual os SLOs podem ser perdidos – e rastreá-los diariamente ou semanalmente. A alta gerência provavelmente também desejará uma avaliação mensal ou trimestral. (Um error budget é apenas um SLO para atender a outros SLOs!)
A taxa de violação de SLO pode ser comparada ao error budget (veja Motivação para orçamentos de erro, disponível no Capítulo 3), com o intervalo usado como um input para o processo que decide quando lançar novos releases.
Escolha de metas
A escolha de metas (SLOs) não é uma atividade puramente técnica por conta das implicações de produto e negócios, que devem ser refletidas nos SLIs e SLOs (e talvez SLAs) que são selecionados. Da mesma forma, pode ser necessário trocar certos atributos de produto por outros dentro das restrições impostas por equipe, tempo de colocação no mercado, disponibilidade de hardware e financiamento. Embora o SRE deva fazer parte desta conversa e aconselhar sobre os riscos e a viabilidade de diferentes opções, aprendemos algumas lições que podem ajudar a tornar essa discussão mais produtiva:
Não escolha uma meta com base no desempenho atual
Embora compreender os méritos e limites de um sistema seja essencial, adotar valores sem fazer uma reflexão antes pode prender o usuário a apoiar um sistema que requer esforços “heroicos” para cumprir suas metas e que não pode ser melhorado sem um redesenho significativo.
Mantenha as coisas simples
Agregações complicadas em SLIs podem obscurecer as alterações no desempenho do sistema e também são mais difíceis de aplicar.
Evite absolutos
Embora seja tentador pedir a um sistema que escale sua carga “infinitamente” sem qualquer aumento de latência e que esteja “sempre” disponível, esse requisito não é realista. Mesmo um sistema que se aproxime de tais ideais provavelmente levará muito tempo para projetar e construir e será caro para operar – provavelmente também se revelará desnecessariamente “melhor” do que aquilo que os usuários ficariam felizes (ou até mesmo encantados) em obter.
Tenha o mínimo de SLOs possível
Escolha SLOs suficientes para fornecer uma boa cobertura dos atributos do seu sistema. Defenda os SLOs que escolher: se você nunca conseguir vencer uma conversa sobre prioridades citando um SLO específico, provavelmente não vale a pena ter esse SLO. (Se você não consegue vencer uma conversa sobre SLOs, provavelmente não vale a pena ter uma equipe de SRE para o Produto). No entanto, nem todos os atributos do produto são passíveis de SLOs: é difícil especificar “satisfação do usuário” com um SLO.
A perfeição pode esperar
Você sempre pode refinar as definições e metas de SLO ao longo do tempo, conforme aprende sobre o comportamento de um sistema. É melhor começar com um alvo solto que você aperta no decorrer do tempo, do que escolher um alvo excessivamente rígido que deve ser relaxado quando você descobrir que é inatingível.
Os SLOs podem – e devem – ser o principal motivador na priorização do trabalho para SREs e desenvolvedores de produtos, porque refletem o que é importante para os usuários. Um bom SLO é uma função de força útil e legítima para uma equipe de desenvolvimento. Mas um SLO mal pensado pode resultar em trabalho perdido se uma equipe usar esforços heroicos para atender a um SLO excessivamente agressivo, ou um produto ruim se o SLO for muito flexível. Os SLOs são uma grande alavanca: use-os com sabedoria.
Medidas de controle
SLIs e SLOs são elementos cruciais nos loops de controle usados para gerenciar sistemas:
- Monitore e faça a medição dos SLIs do sistema
- Compare os SLIs com os SLOs e decida se uma ação é necessária ou não
- Se houver necessidade de ação, descubra o que precisa acontecer para atingir a meta
- Faça essa ação
Por exemplo, se a etapa 2 mostra que a latência da solicitação está aumentando e perderá o SLO em algumas horas, a menos que algo seja feito, a etapa 3 pode incluir o teste da hipótese de que os servidores estão vinculados à CPU e a decisão de adicionar mais deles ao espalhar a carga. Sem o SLO, você não saberia se (ou quando) agir.
SLOs definem expectativas
Publicar SLOs define expectativas para o comportamento do sistema. Os usuários (e usuários potenciais) geralmente desejam saber o que podem esperar de um serviço para entender se ele é apropriado para seu caso de uso. Por exemplo, uma equipe que deseja criar um site de compartilhamento de fotos pode querer evitar o uso de um serviço que promete maior durabilidade a baixo custo em troca de uma disponibilidade ligeiramente inferior, embora o mesmo serviço possa ser um ajuste perfeito para um sistema de gerenciamento de registros de arquivo.
Para definir expectativas realistas para seus usuários, você pode considerar o uso de uma ou das duas táticas a seguir:
Mantenha uma margem de segurança
Usar um SLO interno mais restrito do que o anunciado aos usuários oferece espaço para responder a problemas crônicos antes que eles se tornem visíveis externamente. Um buffer SLO também possibilita acomodar reimplementações que trocam o desempenho por outros atributos, como custo ou facilidade de manutenção, sem ter que decepcionar os usuários.
Não se exceda
Os usuários baseiam-se na realidade do que você oferece, em vez do que você diz que fornecerá, especialmente para serviços de infraestrutura. Se o desempenho real do seu serviço for muito melhor do que o SLO declarado, os usuários passarão a confiar em seu desempenho atual. Você pode evitar a dependência excessiva colocando o sistema offline ocasionalmente (o serviço Chubby do Google introduziu interrupções planejadas em resposta à disponibilidade excessiva), restringindo algumas solicitações ou projetando o sistema para que não seja mais rápido sob cargas leves. (A injeção de falha serve a um propósito diferente, mas também pode ajudar a definir as expectativas).
Entender se um sistema está atendendo bem às suas expectativas ajuda a decidir se deve investir para torná-lo mais rápido, mais disponível e mais resiliente. Como alternativa, se o serviço está indo bem, talvez o tempo da equipe deva ser gasto em outras prioridades, como pagar dívidas técnicas, adicionar novas features ou introduzir outros produtos.
Acordos na prática
Elaborar um SLA exige que as equipes jurídica e de negócios escolham as consequências e penalidades apropriadas para uma violação. A função do SRE é ajudá-los a compreender a probabilidade e a dificuldade de cumprir os SLOs contidos no SLA. Muitos dos conselhos sobre a construção de SLO também se aplicam aos SLAs. É aconselhável ser conservador no que se anuncia aos usuários, pois quanto mais amplo for o eleitorado, mais difícil será alterar ou excluir SLAs que se revelem imprudentes ou difíceis de trabalhar.
Fonte: Google SRE Book.