Capítulo 12 – Solução eficaz de problemas
Escrito por Chris Jones
“Esteja avisado que ser um especialista é mais do que entender como um sistema deve funcionar. A experiência é obtida investigando por que um sistema não funciona.”
“As maneiras pelas quais as coisas dão certo são casos especiais de como as coisas dão errado.”
A resolução de problemas é uma habilidade crítica para qualquer pessoa que opera sistemas de computação distribuídos – especialmente SREs – mas muitas vezes é vista como uma habilidade inata que algumas pessoas têm e outras não. Uma razão para essa suposição é que, para aqueles que solucionam problemas com frequência, é um processo arraigado; explicar como solucionar problemas é difícil, assim como explicar como andar de bicicleta. No entanto, acreditamos que a solução de problemas pode ao mesmo tempo ser aprendida e ensinada.
Os novatos costumam passar por tropeços ao solucionar problemas porque o exercício depende idealmente de dois fatores: uma compreensão de como solucionar problemas genericamente (ou seja, sem qualquer conhecimento do sistema em particular) e um conhecimento sólido do sistema. Embora você possa investigar um problema usando apenas o processo genérico e a derivação dos primeiros princípios, geralmente achamos essa abordagem menos eficiente e menos eficaz do que entender como as coisas devem funcionar. (Na verdade, usar apenas os primeiros princípios e habilidades de solução de problemas é muitas vezes uma maneira eficaz de aprender como um sistema funciona). O conhecimento do sistema normalmente limita a eficácia de um SRE novo para um sistema; há pouco substituto para aprender como o sistema é projetado e construído.
Vejamos um modelo geral do processo de solução de problemas. Leitores com experiência em solução de problemas podem questionar nossas definições e processos; se o seu método for eficaz para você, não há razão para não segui-lo.
Teoria
Formalmente, podemos pensar no processo de solução de problemas como uma aplicação do método hipotético-dedutivo: dado um conjunto de observações sobre um sistema e uma base teórica para compreender o comportamento de um sistema, hipotetizamos iterativamente as causas potenciais para a falha e tentamos testar essas hipóteses.
Em um modelo idealizado como o da Figura 12-1, começaríamos com um relatório de problema informando que algo está errado com o sistema. Então, podemos olhar para a telemetria do sistema – por exemplo, variáveis exportadas conforme descrito no Capítulo 10 – e os logs para entender seu estado atual. Essas informações, combinadas com nosso conhecimento de como o sistema é construído, como deve operar e seus modos de falha, nos permitem identificar algumas causas possíveis.
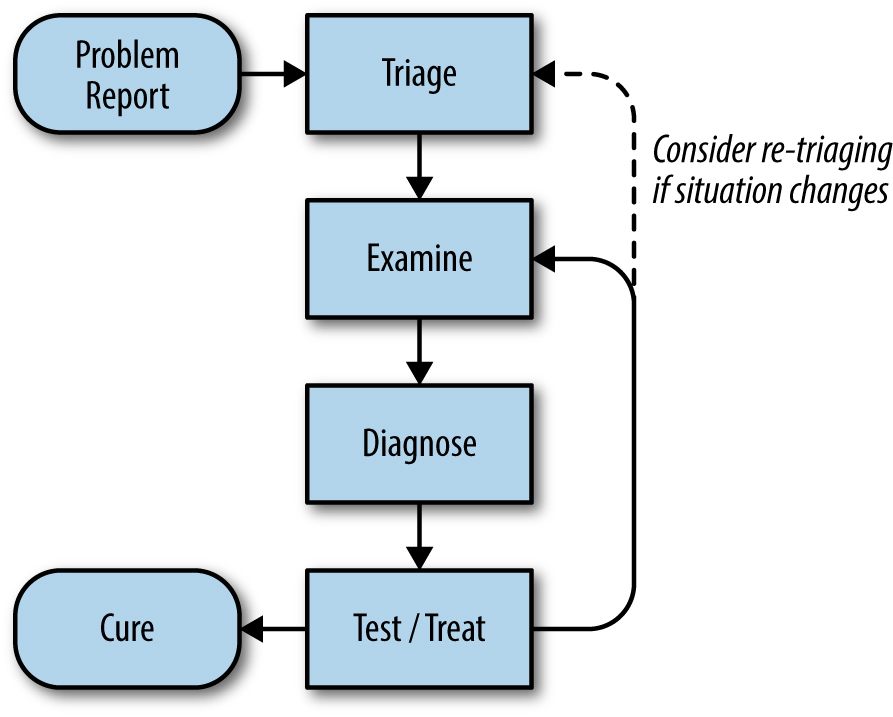
Podemos então testar nossas hipóteses de duas maneiras. Podemos comparar o estado observado do sistema com nossas teorias para encontrar evidências que se confirmam ou não. Ou, em alguns casos, podemos “tratar” ativamente o sistema – ou seja, alterá-lo de forma controlada – e observar os resultados. Esta segunda abordagem refina nossa compreensão do estado do sistema e das possíveis causas dos problemas relatados. Usando qualquer uma dessas estratégias, testamos repetidamente até que uma causa raiz seja identificada, momento em que podemos então tomar uma ação corretiva para evitar uma recorrência e escrever um postmortem. Claro, consertar a(s) causa(s) próxima(s) nem sempre precisa aguardar pela escrita da causa raiz ou postmortem.
Armadilhas Comuns
Sessões de solução de problemas ineficazes são afetadas por problemas nas etapas de Triagem, Exame e Diagnóstico, geralmente devido à falta de compreensão profunda do sistema. A seguir estão as armadilhas comuns a serem evitadas:
- Observar sintomas que não são relevantes ou compreender mal o significado das métricas do sistema. Frequentemente resultam em uma busca tola e sem esperança de algo inatingível
- Não entender como mudar o sistema, suas entradas ou seu ambiente, de modo a testar hipóteses de forma segura e eficaz
- Chegar a teorias extremamente improváveis sobre o que está errado, ou agarrar-se às causas de problemas anteriores, raciocinando que, uma vez que aconteceu uma vez, deve estar acontecendo novamente
- Procurar correlações espúrias que na verdade são coincidências ou estão relacionadas com causas comuns
Consertar a primeira e a segunda armadilhas comuns é uma questão de aprender o sistema e adquirir experiência com os padrões comuns usados em sistemas distribuídos. A terceira armadilha é um conjunto de falácias lógicas que podem ser evitadas, lembrando que nem todas as falhas são igualmente prováveis – como é ensinado a médicos: “quando você ouvir cascos, pense em cavalos, não em zebras“. (afirmação atribuída a Theodore Woodward, da University of Maryland School of Medicine, na década de 1940). Isso funciona em alguns domínios, mas em alguns sistemas, classes inteiras de falhas podem ser eliminadas: por exemplo, usar um sistema de arquivos de cluster bem projetado significa que é improvável que um problema de latência seja devido a um único disco morto. Lembre-se também de que, todas as coisas sendo iguais, devemos preferir explicações mais simples. (Conhecido como “Navalha de Occam” ou “princípio da economia”. Mas lembre-se ainda de que pode haver vários problemas; em particular, pode ser mais provável que um sistema tenha vários problemas comuns de baixo grau que, tomados em conjunto, explicam todos os sintomas, em vez de um único problema raro que causa todos eles. Uma referência a Hickam’s dictum).
Finalmente, devemos lembrar que correlação não é causa: alguns eventos correlacionados, como perda de pacotes dentro de um cluster e discos rígidos com falha no cluster, compartilham causas comuns – neste caso, uma queda de energia, embora a falha de rede claramente não cause as falhas do disco rígido nem vice-versa. Pior ainda, à medida que os sistemas crescem em tamanho e complexidade e mais métricas são monitoradas, é inevitável que haja eventos que se correlacionam bem com outros eventos, puramente por coincidência.
Compreender as falhas em nosso processo de raciocínio é o primeiro passo para evitá-las e nos tornar mais eficazes na solução de problemas. Uma abordagem metódica para saber o que sabemos, o que não sabemos e o que precisamos saber torna mais simples e direto descobrir o que está errado e como consertar.
Na prática
Na prática, é claro, a solução de problemas nunca é tão limpa quanto nosso modelo idealizado sugere que deva ser. Existem algumas etapas que podem tornar o processo menos doloroso e mais produtivo para aqueles que estão enfrentando problemas no sistema e para aqueles que estão respondendo a eles.
Relatório de Problema
Todo problema começa com um relatório de problema, que pode ser um alerta automático ou um de seus colegas dizendo: “O sistema está lento”. Um relatório eficaz deve informar o comportamento esperado, o comportamento atual e, se possível, como reproduzi-lo. (Pode ser útil encaminhar relatórios de possíveis bugs no intuito de ajudar a fornecer relatórios de problemas de alta qualidade). O ideal é que os relatórios tenham um formato consistente e sejam armazenados em um local pesquisável, como um sistema de rastreamento de bugs. Aqui, nossas equipes costumam ter formulários personalizados ou pequenos aplicativos web que solicitam informações relevantes para diagnosticar os sistemas específicos aos quais oferecem suporte, que então geram e encaminham automaticamente um bug. Esse também pode ser um bom ponto para fornecer ferramentas para aqueles que reportam problemas tentem fazer o autodiagnóstico ou reparar problemas comuns por conta própria.
É prática comum no Google abrir um bug para cada problema, mesmo aqueles recebidos por e-mail ou por mensagem instantânea. Isso cria um log de atividades de investigação e correção que podem ser referenciadas no futuro. Muitas equipes desencorajam relatar problemas diretamente a uma pessoa por vários motivos: esta prática introduz uma etapa adicional de transcrição do relatório em um bug, produz relatórios de qualidade inferior que não são visíveis para outros membros da equipe e tende a concentrar a carga de resolução do problema a um punhado de membros da equipe que quem reporta conhece, em vez da pessoa atualmente em serviço (consulte Capítulo 29, Lidando com Interrupções).
Shakespeare tem um problema
Você está de plantão para o serviço de pesquisa Shakespeare e recebe um alerta: “Shakespeare-BlackboxProbe_SearchFailure:”; seu monitoramento de caixa preta não conseguiu localizar resultados de pesquisa para “as formas das coisas desconhecidas” (the forms of things unknown) nos últimos cinco minutos. O sistema de alerta registrou um bug – com links para os resultados recentes do sondador da caixa preta e para a entrada do playbook deste alerta – e o atribuiu a você. É hora de entrar em ação!
Triagem
Depois de receber um relatório de problema, a próxima etapa é descobrir o que fazer a respeito. Os problemas podem variar em gravidade: um problema pode afetar apenas um usuário em circunstâncias muito específicas (e pode ter uma solução alternativa) ou pode acarretar uma interrupção global completa de um serviço. Sua resposta deve ser apropriada para o impacto do problema: é apropriado declarar uma emergência geral quando se tratar de uma interrupção global (saiba mais no Capítulo 14), mas fazê-lo para uma circunstância específica é um exagero. Avaliar a gravidade de um problema requer um exercício de bom senso de engenharia e, muitas vezes, um certo grau de calma sob pressão.
Sua primeira resposta em uma grande interrupção pode ser iniciar a resolução do problema e tentar encontrar a causa raiz o mais rápido possível. Ignore esse instinto!
Em vez disso, seu curso de ação deve ser fazer com que o sistema funcione da melhor maneira possível dentro das circunstâncias. Isso pode envolver opções de emergência, como desviar o tráfego de um cluster quebrado para outros que ainda estão funcionando, interromper o tráfego em conjunto para evitar uma falha em cascata ou desativar subsistemas para aliviar a carga. Parar o sangramento deve ser sua primeira prioridade; você não está ajudando seus usuários se o sistema parar de funcionar enquanto você está mexendo na causa raiz. Claro, uma ênfase na triagem rápida não impede a tomada de medidas para preservar as evidências do que está errado, como logs, para ajudar na análise de causa raiz subsequente.
Os pilotos novatos são ensinados que sua primeira responsabilidade em uma emergência é pilotar o avião; a solução de problemas é secundária para colocar o avião e todos nele em segurança no solo. Essa abordagem também se aplica a sistemas de computador: por exemplo, se um bug está levando a uma corrupção de dados possivelmente irrecuperável, congelar o sistema para evitar mais falhas pode ser melhor do que deixar esse comportamento continuar.
Essa percepção costuma ser bastante perturbadora e contra-intuitiva para novos SREs, especialmente aqueles cuja experiência anterior foi em organizações de desenvolvimento de produtos.
Exame
Precisamos ser capazes de examinar o que cada componente do sistema está fazendo para entender se está se comportando corretamente ou não.
Idealmente, um sistema de monitoramento está registrando métricas para seu sistema, conforme discutido no Capítulo 10. Essas métricas são boas para começar a descobrir o que está dando errado. Representar graficamente séries temporais e operações em séries temporais pode ser uma maneira eficaz de compreender o comportamento de peças específicas de um sistema e encontrar correlações que podem sugerir onde os problemas começaram. (Mas muito cuidado com as falsas correlações que podem levar a caminhos errados!)
O registro de logs é outra ferramenta inestimável. A exportação de informações sobre cada operação e sobre o estado do sistema permite entender exatamente o que um processo estava fazendo em um determinado momento. Você pode precisar analisar os logs do sistema em um ou em vários processos. Rastrear solicitações por meio de toda a pilha usando ferramentas como Dapper fornece uma maneira muito poderosa de entender como um sistema distribuído está funcionando, embora vários casos de uso impliquem designs de rastreamento significativamente diferentes.
Logs
Os logs de texto são muito úteis para o debug reativo em tempo real, enquanto o armazenamento de logs em um formato binário estruturado pode possibilitar a construção de ferramentas para conduzir análises retrospectivas com muito mais informações.
É muito útil ter vários níveis de verbosidade disponíveis, junto com uma maneira de aumentar esses níveis rapidamente. Essa funcionalidade permite examinar uma ou todas as operações com detalhes incríveis sem ter que reiniciar o processo, enquanto ainda permite reduzir os níveis de detalhamento quando o serviço está operando normalmente. Dependendo do volume de tráfego que seu serviço recebe, pode ser melhor usar amostragem estatística; por exemplo, você pode mostrar uma em cada 1.000 operações.
A próxima etapa é incluir um idioma de seleção para que você possa dizer “mostrar operações que correspondem a X” para uma ampla gama de X – por exemplo, Set RPCs com um tamanho de carga útil abaixo de 1.024 bytes ou operações que demoram mais de 10 ms para retornar, ou que se chamem doSomethingInteresting() em rpc_handler.py. Você pode até querer projetar sua infraestrutura de log para que possa ativá-la conforme necessário, de forma rápida e seletiva.
Expor o estado atual é o terceiro truque em nossa toolbox. Por exemplo, os servidores do Google têm endpoints que exibem uma amostra de RPCs enviados ou recebidos recentemente, então é possível entender como qualquer servidor está se comunicando com os outros sem fazer referência a um diagrama de arquitetura. Esses endpoints também mostram histogramas de taxas de erro e latência para cada tipo de RPC, de modo que seja possível dizer rapidamente o que não está íntegro. Alguns sistemas possuem terminais que mostram sua configuração atual ou permitem o exame de seus dados; por exemplo, os servidores Borgmon do Google (Capítulo 10) podem mostrar as regras de monitoramento que estão usando e até mesmo permitir o rastreamento de uma determinada computação passo a passo até as métricas de origem das quais um valor é derivado.
Finalmente, você pode até precisar instrumentar um cliente para experimentar, a fim de descobrir o que um componente está retornando, em resposta às requisições.
O debug do Shakespeare
Usando o link para os resultados de monitoramento de caixa preta no bug, você descobre que o requisitor envia uma requisição HTTP GET para o endpoint /api/search:
{
‘search_text’: ‘the forms of things unknown’
}
Ele espera receber uma resposta com um código HTTP 200 e um payload JSON correspondendo exatamente a:
[{
“work”: “A Midsummer Night’s Dream”,
“act”: 5,
“scene”: 1,
“line”: 2526,
“speaker”: “Theseus”
}]
O sistema está configurado para enviar um requisito uma vez por minuto; nos últimos 10 minutos, cerca de metade dos requisitos foram bem-sucedidos, embora sem nenhum padrão discernível. Infelizmente, o requisitor não exibe o que foi retornado quando ele falhou; você anota para consertar isso futuramente.
Usando curl, é possível enviar requisições manualmente para o endpoint de pesquisa e obter uma resposta com falha com o código de HTTP 502 (Bad Gateway) e sem payload. Ele possui um cabeçalho HTTP, X-Request-Trace, que lista os endereços dos servidores backend responsáveis por responder a essa requisição. Com essas informações, agora é possível examinar esses backends para testar se estão respondendo de maneira adequada.
Diagnóstico
Uma compreensão completa do design do sistema é decididamente útil para chegar a hipóteses plausíveis sobre o que deu errado, mas também existem algumas práticas genéricas que ajudarão mesmo sem o conhecimento do domínio.
Simplificar e reduzir
Idealmente, os componentes em um sistema têm interfaces bem definidas e realizam transformações conhecidas do input para o output (em nosso exemplo, dado um texto de pesquisa de input, um componente pode retornar um output contendo possíveis correspondências). É então possível observar as conexões entre os componentes – ou, de forma equivalente, os dados que fluem entre eles – para determinar se um dado componente está funcionando corretamente. A injeção de dados de teste conhecidos para verificar se a output resultante é esperado (uma forma de teste de caixa preta) em cada etapa pode ser especialmente eficaz, assim como a injeção de dados destinados a explorar as possíveis causas dos erros. Ter um caso de teste sólido reproduzível torna o debug muito mais rápido e pode ser necessário usar o caso em um ambiente de não produção, onde técnicas mais invasivas ou arriscadas estão disponíveis do que seria possível na produção.
Dividir e conquistar é uma técnica de solução de propósito geral muito útil. Em um sistema multicamadas onde o trabalho ocorre em uma pilha de componentes, muitas vezes é melhor começar sistematicamente de uma extremidade da pilha e trabalhar em direção à outra extremidade, examinando cada componente por vez. Essa estratégia também é adequada para uso com pipelines de processamento de dados. Em sistemas excepcionalmente grandes, proceder linearmente pode ser muito lento; uma alternativa, chamada de bissecção (bisection), divide o sistema ao meio e examina os caminhos de comunicação entre os componentes de um lado e do outro. Depois de determinar se uma metade parece estar funcionando corretamente, repita o processo até que fique com um componente possivelmente defeituoso.
Pergunte “o quê”, “onde” e “por quê”
Um sistema com defeito geralmente ainda está tentando fazer algo – apenas não o que você deseja que ele faça. Descobrir o quê ele está fazendo e perguntar por quê está fazendo e onde seus recursos estão sendo usados ou para onde está indo seu output pode ajudar a compreender como as coisas deram errado. (Em muitos aspectos, isso é semelhante à técnica dos “Cinco Porquês”, introduzida por Taiichi Ohno em um livro de 1988 para entender as causas dos erros de fabricação).
Revelando as causas de um sintoma
Sintoma: Um cluster do Spanner tem alta latência e os RPCs para seus servidores estão expirando.
Porque? As tarefas do servidor Spanner estão usando todo o seu tempo de CPU e não podem obter progresso em todas as requisições que os clientes enviam.
Onde no servidor o tempo da CPU está sendo usado? O profiling de servidor mostra que ele está ordenando as entradas nos logs verificados no disco.
Onde no código de classificação de log ele está sendo usado? Ao avaliar uma expressão regular em relação a caminhos para arquivos de log.
Soluções: reescreva a expressão regular para evitar retrocessos. Procure na base de código por padrões semelhantes. Considere o uso de RE2, que não retrocede e garante o crescimento linear do tempo de execução com o tamanho do input. (Em contraste com RE2, o PCRE pode exigir tempo exponencial para avaliar algumas expressões regulares. RE2 está disponível em https://github.com/google/re2).
O que tocou por último
Os sistemas têm inércia: descobrimos que um sistema de computador em funcionamento tende a permanecer em ação até que seja acionado por uma força externa, como uma mudança de configuração ou uma alteração no tipo de carga atendida. Alterações recentes em um sistema podem ser um lugar produtivo para começar a identificar o que está dando errado. (Observe que essa é uma heurística frequentemente usada para resolver indisponibilidades).
Sistemas bem projetados devem possuir log de produção extensivo para rastrear deploys de novas versões e alterações de configuração em todas as camadas da pilha, desde os binários do servidor que lidam com o tráfego do usuário até os pacotes instalados em nós individuais no cluster. Correlacionar as mudanças no desempenho e comportamento de um sistema com outros eventos no sistema e ambiente também pode ser útil na construção de painéis de monitoramento; por exemplo, você pode anotar um gráfico que mostra as taxas de erro do sistema com os tempos de início e término do deploy de uma nova versão, como visto na figura abaixo:
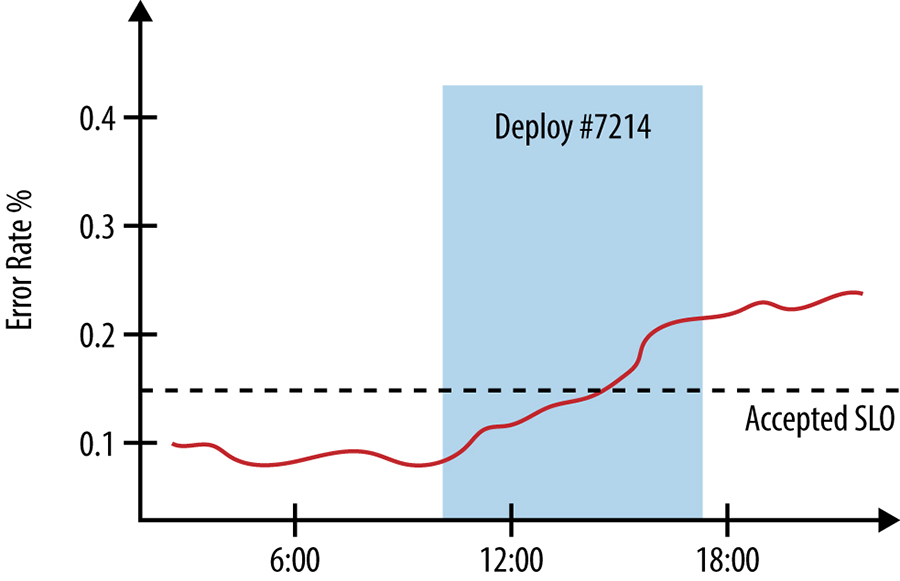
O envio manual de uma requisição para o endpoint /api/search (em “O debug do Shakespeare”) e ver a falha listando os servidores backend que lidaram com a resposta permite desconsiderar a probabilidade de que o problema seja com o servidor frontend da API e com os balanceadores de carga: a resposta provavelmente não teria incluído essa informação se a requisição não tivesse pelo menos chegado aos backends de pesquisa e falhado lá. Agora você pode concentrar seus esforços nos backends – analisando seus logs, enviando consultas de teste para ver quais respostas eles retornam e examinando suas métricas exportadas.
Diagnósticos específicos
Embora as ferramentas genéricas descritas anteriormente sejam úteis em uma ampla gama de domínios de problemas, você provavelmente achará útil construir ferramentas e sistemas para ajudar no diagnóstico de seus serviços específicos. Os SREs do Google gastam muito de seu tempo disponível construindo tais ferramentas. Embora muitas dessas ferramentas sejam necessariamente específicas para um determinado sistema, certifique-se de procurar pontos em comum entre os serviços e as equipes para evitar a duplicação de esforços.
Testar e tratar
Depois de chegar a uma pequena lista de possíveis causas, é hora de tentar descobrir qual fator está na raiz do problema real. Usando o método experimental, podemos tentar testar ou descartar nossas hipóteses. Por exemplo, suponha que pensamos que um problema é causado por uma falha de rede entre um servidor de lógica da aplicação e um servidor de banco de dados ou pela recusa de conexões do banco de dados. Tentar se conectar ao banco de dados com as mesmas credenciais que o servidor de lógica da aplicação usa pode refutar a segunda hipótese, enquanto o ping do servidor de banco de dados pode ser capaz de refutar a primeira, dependendo da topologia da rede, regras de firewall e outros fatores. Seguir o código e tentar imitar o fluxo do código, passo a passo, pode apontar exatamente o que está errado.
Há uma série de considerações a ter em mente ao projetar testes (que podem ser tão simples como enviar um ping ou tão complicados como remover o tráfego de um cluster e injetar requisições especialmente formadas para encontrar uma condição de corrida):
- Um teste ideal deve ter alternativas mutuamente exclusivas, de modo que possa controlar um grupo de hipóteses e governar outro conjunto. Na prática, isso pode ser difícil de conseguir.
- Considere o óbvio primeiro: execute os testes em ordem decrescente de probabilidade, considerando os possíveis riscos do teste para o sistema. Provavelmente faz mais sentido testar os problemas de conectividade de rede entre duas máquinas antes de verificar se uma alteração recente na configuração removeu o acesso de um usuário à segunda máquina.
- Um experimento pode fornecer resultados enganosos devido a fatores de confusão. Por exemplo, uma regra de firewall pode permitir o acesso apenas de um endereço IP específico, o que pode fazer com que o ping do banco de dados de sua estação de trabalho falhe, mesmo se o ping da máquina do servidor de lógica de aplicação for bem-sucedido.
- Os testes ativos podem ter efeitos colaterais que alteram os resultados de testes futuros. Por exemplo, permitir que um processo use mais CPUs pode tornar as operações mais rápidas, mas pode aumentar a probabilidade de ocorrer disputas de dados. Da mesma forma, ativar o log verboso pode tornar um problema de latência ainda pior e confundir seus resultados: o problema está piorando por conta própria ou por causa do log?
- Alguns testes podem não ser definitivos, apenas sugestivos. Pode ser muito difícil fazer com que as condições de corrida ou deadlocks aconteçam de maneira oportuna e reproduzível, então você pode ter que se contentar com evidências menos certas de que essas são as causas.
Anote com clareza quais ideias você teve, quais testes você executou e os resultados que obteve. (Usar um documento compartilhado ou bate-papo em tempo real para anotações fornece um carimbo de data/hora de quando você fez algo, o que é útil para postmortems. Também ajuda a compartilhar essas informações com outras pessoas, para que elas fiquem a par do estado atual do mundo e não precisem interromper sua solução de problemas). Principalmente quando você está lidando com casos mais complicados e prolongados, esta documentação pode ser crucial para ajudá-lo a lembrar exatamente o que aconteceu e evitar repetir essas etapas. Se você executou um teste ativo alterando um sistema – por exemplo, dando mais recursos a um processo – fazer alterações de forma sistemática e documentada o ajudará a retornar o sistema à sua configuração de pré-teste, em vez de executar em uma configuração confusa e desconhecida.
Resultados negativos são mágicos
Escrito por Randall Bosetti
Editado por Joan Wendt
Um resultado “negativo” é um resultado experimental em que o efeito esperado está ausente, ou seja, qualquer experimento que não funcione conforme o planejado. Isso inclui novos projetos, heurísticas ou processos humanos que não conseguem melhorar os sistemas que substituem.
Os resultados negativos não devem ser ignorados ou descontados. Perceber que está errado tem muito valor: um resultado negativo claro pode resolver algumas das questões de design mais difíceis. Frequentemente, uma equipe tem dois projetos aparentemente razoáveis, mas o progresso em uma direção deve abordar questões vagas e especulativas sobre se a outra direção poderia ser melhor.
Experimentos com resultados negativos são conclusivos. Eles nos dizem algo certo sobre a produção, ou o espaço de design, ou os limites de desempenho de um sistema. Eles podem ajudar outros a determinar se seus próprios experimentos ou projetos valem a pena. Por exemplo, uma determinada equipe de desenvolvimento pode decidir não usar um determinado servidor web porque ele pode lidar com apenas cerca de 800 conexões das 8.000 conexões necessárias antes de falhar devido à contenção de bloqueio. Quando a equipe de desenvolvimento subsequente decidir avaliar servidores web, em vez de começar do zero, eles podem usar esse resultado negativo já bem documentado como um ponto de partida para decidir rapidamente se (a) eles precisam de menos de 800 conexões ou (b) os problemas de contenção de bloqueio foram resolvidos.
Mesmo quando os resultados negativos não se aplicam diretamente ao experimento de outra pessoa, os dados complementares coletados podem ajudar outros ainda a escolher novos experimentos ou a evitar armadilhas em projetos anteriores. Microbenchmarks, anti padrões documentados e post mortem de projeto se encaixam nessa categoria. Você deve considerar o escopo do resultado negativo ao projetar um experimento, porque um resultado negativo amplo ou especialmente robusto ajudará seus pares ainda mais.
Ferramentas e métodos podem sobreviver ao experimento e informar o trabalho futuro. Como exemplo, ferramentas de benchmarking e geradores de carga podem resultar tão facilmente de um experimento de desconfirmação quanto de um experimento de apoio. Muitos webmasters se beneficiaram do trabalho difícil e orientado a detalhes que produziu o ApacheBench, um servidor web para teste de carregamento, embora seus primeiros resultados provavelmente tenham sido decepcionantes.
Construir ferramentas para experimentos repetíveis também pode ter benefícios indiretos: embora um aplicativo que você construa possa não se beneficiar de ter seu banco de dados em SSDs ou de criar índices para chaves densas, o próximo pode precisar; escrever um script que permite testar facilmente essas alterações de configuração garante que você não se esqueça ou perca as otimizações em seu próximo projeto.
Publicar resultados negativos melhora a cultura baseada em dados da nossa indústria. A contabilização de resultados negativos e insignificância estatística reduz a rejeição em nossas métricas e fornece um exemplo para outros de como aceitar a incerteza com maturidade. Ao publicar tudo, você incentiva outros a fazerem o mesmo, e todos no setor aprendem coletivamente com muito mais rapidez. A SRE já aprendeu essa lição com postmortems de alta qualidade, que tiveram um grande efeito positivo na estabilidade da produção.
Publique seus resultados. Se você estiver interessado nos resultados de um experimento, há uma boa chance de que outras pessoas também estejam. Quando você publica os resultados, essas pessoas não precisam projetar e executar um experimento semelhante. É tentador e comum evitar relatar resultados negativos porque é fácil perceber que o experimento “falhou”. Alguns experimentos estão condenados ao fracasso e tendem a ser apanhados em revisão. Muitos outros experimentos simplesmente não são relatados porque as pessoas acreditam erroneamente que resultados negativos não significam progresso.
Faça sua parte contando a todos sobre os designs, algoritmos e fluxos de trabalho da equipe que você descartou. Incentive seus colegas reconhecendo que os resultados negativos fazem parte de uma tomada de risco cuidadosa e que todo experimento bem planejado tem mérito. Seja cético em relação a qualquer documento de design, avaliação de desempenho ou ensaio que não mencione falhas. Esse documento é potencialmente muito filtrado ou o autor não foi rigoroso o suficiente em seus métodos.
Acima de tudo, publique os resultados que você achar surpreendentes para que os outros – incluindo o seu eu futuro – não fiquem surpresos depois.
Cura
Idealmente, agora reduzimos o conjunto de causas possíveis a uma só. A seguir, gostaríamos de provar que essa é a causa real. Provar definitivamente que um determinado fator causou um problema – ao reproduzi-lo à vontade – pode ser difícil de fazer nos sistemas em produção; frequentemente, só podemos encontrar fatores causais prováveis, pelos seguintes motivos:
- Os sistemas são complexos. É muito provável que existam vários fatores, cada um dos quais individualmente não sendo a causa, mas que, considerados em conjunto, são as causas. (Veja em “Thinking in Systems” como pensar sobre sistemas e também em “How Complex Systems Fail” e The Field Guide to Understanding “Human Error” sobre as limitações de encontrar uma única causa raiz em vez de examinar o sistema e seu ambiente em busca de fatores causais). Os sistemas reais também são frequentemente dependentes de caminho, de modo que devem estar em um estado específico antes que ocorra uma falha.
- Reproduzir o problema em um sistema de produção ao vivo pode não ser uma opção, seja por causa da complexidade de colocar o sistema em um estado em que a falha pode ser acionada, ou porque mais tempo de inatividade pode ser inaceitável. Ter um ambiente de não produção pode mitigar esses desafios, embora ao custo de ter outra cópia do sistema para funcionar.
Depois de encontrar os fatores que causaram o problema, é hora de fazer anotações sobre o que deu errado com o sistema, como você rastreou o problema, como corrigiu o problema e como evitar que aconteça novamente. Em outras palavras, você precisa escrever uma postmortem (embora, idealmente, o sistema esteja vivo neste momento!).
Estudo de caso
O App Engine, parte do Google Cloud Platform, é um produto de plataforma como serviço que permite aos desenvolvedores criar serviços na infraestrutura do Google. Um de nossos clientes internos preencheu um relatório de problema indicando que eles viram recentemente um aumento dramático na latência, uso da CPU e número de processos em execução necessários para servir o tráfego para seu aplicativo, um sistema de gerenciamento de conteúdo usado para construir documentação para desenvolvedores (compactamos e simplificamos este estudo de caso para ajudar na compreensão) O cliente não conseguiu encontrar nenhuma mudança recente em seu código que se correlacionasse com o aumento nos recursos, e não houve um aumento no tráfego para seu aplicativo (veja Figura 12-3), então eles estavam se perguntando se uma mudança no serviço do App Engine seria o responsável.
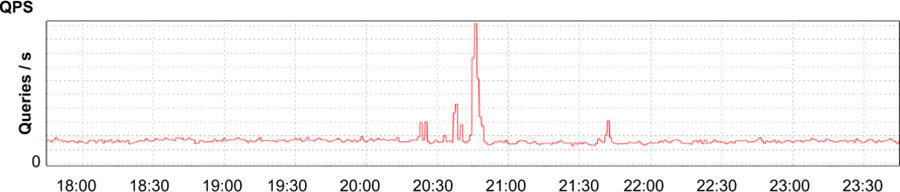 Figura 12-3 Solicitações do aplicativo recebidas por segundo, mostrando um breve pico e voltando ao normal
Figura 12-3 Solicitações do aplicativo recebidas por segundo, mostrando um breve pico e voltando ao normal
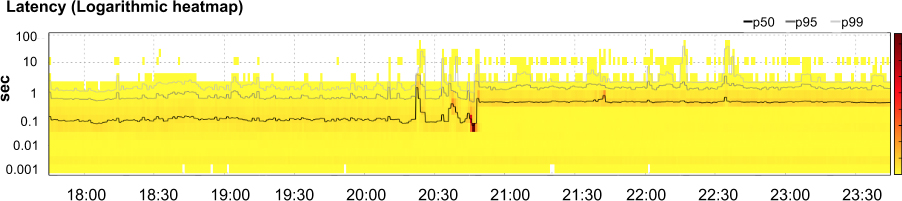 Figura 12-4 Latência da aplicação, mostrando 50º, 95º e 99º percentis (linhas) com um mapa de calor exibindo quantas solicitações caíram em um determinado intervalo de latência em qualquer ponto no tempo (sombra)
Figura 12-4 Latência da aplicação, mostrando 50º, 95º e 99º percentis (linhas) com um mapa de calor exibindo quantas solicitações caíram em um determinado intervalo de latência em qualquer ponto no tempo (sombra)
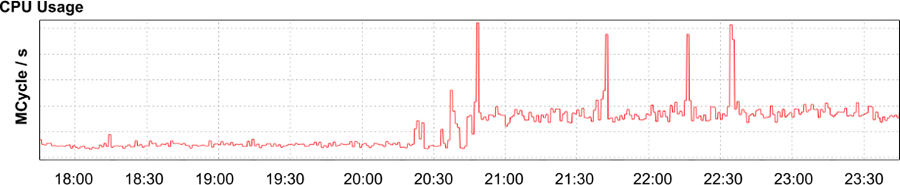 Figura 12-5 Uso agregado da CPU pelo aplicativo
Figura 12-5 Uso agregado da CPU pelo aplicativo
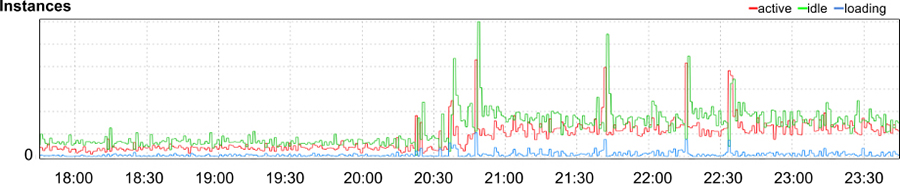 Figura 12-6: Número de instâncias para o aplicativo
Figura 12-6: Número de instâncias para o aplicativo
Nossa investigação descobriu que a latência havia de fato aumentado em quase uma ordem de magnitude (como mostrado na Figura 12-4). Simultaneamente, a quantidade de tempo de CPU (Figura 12-5) e o número de processos de serviço (Figura 12-6) quase quadruplicaram. Obviamente, algo estava errado. Era hora de começar a solução de problemas.
Normalmente, um aumento repentino na latência e no uso de recursos indica um aumento no tráfego enviado ao sistema ou uma mudança na configuração do sistema. No entanto, poderíamos facilmente descartar essas duas possíveis causas: embora um pico no tráfego para o aplicativo por volta de 20:45 possa explicar um breve aumento no uso de recursos, esperamos que o tráfego retorne à linha de base logo após a normalização do volume da requisição. Esse pico certamente não deveria ter continuado por vários dias, começando quando os desenvolvedores do aplicativo preencheram o relatório e iniciamos a investigação do problema. Em segundo lugar, a mudança no desempenho aconteceu no sábado, quando nem as mudanças no aplicativo nem no ambiente de produção ocorreram. Os pushes de código ede configuração mais recentes do serviço foram concluídos dias antes. Além disso, se o problema foi originado com o serviço, esperamos ver efeitos semelhantes em outros aplicativos que usam a mesma infraestrutura. No entanto, nenhum outro aplicativo estava experimentando efeitos semelhantes.
Encaminhamos o relatório do problema para nossos colegas, desenvolvedores do App Engine, para investigar se o cliente estava encontrando alguma idiossincrasia na infraestrutura de serviço. Os desenvolvedores também não conseguiram encontrar estranhezas. No entanto, um desenvolvedor percebeu uma correlação entre o aumento da latência e o aumento de uma chamada de API de armazenamento de dados específica, merge_join, que geralmente indica indexação abaixo do ideal ao ler o armazenamento de dados. Adicionar um índice composto às propriedades que o aplicativo usa para selecionar objetos do armazenamento de dados aceleraria essas solicitações e, em princípio, aceleraria o aplicativo como um todo, mas precisaríamos descobrir quais propriedades precisavam de indexação. Uma rápida olhada no código do aplicativo não revelou nenhum suspeito óbvio.
Era hora de retirar o maquinário pesado do nosso kit de ferramentas: usando Dapper, rastreamos as etapas que as solicitações HTTP individuais seguiram – desde o recebimento por um proxy reverso de frontend até o ponto em que o código do aplicativo retornou uma resposta – e procuramos nos RPCs emitidos por cada servidor envolvido no tratamento dessa solicitação. Isso nos permitiria ver quais propriedades foram incluídas nas solicitações para o armazenamento de dados e, em seguida, criar os índices apropriados.
Durante a investigação, descobrimos que as solicitações de conteúdo estático, como imagens, que não eram veiculadas no armazenamento de dados, também eram muito mais lentas do que o esperado. Observando os gráficos com granularidade em nível de arquivo, vimos que suas respostas tinham sido muito mais rápidas apenas alguns dias antes. Isso implicava que a correlação observada entre merge_join e o aumento de latência era espúria e que nossa teoria de indexação subótima era fatalmente falha.
Examinando as solicitações inesperadamente lentas de conteúdo estático, a maioria dos RPCs enviados da aplicação foi para um serviço memcache, portanto, as solicitações deveriam ter sido muito rápidas – na ordem de alguns milissegundos. Essas solicitações acabaram sendo muito rápidas, então o problema não parecia se originar ali. No entanto, entre o momento em que o aplicativo começou a trabalhar em uma solicitação e quando fez os primeiros RPCs, houve cerca de um período de 250ms em que o aplicativo estava funcionando… bem, de alguma forma. Como o App Engine executa o código fornecido pelos usuários, sua equipe SRE não faz o perfil ou inspeciona o código do aplicativo, portanto, não podíamos dizer o que o aplicativo estava fazendo naquele intervalo; da mesma forma, o Dapper não pode ajudar a rastrear o que estava acontecendo, pois ele só pode rastrear chamadas RPC, e nenhuma foi feita durante esse período.
Diante do que era, a essa altura, um mistério e tanto, decidimos não resolvê-lo… ainda. O cliente tinha um lançamento público agendado para a semana seguinte, e não tínhamos certeza de quando seríamos capazes de identificar o problema e corrigi-lo. Em vez disso, recomendamos que o cliente aumentasse os recursos alocados para seu aplicativo para o tipo de instância mais rica na CPU disponível. Isso reduziu a latência do aplicativo a níveis aceitáveis, embora não tão baixa quanto gostaríamos. Concluímos que a atenuação da latência foi boa o suficiente para que a equipe pudesse conduzir seu lançamento com sucesso e, em seguida, investigar no lazer. (Embora lançar com um bug não identificado não seja o ideal, muitas vezes é impraticável eliminar todos os bugs conhecidos. Em vez disso, às vezes temos que nos contentar com medidas secundárias e mitigar os riscos da melhor maneira possível, usando o bom senso de engenharia).
Nesse ponto, suspeitamos que o aplicativo fosse vítima de outra causa comum de aumentos repentinos na latência e no uso de recursos: uma alteração no tipo de trabalho. Vimos um aumento nas gravações no armazenamento de dados do aplicativo, pouco antes de sua latência aumentar, mas como esse aumento não era muito grande – nem foi sustentado – nós o descartamos como coincidência. No entanto, esse comportamento se parecia com um padrão comum: uma instância do aplicativo é inicializada lendo objetos do armazenamento de dados e, em seguida, armazenando-os na memória da instância. Ao fazer isso, a instância evita ler, raramente altera a configuração do armazenamento de dados em cada solicitação e, em vez disso, verifica os objetos na memória. Então, o tempo que leva para lidar com as solicitações frequentemente aumentará com a quantidade de dados de configuração. (A pesquisa do armazenamento de dados pode usar um índice para acelerar a comparação, mas uma implementação frequente na memória é uma comparação simples for loop em todos os objetos em cache. Se houver apenas alguns objetos, não importa que isso leve um tempo linear, mas pode causar um aumento significativo na latência e no uso de recursos conforme o número de objetos em cache aumenta). Não poderíamos provar que esse comportamento era a raiz do problema, mas é um antipadrão comum.
Os desenvolvedores de aplicativos adicionaram instrumentação para entender onde o aplicativo estava consumindo tempo. Eles identificaram um método que era chamado a cada solicitação, que verificava se um usuário tinha acesso à lista de permissões para um determinado caminho. O método usou uma camada de cache que buscava minimizar os acessos ao armazenamento de dados e ao serviço memcache, mantendo objetos da lista de permissões na memória das instâncias. Como um dos desenvolvedores do aplicativo observou na investigação: “Não sei onde está o fogo ainda, mas estou cego pela fumaça que sai deste cache da lista de permissões”.
Algum tempo depois, a causa raiz foi encontrada: devido a um bug de longa data no sistema de controle de acesso do aplicativo, sempre que um caminho específico fosse acessado, um objeto de lista de permissões seria criado e armazenado no datastore. Na corrida para o lançamento, um scanner de segurança automatizado testou o aplicativo em busca de vulnerabilidades e, como efeito colateral, sua varredura produziu milhares de objetos na lista de permissões ao longo de meia hora. Esses objetos supérfluos da lista de permissões tiveram que ser verificados em cada solicitação ao aplicativo, o que levou a respostas patologicamente lentas – sem causar nenhuma chamada RPC do aplicativo para outros serviços. Corrigir o bug e remover esses objetos retornou o desempenho do aplicativo aos níveis esperados.
Tornando a solução de problemas mais fácil
Existem muitas maneiras de simplificar e acelerar a solução de problemas. Talvez as mais fundamentais sejam:
- Construir Observabilidade – com métricas de caixa branca e logs estruturados – em cada componente desde o início
- Projetar sistemas com interfaces bem compreendidas e observáveis entre os componentes
Garantir que as informações estejam disponíveis de maneira consistente em todo o sistema – por exemplo, usando um identificador de solicitação exclusivo em toda a extensão de RPCs gerados por vários componentes – reduz a necessidade de descobrir qual entrada de log em um componente upstream corresponde a uma entrada de log em um componente downstream, acelerando o tempo de diagnóstico e recuperação.
Problemas em representar corretamente o estado da realidade em uma mudança de código ou de ambiente geralmente levam à necessidade de solucionar o problema. Simplificar, controlar e registrar essas alterações pode reduzir a necessidade de solução de problemas e tornar mais fácil de resolvê-los, quando vierem a ocorrer.
Conclusão
Vimos algumas etapas que você pode seguir para tornar o processo de solução de problemas claro e compreensível para os novatos, para que eles também possam se tornar eficazes na solução de problemas. A adoção de uma abordagem sistemática para a solução de problemas – em vez de confiar na sorte ou na experiência – pode ajudar a limitar o tempo de recuperação dos seus serviços, levando a uma experiência melhor para os usuários.
Fonte: Google SRE Book