Rastreamento de interrupções
Escrito por Gabe Krabbe
Editado por Lisa Carey
Melhorar a confiabilidade ao longo do tempo só é possível se você começar a partir de uma baseline conhecida e puder acompanhar o progresso. “Outalator”, nosso rastreador de interrupções, é uma das ferramentas que usamos para fazer exatamente isso. Outalator é um sistema que recebe passivamente todos os alertas enviados por nossos sistemas de monitoramento e nos permite anotar, agrupar e analisar esses dados.
Aprender sistematicamente com os problemas do passado é essencial para o gerenciamento eficaz de serviços. O Capítulo 15 “Cultura Postmortem: Aprendendo com o Fracasso”) fornece informações detalhadas para interrupções individuais, mas são apenas parte da resposta. Eles foram escritos apenas para incidentes com um grande impacto, portanto, os problemas que têm um impacto individualmente pequeno, mas são frequentes e generalizados, não se enquadram em seu escopo. Da mesma forma, postmortems tendem a fornecer insights úteis para melhorar um único serviço ou conjunto de serviços, mas podem perder oportunidades que teriam um pequeno efeito em casos individuais, ou oportunidades que têm uma relação custo/benefício baixa, mas que teriam grande impacto horizontal. (Por exemplo, pode ser necessário um esforço significativo de engenharia para fazer uma mudança específica no Bigtable que tem apenas um pequeno efeito de mitigação para uma interrupção. No entanto, se essa mesma mitigação estiver disponível em muitos eventos, o esforço de engenharia pode valer a pena).
Também podemos obter informações úteis a partir de perguntas como, “Quantos alertas por turno de plantão esta equipe recebe?”, “Qual é a proporção de alertas acionáveis/não acionáveis no último trimestre?”, Ou mesmo simplesmente “Qual dos serviços que essa equipe gerencia cria mais trabalho?”
Escalator
No Google, todas as notificações de alerta SRE compartilham um sistema replicado central que rastreia se um humano acusou o recebimento da notificação. Se nenhuma confirmação for recebida após um intervalo configurado, o sistema escalará para o(s) próximo(s) destino(s) configurado(s) – por exemplo, de plantão primário para secundário. Esse sistema, denominado “The Escalator”, foi inicialmente projetado como uma ferramenta amplamente transparente que recebia cópias de e-mails enviados para aliases de plantão. Essa funcionalidade permitiu que o Escalator se integrasse facilmente aos fluxos de trabalho existentes, sem exigir nenhuma mudança no comportamento do usuário (ou, na época, monitorar o comportamento do sistema).
Outalator
Seguindo o exemplo do Escalator, onde adicionamos recursos úteis à infraestrutura existente, criamos um sistema que lidaria não apenas com as notificações de escalonamento individuais, mas com a próxima camada de abstração: interrupções.
O Outalator permite que os usuários visualizem uma lista intercalada no tempo de notificações para várias filas de uma vez, em vez de exigir que o usuário alterne entre as filas manualmente. A figura abaixo mostra várias filas conforme aparecem na exibição do Outalator. Essa funcionalidade é útil porque frequentemente uma única equipe de SRE é o ponto principal de contato para serviços com alvos de escalação secundários distintos, geralmente as equipes de desenvolvedores.
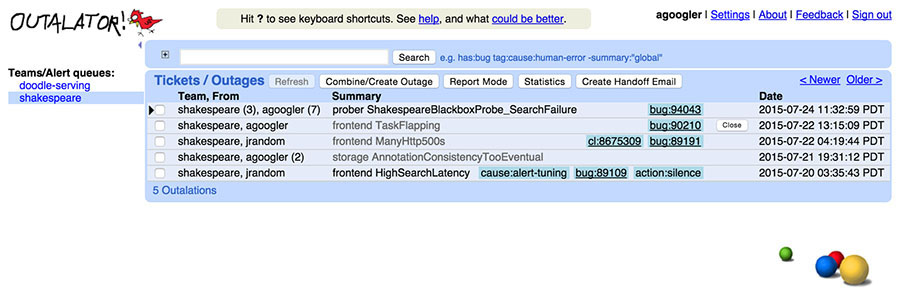
O Outalator armazena uma cópia da notificação original e permite anotar incidentes. Por conveniência, ele também recebe e salva silenciosamente uma cópia de todas as respostas de e-mail. Como alguns acompanhamentos são menos úteis do que outros (por exemplo, uma resposta – todos enviados com o único propósito de adicionar mais destinatários à lista de cc), as anotações podem ser marcadas como “importantes”. Se uma anotação for importante, outras partes da mensagem serão recolhidas na interface para diminuir a confusão. Juntos, isso fornece mais contexto ao se referir a um incidente do que a uma thread de e-mail possivelmente fragmentada.
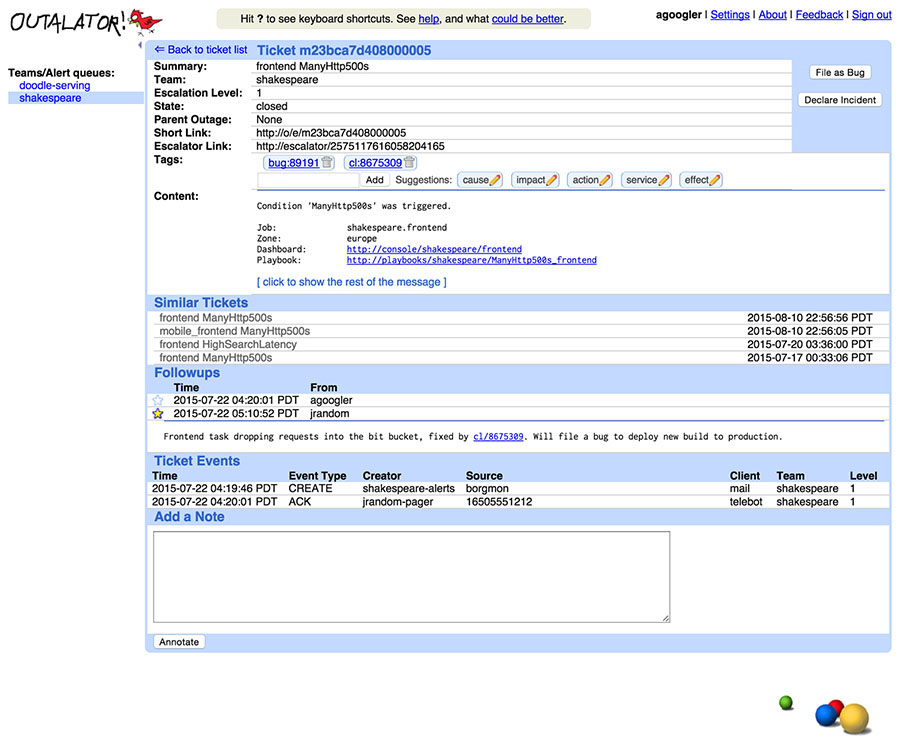
Várias notificações escalonadas (“alertas”) podem ser combinadas em uma única entidade (“incidente”) no Outalator. Essas notificações podem estar relacionadas ao mesmo incidente único, podem ser eventos auditáveis não relacionados e desinteressantes, como acesso privilegiado ao banco de dados, ou podem ser falhas de monitoramento espúrias. Essa funcionalidade de agrupamento, mostrada na figura abaixo, organiza as exibições de visão geral e permite uma análise separada de “incidentes por dia” versus “alertas por dia”.
Como construir seu próprio Outalator
Muitas organizações usam sistemas de mensagens como Slack, Hipchat ou mesmo IRC para comunicação interna e ou atualização de painéis de status. Esses sistemas são ótimos lugares para se conectar a um sistema como o Outalator.
Agregação
Um único evento pode acionar vários alertas, e geralmente irá fazer isso mesmo. Por exemplo, as falhas de rede causam timeout e serviços de backend inacessíveis para todos, então todas as equipes afetadas recebem seus próprios alertas, incluindo os proprietários dos serviços de backend; enquanto isso, o centro de operações de rede terá seu próprio toque de klaxons. No entanto, problemas ainda menores que afetam um único serviço podem acionar vários alertas devido a várias condições de erro diagnosticadas. Embora valha a pena tentar minimizar o número de alertas acionados por um único evento, acionar vários alertas é inevitável na maioria dos cálculos de compensação entre falsos positivos e falsos negativos.
A capacidade de agrupar vários alertas em um único incidente é crítica para lidar com essa duplicação. Enviar um e-mail dizendo “isso é a mesma coisa que outra coisa; são sintomas do mesmo incidente” funciona para um determinado alerta: pode evitar a duplicação de debug ou pânico. Mas o envio de um e-mail para cada alerta não é uma solução prática ou escalonável para lidar com alertas duplicados dentro de uma equipe, muito menos entre equipes ou por longos períodos de tempo.
Marcação de propósito geral
Obviamente, nem todo evento de alerta é um incidente. Alertas de falso positivo ocorrem, bem como eventos de teste ou e-mails mal direcionados de humanos. O Outalator em si não faz distinção entre esses eventos, mas permite a marcação de propósito geral para adicionar metadados às notificações, em qualquer nível. As tags são, em sua maioria, “palavras únicas” de formato livre. Os dois pontos, no entanto, são interpretados como separadores semânticos, o que promove sutilmente o uso de namespaces hierárquicos e permite algum tratamento automático. Este namespacing é suportado por prefixos de tag sugeridos, principalmente “causa” e “ação”, mas a lista é específica da equipe e gerada com base no uso histórico. Por exemplo, “cause:network” (causa:rede) pode ser informação suficiente para algumas equipes, enquanto outra equipe pode optar por tags mais específicas, como “cause:network:switch” (causa:rede:switch) versus “cause:network:cable” (causa:rede:cabo). Algumas equipes podem usar frequentemente tags no estilo “customer:132456” (cliente: 132456), portanto, “cliente” seria sugerido para essas equipes, mas não para outras.
As tags podem ser analisadas e transformadas em um link conveniente (“bug:76543” para o sistema de rastreamento de bugs). Outras tags são apenas uma única palavra (“bogus” é amplamente usado para falsos positivos, por exemplo). Claro, algumas tags são erros de digitação (“cause:netwrok”) e outras não são particularmente úteis, como “problem-went-away” (o problema foi embora), mas evitar uma lista predeterminada e permitir que as equipes encontrem suas próprias preferências e padrões resultará em uma ferramenta mais útil e melhores dados. No geral, as tags têm sido uma ferramenta extremamente poderosa para as equipes obterem e fornecerem uma visão geral dos pontos problemáticos de um determinado serviço, mesmo sem muita, ou mesmo nenhuma, análise formal. Por mais trivial que a marcação pareça, é provavelmente um dos recursos exclusivos mais úteis do Outalator.
Análise
Obviamente, o SRE faz muito mais do que apenas reagir a incidentes. Os dados históricos são úteis quando se está respondendo a um incidente – a pergunta “o que fizemos da última vez?” é sempre um bom ponto de partida. Mas as informações históricas são muito mais úteis quando se referem a problemas sistêmicos, periódicos ou outros problemas mais amplos que possam existir. Habilitar essa análise é uma das funções mais importantes de uma ferramenta de rastreamento de interrupção.
A camada inferior de análise abrange contagem e estatísticas agregadas básicas para relatórios. Os detalhes dependem da equipe, mas incluem informações como incidentes por semana/mês/trimestre e alertas por incidente. A próxima camada é mais importante e fácil de fornecer: comparação entre equipes/serviços e, ao longo do tempo, para identificar os primeiros padrões e tendências. Essa camada permite que as equipes determinem se uma carga de alerta é “normal” em relação ao seu próprio histórico e ao de outros serviços. “Essa é a terceira vez nesta semana” pode ser bom ou ruim, mas saber se “isso” costumava acontecer cinco vezes por dia ou cinco vezes por mês permite a interpretação.
A próxima etapa na análise de dados é encontrar problemas mais amplos, que não são apenas contagens brutas, mas requerem alguma análise semântica. Por exemplo, identificar o componente da infraestrutura que causa a maioria dos incidentes e, portanto, o benefício potencial de aumentar a estabilidade ou desempenho deste componente pressupõe que existe uma maneira direta de fornecer essas informações junto com os registros de incidentes. Como um exemplo simples: diferentes equipes têm condições de alerta específicas do serviço, como “dados obsoletos” ou “alta latência”. Ambas as condições podem ser causadas por congestionamento da rede, levando a atrasos na replicação do banco de dados, e precisam de intervenção. Ou eles podem estar dentro do objetivo de nível de serviço nominal, mas não estão atendendo às expectativas mais elevadas dos usuários. Examinar essas informações em várias equipes nos permite identificar problemas sistêmicos e escolher a solução correta, especialmente se a solução for a introdução de mais falhas artificiais para interromper o desempenho excessivo.
Por um lado, “a maioria dos incidentes causados” é um bom ponto de partida para reduzir o número de alertas acionados e melhorar o sistema geral. Por outro lado, essa métrica pode ser simplesmente um artefato de monitoramento excessivamente sensível ou um pequeno conjunto de sistemas clientes que não estão funcionando corretamente ou que estão sendo executados fora do nível de serviço acordado. E, por outro lado, o número de incidentes por si só não dá nenhuma indicação quanto à dificuldade de consertar ou à gravidade do impacto.
Relatórios e comunicação
De uso mais imediato para SREs da linha de frente é a capacidade de selecionar zero ou mais desajustes e incluir seus assuntos, tags e anotações “importantes” em um e-mail para o próximo engenheiro de plantão (e uma lista de cc arbitrária) para repassar o status atual entre os turnos. Para revisões periódicas dos serviços de produção (que ocorrem semanalmente para a maioria das equipes), o Outalator também oferece um “modo de relatório”, no qual as anotações importantes são expandidas em linha com a lista principal para fornecer uma visão geral rápida dos pontos apresentados.
Benefícios inesperados
Ser capaz de identificar que um alerta, ou uma inundação de alertas, coincide com outra interrupção traz benefícios óbvios: aumenta a velocidade do diagnóstico e reduz a carga em outras equipes, reconhecendo que realmente há um incidente. Existem benefícios adicionais não óbvios. Para usar o Bigtable como exemplo, se um serviço tiver uma interrupção devido a um aparente incidente do Bigtable, mas você pode observar que a equipe SRE do Bigtable não foi alertada, alertar manualmente a equipe provavelmente é uma boa ideia. A visibilidade aprimorada entre as equipes pode e faz uma grande diferença na resolução de incidentes, ou pelo menos na mitigação deles.
Algumas equipes da empresa chegaram ao ponto de definir configurações de escalonamento fictícias: nenhum ser humano recebe as notificações enviadas para lá, mas as notificações aparecem no Outalator e podem ser marcadas, anotadas e revisadas. Um exemplo de uso para esse “sistema de registro” é logar e auditar o uso de contas privilegiadas ou de função (embora seja necessário observar que essa funcionalidade é básica e usada para auditorias técnicas, em vez de jurídicas). Outro uso é registrar e anotar automaticamente execuções de trabalhos periódicos que podem não ser idempotentes – por exemplo, aplicação automática de alterações no schema do controle de versão para os sistemas de banco de dados.
Fonte: Google SRE Book