O ambiente de produção no Google, sob o ponto de vista do SRE
Escrito por JC van Winkel
Editado por Betsy Beyer
Os datacenters do Google são muito diferentes da maioria dos datacenters convencionais e farms de servidores de pequena escala. Essas diferenças apresentam problemas e oportunidades extras. Este capítulo discute os desafios e oportunidades que caracterizam os datacenters do Google e apresenta a terminologia que é usada ao longo do livro.
Hardware
A maioria dos recursos de computação do Google estão em datacenters projetados pelo Google com distribuição de energia, refrigeração, rede e hardware de computação proprietários. Ao contrário dos datacenters de colocation “padrão”, o hardware de computação em um datacenter projetado pelo Google é o mesmo em todos os aspectos. (Ou, majoritariamente o mesmo. Alguns datacenters acabam contando com várias gerações de hardware de computação e, às vezes, aumentamos os datacenters depois de construídos. Mas, na maior parte, nosso hardware de datacenter é homogêneo).
Para eliminar a confusão entre hardware de servidor e software de servidor, usamos a seguinte terminologia ao longo do livro:
Máquina
Uma peça de hardware (ou talvez uma VM)
Servidor
Um pedaço de software que implementa um serviço
As máquinas podem executar qualquer servidor, portanto, não dedicamos máquinas específicas a programas de servidor específicos. Não há nenhuma máquina específica que execute nosso servidor de e-mail, por exemplo. Em vez disso, a alocação de recursos é gerenciada por nosso sistema operacional de cluster, Borg.
Percebemos que o uso da palavra servidor é incomum. O uso comum da palavra combina “binário que aceita conexão de rede” com máquina, mas diferenciar entre os dois é importante quando se fala sobre computação no Google. Depois que você se acostumar com nosso uso de servidor, fica mais claro por que faz sentido usar essa terminologia especializada, não apenas no Google, mas também no restante deste livro.
A figura abaixo ilustra a topologia de um datacenter do Google:
- Dezenas de máquinas são colocadas em um rack
- Os racks estão enfileirados
- Uma ou mais fileiras formam um cluster
- Normalmente, um edifício de datacenter abriga vários clusters
- Vários edifícios de datacenter localizados próximos uns dos outros formam um campus
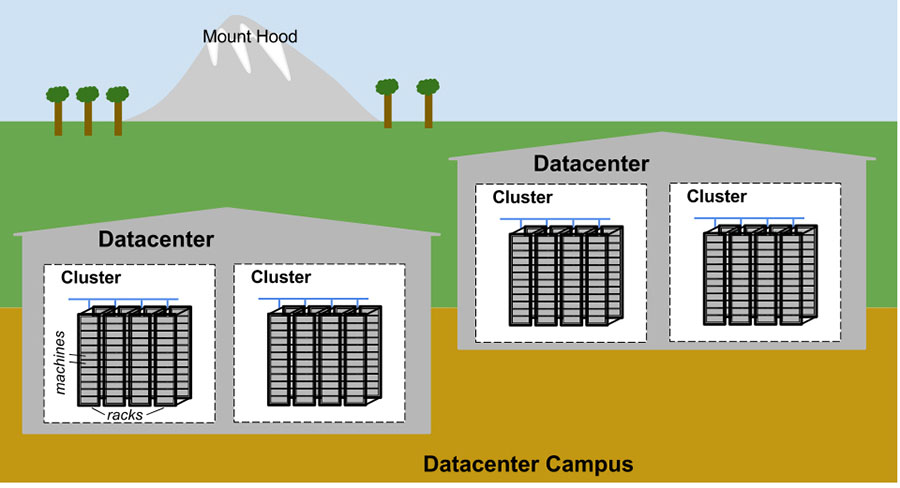
As máquinas em um determinado datacenter precisam ser capazes de se comunicar, então criamos um switch virtual muito rápido com dezenas de milhares de portas. Conseguimos isso conectando centenas de switches construídos pelo Google em uma malha de rede Clos chamada Jupiter. Em sua maior configuração, o Jupiter suporta largura de banda de bissecção de 1,3 Pbps entre os servidores.
Os datacenters estão conectados uns aos outros com nossa rede de backbone global B4. O B4 é uma arquitetura de rede definida por software (e que usa o protocolo de comunicação de código aberto OpenFlow). Ele fornece largura de banda massiva para um número modesto de sites e usa alocação de largura de banda elástica para maximizar a largura de banda média.
Software de sistema que “organiza” o hardware
Nosso hardware deve ser controlado e administrado por software que possa lidar com grande escala. As falhas de hardware são um problema notável que gerenciamos com software. Dado o grande número de componentes de hardware em um cluster, as falhas de hardware ocorrem com bastante frequência. Em um único cluster, em um ano típico, milhares de máquinas falham e milhares de discos rígidos quebram; quando multiplicados pelo número de clusters que operamos globalmente, esses números tornam-se um tanto impressionantes. Portanto, queremos abstrair esses problemas dos usuários, e as equipes que executam nossos serviços da mesma forma não querem ser incomodadas por falhas de hardware. Cada campus do datacenter tem equipes dedicadas à manutenção do hardware e da infraestrutura do datacenter.
Gerenciando Máquinas
O Borg, como mostra a figura abaixo, é um sistema operacional de cluster distribuído, semelhante ao Apache Mesos. Alguns leitores podem estar mais familiarizados com o descendente do Borg, o Kubernetes – um framework de orquestração de cluster de container em código aberto iniciado pelo Google em 2014. Ele gerencia seus trabalhos em nível de cluster.
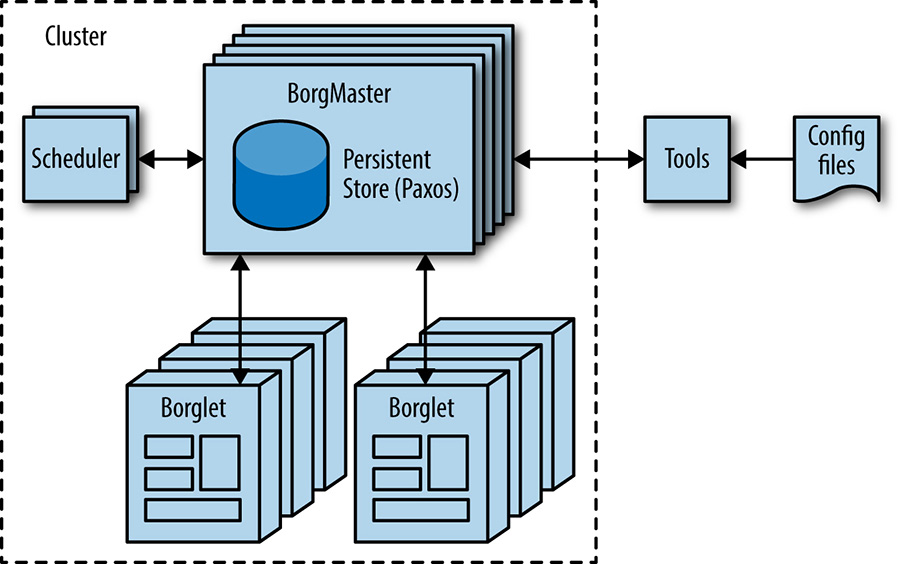
O Borg é responsável por executar jobs de usuários, que podem ser servidores executando indefinidamente ou processos em lote como um MapReduce. Os jobs podem consistir em mais de uma (e às vezes milhares) de tarefas idênticas, tanto por razões de confiabilidade, quanto porque um único processo geralmente não pode lidar com todo o tráfego do cluster. Quando o Borg inicia um job, ele encontra as máquinas para as tarefas e as instrui a iniciar o programa no servidor. O Borg então monitora continuamente essas tarefas. Se uma tarefa não funcionar corretamente, ela será eliminada e reiniciada, possivelmente em uma máquina diferente.
Como as tarefas são alocadas com fluidez nas máquinas, não podemos simplesmente contar com endereços IP e números de porta para nos referirmos a elas. Resolvemos esse problema com um nível extra de indireção: ao iniciar um job, o Borg aloca um nome e um número de índice para cada tarefa usando o Borg Naming Service (BNS). Em vez de usar o endereço IP e o número da porta, outros processos se conectam às tarefas do Borg por meio do nome BNS, que é traduzido em um endereço IP e número de porta pelo BNS. Por exemplo, o caminho BNS pode ser uma string como /bns/<cluster>/<user>/<jobname>/<task number>, que resolveria para <IP address>:<port>.
O Borg também é responsável pela alocação de recursos para os jobs. Cada job precisa especificar os recursos necessários (por exemplo, 3 núcleos de CPU, 2 GiB de RAM). Usando a lista de requisitos para todos os trabalhos, o Borg pode empacotar as tarefas nas máquinas de uma maneira ideal que também contabiliza falhas de domínio (por exemplo: o Borg não executará todas as tarefas de um job no mesmo rack, pois isso significa que a parte superior do switch do rack é um ponto único de falha para esse job).
Se uma tarefa tentar usar mais recursos do que o solicitado, o Borg elimina a tarefa e a reinicia (já que uma tarefa de travamento lento geralmente é preferível a uma tarefa que ainda não foi reiniciada).
Armazenamento
As tarefas podem usar o disco local nas máquinas como um bloco de rascunho, mas temos várias opções em cluster para armazenamento permanente (e até mesmo o espaço de rascunho eventualmente mudará para o modelo de armazenamento em cluster). Eles são comparáveis ao Lustre e ao Hadoop Distributed File System (HDFS), ambos sistemas de arquivos de cluster de código aberto.
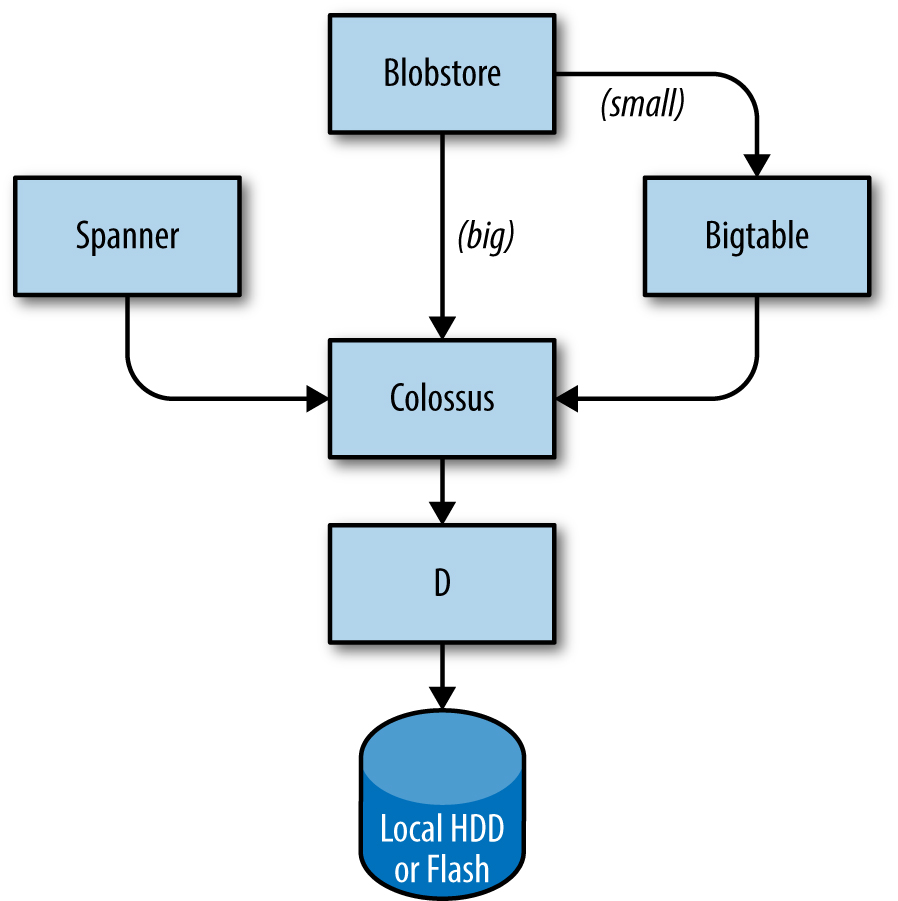
A camada de armazenamento é responsável por oferecer aos usuários acesso fácil e confiável ao armazenamento disponível para um cluster. Conforme mostrado na figura abaixo, o armazenamento tem muitas camadas:
- A camada mais baixa é chamada de D (de disco, embora D use discos giratórios e armazenamento flash). D é um servidor de arquivos em execução em quase todas as máquinas de um cluster. No entanto, os usuários que desejam acessar seus dados não querem ter que lembrar qual máquina está armazenando seus dados, que é onde a próxima camada entra em jogo.
- Uma camada no topo de D chamada Colossus cria um sistema de arquivos em todo o cluster que oferece semântica de sistema de arquivos usual, bem como replicação e criptografia. Colossus é o sucessor do GFS, o Google File System.
- Existem vários serviços semelhantes a banco de dados construídos em cima do Colossus:
- Bigtable é um sistema de banco de dados NoSQL que pode manipular bancos com petabytes de dados. Um Bigtable é um mapa classificado multidimensional esparso, distribuído e persistente que é indexado por chave de linha, chave de coluna e registro de data e hora; cada valor no mapa é uma matriz não interpretada de bytes. O Bigtable oferece suporte à replicação eventualmente consistente entre datacenters
- O Spanner oferece uma interface semelhante ao SQL para usuários que exigem consistência real no mundo todo.
- Vários outros sistemas de banco de dados estão disponíveis, como o Blobstore. Cada uma dessas opções vem com seu próprio conjunto de compensações (acesse “Data Integrity: What You Read Is What You Wrote, para mais informações)
Networking
O hardware de rede do Google é controlado de várias maneiras. Conforme discutido anteriormente, usamos uma rede definida por software baseada em OpenFlow. Em vez de usar hardware de roteamento “inteligente”, contamos com componentes de comutação “burros” mais baratos, em combinação com um controlador central (duplicado) que pré-computa os melhores caminhos na rede. Portanto, somos capazes de mover as decisões de roteamento dispendiosas de computação para longe dos roteadores e usar hardware de comutação simples.
A largura de banda da rede precisa ser alocada com sabedoria. Assim como o Borg limita os recursos de computação que uma tarefa pode usar, o Bandwidth Enforcer (BwE) gerencia a largura de banda para maximizar a largura de banda média disponível. A otimização da largura de banda não envolve apenas custos: a engenharia de tráfego centralizada demonstrou resolver uma série de problemas que são, tradicionalmente, extremamente difíceis de resolver por meio de uma combinação de roteamento distribuído e engenharia de tráfego.
Alguns serviços possuem jobs em execução em vários clusters que são distribuídos em todo o mundo. Para minimizar a latência para serviços distribuídos globalmente, queremos direcionar os usuários ao datacenter mais próximo com capacidade disponível. Nosso Global Software Load Balancer (GSLB) executa o balanceamento de carga em três níveis:
- Balanceamento de carga geográfica para solicitações de DNS (por exemplo, para www.google.com), descrito em Balanceamento de carga no front-end
- Balanceamento de carga em nível de serviço do usuário (por exemplo, YouTube ou Google Maps)
- Balanceamento de carga em nível de Chamada de Procedimento Remoto (RPC), descrito em Balanceamento de carga no Datacenter
Proprietários de serviço especificam um nome simbólico para os mesmos, uma lista de endereços de servidores BNS e a capacidade disponível em cada um dos locais (normalmente medida em consultas por segundo). O GSLB então direciona o tráfego para os endereços BNS.
Outro software de sistema
Vários outros componentes em um datacenter também são importantes.
Serviço de bloqueio
O serviço de bloqueio Chubby fornece uma API semelhante a um sistema de arquivos para manter os bloqueios. Chubby lida com esses bloqueios em locais de datacenter. Ele usa o protocolo Paxos para consenso assíncrono (veja Gerenciando estado crítico: consenso distribuído para confiabilidade).
Chubby também desempenha um papel importante na eleição do mestre. Quando um serviço tem cinco replicas de um job em execução para fins de confiabilidade, mas apenas uma replica pode executar o trabalho real, o Chubby é usado para selecionar qual replica pode prosseguir.
Os dados que devem ser consistentes são adequados para armazenamento no Chubby. Por esse motivo, o BNS usa o Chubby para armazenar o mapeamento entre os caminhos do BNS e os pares IP address:port.
Monitoramento e Alerta
Queremos ter certeza de que todos os serviços estão sendo executados conforme necessário. Portanto, executamos muitas instâncias de nosso programa de monitoramento Borgmon (veja Alerta Prático de Dados de Séries Temporais). O Borgmon regularmente “extrai” as métricas dos servidores monitorados. Essas métricas podem ser usadas instantaneamente para alertar e também armazenadas para uso em visões gerais históricas (por exemplo, gráficos). Podemos usar o monitoramento de várias maneiras:
- Configurar alertas para problemas críticos
- Comparar o comportamento: uma atualização de software tornou o servidor mais rápido?
- Examinar como o comportamento de consumo de recursos evolui ao longo do tempo, o que é essencial para o planejamento da capacidade
Nossa infraestrutura de software
Nossa arquitetura de software é projetada para fazer o uso mais eficiente da nossa infraestrutura de hardware. Nosso código é altamente multithread, então uma tarefa pode facilmente usar muitos núcleos. Para facilitar os painéis, o monitoramento e o debug, cada servidor possui um servidor HTTP que fornece diagnósticos e estatísticas para uma determinada tarefa.
Todos os serviços do Google se comunicam usando uma infraestrutura de Chamada de Procedimento Remoto (RPC) chamada Stubby; uma versão gRPC, de código aberto, também está disponível. Frequentemente, uma chamada RPC é feita mesmo quando uma chamada para uma subrotina no programa local precisa ser executada. Isso torna mais fácil refatorar a chamada em um servidor diferente se mais modularidade for necessária, ou quando a base de código de um servidor aumentar. O GSLB pode balancear a carga de RPCs da mesma forma que faz o balanceamento de carga de serviços visíveis externamente.
Um servidor recebe solicitações RPC de seu frontend e envia RPCs para seu back-end. Em termos tradicionais, o front-end é chamado de cliente e o back-end é chamado de servidor.
Os dados são transferidos de/para um RPC usando buffers de protocolo, muitas vezes abreviados para “protobufs”, que são semelhantes ao Thrift do Apache. Os buffers de protocolo são mecanismos extensíveis de linguagem e plataforma neutros usados para serializar dados estruturados. Buffers de protocolo têm muitas vantagens sobre XML para serializar dados estruturados: são mais simples de usar, de 3 a 10 vezes menores, e de 20 a 100 vezes mais rápidos e menos ambíguos.
Nosso Ambiente de Desenvolvimento
A velocidade de desenvolvimento é muito importante para o Google, então criamos um ambiente de desenvolvimento completo para usar nossa infraestrutura.
Além de alguns grupos que têm seus próprios repositórios de código aberto (por exemplo, Android e Chrome), os engenheiros de software do Google trabalham a partir de um único repositório compartilhado. Isso tem algumas implicações práticas importantes para nossos fluxos de trabalho:
- Se os engenheiros encontrarem um problema em um componente fora do projeto, eles podem corrigir o problema, enviar as alterações propostas (“changelist” ou CL) ao proprietário para revisão e enviar o CL para a linha principal.
- Mudanças no código-fonte em um projeto do próprio engenheiro exigem uma revisão. Todo o software é revisado antes de ser enviado.
Quando o software é construído, a solicitação de construção é enviada para construir servidores em um datacenter. Mesmo grandes compilações são executadas rapidamente, já que muitos servidores podem compilar em paralelo. Essa infraestrutura também é usada para testes contínuos. Cada vez que um CL é enviado, os testes são executados em todos os softwares que podem depender desse CL, direta ou indiretamente. Se o framework determinar que a mudança provavelmente quebrou outras partes do sistema, ele notificará o proprietário da alteração enviada. Alguns projetos usam um sistema push-on-green, em que uma nova versão é automaticamente colocada em produção após passar nos testes.
Shakespeare: um serviço de exemplo
Para fornecer um modelo de como um serviço seria hipoteticamente implantado no ambiente de produção do Google, vejamos um exemplo de serviço que interage com várias tecnologias do Google. Suponha que queremos oferecer um serviço que permite determinar onde uma palavra específica é usada nas obras de Shakespeare.
Podemos dividir o sistema em duas partes:
- Um componente batch que lê todos os textos de Shakespeare, cria um index e grava o index em uma Bigtable. Esse job só precisa ser executado uma vez, ou talvez muito raramente (você nunca sabe se um novo texto pode ser descoberto a qualquer momento).
- Um front-end de aplicação que lida com as solicitações do usuário final. Esse job está sempre ativo, pois os usuários em todos os fusos horários vão querer pesquisar nos livros de Shakespeare.
O componente batch é um MapReduce que compreende três fases.
A fase de mapeamento lê os textos de Shakespeare e os divide em palavras individuais.
Isso é mais rápido se executado em paralelo por vários trabalhadores.
A fase de embaralhamento classifica as tuplas por palavra.
Na fase de redução, uma tupla de (palavra, lista de locais) é criada.
Cada tupla é gravada em uma linha em uma Bigtable, usando a palavra como chave.
O ciclo de vida de uma requisição
A figura abaixo mostra como a solicitação de um usuário é atendida: primeiro, o usuário aponta seu navegador para shakespeare.google.com. Para obter o endereço IP correspondente, o dispositivo do usuário resolve o endereço com seu servidor DNS (1). Essa solicitação acaba no servidor DNS do Google, que se comunica com o GSLB. Como o GSLB rastreia a carga de tráfego entre os servidores front-end nas regiões, ele escolhe qual endereço IP do servidor enviar para esse usuário.
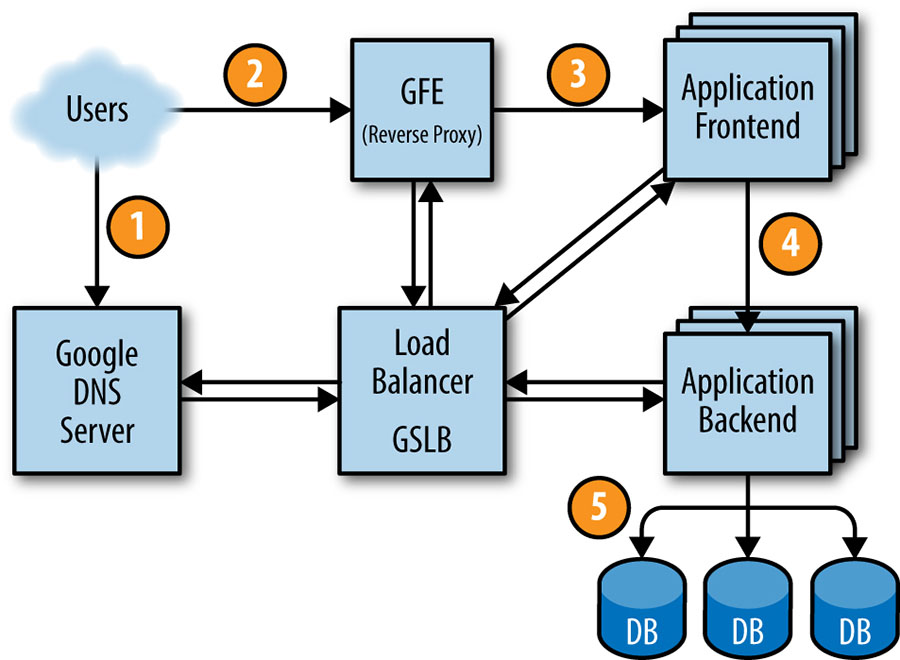
O navegador se conecta ao servidor HTTP neste IP. Este servidor (denominado Google Frontend ou GFE) é um proxy reverso que encerra a conexão TCP (2). O GFE procura qual serviço é necessário (pesquisa na web, mapas ou, neste caso, Shakespeare). Novamente usando GSLB, o servidor encontra um servidor frontend Shakespeare disponível e envia a esse servidor um RPC contendo a solicitação HTTP (3).
O servidor Shakespeare analisa a solicitação HTTP e constrói um protobuf contendo a palavra a ser pesquisada. O servidor frontend Shakespeare agora precisa entrar em contato com o servidor de backend Shakespeare: o servidor de frontend contata o GSLB para obter o endereço BNS de um servidor de backend adequado e sem carga (4). Esse servidor de backend Shakespeare agora contata um servidor Bigtable para obter os dados solicitados (5).
A resposta é gravada no protobuf e retornada ao servidor backend Shakespeare. O backend entrega um protobuf contendo os resultados ao servidor frontend Shakespeare, que monta o HTML e retorna a resposta ao usuário.
Toda essa cadeia de eventos é executada em um piscar de olhos – apenas algumas centenas de milissegundos! Como muitas peças móveis estão envolvidas, há muitos pontos potenciais de falha; em particular, um GSLB com falha causaria estragos. No entanto, as políticas do Google de testes rigorosos e lançamento cuidadoso, além de nossos métodos proativos de recuperação de erros, como degradação normal, nos permitem oferecer o serviço confiável que nossos usuários esperam. Afinal, as pessoas usam regularmente www.google.com para verificar se a conexão com a Internet está configurada corretamente.
Organização de jobs e dados
O teste de carga determinou que nosso servidor backend pode lidar com cerca de 100 consultas por segundo (QPS). Os testes realizados com um conjunto limitado de usuários nos levam a esperar um pico de carga de cerca de 3.470 QPS, portanto, precisamos de pelo menos 35 tarefas. No entanto, as seguintes considerações significam que precisamos de pelo menos 37 tarefas no job, ou N+2:
- Durante as atualizações, uma tarefa por vez ficará indisponível, restando 36 tarefas
- Uma falha de máquina pode ocorrer durante uma atualização de tarefa, deixando apenas 35 tarefas, apenas o suficiente para atender à carga de pico. (Assumimos que a probabilidade de duas falhas de tarefa simultâneas acontecerem em nosso ambiente é baixa o suficiente para ser insignificante. Pontos de falha únicos, como interruptores no topo do rack ou distribuição de energia, podem tornar essa suposição inválida em outros ambientes).
Um exame mais detalhado do tráfego de usuários mostra que nosso pico de uso é distribuído globalmente: 1.430 QPS da América do Norte, 290 da América do Sul, 1.400 da Europa e África e 350 da Ásia e Austrália. Em vez de localizar todos os backends em um site, nós os distribuímos nos EUA, América do Sul, Europa e Ásia. Permitir a redundância N+2 por região significa que acabamos com 17 tarefas nos EUA, 16 na Europa e 6 na Ásia. No entanto, decidimos usar 4 tarefas (em vez de 5) na América do Sul, para reduzir o overhead de N+2 para N+1. Nesse caso, estamos dispostos a tolerar um pequeno risco de latência mais alta em troca de custos de hardware mais baixos: se o GSLB redirecionar o tráfego de um continente para outro quando nosso datacenter sul-americano estiver acima da capacidade, podemos economizar 20% dos recursos que gastaríamos em hardware. Nas regiões maiores, distribuiremos as tarefas em dois ou três clusters para maior resiliência.
Como os backends precisam entrar em contato com a Bigtable que contém os dados, também precisamos projetar esse elemento de armazenamento estrategicamente. Um backend na Ásia em contato com uma Bigtable nos EUA adiciona uma quantidade significativa de latência, portanto, replicamos o Bigtable em cada região. A replicação do Bigtable nos ajuda de duas maneiras: fornece resiliência caso um servidor Bigtable falhe e reduz a latência de acesso aos dados. Embora a Bigtable apenas ofereça consistência eventual, não é um grande problema porque não precisamos atualizar o conteúdo com frequência.
Introduzimos muita terminologia aqui; embora você não precise se lembrar de tudo, é útil para entender a concepção de muitos dos outros sistemas aos quais nos referiremos mais tarde, nos próximos capítulos desse livro.
Fonte: Google SRE Boo