Escrito por Jamie Wilkinson
Editado por Kavita Guliani
“Que as consultas fluam e o pager fique em silêncio.”
Oração SRE tradicional
Monitoramento, a camada inferior da Hierarquia das Necessidades de Produção, é fundamental para a execução de um serviço estável. O monitoramento permite que os proprietários de serviço tomem decisões racionais sobre o impacto das mudanças no serviço, apliquem o método científico à resposta a incidentes e, claro, garantam sua razão de existência: medir o alinhamento de serviço com os objetivos de negócios (veja mais em Monitoramento de Sistemas Distribuídos).
Independentemente de um serviço ter ou não suporte SRE, ele deve ser executado em uma relação simbiótica com seu monitoramento. Mas, tendo sido incumbidos da responsabilidade final pela produção do Google, os SREs desenvolvem um conhecimento particularmente íntimo da infraestrutura de monitoramento que dá suporte a seus serviços.
Monitorar um sistema muito grande é desafiador por dois motivos:
- O número absoluto de componentes sendo analisados
- A necessidade de manter uma carga de manutenção razoavelmente baixa para os engenheiros responsáveis pelo sistema
Os sistemas de monitoramento do Google não medem apenas métricas simples, como o tempo médio de resposta de um servidor da web europeu sem carga; também precisamos entender a distribuição desses tempos de resposta em todos os servidores da web naquela região. Esse conhecimento nos permite identificar os fatores que contribuem para a cauda de latência.
Na escala em que nossos sistemas operam, ser alertado sobre falhas em uma única máquina é inaceitável porque esses dados são muito barulhentos para serem acionados. Em vez disso, tentamos construir sistemas robustos contra falhas nos sistemas dos quais eles dependem. Em vez de exigir o gerenciamento de muitos componentes individuais, um grande sistema deve ser projetado para agregar sinais e eliminar valores discrepantes. Precisamos de sistemas de monitoramento que nos permitam alertar para objetivos de serviço de alto nível, mas manter a granularidade para inspecionar componentes individuais conforme necessário.
Os sistemas de monitoramento do Google evoluíram ao longo de 10 anos do modelo tradicional de scripts personalizados que verificam as respostas e alertas, totalmente separados da exibição visual de tendências, para um novo paradigma. Esse novo modelo tornou a coleta de séries temporais uma função de primeira classe do sistema de monitoramento e substituiu esses scripts de verificação por uma linguagem rica para manipular séries temporais em gráficos e alertas.
O surgimento do Borgmon
Logo depois que a infraestrutura de agendamento de rotinas Borg [https://research.google/pubs/pub43438/] foi criada em 2003, um novo sistema de monitoramento – Borgmon – foi construído para complementá-la.
Monitoramento de Séries Temporais fora do Google
Este capítulo descreve a arquitetura e a interface de programação de uma ferramenta de monitoramento interno que foi fundamental para o crescimento e a confiabilidade do Google por quase 10 anos… mas como isso ajuda você, nosso caro leitor?
Nos últimos anos, o monitoramento passou por uma explosão cambriana: Riemann, Heka, Bosun e Prometheus surgiram como ferramentas de código aberto muito semelhantes aos alertas baseados em séries temporais de Borgmon. Em particular, o Prometheus (um sistema de monitoramento de código aberto e banco de dados de série temporal) compartilha muitas semelhanças com o Borgmon, especialmente quando comparamos as duas linguagens. Os princípios de coleta de variáveis e avaliação de regras permanecem os mesmos em todas essas ferramentas e fornecem um ambiente com o qual podemos experimentar e, com sorte, lançar em produção as ideias inspiradas neste capítulo.
Em vez de executar scripts personalizados para detectar falhas do sistema, o Borgmon conta com um formato de exposição de dados comum; isso permite a coleta de dados em massa com baixos custos indiretos e evita os custos de execução de subprocesso e configuração de conexão de rede. Chamamos isso de monitoramento de caixa branca (consulte o Capítulo 6 para uma comparação de monitoramento de caixa branca e caixa preta).
Os dados são usados para renderizar gráficos e criar alertas, que são realizados usando aritmética simples. Como a coleta não é mais um processo de curta duração, o histórico dos dados coletados também pode ser usado para esse cálculo de alerta.
Esses recursos ajudam a cumprir a meta de simplicidade descrita no Capítulo 6. Eles permitem que a sobrecarga do sistema seja mantida baixa para que as pessoas que executam os serviços possam permanecer ágeis e responder às mudanças contínuas no sistema conforme ele cresce.
Para facilitar a coleta em massa, o formato das métricas teve que ser padronizado. Um método mais antigo de exportar o estado interno (conhecido como varz, leia-se “var-zee”) foi formalizado para permitir a coleta de todas as métricas de um único destino em uma busca HTTP. Por exemplo, para visualizar uma página de métricas manualmente, você pode usar o seguinte comando:
% curl https://webserver:80/varz http_requests 37
errors_total 12
Um Borgmon pode coletar de outro Borgmon, para que possamos construir hierarquias que sigam a topologia do serviço, agregando e resumindo informações e descartando algumas estrategicamente em cada nível. Normalmente, uma equipe executa um único Borgmon por cluster e um par em nível global. Alguns serviços muito grandes se fragmentam abaixo do nível do cluster em muitos Borgmon raspadores, que por sua vez alimentam o Borgmon do nível do cluster.
Instrumentação de Aplicações
O manipulador HTTP /varz simplesmente lista todas as variáveis exportadas em texto simples, como chaves e valores separados por espaço, um por linha. Uma extensão posterior adicionou uma variável mapeada, que permite ao exportador definir vários rótulos em um nome de variável e, em seguida, exportar uma tabela de valores ou um histograma. Um exemplo de variável map-valued se parece conforme o código abaixo, mostrando 25 respostas HTTP 200 e 12 HTTP 500s:
http_responses map: code 200: 25 404: 0 500: 12
Adicionar uma métrica a um programa requer apenas uma única declaração no código onde a métrica é necessária.
Em retrospectiva, é aparente que esta interface textual sem esquema torna a barreira para adicionar nova instrumentação muito baixa, o que é positivo para as equipes de engenharia de software e SRE. No entanto, isso tem uma desvantagem contra a manutenção contínua; o desacoplamento da definição de variável de seu uso nas regras de Borgmon requer um gerenciamento de mudança cuidadoso. Na prática, esse trade-off tem sido satisfatório porque ferramentas para validar e gerar regras também foram escritas. (Muitas equipes não-SRE usam um gerador para eliminar o boilerplate inicial e as atualizações contínuas e consideram o gerador muito mais fácil de usar (embora menos poderoso) do que editar as regras diretamente).
Exportando variáveis
As raízes da web do Google são profundas: cada uma das principais linguagens usadas no Google tem uma implementação da interface de variável exportada que se registra automaticamente com o servidor HTTP embutido em cada binário do Google por padrão. (Muitos outros aplicativos também usam seu protocolo de serviço para exportar seu estado interno. O OpenLDAP faz a exportação através da subárvore cn=Monitor; o MySQL pode relatar o estado com uma query SHOW VARIABLES; já o Apache tem seu manipulador mod_status).
As instâncias da variável a serem exportadas permitem que o autor do servidor realize operações óbvias, como adicionar um valor ao valor atual, definir uma chave para um valor específico e assim por diante. A biblioteca Go expvar47 [https://golang.org/pkg/expvar/] e seu formato de saída JSON possuem uma variante dessa API.
Coleta de Dados Exportados
Para encontrar seus alvos, uma instância do Borgmon é configurada com uma lista de alvos usando um dos vários métodos de resolução de nome. A lista de alvos é frequentemente dinâmica, portanto, usar a descoberta de serviço reduz o custo de manutenção e permite que o monitoramento seja escalonado.
Em intervalos predefinidos, o Borgmon busca o URI /varz em cada destino, decodifica os resultados e armazena os valores na memória. O Borgmon também distribui a coleta de cada instância na lista de alvos ao longo de todo o intervalo, de forma que a coleta de cada alvo não esteja em sincronia com seus pares.
Borgmon também registra variáveis “sintéticas” para cada alvo, a fim de identificar:
- Se o nome foi resolvido para um servidor e uma porta
- Se o alvo respondeu com uma coleta
- Se o alvo respondeu a um health check
- O instante no qual a coleta foi concluída
Essas variáveis sintéticas facilitam a gravação de regras para detectar se as tarefas monitoradas estão indisponíveis.
É interessante que o varz seja bastante diferente do SNMP (Simple Network Management Protocol), que “é projetado […] para ter requisitos mínimos de transporte e continuar trabalhando quando a maioria dos outros aplicativos de rede falham” [https://technet.microsoft.com/en-us/library/cc776379%28v=ws.10%29.aspx ].
A raspagem de alvos por HTTP parece estar em desacordo com esse princípio de design; no entanto, a experiência mostra que isso raramente é um problema (veja no capítulo sobre Sistemas Distribuídos de Monitoramento, já mencionado anteriormente aqui, a distinção entre alertar sobre os sintomas e alertar sobre as causas). O próprio sistema já foi projetado para ser robusto contra falhas de rede e de máquina, e o Borgmon permite que os engenheiros escrevam regras de alerta mais inteligentes usando a própria falha de coleta como um sinal.
Armazenamento na arena de Séries Temporais
Um serviço é tipicamente composto de vários arquivos binários executando muitas tarefas, em muitas máquinas, em muitos clusters. O Borgmon precisa manter todos estes dados organizados, ao mesmo tempo em que permite a consulta e divisão flexível desses dados.
Ele também armazena todos os dados em uma base in-memory, regularmente gravada em disco. Cada ponto de dados tem o formato (timestamp, value), e estes são armazenados em listas cronológicas chamadas séries temporais, e cada série temporal é nomeada por um conjunto único de rótulos, no formato name=value.
Como apresentado na figura abaixo, uma série temporal é conceitualmente uma matriz numérica, progredindo ao longo do tempo. Conforme adicionamos permutações de rótulos a esta série temporal, a matriz se torna multidimensional.
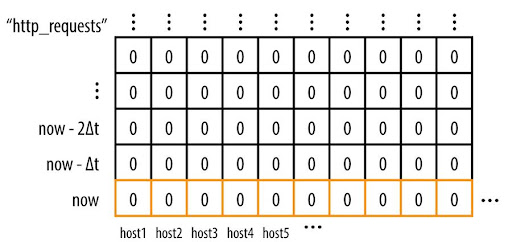
Figura 10-1. Uma série temporal para erros rotulados pelo host original, de onde cada um foi coletado
Na prática, a estrutura é um bloco de memória de tamanho fixo, conhecido como arena da série temporal, com um coletor de lixo que expira as entradas mais antigas quando a arena está cheia. O intervalo de tempo entre as entradas mais recentes e mais antigas na arena é o horizonte, que indica quantos dados consultáveis são mantidos na RAM. Tipicamente, o datacenter e o Borgmon global são dimensionados para armazenar cerca de 12 horas de dados para renderizar consoles e muito menos tempo se forem os fragmentos de coletor de nível mais baixo (este horizonte de 12 horas é um número mágico que visa ter informações suficientes para depurar um incidente na RAM para consultas rápidas sem gastar muita RAM). O requisito de memória para um único ponto de dados é de cerca de 24 bytes, portanto, podemos ajustar 1 milhão de séries temporais exclusivas por 12 horas em intervalos de 1 minuto em menos de 17 GB de RAM.
Periodicamente, o estado na memória é arquivado em um sistema externo conhecido como Time-Series Database (TSDB). O Borgmon pode consultar o TSDB em busca de dados mais antigos e, embora seja mais lento, o TSDB é mais barato e maior do que a RAM do Borgmon.
Etiquetas e vetores
Conforme mostrado no exemplo de série temporal da figura abaixo, as séries temporais são armazenadas como sequências de números e carimbos de data/hora, chamados de vetores. Como os vetores na álgebra linear, esses vetores são fatias e seções transversais da matriz multidimensional de pontos de dados na arena. Conceitualmente, os carimbos de data/hora podem ser ignorados, porque os valores são inseridos no vetor em intervalos regulares no tempo – por exemplo, 1 ou 10 segundos ou 1 minuto de intervalo.

Figura 10-2. Um exemplo de série temporal
O nome de uma série temporal é um labelset, porque é implementado como um conjunto de rótulos expresso como pares key=value. Um desses rótulos é o próprio nome da variável, a chave que aparece na página varz.
Alguns nomes de rótulos são declarados como importantes. Para que a série temporal no banco de dados de série temporal seja identificável, ela deve ter, no mínimo, os seguintes rótulos:
var
O nome da variável
job
O nome dado ao tipo de servidor que está sendo monitorado
service
Uma coleção vagamente definida de rotinas que fornecem um serviço aos usuários, sejam internos ou externos
zone
Uma convenção do Google que se refere à localização (normalmente o datacenter) do Borgmon que realizou a coleta desta variável
Juntas, essas variáveis se parecem com o código abaixo, chamado de variable expression (ou expressão variável):
{var = http_requests, job = webserver, instance = host0: 80, service = web, zone = us-west}
Uma query para uma série temporal não requer a especificação de todos esses rótulos, e uma pesquisa por um labelset retorna todas as séries temporais correspondentes em um vetor. Portanto, poderíamos retornar um vetor de resultados removendo o rótulo instance na query anterior, se houvesse mais de uma instância no cluster. Por exemplo:
{var=http_requests,job=webserver,service=web,zone=us-west}
pode ter o resultado de cinco linhas em um vetor, com o valor mais recente na série temporal representado da seguinte forma:
{var = http_requests, job = webserver, instance = host0: 80, service = web, zone = us-west} 10
{var = http_requests, job = webserver, instance = host1: 80, service = web, zone = us-west} 9
{var = http_requests, job = webserver, instance = host2: 80, service = web, zone = us-west} 11
{var = http_requests, job = webserver, instance = host3: 80, service = web, zone = us-west} 0
{var = http_requests, job = webserver, instance = host4: 80, service = web, zone = us-west} 10
Os rótulos podem ser adicionados a uma série temporal a partir de:
- O nome do alvo, por exemplo, a rotina e a instância
- O próprio destino, por exemplo, através de variáveis map-valued
- A configuração de Borgmon, por exemplo, anotações sobre localização ou reclassificação
- As regras Borgmon sendo avaliadas
Também podemos consultar séries temporais no tempo, especificando uma duração para a expressão variável:
{var = http_requests, job = webserver, service = web, zone = us-west} [10m]
Isso retorna os últimos 10 minutos de histórico da série temporal que correspondeu à expressão. Se estivéssemos coletando pontos de dados uma vez por minuto, esperaríamos retornar 10 pontos de dados em uma janela de 10 minutos, como representado abaixo. (Os rótulos service e zone são omitidos aqui por questão de espaço, mas estão presentes na expressão retornada).
{var=http_requests,job=webserver,instance=host0:80, …} 0 1 2 3 4 5 6 7 8 9 10
{var=http_requests,job=webserver,instance=host1:80, …} 0 1 2 3 4 4 5 6 7 8 9
{var=http_requests,job=webserver,instance=host2:80, …} 0 1 2 3 5 6 7 8 9 9 11
{var=http_requests,job=webserver,instance=host3:80, …} 0 0 0 0 0 0 0 0 0 0 0
{var=http_requests,job=webserver,instance=host4:80, …} 0 1 2 3 4 5 6 7 8 9 10
Avaliação de regra
O Borgmon é na verdade apenas uma calculadora programável, com algum açúcar sintático que permite gerar alertas. Os componentes de coleta e armazenamento de dados já descritos são apenas males necessários para tornar essa calculadora programável e, em última análise, adequada para o propósito aqui como um sistema de monitoramento. 🙂
Observação
Centralizar a avaliação da regra em um sistema de monitoramento, em vez de delegá-la a subprocessos bifurcados (fork), significa que os cálculos podem ser executados em paralelo em muitos destinos semelhantes. Essa prática mantém a configuração relativamente pequena em tamanho (por exemplo, removendo a duplicação de código) ainda mais poderosa por meio de sua expressividade.
O código do programa Borgmon, também conhecido como Borgmon rules (ou regras de Borgmon), consiste em expressões algébricas simples que calculam séries temporais de outras séries temporais. Essas regras podem ser bastante poderosas porque podem consultar o histórico de uma única série temporal (ou seja, o eixo do tempo), consultar diferentes subconjuntos de rótulos de várias séries temporais de uma vez (ou seja, o eixo espacial) e aplicar muitas operações matemáticas.
As regras são executadas em um threadpool paralelo onde é possível, mas dependem da ordem ao usar regras definidas anteriormente como entrada. O tamanho dos vetores retornados por suas expressões de query também determina o tempo de execução geral de uma regra. Portanto, normalmente, é possível adicionar recursos da CPU a uma tarefa do Borgmon em resposta à sua lentidão. Para auxiliar na análise mais detalhada, métricas internas sobre o tempo de execução das regras são exportadas para o debug de desempenho e para monitorar o monitoramento.
A agregação é a base da avaliação de regras em um ambiente distribuído. A agregação envolve obter a soma de um conjunto de séries temporais das tarefas em uma rotina para tratar a rotina como um todo. A partir dessas somas, as taxas gerais podem ser calculadas. Por exemplo, a taxa total de queries por segundo de uma rotina em um datacenter é a soma de todas as taxas de alteração de todos os contadores de query. (Calcular a soma das taxas em vez da taxa das somas protege o resultado contra redefinições do contador ou dados ausentes, talvez devido a uma reinicialização da tarefa ou falha na coleta de dados. Apesar de não serem tipificados, a maioria dos varz são contadores simples. A função de Borgmon lida com todos os casos extremos de redefinições de contador).
Dica
Um contador é qualquer variável monotonicamente não decrescente – ou seja, os contadores apenas aumentam de valor. Os medidores, por outro lado, podem assumir qualquer valor que desejarem. Os contadores medem valores crescentes, como o número total de quilômetros rodados, enquanto os medidores mostram o estado atual, como a quantidade de combustível restante ou a velocidade atual. Ao coletar dados no estilo Borgmon, é melhor usar contadores, porque eles não perdem o significado quando os eventos ocorrem entre os intervalos de amostragem. Caso alguma atividade ou mudança ocorra entre os intervalos de amostragem, uma coleção de medidores provavelmente perderá essa atividade.
Para um servidor web de exemplo, podemos querer alertar quando nosso cluster de servidor web começa a servir mais erros, como uma porcentagem de solicitações do que pensamos ser normal – ou, mais tecnicamente, quando a soma das taxas de códigos de retorno non-HTTP-200 em todas as tarefas no cluster, dividida pela soma das taxas de solicitações para todas as tarefas neste cluster, é maior do que algum valor.
Isso é realizado quando:
- Agregamos as taxas de códigos de resposta em todas as tarefas, gerando um vetor de taxas naquele momento, uma para cada código
- Calculamos a taxa de erro total como a soma desse vetor, gerando um único valor para o cluster naquele momento. Essa taxa de erro total exclui o código 200 da soma, porque não é um erro.
- Calculamos a proporção de erros para solicitações em todo o cluster, dividindo a taxa de erro total pela taxa de solicitações que chegaram e, novamente, gerando um único valor para o cluster naquele momento.
Cada uma dessas saídas em um determinado momento é anexada à sua expressão de variável nomeada, que cria a nova série temporal. Como resultado, seremos capazes de inspecionar o histórico das taxas de erro e também as taxas de erro, em outro momento.
As regras da taxa de solicitações seriam escritas conforme as regras da linguagem Borgmon, da seguinte forma:
rules <<<
# Compute the rate of requests for each task from the count of requests
{var=task:http_requests:rate10m,job=webserver} =
rate({var=http_requests,job=webserver}[10m]);
# Sum the rates to get the aggregate rate of queries for the cluster;
# ‘without instance’ instructs Borgmon to remove the instance label
# from the right hand side.
{var=dc:http_requests:rate10m,job=webserver} =
sum without instance({var=task:http_requests:rate10m,job=webserver})
>>>
A função rate() pega a expressão incluída e retorna o delta total dividido pelo tempo total entre os valores mais antigos e os mais recentes.
Com os dados de série temporal de exemplo da query anterior, os resultados para a regra task:http_requests:rate10m se pareceriam com o seguinte:
{var=task:http_requests:rate10m,job=webserver,instance=host0:80, …} 1
{var=task:http_requests:rate10m,job=webserver,instance=host1:80, …} 0.9
{var=task:http_requests:rate10m,job=webserver,instance=host2:80, …} 1.1
{var=task:http_requests:rate10m,job=webserver,instance=host3:80, …} 0
{var=task:http_requests:rate10m,job=webserver,instance=host4:80, …} 1
e os resultados para a regra dc:http_requests:rate10m rule seriam:
{var=dc:http_requests:rate10m,job=webserver,service=web,zone=us-west} 4
porque a segunda regra usa a primeira como entrada.
Observação
O rótulo instance está faltando na saída agora, descartado pela regra de agregação. Se tivesse permanecido na regra, o Borgmon não teria sido capaz de somar as cinco linhas.
Nestes exemplos, usamos uma janela de tempo porque estamos lidando com pontos discretos na série temporal, em oposição a funções contínuas. Isso torna o cálculo da taxa mais fácil do que performar o cálculo, mas significa que, para calcular uma taxa, precisamos selecionar um número suficiente de pontos de dados. Também temos que lidar com a possibilidade de que algumas coleções recentes tenham falhado. Lembre-se de que a notação de expressão da variável histórica usa o intervalo [10m] para evitar pontos de dados perdidos causados por erros de coleção.
O exemplo também usa uma convenção do Google que ajuda na legibilidade. Cada nome de variável calculado contém um trio separado por dois pontos indicando o nível de agregação, o nome da variável e a operação que criou esse nome. Neste exemplo, as variáveis do lado esquerdo são “tarefa HTTP solicita taxa de 10 minutos” (“task HTTP requests 10-minute rate”) e “datacenter HTTP solicita taxa de 10 minutos” (“datacenter HTTP requests 10-minute rate”).
Agora que sabemos como criar uma taxa de queries, podemos construir sobre isso para calcular também uma taxa de erros e, então, podemos calcular a proporção de respostas para solicitações para entender quanto trabalho útil o serviço está realizando. Podemos comparar a taxa de proporção de erros com nosso objetivo de nível de serviço (consulte Capítulo 4 para detalhamento sobre o tema) e alertar se este objetivo foi perdido ou está em risco de ser perdido:
rules <<<
# Compute a rate pertask and per ‘code’ label
{var=task:http_responses:rate10m,job=webserver} =
rate by code({var=http_responses,job=webserver}[10m]);
# Compute a cluster level response rate per ‘code’ label
{var=dc:http_responses:rate10m,job=webserver} =
sum without instance({var=task:http_responses:rate10m,job=webserver});
# Compute a new cluster level rate summing all non 200 codes
{var=dc:http_errors:rate10m,job=webserver} =
sum without code({var=dc:http_responses:rate10m,job=webserver,code=!/200/});
# Compute the ratio of the rate of errors to the rate of requests
{var=dc:http_errors:ratio_rate10m,job=webserver} =
{var=dc:http_errors:rate10m,job=webserver}
/
{var=dc:http_requests:rate10m,job=webserver};
>>>
Novamente, esse cálculo demonstra a convenção de empregar o sufixo no novo nome da variável de série temporal com a operação que o criou. Esse resultado é lido como “datacenter HTTP errors 10 minute ratio of rates” (“taxa de taxas de 10 minutos de erros de HTTP do datacenter”).
A saída dessas regras pode ser semelhante a:
{var=task:http_responses:rate10m,job=webserver}
{var=task:http_responses:rate10m,job=webserver,code=200,instance=host0:80, …} 1
{var=task:http_responses:rate10m,job=webserver,code=500,instance=host0:80, …} 0
{var=task:http_responses:rate10m,job=webserver,code=200,instance=host1:80, …} 0.5
{var=task:http_responses:rate10m,job=webserver,code=500,instance=host1:80, …} 0.4
{var=task:http_responses:rate10m,job=webserver,code=200,instance=host2:80, …} 1
{var=task:http_responses:rate10m,job=webserver,code=500,instance=host2:80, …} 0.1
{var=task:http_responses:rate10m,job=webserver,code=200,instance=host3:80, …} 0
{var=task:http_responses:rate10m,job=webserver,code=500,instance=host3:80, …} 0
{var=task:http_responses:rate10m,job=webserver,code=200,instance=host4:80, …} 0.9
{var=task:http_responses:rate10m,job=webserver,code=500,instance=host4:80, …} 0.1
{var=dc:http_responses:rate10m,job=webserver}
{var=dc:http_responses:rate10m,job=webserver,code=200, …} 3.4
{var=dc:http_responses:rate10m,job=webserver,code=500, …} 0.6
{var=dc:http_responses:rate10m,job=webserver,code=!/200/}
{var=dc:http_responses:rate10m,job=webserver,code=500, …} 0.6
{var=dc:http_errors:rate10m,job=webserver}
{var=dc:http_errors:rate10m,job=webserver, …} 0.6
{var=dc:http_errors:ratio_rate10m,job=webserver}
{var=dc:http_errors:ratio_rate10m,job=webserver} 0.15
Observação
A saída anterior mostra a query intermediária na regra dc: http_errors: rate10m que filtra os códigos de erro diferentes de 200. Embora o valor das expressões seja o mesmo, observe que o rótulo do código é retido em uma, mas removido da outra.
Como mencionado anteriormente, as regras de Borgmon criam novas séries temporais, de modo que os resultados dos cálculos são mantidos na arena da série temporal e podem ser inspecionados da mesma forma que as séries temporais de origem. A capacidade de fazer isso permite queries ad hoc , avaliação e exploração, como tabelas ou gráficos. Este é um recurso útil para debug durante a chamada e, se essas consultas ad hoc se mostrarem úteis, podem ser feitas visualizações permanentes em um console de serviço.
Alerta
Quando uma regra de alerta é avaliada por um Borgmon, o resultado é verdadeiro, caso em que o alerta é acionado, ou falso. A experiência mostra que os alertas podem “bater” (alternar seu estado rapidamente); portanto, as regras permitem uma duração mínima durante a qual a regra de alerta deve ser verdadeira antes que o alerta seja enviado. Tipicamente, essa duração é definida para pelo menos dois ciclos de avaliação de regra para garantir que nenhuma coleção perdida cause um alerta falso.
O exemplo a seguir cria um alerta quando a taxa de erro em 10 minutos excede 1% e o número total de erros excede 1 por segundo
rules <<<
{var=dc:http_errors:ratio_rate10m,job=webserver} > 0.01
and by job, error
{var=dc:http_errors:rate10m,job=webserver} > 1
for 2m
=> ErrorRatioTooHigh
details “webserver error ratio at %trigger_value%”
labels { severity=page };
>>>
Nosso exemplo mantém a taxa de razão em 0,15, que está bem acima do limite de 0,01 na regra de alerta. No entanto, o número de erros não é maior que 1 neste momento, então o alerta não estará ativo. Quando o número de erros ultrapassar 1, o alerta ficará pendente por dois minutos para garantir que não seja um estado transitório e só então será disparado.
A regra de alerta contém um pequeno modelo para preencher uma mensagem contendo informações contextuais: a qual rotina o alerta se destina, o nome do alerta, o valor numérico da regra de acionamento e assim por diante. As informações contextuais são preenchidas pelo Borgmon quando o alerta dispara e é enviado no RPC de Alerta.
O Borgmon está conectado a um serviço executado centralmente, conhecido como Alertmanager, que recebe RPCs de alerta quando a regra é acionada pela primeira vez e, novamente, quando o alerta é considerado “disparado”. O Alertmanager é responsável por rotear a notificação de alerta para o destino correto. O Alertmanager pode ser configurado para fazer o seguinte:
- Inibir certos alertas quando outros estão ativos
- Eliminar a duplicação de alertas de vários Borgmon que tenham os mesmos labelsets (conjuntos de rótulos)
- Alertas fan-in ou fan-out com base em seus labelsets quando vários alertas com labelsets semelhantes disparam
Conforme descrito em Monitorando sistemas distribuídos, as equipes enviam seus alertas críticos e seus alertas importantes, mas subcríticos, para suas filas de tickets. Todos os outros alertas devem ser retidos como dados informativos para painéis de status.
Um guia mais abrangente para o design de alertas pode ser encontrado em Objetivos de nível de serviço.
Fragmentando a topologia de monitoramento
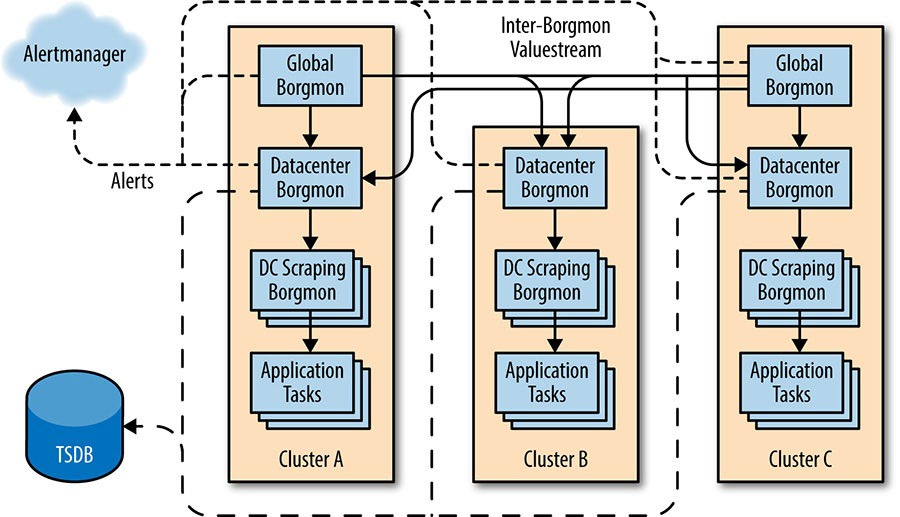
Um Borgmon também pode importar dados de série temporal de outro Borgmon. Embora seja possível tentar coletar de todas as tarefas em um serviço globalmente, fazer isso rapidamente se torna um gargalo de escala e introduz um único ponto de falha no design. Em vez disso, um protocolo de streaming é usado para transmitir dados de série temporal entre o Borgmon, economizando tempo de CPU e bytes de rede em comparação com o formato varz baseado em texto. Uma implantação típica usa dois ou mais Borgmon globais para agregação de nível superior e um Borgmon em cada datacenter para monitorar todos os trabalhos em execução naquele local. (O Google divide a rede de produção em zonas para mudanças de produção, portanto, ter duas ou mais réplicas globais fornece diversidade em face da manutenção e interrupções para esse ponto único de falha).
Conforme mostrado na figura abaixo, implantações mais complicadas fragmentam o datacenter Borgmon ainda mais em uma camada puramente de raspagem (muitas vezes devido a restrições de RAM e CPU em um único Borgmon para serviços muito grandes) e uma camada de agregação DC que realiza principalmente avaliação de regras para agregação. Às vezes, a camada global é dividida entre avaliação de regra e painel. O Borgmon de nível superior pode filtrar os dados que deseja transmitir do Borgmon de nível inferior, de modo que o Borgmon global não preencha sua arena com todas as séries temporais por tarefa dos níveis inferiores. Assim, a hierarquia de agregação constrói caches locais de séries temporais relevantes que podem ser aprofundadas quando necessário.
Monitoramento de caixa preta
O Borgmon é um sistema de monitoramento de caixa branca – ele inspeciona o estado interno do serviço de destino e as regras são escritas com o conhecimento dos internos em mente. A natureza transparente desse modelo fornece grande poder para identificar rapidamente quais componentes estão falhando, quais filas estão cheias e onde ocorrem gargalos, tanto ao responder a um incidente quanto ao testar a implantação de um novo recurso.
No entanto, o monitoramento de caixa branca não fornece uma imagem completa do sistema que está sendo monitorado; depender apenas do monitoramento de caixa branca significa que você não está ciente do que os usuários veem. Você só vê as queries que chegam ao destino; as queries que nunca chegam devido a um erro de DNS são invisíveis, enquanto as queries perdidas devido a um travamento do servidor nunca fazem barulho. Você só pode alertar sobre as falhas que já esperadas.
As equipes do Google resolvem esse problema de cobertura com o Prober, que executa uma verificação de protocolo em um alvo e relata sucesso ou falha. O prober pode enviar alertas diretamente para Alertmanager, ou seu próprio varz pode ser coletado por um Borgmon. O Prober pode validar a carga útil da resposta do protocolo (por exemplo, o conteúdo HTML de uma resposta HTTP) e validar se o conteúdo é esperado e até mesmo extrair e exportar valores como séries temporais. As equipes costumam usar o Prober para exportar histogramas de tempos de resposta por tipo de operação e tamanho da carga útil para que possam dividir e cortar o desempenho visível ao usuário. Prober é um híbrido do modelo de verificação e teste com alguma extração de variável mais rica para criar séries temporais.
O Prober pode ser apontado para o domínio de frontend ou atrás do balanceador de carga. Usando ambos os alvos, podemos detectar falhas localizadas e suprimir alertas. Por exemplo, podemos monitorar a carga balanceada www.google.com e os servidores da web em cada datacenter por trás do balanceador de carga. Essa configuração nos permite saber se o tráfego ainda é servido quando um datacenter falha ou isolar rapidamente uma borda no gráfico de fluxo de tráfego onde ocorreu uma falha.
Mantendo a configuração
A configuração do Borgmon separa a definição das regras dos destinos monitorados. Isso significa que os mesmos conjuntos de regras podem ser aplicados a muitos destinos ao mesmo tempo, em vez de escrever configurações quase idênticas repetidamente. Essa separação de interesses pode parecer acidental, mas reduz muito o custo de manutenção do monitoramento, evitando muitas repetições na descrição dos sistemas de destino.
O Borgmon também oferece suporte a modelos de linguagem. Esse sistema, semelhante a uma macro, permite que os engenheiros construam bibliotecas de regras que podem ser reutilizadas. Essa funcionalidade reduz novamente a repetição, reduzindo assim a probabilidade de bugs na configuração.
Obviamente, qualquer ambiente de programação de alto nível cria oportunidade para a complexidade, então o Borgmon fornece uma maneira de construir testes de unidade e regressão extensos, sintetizando dados de série temporal, a fim de garantir que as regras se comportem como o autor pensa que o fazem. A equipe de Monitoramento de Produção executa um serviço de integração contínua que executa uma suite desses testes, empacota a configuração e a envia para todos os Borgmon em produção, que então validam a configuração antes de aceitá-la.
Na vasta biblioteca de templates comuns que foram criados, surgiram duas classes de configuração de monitoramento. A primeira classe simplesmente codifica o esquema emergente de variáveis exportadas de uma determinada biblioteca de código, de forma que qualquer usuário da biblioteca possa reutilizar o modelo de seu varz. Esses templates existem para a biblioteca do servidor HTTP, alocação de memória, biblioteca de armazenamento de cliente e serviços RPC genéricos, entre outros. (Embora a interface varz não declare nenhum schema, a biblioteca de regras associada à biblioteca de códigos acaba declarando um schema).
A segunda classe de biblioteca surgiu à medida que construímos templates para gerenciar a agregação de dados de uma tarefa de servidor único para a área de cobertura do serviço global. Essas bibliotecas contêm regras de agregação genéricas para variáveis exportadas que os engenheiros podem usar para modelar a topologia de seu serviço.
Por exemplo, um serviço pode fornecer uma única API global, mas estar hospedado em muitos datacenters. Dentro de cada datacenter, o serviço é composto de vários shards, e cada shard é composto por várias rotinas com vários números de tarefas. Um engenheiro pode modelar essa divisão com regras Borgmon para que, durante o debug, os subcomponentes possam ser isolados do resto do sistema. Esses agrupamentos geralmente seguem o destino compartilhado de componentes; por exemplo, tarefas individuais compartilham o destino devido aos arquivos de configuração, as rotinas em um shard compartilham o destino porque estão hospedadas no mesmo datacenter e os locais físicos compartilham o destino devido à rede.
As convenções de rotulagem tornam essa divisão possível: um Borgmon adiciona rótulos indicando o nome da instância do destino e o shard e datacenter que ocupa, que podem ser usados para agrupar e agregar essas séries temporais.
Assim, temos vários usos para rótulos em uma série temporal, embora todos sejam intercambiáveis:
- Rótulos que definem detalhamentos dos próprios dados (por exemplo, nosso código de resposta HTTP na variável http_responses)
- Rótulos que definem a fonte dos dados (por exemplo, a instância ou o nome da rotina)
- Rótulos que indicam a localidade ou agregação dos dados dentro do serviço como um todo (por exemplo, o rótulo da zona descrevendo um local físico, um rótulo de shard que descreve um agrupamento lógico de tarefas)
- A natureza modelada dessas bibliotecas permite flexibilidade em seu uso. O mesmo template pode ser usado para agregação a partir de cada camada.
Dez anos depois…
O Borgmon transpôs o modelo de verificação e alerta por destino em uma coleção de variáveis em massa e uma avaliação de regra centralizada em toda a série temporal para alertas e diagnósticos.
Esse desacoplamento permite que o tamanho do sistema que está sendo monitorado seja dimensionado independentemente do tamanho das regras de alerta. Essas regras custam menos para manter porque são abstraídas em um formato de série temporal comum. Novas aplicações vêm prontas com exportações de métricas em todos os componentes e bibliotecas aos quais se vinculam, além de templates de agregação e console bastante utilizados, o que reduz ainda mais a carga de implementação.
Garantir que o custo de manutenção seja escalonado sublinearmente com o tamanho do serviço é a chave para tornar o monitoramento sustentável (e todas as operações de sustentação funcionarem). Este tema é recorrente em todos os trabalhos SRE, já que os SREs trabalham para dimensionar todos os aspectos de seu trabalho em uma escala global.
No entanto, dez anos é muito tempo e, é claro, hoje a forma do cenário de monitoramento dentro do Google evoluiu com experimentos e mudanças, buscando a melhoria contínua à medida que a empresa cresce.
Mesmo que o Borgmon permaneça interno no Google, a ideia de tratar dados de série temporal como uma fonte de dados para gerar alertas agora está acessível a todos através de ferramentas de código aberto, tais como: Prometheus, Riemann, Heka e Bosun , e provavelmente até outras mais enquanto você lê este texto.