Capítulo 7: A evolução da automação no Google
Escrito por Niall Murphy com John Looney e Michael Kacirek
Editado por Betsy Beyer
“Além da arte negra, existe apenas automação e mecanização.”
Federico García Lorca (1898–1936), poeta e dramaturgo espanhol
Para SRE, a automação é um multiplicador de força, não uma panaceia. É claro que apenas multiplicar a força não muda naturalmente a precisão de onde essa força é aplicada: fazer a automação sem pensar pode criar tantos problemas quanto aqueles que ela se propõe a resolver. Portanto, embora acreditemos que a automação baseada em software seja superior à operação manual na maioria das circunstâncias, melhor do que qualquer uma das opções é um projeto de sistema de nível superior que não requer nenhum deles – um sistema autônomo. Ou, em outras palavras, o valor da automação vem tanto do que ela faz quanto de sua aplicação criteriosa. Discutiremos o valor da automação e como nossa atitude evoluiu ao longo do tempo.
O valor da automação
Qual é exatamente o valor da automação?
(Para aqueles leitores que já acham que entendem precisamente o valor da Automação, pule para “O Valor para o Google SRE”. No entanto, observe que nossa descrição contempla algumas nuances que podem ser úteis para ter em mente ao ler o restante deste capítulo).
Consistência
Embora a escala seja uma motivação óbvia para a automação, há muitos outros motivos para usá-la. Veja o exemplo dos sistemas de computação universitários, onde muitos engenheiros de sistemas começaram suas carreiras. Os administradores de sistemas com esse histórico geralmente eram encarregados de operar uma coleção de máquinas ou algum software e estavam acostumados a executar manualmente várias ações no cumprimento dessa função. Um exemplo comum é a criação de contas de usuário; outros incluem funções puramente operacionais, como garantir que os backups aconteçam, gerenciar o failover do servidor e pequenas manipulações de dados, como alterar o resolv.conf dos servidores DNS upstream, os dados da zona do servidor DNS e atividades semelhantes. Em última análise, no entanto, essa prevalência de tarefas manuais é insatisfatória tanto para as organizações quanto para as pessoas que mantêm os sistemas dessa maneira. Para começar, qualquer ação realizada por um humano ou humanos centenas de vezes não será realizada da mesma forma todas as vezes: mesmo com a melhor vontade do mundo, muito poucos de nós serão tão consistentes quanto uma máquina. Essa inevitável falta de consistência leva a erros, omissões, problemas com a qualidade dos dados e, sim, problemas de confiabilidade. Neste domínio – a execução de procedimentos bem definidos e conhecidos – o valor da consistência é, em muitos aspectos, o valor principal da automação.
Uma plataforma
A automação não fornece apenas consistência. Projetados e feitos de maneira adequada, os sistemas automáticos também fornecem uma plataforma que pode ser estendida, aplicada a mais sistemas, ou talvez até mesmo adaptada para gerar lucro. (A alternativa, sem automação, não é econômica nem extensível: é, ao invés disso, uma taxa cobrada sobre a operação de um sistema. A experiência adquirida na construção de tal automação também é valiosa por si só; os engenheiros entendem profundamente os processos que automatizaram e podem, posteriormente, automatizar novos processos mais rapidamente).
Uma plataforma também centraliza erros. Em outras palavras, um bug corrigido no código será corrigido lá de uma vez por todas, ao contrário de um conjunto suficientemente grande de humanos executando o mesmo procedimento, conforme discutido anteriormente. Uma plataforma pode ser estendida para executar tarefas adicionais mais facilmente do que humanos podem ser instruídos a executá-las (ou às vezes até perceber que elas têm que ser feitas). A depender da natureza da tarefa, ela pode ser executada continuamente ou com muito mais frequência do que os humanos poderiam realizá-la apropriadamente; ou, ainda, podem ser inconvenientes para os humanos. Além disso, uma plataforma pode exportar métricas sobre seu desempenho ou, de outra forma, permitir explorar detalhes sobre seu processo que você não conhecia anteriormente, porque esses detalhes são mais facilmente mensuráveis dentro do contexto de uma plataforma.
Reparos mais rápidos
Há um benefício adicional para sistemas onde a automação é usada para resolver falhas comuns em um sistema (uma situação frequente para automação criada por SRE). Se a automação for executada regularmente e com sucesso suficiente, o resultado é um mean time to repair (MTTR) reduzido para essas falhas comuns. Você pode, então, gastar seu tempo em outras tarefas, alcançando assim maior velocidade do desenvolvedor, porque você não precisa perder tempo prevenindo ou, mais comumente, limpando um problema.
Como é bem conhecido na indústria, quanto mais tarde um problema for descoberto no ciclo de vida de um produto, mais caro será para consertar; veja o Capítulo 17, sobre Teste de Confiabilidade. Geralmente, os problemas que ocorrem na produção real são mais caros de consertar, tanto em termos de tempo quanto de dinheiro, o que significa que um sistema automatizado procurando por problemas assim que eles surgem tem uma boa chance de reduzir o custo total do sistema, dado que o sistema é suficientemente grande.
Ação mais rápida
Nas situações de infraestrutura em que a automação SRE tende a ser implantada, os humanos geralmente não reagem tão rápido quanto as máquinas. Na maioria dos casos comuns, onde, por exemplo, failover ou switch de tráfego podem ser bem definidos para um aplicativo específico, não faz sentido exigir que uma pessoa pressione de forma intermitente um botão chamado “permitir que o sistema continue a funcionar”. (Sim, é verdade que às vezes os procedimentos automáticos podem acabar piorando uma situação ruim, mas é por isso que esses procedimentos devem ter domínios bem definidos como escopo). O Google concentra uma grande quantidade de automação; em muitos casos, os serviços aos quais oferecemos suporte não sobreviveriam por muito tempo sem essa automação, porque ultrapassaram o limiar da operação manual gerenciável há muito tempo.
Economia de tempo
Por fim, a economia de tempo é uma justificativa muito citada para a automação. Embora as pessoas citem mais esse argumento para a automação do que os outros, em muitos aspectos o benefício costuma ser menos imediatamente calculável. Os engenheiros muitas vezes hesitam sobre se vale a pena escrever uma parte específica de automação ou código, em termos de esforço poupado, por não exigir que uma tarefa seja executada manualmente versus o esforço necessário para escrevê-la (a respeito disso, veja o cartoon XKCD). É fácil ignorar o fato de que, uma vez que você encapsulou alguma tarefa em automação, qualquer um pode executá-la. Portanto, a economia de tempo aplica-se a qualquer pessoa que usaria a automação de maneira plausível. Desacoplar o operador da operação é muito poderoso.
Joseph Bironas, um SRE que liderou os esforços de renovação do datacenter do Google por um tempo, argumentou vigorosamente:
“Se somos processos e soluções de engenharia que não são automatizados, continuamos tendo que contratar humanos para manter o sistema. Se tivermos que contratar humanos para fazer o trabalho, estamos alimentando as máquinas com sangue, suor e lágrimas de seres humanos. Pense na Matrix com menos efeitos especiais e mais administradores de sistema irritados.”
O Valor para o Google SRE
Todos esses benefícios e compensações se aplicam a nós tanto quanto a qualquer outra pessoa, e o Google tem uma forte tendência para a automação. Parte de nossa preferência por automação deriva de nossos desafios comerciais específicos: os produtos e serviços que cuidamos abrangem o planeta em escala e normalmente não temos tempo para nos envolver no mesmo tipo de máquina ou serviço de manuseio comum em outras organizações. Para serviços realmente grandes, os fatores de consistência, rapidez e confiabilidade dominam a maioria das conversas sobre as compensações de executar a automação.
Outro argumento a favor da automação, particularmente no caso do Google, é nosso ambiente de produção complicado, mas surpreendentemente uniforme, descrito no Capítulo 2. Embora outras organizações possam ter um equipamento importante sem uma API prontamente acessível, um software para o qual nenhum código-fonte está disponível ou mesmo outro impedimento para o controle completo sobre as operações de produção, o Google geralmente evita esses cenários. Criamos APIs para sistemas quando não havia API disponível pelo fornecedor. Embora comprar software para uma tarefa específica fosse muito mais barato no curto prazo, optamos por escrever nossas próprias soluções, porque isso produzia APIs com potencial para benefícios muito maiores a longo prazo. Gastamos muito tempo superando obstáculos ao gerenciamento automático do sistema e, então, desenvolvemos resolutamente esse próprio gerenciamento automático do sistema. Dado como o Google gerencia seu código-fonte, a disponibilidade desse código para qualquer sistema que a equipe SRE toque também significa que nossa missão de “possuir o produto em produção” é muito mais fácil porque controlamos a totalidade da pilha.
Claro que, embora o Google esteja ideologicamente inclinado a usar máquinas para gerenciar máquinas sempre que possível, a realidade requer algumas modificações em nossa abordagem. Não é apropriado automatizar todos os componentes de cada sistema, e nem todos têm a capacidade ou inclinação para desenvolver automação em um determinado momento. Alguns sistemas essenciais começaram como protótipos rápidos, não projetados para durar ou fazer interface com a automação. Os parágrafos anteriores apresentaram uma visão maximalista de nossa posição, mas que tivemos grande sucesso em colocar em ação dentro do contexto do Google. Em geral, optamos por criar plataformas onde pudéssemos, ou nos posicionar de forma que pudéssemos criar plataformas ao longo do tempo. Vemos essa abordagem baseada em plataforma como necessária para a capacidade de gerenciamento e escalabilidade.
Casos de uso para automação
Na indústria, automação é o termo geralmente usado para escrever código na intenção de resolver uma ampla variedade de problemas, embora as motivações para escrever esse código e as próprias soluções sejam frequentemente bem diferentes. De forma mais ampla, nessa visão, automação é “meta-software” – software para agir sobre software.
Como sugerimos anteriormente, há vários casos de uso para automação. Abaixo uma lista não exaustiva de exemplos:
- Criação de conta de usuário
- Ativação e desativação de cluster para serviços
- Preparação e descomissionamento da instalação de software ou hardware
- Lançamentos de novas versões de software
- Mudanças na configuração do tempo de execução
- Um caso especial de mudanças na configuração do tempo de execução: mudanças em suas dependências
Essa lista poderia continuar essencialmente ad infinitum.
Casos de uso do Google SRE para Automação
No Google, temos todos os casos de uso que acabamos de listar e muito mais.
No entanto, dentro do Google SRE, nossa principal afinidade normalmente tem sido para executar a infraestrutura, em oposição ao gerenciamento da qualidade dos dados que passam por essa infraestrutura. Esta linha não é totalmente clara – por exemplo, nos preocupamos profundamente se metade de um conjunto de dados desaparece após um push e, portanto, alertamos sobre diferenças de granulação como esta, mas é raro escrevermos o equivalente a alterar as propriedades de algum subconjunto arbitrário de contas em um sistema. Portanto, o contexto de nossa automação é frequentemente a automação para gerenciar o ciclo de vida dos sistemas, não seus dados: por exemplo, implantações de um serviço em um novo cluster.
Nesse sentido, os esforços de automação das equipes SRE não estão muito distantes do que muitas outras pessoas e organizações fazem, exceto que usamos ferramentas diferentes para gerenciá-lo e temos um foco diferente (como discutiremos aqui).
Ferramentas amplamente disponíveis como Puppet, Chef, cfengine e até mesmo o Perl, que fornecem maneiras de automatizar tarefas específicas, diferem em termos do nível de abstração dos componentes fornecidos para ajudar na parte prática da automação. Uma linguagem completa como Perl fornece recursos de nível POSIX, que em teoria fornecem um escopo essencialmente ilimitado de automação nas APIs acessíveis ao sistema, enquanto Chef e Puppet fornecem abstrações prontas para uso com as quais serviços ou outras entidades de nível podem ser manipuladas. (Claro, nem todo sistema que precisa ser gerenciado realmente fornece APIs que podem ser chamadas para gerenciamento – forçando algumas ferramentas a usar, por exemplo, invocações CLI ou cliques automatizados em sites).
A compensação aqui é clássica: abstrações de nível superior são mais fáceis de gerenciar e raciocinar, mas quando você encontra uma “abstração que vaza”, você falha sistemicamente, repetidamente e potencialmente de forma inconsistente. Por exemplo, frequentemente assumimos que enviar um novo binário para um cluster é atômico; o cluster terminará com a versão antiga ou a nova versão. No entanto, o comportamento no mundo real é mais complicado: a rede desse cluster pode falhar no meio do caminho; as máquinas podem falhar; a comunicação com a camada de gerenciamento do cluster pode falhar, deixando o sistema em um estado inconsistente; dependendo da situação, novos binários podem ser testados, mas não enviados por push, ou enviados por push, mas não reiniciados, ou reiniciados, mas não verificáveis. Muito poucas abstrações modelam esses tipos de resultados com sucesso e, em geral, acabam parando e exigindo intervenção. Sistemas de automação ruins nem mesmo fazem isso.
O SRE contempla uma série de filosofias e produtos no domínio da automação, alguns dos quais se parecem mais com ferramentas de implementação genéricas sem modelagem particularmente detalhada de entidades de nível superior, enquanto outros se parecem mais com linguagens para descrever a implantação de serviço (e assim por diante) em um nível muito abstrato. O trabalho feito neste último tende a ser mais reutilizável e ser mais uma plataforma comum do que o anterior, mas a complexidade de nosso ambiente de produção às vezes significa que o primeiro método é a opção mais imediatamente tratável.
Uma hierarquia de classes de automação
Embora todas essas etapas de automação sejam valiosas e, de fato, uma plataforma de automação seja valiosa por si só, em um mundo ideal, não precisaríamos de automação externalizada. Na verdade, em vez de ter um sistema que precisa ter lógica de colagem externa, seria ainda melhor ter um sistema que não precise de nenhuma lógica de colagem, não apenas porque a internalização é mais eficiente (embora tal eficiência seja útil), mas porque ele foi projetado para não precisar de glue code em primeiro lugar. Conseguir isso envolve pegar os casos de uso para a lógica de colagem – geralmente manipulações de “primeira ordem” de um sistema, como adicionar contas ou executar a ativação do sistema – e encontrar uma maneira de lidar com esses casos de uso diretamente no aplicativo.
Como um exemplo mais detalhado, a maior parte da automação de ativação no Google é problemática porque acaba sendo mantida separadamente do sistema central e, portanto, sofre de “bit rot“, ou seja, não muda quando os sistemas subjacentes mudam. Apesar da melhor das intenções, a tentativa de acoplar mais dois (automação de ativação e o sistema central) geralmente falha devido a prioridades desalinhadas, já que os desenvolvedores de produto, não sem razão, resistirão a um requisito de implantação de teste para cada mudança. Em segundo lugar, a automação que é crucial, mas executada apenas em intervalos infrequentes e, portanto, difícil de testar, é particularmente frágil por conta do ciclo de feedback estendido. O failover de cluster é um exemplo clássico de automação executada com pouca frequência: os failovers podem ocorrer apenas a cada poucos meses, ou com pouca frequência, o suficiente para que sejam introduzidas inconsistências entre as instâncias.
A evolução da automação segue um caminho:
1) Sem automação
A master do banco de dados sofre failover manualmente entre os locais.
2) Automação específica do sistema mantida externamente
Um SRE possui um script de failover em seu diretório inicial.
3) Automação genérica mantida externamente
O SRE adiciona suporte de banco de dados a um script de “failover genérico” que todos usam.
4) Automação específica do sistema mantida internamente
O banco de dados é fornecido com seu próprio script de failover.
5) Sistemas que não precisam de automação
O banco de dados detecta problemas e executa failover automaticamente sem intervenção humana.
O SRE odeia operações manuais, então obviamente tentamos criar sistemas que não as requeiram. No entanto, às vezes as operações manuais são inevitáveis.
Além disso, há uma subvariedade de automação que aplica mudanças não no domínio da configuração específica do sistema, mas no domínio da produção como um todo. Em um ambiente de produção proprietário altamente centralizado como o do Google, há um grande número de alterações que têm um escopo não específico do serviço, por exemplo, alteração de servidores Chubby upstream, uma alteração de flag na biblioteca cliente Bigtable para tornar o acesso mais confiável e assim ativado – que, no entanto, precisa ser gerenciado com segurança e revertido, se necessário. Além de um certo volume de mudanças, é inviável que as alterações em toda a produção sejam realizadas manualmente e, em algum momento antes desse ponto, é um desperdício ter supervisão manual para um processo onde uma grande proporção das mudanças são triviais ou realizadas com sucesso por meio de estratégias básicas de relançamento e verificação.
Vamos usar estudos de caso internos para ilustrar alguns dos pontos anteriores em detalhes. O primeiro estudo de caso é sobre como, devido a algum trabalho diligente e perspicaz, conseguimos alcançar o nirvana autoproclamado da SRE: a automatização do trabalho.
Automação do trabalho: Automatize TODAS as coisas!
Por um longo tempo, os anúncios de produtos do Google armazenaram seus dados em um banco de dados MySQL. Como os dados de anúncios obviamente têm requisitos de alta confiabilidade, uma equipe SRE foi encarregada de cuidar dessa infraestrutura. De 2005 a 2008, o banco de dados de anúncios foi executado principalmente no que consideramos um estado maduro e gerenciado. Por exemplo, automatizamos o pior, mas não todo o trabalho de rotina para substituições de réplicas padrão. Acreditávamos que o banco de dados de anúncios era bem gerenciado e que havíamos colhido a maior parte dos frutos mais fáceis em termos de otimização e escala. No entanto, conforme as operações diárias se tornaram confortáveis, os membros da equipe começaram a olhar para o próximo nível de desenvolvimento do sistema: a migração do MySQL para o Borg, o sistema de agendamento de cluster do Google.
Esperávamos que essa migração trouxesse dois benefícios principais:
- Eliminasse completamente a manutenção da máquina/réplica: o Borg lidaria automaticamente com a configuração/reinicialização de tarefas novas e interrompidas.
- Habilitasse o empacotamento de várias instâncias do MySQL na mesma máquina física: o Borg permitiria o uso mais eficiente dos recursos da máquina por meio de containers.
No final de 2008, implantamos com sucesso uma instância de prova de conceito do MySQL no Borg. Infelizmente, isso foi acompanhado por uma nova dificuldade significativa. Uma característica operacional central do Borg é que suas tarefas se movem automaticamente. As tarefas geralmente são movidas dentro do Borg uma ou duas vezes na semana. Essa frequência era tolerável para nossas réplicas de banco de dados, mas inaceitável para nossas masters.
Naquela época, o processo de failover da master levava de 30 a 90 minutos por instância. Simplesmente porque rodamos em máquinas compartilhadas e estávamos sujeitos a reinicializações para atualizações de kernel, além da taxa normal de falha da máquina, tínhamos que esperar uma série de failovers não relacionados a cada semana. Esse fator, em combinação com o número de shards em que nosso sistema estava hospedado, significava que:
- Os failovers manuais consumiriam uma quantidade substancial de horas humanas e nos dariam, no melhor dos casos, disponibilidade de 99% de tempo de atividade, o que ficava aquém dos requisitos comerciais reais do produto.
- Para atender aos nossos error budgets, cada failover levaria menos de 30 segundos de tempo de inatividade. Não havia como otimizar um procedimento dependente de humanos para tornar o tempo de inatividade menor que 30 segundos.
Portanto, nossa única opção era automatizar o failover. Na verdade, precisávamos automatizar mais do que apenas o failover.
Em 2009, a equipe SRE de Ads concluiu nosso daemon de failover automatizado, que apelidamos de “Decider”. O Decider podia concluir failovers do MySQL para failovers planejados e não planejados em menos de 30 segundos 95% do tempo. Com a criação do Decider, o MySQL on Borg (MoB) finalmente se tornou uma realidade. Passamos da otimização de nossa infraestrutura por falta de failover para abraçar a ideia de que a falha é inevitável e, portanto, otimizar para recuperar rapidamente através da automação.
Embora a automação nos permitisse alcançar o MySQL altamente disponível em um mundo que forçava até duas reinicializações por semana, ela trazia seu próprio conjunto de custos. Todos os nossos aplicativos tiveram que ser alterados para incluir significativamente mais lógica de tratamento de falhas do que antes. Dado que a norma no mundo do desenvolvimento MySQL é assumir que a instância do MySQL será o componente mais estável da pilha, essa opção significou personalizar software como o JDBC para ser mais tolerante com nosso ambiente sujeito a falhas. No entanto, os benefícios de migrar para o MoB com o Decider compensaram esses custos. Uma vez no MoB, o tempo que nossa equipe gastou em tarefas operacionais rotineiras caiu 95%. Nossos failovers foram automatizados, portanto, uma interrupção de uma única tarefa de banco de dados não chamava mais um ser humano.
O principal resultado dessa nova automação foi que tínhamos muito mais tempo livre para gastar na melhoria de outras partes da infraestrutura. Essas melhorias tiveram um efeito cascata: quanto mais tempo economizávamos, mais tempo podíamos gastar na otimização e automação de outros trabalhos tediosos. Por fim, fomos capazes de automatizar as alterações de schema, fazendo com que o custo de manutenção operacional total do banco de dados de anúncios caísse em quase 95%. Alguns podem dizer que nos automatizamos com sucesso esse trabalho. O lado do hardware do nosso domínio também passou por melhorias. A migração para o MoB liberou recursos consideráveis porque podíamos agendar várias instâncias do MySQL nas mesmas máquinas, o que melhorou a utilização de nosso hardware. No total, conseguimos liberar cerca de 60% do nosso hardware. Nossa equipe agora estava abastecida com recursos de hardware e engenharia.
Este exemplo demonstra a sabedoria de ir além para entregar uma plataforma em vez de substituir os procedimentos manuais existentes. O próximo exemplo vem do grupo de infraestrutura de cluster e ilustra algumas das compensações mais difíceis que você pode encontrar ao automatizar todas as coisas.
Acalmando a dor: aplicando automação no cluster
Dez anos atrás, a equipe SRE de infraestrutura de cluster parecia conseguir uma nova contratação a cada poucos meses. Acontece que essa era aproximadamente a mesma frequência com que criávamos um novo cluster. Como ativar um serviço em um novo cluster dá aos novos contratados exposição a componentes internos de um serviço, essa tarefa parecia uma ferramenta de treinamento natural e útil.
As etapas executadas para preparar um cluster para uso foram mais ou menos as seguintes:
- Prepare um edifício de datacenter para energia e refrigeração.
- Instale e configure switches centrais e conexões com o backbone.
- Instale alguns racks iniciais de servidores.
- Configure serviços básicos como DNS e instaladores e, em seguida, configure um serviço de bloqueio, armazenamento e computação.
- Implante os racks de máquinas restantes.
- Atribua recursos de serviços voltados para o usuário, para que suas equipes possam configurar os serviços.
As etapas 4 e 6 foram extremamente complexas. Embora serviços básicos como DNS sejam relativamente simples, os subsistemas de armazenamento e computação da época ainda estavam em forte desenvolvimento, portanto, novas flags, componentes e otimizações eram adicionados semanalmente.
Alguns serviços tinham mais de cem subsistemas de componentes diferentes, cada um com uma complexa teia de dependências. Deixar de configurar um subsistema ou configurar um sistema ou componente de maneira diferente de outras implantações é uma interrupção prestes a acontecer e que impacta diretamente o cliente.
Em um caso, um cluster Bigtable de vários petabytes foi configurado para não usar o primeiro disco (de logging) em sistemas de 12 discos, por motivos de latência. Um ano depois, alguma automação presumiu que, se o primeiro disco de uma máquina não estava sendo usado, essa máquina não tinha nenhum armazenamento configurado; portanto, era seguro limpar a máquina e configurá-la do zero. Todos os dados do Bigtable foram apagados instantaneamente. Felizmente, tínhamos várias réplicas em tempo real do conjunto de dados, mas essas surpresas não são bem-vindas. A automação precisa ter cuidado ao confiar em sinais implícitos de “segurança”.
A automação inicial focava na aceleração da entrega do cluster. Essa abordagem tendia a depender do uso criativo de SSH para problemas entediantes de distribuição de pacotes e inicialização de serviços. Essa estratégia foi uma vitória inicial, mas os scripts de formato livre tornaram-se um “colesterol ruim” em termos de dívida técnica.
Detectando inconsistências com Prodtest (teste de produção)
Conforme o número de clusters crescia, alguns exigiam flags e configurações ajustadas manualmente. Como resultado, as equipes perdiam cada vez mais tempo perseguindo configurações incorretas difíceis de localizar. Se uma flag que tornava o GFS mais responsivo ao processamento de log vazasse para os modelos padrão, as células com muitos arquivos poderiam ficar sem memória durante o carregamento. Configurações incorretas demoradas e enfurecedoras surgiam em quase todas as grandes mudanças de configuração.
Os shell scripts criativos – embora frágeis – que usamos para configurar clusters não estavam escalando para o número de pessoas que queriam fazer alterações, nem para o número absoluto de permutações de cluster que precisavam ser construídas. Esses scripts shell também não conseguiram resolver questões mais significativas antes de declarar que um serviço fosse bom para receber o tráfego voltado para o cliente, tais como:
- Todas as dependências do serviço estavam disponíveis e configuradas corretamente?
- Todas as configurações e pacotes eram consistentes com outras implantações?
- A equipe poderia confirmar se todas as exceções de configuração foram desejadas?
O Prodtest (Teste de Produção) foi uma solução engenhosa para essas surpresas indesejáveis. Estendemos a estrutura de teste de unidade Python para permitir o teste de unidade de serviços do mundo real. Esses testes de unidade têm dependências, permitindo uma cadeia de testes, e uma falha em um teste abortaria rapidamente. Pegue o teste mostrado na Figura 7-1 como exemplo: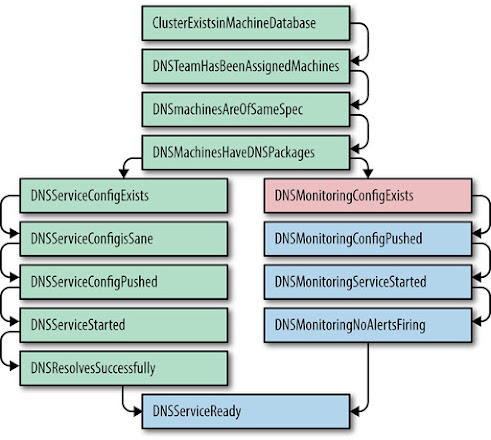
O Prodtest de uma determinada equipe recebeu o nome do cluster e poderia validar os serviços dessa equipe nesse cluster. Adições posteriores nos permitiram gerar um gráfico dos testes de unidade e seus estados. Essa funcionalidade possibilitou que um engenheiro visse rapidamente se seu serviço estava configurado corretamente em todos os clusters e, em caso negativo, descobrir o por quê. O gráfico destacou a etapa com falha e o teste de unidade Python com falha gerou uma mensagem de erro mais detalhada.
Sempre que uma equipe encontrava um atraso devido a uma configuração incorreta inesperada de outra equipe, um bug podia ser arquivado para estender seu Prodtest. Isso garantia que um problema semelhante seria descoberto mais cedo no futuro. Os SREs se orgulhavam de garantir a seus clientes que todos os serviços – tanto os serviços recém-disponibilizados quanto os existentes com nova configuração – atenderiam de forma confiável ao tráfego da produção.
Pela primeira vez, nossos gerentes de projeto puderam prever quando um cluster poderia “entrar em operação” e compreenderam completamente por que cada cluster levava seis ou mais semanas para ir de “pronto para a rede” para “atender ao tráfego em tempo real“. Inesperadamente, o SRE recebeu uma missão da alta administração: em três meses, cinco novos clusters estarão prontos para a rede no mesmo dia. Aumente-os em uma semana.
Resolvendo inconsistências de forma idempotente
“Aumentar em uma semana” foi uma missão aterrorizante. Tínhamos dezenas de milhares de linhas de shell scripts pertencentes a dezenas de equipes. Pudemos saber rapidamente o quão despreparado um determinado cluster estava, mas consertá-lo significava que dezenas de equipes teriam que arquivar centenas de bugs, e então tínhamos que esperar que esses bugs fossem corrigidos imediatamente.
Percebemos que a evolução de “testes de unidade Python encontrando configurações incorretas” para “código Python corrigindo configurações incorretas” poderia nos permitir corrigir esses problemas mais rapidamente.
O teste de unidade já sabia qual cluster estávamos examinando e o teste específico que estava falhando, então emparelhamos cada teste com uma correção. Se cada correção fosse escrita para ser idempotente e pudesse assumir que todas as dependências foram atendidas, deveria ser fácil – e seguro – de resolver o problema. A exigência de correções idempotentes significa que as equipes podem executar seu “script de correção” a cada 15 minutos sem temer danos à configuração do cluster. Se o teste da equipe de DNS fosse bloqueado na configuração de um novo cluster da equipe de banco de dados da máquina, assim que o cluster aparecesse no banco de dados, os testes e correções da equipe de DNS começariam a funcionar.
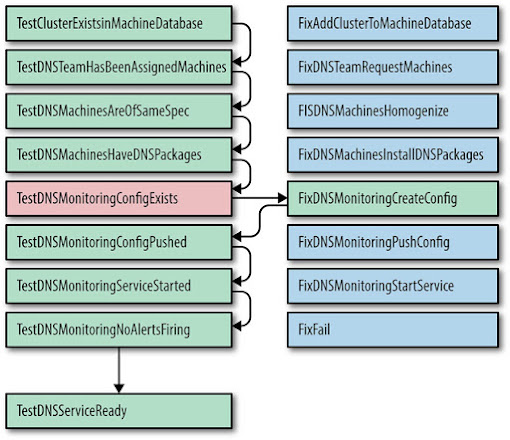
Tome o teste mostrado na Figura 7-2 como exemplo. Se TestDnsMonitoringConfigExists falhar, conforme mostrado, podemos chamar FixDnsMonitoringCreateConfig, que extrai a configuração de um banco de dados e, em seguida, verifica um arquivo de configuração de esqueleto em nosso sistema de controle de revisão. Em seguida, TestDnsMonitoringConfigExists passa na nova tentativa e o teste TestDnsMonitoringConfigPushed pode ser iniciado. Se o teste falhar, a etapa FixDnsMonitoringPushConfig será executada. Se uma correção falhar várias vezes, a automação assume que a correção falhou e para, notificando o usuário.
Em posse desses scripts, um pequeno grupo de engenheiros poderia garantir que poderíamos ir de “A rede funciona, e as máquinas estão listadas no banco de dados” para “Servindo 1% do tráfego de pesquisa na web e anúncios” em questão de uma ou duas semanas. Na época, este parecia ser o ápice da tecnologia de automação.
Olhando para trás, essa abordagem era profundamente falha; a latência entre o teste, a correção e, em seguida, um segundo teste introduziu testes instáveis que às vezes funcionavam e às vezes falhavam. Nem todas as correções eram naturalmente idempotentes, então um teste instável seguido por uma correção pode deixar o sistema em um estado inconsistente.
A inclinação para se especializar
Os processos de automação podem variar em três aspectos:
- Competência, ou seja, sua precisão
- Latência, a rapidez com que todas as etapas são executadas quando iniciadas
- Relevância, ou proporção do processo do mundo real coberto pela automação
Começamos com um processo que era altamente competente (mantido e executado pelos proprietários do serviço), de alta latência (os proprietários do serviço executavam o processo em seu tempo livre ou o atribuíam a novos engenheiros) e muito relevante (os proprietários do serviço sabiam quando o mundo real mudava e podiam consertar a automação).
Para reduzir a latência de ativação, muitas equipes proprietárias de serviço instruíram uma única “equipe de ativação” sobre a automação a ser executada. A equipe de turnup usou tickets para iniciar cada estágio da mudança para que pudéssemos rastrear as tarefas restantes e a quem essas tarefas foram atribuídas. Se as interações humanas em relação aos módulos de automação ocorressem entre pessoas na mesma sala, a ativação do cluster poderia ocorrer em um tempo muito mais curto. Finalmente, tivemos nosso processo de automação competente, preciso e oportuno!
Mas esse estado não durou muito. O mundo real é caótico: software, configuração, dados, etc. alterados, resultando em mais de mil mudanças separadas por dia nos sistemas afetados. As pessoas mais afetadas pelos bugs de automação não eram mais especialistas no domínio, então a automação se tornou menos relevante (significando que novas etapas foram perdidas) e menos competente (novas flags podem ter causado a falha da automação). No entanto, demorou um pouco para que essa queda na qualidade afetasse a velocidade.
Tanto o código de automação como o código de teste de unidade acabam morrendo quando a equipe de manutenção não é obsessiva em manter o código em sincronia com a base de código que ele cobre. O mundo muda em torno do código: a equipe DNS adiciona novas opções de configuração, a equipe de armazenamento muda seus nomes de pacotes e a equipe de rede precisa oferecer suporte a novos dispositivos.
Ao dispensar as equipes que executavam os serviços da responsabilidade de manter e executar seu código de automação, criamos incentivos organizacionais horríveis:
- Uma equipe cuja principal tarefa é acelerar a ativação atual não tem incentivo para reduzir o débito técnico da equipe proprietária do serviço que, por sua vez, executará o serviço em produção posteriormente.
- Uma equipe que não executa a automação não tem incentivo para construir sistemas fáceis de automatizar.
- Um Gerente de Produto cuja programação não é afetada pela automação de baixa qualidade sempre priorizará novos recursos em vez da simplicidade e da automação.
As ferramentas mais funcionais geralmente são escritas por aqueles que as usam. Um argumento semelhante se aplica ao motivo pelo qual as equipes de desenvolvimento de produto se beneficiam de manter pelo menos alguma consciência operacional de seus sistemas em produção.
Os turnups foram novamente de alta latência, imprecisos e incompetentes – o pior de todos os mundos. No entanto, uma questão de segurança não relacionada nos permitiu sair dessa armadilha. Grande parte da automação distribuída na época dependia do SSH. Isso é desajeitado do ponto de vista da segurança, porque as pessoas devem ter root em muitas máquinas para executar a maioria dos comandos. Uma consciência crescente das ameaças de segurança avançadas e persistentes nos levou a reduzir os privilégios de que os SREs desfrutavam ao mínimo de que precisavam para realizar seus trabalhos. Tivemos que substituir nosso uso de sshd por um Daemon Admin local baseado em RPC e baseado em ACL, também conhecido como Admin Servers, que tinha permissão para realizar essas alterações locais. Como resultado, ninguém poderia instalar ou modificar um servidor sem uma trilha de auditoria. Mudanças no Daemon Admin Local e no Package Repo foram bloqueadas em revisões de código, tornando muito difícil para alguém exceder sua autoridade; dar a alguém o acesso para instalar pacotes não permitiria que eles visualizassem os logs colocados. O Admin Server registrou o solicitante RPC, quaisquer parâmetros e os resultados de todos os RPCs para aprimorar o debug e as auditorias de segurança.
Ativação de cluster orientada a serviços
Na próxima iteração, os Admin Servers tornaram-se parte dos fluxos de trabalho das equipes de serviço, tanto relacionados aos Admin Servers específicos da máquina (para instalar pacotes e reinicialização) quanto aos Admin Servers em nível de cluster (para ações como drenar ou ativar um serviço). Os SREs deixaram de escrever shell scripts em seus diretórios pessoais para construir servidores RPC revisados por pares com ACLs de baixa granularidade.
Mais tarde, após a constatação de que os processos de ativação deveriam pertencer às equipes que possuíam os serviços totalmente incorporados, vimos isso como uma forma de abordar a ativação do cluster como um problema de Arquitetura Orientada a Serviços (SOA): os proprietários dos serviços seriam os responsáveis por criar um Admin Server para lidar com RPCs de ativação/desativação de cluster, enviados pelo sistema, que sabia quando os clusters estavam prontos. Por sua vez, cada equipe forneceria o contrato (API) de que a automação de ativação precisava, embora ainda estivesse livre para alterar a implementação subjacente. À medida que um cluster ficava “pronto para a rede”, a automação enviava um RPC para cada Admin Server que participava da ativação do cluster.
Agora temos um processo de baixa latência, competente e preciso; o mais importante é que esse processo permaneceu forte à medida que a taxa de mudança, o número de equipes e o número de serviços parecem dobrar a cada ano.
Conforme mencionado anteriormente, nossa evolução da automação de turnup seguiu um caminho:
- Ação manual acionada pelo operador (sem automação)
- Automação específica do sistema escrita pelo operador
- Automação genérica mantida externamente
- Automação específica do sistema mantida internamente
- Sistemas autônomos que não precisam de intervenção humana
Embora essa evolução tenha sido, em termos gerais, um sucesso, o estudo de caso Borg ilustra outra maneira pela qual pensamos no problema da automação.
Borg: o nascimento do computador em escala de Warehouse
Outra maneira de entender o desenvolvimento de nossa atitude em relação à automação, e quando e onde essa automação é melhor implantada, é considerar a história do desenvolvimento de nossos sistemas de gerenciamento de cluster (que resumiremos aqui). Como o MySQL no Borg, que demonstrou o sucesso da conversão de operações manuais para automáticas e o processo de ativação do cluster, que demonstrou a desvantagem de não pensar com cuidado o suficiente sobre onde e como a automação era implementada, o desenvolvimento do gerenciamento de cluster também acabou demonstrando outra lição sobre como a automação deve ser feita. Como nossos dois exemplos anteriores, algo bastante sofisticado foi criado como o resultado final da evolução contínua de começos mais simples.
Os clusters do Google foram inicialmente implantados como todas as outras pequenas redes da época: racks de máquinas com finalidades específicas e configurações heterogêneas. Os engenheiros se logariam em alguma máquina “master” bem conhecida para realizar tarefas administrativas; Binários “dourados” e configurações viviam nessas masters. Como tínhamos apenas um único provedor, a maioria das lógicas de nomenclatura assumia implicitamente esse local. Conforme a produção crescia e começávamos a usar vários clusters, diferentes domínios (nomes de cluster) entravam em cena. Tornou-se necessário ter um arquivo descrevendo o que cada máquina fazia, que agrupava as máquinas sob alguma estratégia de nomenclatura flexível. Este arquivo descritor, em combinação com o equivalente a um SSH paralelo, nos permitiu reiniciar (por exemplo) todas as máquinas de busca de uma vez. Nessa época, era comum obter tíquetes como “a pesquisa é feita com a máquina x1, o rastreamento pode passar pela máquina agora”.
O desenvolvimento da automação começou. Inicialmente, a automação consistia em scripts Python simples para operações como as seguintes:
- Gerenciamento de serviço: manter os serviços em execução (por exemplo, reinicia após segfaults)
- Rastrear quais serviços deveriam ser executados em quais máquinas
- Parsing de mensagem de log: SSHing em cada máquina e procurando por regexps
A automação acabou se transformando em um banco de dados adequado que rastreava o estado da máquina e também incorporava ferramentas de monitoramento mais sofisticadas. Com a disponibilidade de um conjunto ordenado de automação, podíamos agora gerenciar automaticamente grande parte do ciclo de vida das máquinas: perceber quando estivessem quebradas, remover os serviços, enviá-los para reparo e restaurar a configuração quando voltassem do reparo.
Mas, para dar um passo atrás, essa automação era útil, embora profundamente limitada, devido ao fato de que as abstrações do sistema eram implacavelmente ligadas às máquinas físicas. Precisávamos de uma nova abordagem; foi quando o Borg nasceu: um sistema que se afastou das atribuições relativamente estáticas de host/porta/trabalho do mundo anterior, em direção a tratar uma coleção de máquinas como um mar gerenciado de recursos. Central para seu sucesso – e sua concepção – foi a noção de transformar o gerenciamento de cluster em uma entidade para a qual chamadas de API pudessem ser emitidas, para algum coordenador central. Isso liberou dimensões extras de eficiência, flexibilidade e confiabilidade: ao contrário do modelo anterior de “propriedade” da máquina, o Borg podia permitir que as máquinas agendassem, por exemplo, tarefas em lote e voltadas para o usuário na mesma máquina.
Essa funcionalidade acabou resultando em atualizações contínuas e automáticas do sistema operacional com uma quantidade muito pequena de esforço constante – esforço que não se ajusta ao tamanho total das implantações de produção. Pequenos desvios no estado da máquina agora são corrigidos automaticamente; o gerenciamento de interrupções e do ciclo de vida são essencialmente autônomos para o SRE neste ponto. Milhares de máquinas nascem, morrem e passam por reparos diariamente sem nenhum esforço SRE. Para repetir as palavras de Ben Treynor Sloss: assumindo a abordagem de que se tratava de um problema de software, a automação inicial nos deu tempo suficiente para transformar o gerenciamento de cluster em algo autônomo, em vez de automatizado. Alcançamos esse objetivo trazendo ideias relacionadas à distribuição de dados, APIs, arquiteturas hub-and-spoke e desenvolvimento de software de sistema distribuído clássico para o domínio do gerenciamento de infraestrutura.
Uma analogia interessante é possível aqui: podemos fazer um mapeamento direto entre o caso de uma única máquina e o desenvolvimento de abstrações de gerenciamento de cluster. Nessa visão, o reescalonamento em outra máquina se parece muito com um processo que se move de uma CPU para outra: é claro, esses recursos de computação estão na outra extremidade de um link de rede, mas até que ponto isso realmente importa? Pensando nesses termos, a reprogramação parece uma característica intrínseca do sistema, em vez de algo que se “automatizaria” – os humanos não poderiam reagir rápido o suficiente de qualquer maneira. Da mesma forma, no caso da ativação do cluster: nesta metáfora, a ativação do cluster é simplesmente uma capacidade programável adicional, um pouco como adicionar disco ou RAM a um único computador. No entanto, geralmente não se espera que um computador de nó único continue operando quando um grande número de componentes falhar. O computador global deve ser auto-reparável para operar uma vez que cresce além de um certo tamanho, devido ao grande número de falhas essencialmente garantidas que ocorrem a cada segundo. Isso implica que, à medida que movemos os sistemas para cima na hierarquia, de acionados manualmente para acionados automaticamente e para autônomos, alguma capacidade de auto-introspecção é necessária para sobreviver.
Confiabilidade é o recurso fundamental
Obviamente, para uma solução de problemas eficaz, os detalhes da operação interna nos quais a introspecção depende também devem ser expostos aos humanos que gerenciam o sistema geral. Discussões análogas sobre o impacto da automação no domínio não computacional – por exemplo, em vôos de avião ou aplicações industriais – muitas vezes apontam o lado negativo da automação altamente eficaz: 34 operadores humanos estão progressivamente mais livres do contato direto útil com o sistema, pois a automação cobre mais e mais atividades diárias ao longo do tempo. Inevitavelmente, então, surge uma situação em que a automação falha e os humanos agora são incapazes de operar o sistema com sucesso. A fluidez de suas reações foi perdida devido à falta de prática, e seus modelos mentais do que o sistema deveria estar fazendo não refletem mais a realidade do que está sendo feito. Esta situação surge mais quando o sistema não é autônomo – isto é, onde a automação substitui as ações manuais e presume-se que as ações manuais sejam sempre executáveis e disponíveis exatamente como estavam antes. Infelizmente, com o tempo, isso acaba se tornando falso: essas ações manuais nem sempre são executáveis porque a funcionalidade para permiti-las não existe mais.
Nós também já passamos por situações em que a automação foi ativamente prejudicial em várias ocasiões – veja abaixo em “Automação: Habilitando a falha em escala” – mas, na experiência do Google, existem mais sistemas para os quais a automação ou o comportamento autônomo não são mais extras opcionais. Conforme você escala, é claro que este é o caso, mas ainda existem fortes argumentos para um comportamento mais autônomo dos sistemas, independentemente do tamanho. A confiabilidade é o recurso fundamental, e o comportamento autônomo e resiliente é uma maneira útil de conseguir isso.
Recomendações
Você pode ler os exemplos neste capítulo e decidir que precisa ser compatível com o Google antes de ter qualquer contato prático com a automação. Isso não é verdade, por duas razões: a automação fornece mais do que apenas economia de tempo, então vale a pena implementar em mais casos do que um simples cálculo de tempo gasto versus tempo economizado possam sugerir. Mas a abordagem com a maior alavancagem realmente ocorre na fase do design de projeto: o envio e a iteração rápida podem permitir que você implemente a funcionalidade mais rapidamente, embora raramente crie um sistema resiliente. A operação autônoma é difícil de adaptar de forma convincente a sistemas suficientemente grandes, mas as boas práticas padrão em engenharia de software ajudarão consideravelmente a ter subsistemas desacoplados, introduzir APIs, minimizar efeitos colaterais e assim por diante.
Automação: Habilitando a falha em escala
O Google opera mais de uma dúzia de seus próprios grandes datacenters, mas também dependemos de máquinas em muitas instalações de colocation de terceiros (ou “colos”). Nossas máquinas nesses colos são usadas para encerrar a maioria das conexões de entrada, ou como um cache para nossa própria rede de distribuição de conteúdo, a fim de reduzir a latência do usuário final. A qualquer momento, vários desses racks estão sendo instalados ou desativados; ambos os processos são amplamente automatizados. Uma etapa durante a desativação envolve sobrescrever todo o conteúdo do disco de todas as máquinas no rack, após o que um sistema independente verifica se o apagamento foi bem-sucedido. Chamamos esse processo de “Diskerase”.
Era uma vez, a automação encarregada de descomissionar um rack específico que falhou, mas somente depois que a etapa Diskerase foi concluída com sucesso. Posteriormente, o processo de desativação foi reiniciado desde o início, para depurar a falha. Nessa iteração, ao tentar enviar o conjunto de máquinas do rack para o Diskerase, a automação determinou que o conjunto de máquinas que ainda precisava ser Diskerased estava (corretamente) vazio. Infelizmente, o conjunto vazio foi usado como um valor especial, interpretado como significando “tudo”. Isso significa que a automação enviou quase todas as máquinas que temos em todos os colos para o Diskerase.
Em minutos, o altamente eficiente Diskerase apagou os discos de todas as máquinas em nosso CDN, e as máquinas não foram mais capazes de encerrar as conexões dos usuários (ou fazer qualquer outra coisa útil). Ainda podíamos servir a todos os usuários de nossos próprios datacenters e, após alguns minutos, o único efeito visível externamente era um ligeiro aumento na latência. Pelo que pudemos ver, poucos usuários perceberam o problema, graças ao bom planejamento de capacidade (pelo menos acertamos!). Enquanto isso, passamos a maior parte de dois dias reinstalando as máquinas nos colo racks afetados; em seguida, passamos as semanas seguintes auditando e adicionando mais verificações de integridade – incluindo limitação de taxa – em nossa automação e tornando nosso fluxo de trabalho de desativação idempotente.
Fonte: Google SRE Book