Escrito por Ben McCormack (Evernote) e
William Bonnell (The Home Depot)
Com Garrett Plasky (Evernote), Alex Hidalgo,
Betsy Beyer, e Dave Rensin
Embora muitos princípios do SRE tenham sido moldados dentro das paredes do Google, os seus princípios viveram durante muito tempo fora dos nossos portões. Muitas práticas padrão do Google SRE foram descobertas em paralelo ou foram adotadas por muitas outras organizações em todo o setor.
Os SLOs são fundamentais para o modelo SRE. Desde que lançamos a equipe de Engenharia de Confiabilidade do Cliente (CRE) – um grupo de SREs experientes que ajudam os clientes da plataforma Google Cloud Platform (GCP) a construir serviços mais confiáveis – quase todas as interações dos clientes começam e terminam com SLOs.
Aqui apresentamos duas histórias, contadas por duas empresas muito diferentes, que descrevem suas jornadas para a adoção de uma abordagem baseada em SLO e orçamento de erro enquanto trabalham com a equipe CRE do Google. Para uma discussão mais geral sobre SLOs e orçamentos de erro, ver Capítulo 2 neste livro, e Capítulo 3 no nosso primeiro livro.
A história de SLO do Evernote
Por Ben McCormack, Evernote
Evernote é uma aplicação multiplataforma que ajuda indivíduos e equipes a criar, reunir e compartilhar informações. Com mais de 220 milhões de usuários em todo o mundo, armazenamos mais de 12 mil milhões de informações – uma mistura de notas baseadas em texto, arquivos e anexos/imagens – dentro da plataforma. Nos bastidores, o serviço Evernote é suportado por mais de 750 instâncias MySQL.
Introduzimos o conceito de SLOs no Evernote como parte de uma renovação tecnológica muito mais ampla destinada a aumentar a velocidade de engenharia, mantendo ao mesmo tempo a qualidade do serviço. Os nossos objetivos incluíam:
- Mover o foco da engenharia para longe do levantamento pesado indiferenciado em datacenters e para o trabalho de engenharia de produtos que os clientes realmente se preocupavam.
- Rever o modelo de trabalho dos engenheiros de operações e de software para apoiar um aumento da velocidade das características, mantendo a qualidade geral do serviço.
- Reformular a forma como olhamos para os SLAs para assegurar que aumentamos a nossa atenção sobre como as falhas têm impacto na nossa grande base global de clientes.
Estes objetivos podem parecer familiares às organizações de muitas indústrias. Embora nenhuma abordagem única para fazer esses tipos de mudanças funcione em todos os aspectos, esperamos que compartilhar nossa experiência forneça informações valiosas para outras pessoas que enfrentam desafios semelhantes.
Por que o Evernote adotou o modelo SRE?
No início dessa transição, o Evernote era caracterizado por uma divisão tradicional de operações/desenvolvimento: uma equipe de operações protegia a inviolabilidade do ambiente de produção, enquanto uma equipe de desenvolvimento era encarregada de desenvolver novas características do produto para os clientes. Estes objetivos estavam geralmente em conflito: a equipe de desenvolvimento se sentia limitada por longos requisitos operacionais, enquanto a equipe de operações ficava frustrada quando o novo código introduzia novos problemas na produção. À medida que oscilamos desesperadamente entre estes dois objetivos, as equipes de operações e de desenvolvimento desenvolveram uma relação frustrada e tensa. Queríamos alcançar um meio mais feliz que equilibrasse melhor as diferentes necessidades das equipes envolvidas.
Tentamos abordar as lacunas desta dicotomia tradicional de várias maneiras ao longo de mais de cinco anos. Depois de experimentar um modelo “Você escreveu, você executa” (desenvolvimento) e um modelo “Você escreveu, nós executamos para você” (operações), avançamos para uma abordagem SRE centrada no SLO.
Então, o que motivou o Evernote a avançar nesta direção?
No Evernote, vemos as disciplinas centrais de operações e desenvolvimento como pistas profissionais separadas nas quais os engenheiros podem especializar-se. Uma pista está preocupada com a prestação contínua de um serviço aos clientes, quase 24 horas por dia, 7 dias por semana. A outra está preocupada com a extensão e evolução desse serviço para satisfazer as necessidades dos clientes no futuro. Essas duas disciplinas se aproximaram nos últimos anos, à medida que movimentos como SRE e DevOps enfatizam o desenvolvimento de software aplicado às operações. (Essa convergência foi promovida pelos avanços na automação do datacenter e o crescimento das nuvens públicas, ambos nos dando um datacenter que pode ser totalmente controlado por software). Do outro lado do espectro, a propriedade full-stack e a implantação contínua são cada vez mais aplicadas ao desenvolvimento de software.
Fomos atraídos para o modelo SRE porque este abraça e aceita plenamente as diferenças entre operações e desenvolvimento, ao mesmo tempo que encoraja as equipes a trabalhar para um objetivo comum. Não tenta transformar os engenheiros de operações em desenvolvedores de aplicações, ou vice-versa. Em vez disso, dá a ambos um quadro comum de referência. Na nossa experiência, uma abordagem de erro orçamental/SLO levou ambas as equipes a tomar decisões semelhantes quando apresentadas aos mesmos fatos, uma vez que remove uma boa parte da subjetividade da conversa.
Introdução de SLOs: Uma Jornada em Progresso
A primeira parte da nossa jornada foi a mudança dos datacenters físicos para a plataforma Google Cloud. Uma vez que o serviço Evernote estava funcionando no GCP e estabilizado, introduzimos os SLOs. Os nossos objetivos aqui eram duplos:
- Alinhar as equipes internamente em torno dos SLOs do Evernote, assegurando que todas as equipes estivessem trabalhando dentro do novo quadro.
- Incorporar o SLO do Evernote na forma como trabalhamos com a equipe do Google Cloud, que agora tinha responsabilidade pela nossa infra-estrutura subjacente. Uma vez que agora tínhamos um novo parceiro dentro do modelo global, precisávamos assegurar que a mudança para o GCP não diluisse ou mascarasse nosso compromisso com nossos usuários.
Depois de utilizar ativamente os SLOs durante cerca de nove meses, o Evernote já está na versão 3 da sua prática SLO!
Antes de entrar nos detalhes técnicos de um SLO, é importante iniciar a conversa do ponto de vista dos seus clientes: que promessas está tentando cumprir? À semelhança da maioria dos serviços, o Evernote tem muitos recursos e opções que os nossos usuários usam de várias formas criativas. Queríamos garantir que inicialmente focamos na necessidade mais importante e comum do consumidor: a disponibilidade do serviço Evernote para que os usuários acessem e sincronizem seu conteúdo através de múltiplos clientes. Nossa jornada SLO começou a partir desse objetivo. Mantivemos nossa primeira passagem simples, concentrando-nos no tempo de atividade. Usando essa primeira abordagem simples, pudemos articular claramente o que estávamos medindo e como.
O nosso primeiro documento SLOs continha o seguinte:
Uma definição dos SLOs
Esta foi uma medida de tempo de atividade: 99,95% de tempo de atividade medido ao longo de uma janela mensal, definido para certos serviços e métodos. Escolhemos este número com base em discussões com as nossas equipes internas de apoio ao cliente e de produtos e – o que é mais importante – feedback dos usuários. Escolhemos deliberadamente vincular os nossos SLOs a um mês de calendário em vez de um período contínuo para nos manter focados e organizados ao executar revisões de serviço.
O que medir, e como medir
O que medir
Especificamos um parâmetro de serviço que poderíamos chamar para testar se o serviço estava funcionando conforme o esperado. No nosso caso, temos uma página de status embutida em nosso serviço que exercita a maior parte de nossa pilha e retorna um código de status 200 se tudo estiver bem.
Como medir
Quisemos uma sonda que chamasse periodicamente a página de status. Queríamos que essa sonda ficasse localizada completamente fora e independente do nosso ambiente, para que pudéssemos testar todos os nossos componentes, incluindo a nossa pilha de equilíbrio de carga. Nosso objetivo aqui era ter certeza de que estávamos medindo todas e quaisquer falhas do serviço GCP e do aplicativo Evernote. Contudo, não queríamos que questões aleatórias na Internet desencadeassem falsos positivos. Optamos por utilizar uma empresa terceirizada especializada na construção e gestão de tais aparelhos. Selecionamos a Pingdom, mas existem muitas outras no mercado. Conduzimos as nossas medições da seguinte forma:
- Frequência da sonda: Fazemos a sondagem dos nossos nós front-end a cada minuto.
- Localização das sondas: Esta configuração é configurável; atualmente utilizamos várias sondas na América do Norte e Europa.
- Definição de “Down”: Se uma verificação de sonda falhar, o nó é marcado como Down Não confirmado e, em seguida, uma segunda sonda geograficamente separada executa uma verificação. Se a segunda verificação falhar, o nó é marcado down para efeitos de cálculo do SLO. O nó continuará a ser marcado como down enquanto solicitações de sondagem consecutivas registrarem erros.
Como calcular SLOs a partir de dados de monitoramento
Finalmente, documentamos cuidadosamente a forma como calculamos o SLO a partir dos dados brutos que recebemos do Pingdom. Por exemplo, especificamos como contabilizar as janelas de manutenção: não podíamos assumir que todos os nossos centenas de milhões de usuários sabiam das nossas janelas de manutenção publicadas. Os usuários não informados experimentariam, portanto, estas janelas como um tempo de inatividade genérico e inexplicável, portanto, nossos cálculos de SLO trataram a manutenção como um tempo de inatividade.
Uma vez definidos os nossos SLOs, tivemos que fazer algo com eles. Queríamos que os SLOs conduzissem mudanças de software e operações que tornassem os nossos clientes mais felizes e os mantivessem felizes. Qual a melhor forma de fazer isso?
Usamos o conceito de SLO/orçamento de erro como um método para alocar recursos daqui para frente. Por exemplo, se falhamos com o SLO no mês passado, esse comportamento nos ajuda a dar prioridade a correções relevantes, melhorias, e correções de bugs. Mantemos isto simples: equipes do Evernote e do Google efetuam uma revisão mensal do desempenho do SLO. Nesta reunião, analisamos o desempenho do SLO do mês anterior e analisamos detalhadamente quaisquer interrupções. Com base nesta análise do mês passado, definimos itens de ação para melhorias que podem não ter sido capturadas através do processo regular de análise da causa raiz.
Ao longo deste processo, o nosso princípio orientador tem sido “O perfeito é inimigo do bom”. Mesmo quando os SLOs não são perfeitos, eles são suficientemente bons para orientar as melhorias ao longo do tempo. Um SLO “perfeito” seria aquele que mede todas as interações possíveis do usuário com o nosso serviço e considera todos os casos extremos. Embora esta seja uma grande ideia no papel, levaria muitos meses para ser alcançada (se fosse mesmo possível atingir a perfeição) – tempo que poderíamos usar para melhorar o serviço. Em vez disso, selecionamos um SLO inicial que cobria a maioria, mas não todas as interações dos usuários, o que era um bom indicador da qualidade do serviço.
Desde que começamos, revisamos os nossos SLOs duas vezes, de acordo com os sinais das nossas revisões internas de serviço e em resposta a interrupções com impacto no cliente. Uma vez que não tínhamos como objetivo, desde o início, SLOs perfeitos, estávamos confortáveis em fazer alterações para nos alinharmos melhor com o negócio. Para além da nossa revisão mensal Evernote/Google do desempenho SLO, estabelecemos um ciclo de revisão SLO de seis meses, que atinge o equilíbrio certo entre a alteração de SLOs com muita frequência e deixá-los obsoletos. Ao rever os nossos SLOs, aprendemos também que é importante equilibrar o que se gostaria de medir com o que é possível medir.
Desde a introdução dos SLOs, a relação entre as nossas operações e as equipes de desenvolvimento melhorou de forma sutil, mas notavelmente. As equipes têm agora uma medida comum de sucesso: eliminar a interpretação humana da qualidade do serviço (QoS) permitiu a ambas as equipes manter a mesma visão e os mesmos padrões. Para dar apenas um exemplo, os SLOs proporcionaram um terreno comum quando tivemos que facilitar vários lançamentos numa linha de tempo comprimida em 2017. Enquanto caçamos um bug complexo, o desenvolvimento de produtos solicitou que repartíssemos o nosso lançamento semanal normal por várias janelas separadas, cada uma das quais teria um impacto potencial nos clientes. Aplicando um cálculo SLO ao problema e removendo a subjetividade humana do cenário, fomos capazes de quantificar melhor o impacto do cliente e reduzir as nossas janelas de lançamento de cinco para duas, para minimizar a dor do cliente.
Quebrando a barreira SLO entre o Cliente e o Provedor de Nuvem
Uma barreira virtual entre as preocupações do cliente e do provedor de nuvem pode parecer natural ou inevitável. Enquanto o Google tem SLOs e SLAs (acordos de nível de serviço) para as plataformas GCP em que gerimos o Evernote, o Evernote tem os seus próprios SLOs e SLAs. Nem sempre se espera que duas equipes de engenharia deste tipo sejam informadas sobre os SLAs uma da outra.
O Evernote nunca quis tal barreira. Claro que poderíamos ter construído uma parede divisória, baseando os nossos SLOs e SLAs nas métricas GCP subjacentes. Em vez disso, desde o início, queríamos que o Google compreendesse quais as características de desempenho que eram mais importantes para nós, e por quê. Queríamos alinhar os objetivos do Google com os nossos, e que ambas as empresas encarassem os sucessos e fracassos do Evernote em termos de confiabilidade como responsabilidades compartilhadas. Para conseguir isso, precisávamos de uma maneira de:
- Alinhar objetivos
- Assegurar que o nosso parceiro (neste caso, Google) compreendeu realmente o que é importante para nós
- Compartilhar sucessos e fracassos
A maioria dos provedores de serviços gerencia os SLO/SLAs publicados para seus serviços em nuvem. Trabalhar nesse contexto é importante, mas não pode representar de forma holística o quão bem nosso serviço está sendo executado no ambiente do provedor de nuvem.
Por exemplo, um determinado provedor de nuvem provavelmente executa centenas de milhares de máquinas virtuais a nível mundial, que eles gerenciam para tempo de atividade e disponibilidade. O GCP promete 99,95% de disponibilidade para o Compute Engine (ou seja, as suas máquinas virtuais). Mesmo quando os gráficos GCP SLO estão verdes (ou seja, acima de 99,95%), a visão do Evernote sobre o mesmo SLO pode ser muito diferente: porque a nossa abrangência de máquinas virtuais é apenas uma pequena percentagem do número global de GCP, as interrupções isoladas para a nossa região (ou isoladas por outras razões) podem ser “perdidas” no rollup geral a um nível global.
Para corrigir cenários como este, compartilhamos o nosso SLO e o desempenho em tempo real em relação ao SLO com o Google. Como resultado, tanto a equipe do Google CRE como a Evernote trabalham com os mesmos painéis de desempenho. Este pode parecer um ponto muito simples, mas provou ser uma forma bastante poderosa de conduzir um comportamento verdadeiramente centrado no cliente. Como resultado, em vez de receber notificações genéricas do tipo “Serviço X está lento”, o Google fornece-nos notificações mais específicas para o nosso ambiente. Por exemplo, para além de um ambiente genérico “ambiente de balanceamento de carga do GCP está lento hoje”, também seremos informados de que esse problema está causando um impacto de 5% no SLO do Evernote. Esta relação também ajuda as equipes do Google, que podem ver como as suas ações e decisões têm impacto nos clientes.
Essa relação de mão dupla também nos deu uma estrutura muito eficaz para dar suporte a grandes incidentes. Na maioria das vezes, o modelo habitual de tickets P1-P5 e canais de suporte regulares funciona bem e nos permite manter um bom atendimento e um bom relacionamento com o Google. Mas todos nós sabemos que há momentos em que um ticket P1 (“impacto importante para nossos negócios”) não é suficiente – os momentos em que todo o seu serviço está em linha e você enfrenta um impacto comercial prolongado.
Em momentos como esses, nossos SLOs compartilhados e o relacionamento com a equipe CRE tornam-se realidade. Temos um entendimento comum de que se o impacto do SLO for suficientemente elevado, ambas as partes tratarão a questão como um ticket P1 com tratamento especial. Com bastante frequência, isto significa que a equipe CRE do Evernote e do Google se mobilizam rapidamente numa ponte de conferência compartilhada. A equipe CRE do Google monitora o SLO que definimos e acordamos conjuntamente, permitindo-nos permanecer em sincronia em termos de priorização e respostas adequadas.
Estado atual
Depois de utilizar ativamente os SLOs durante cerca de nove meses, o Evernote já está na versão 3 da sua prática SLO. A próxima versão de SLOs irá progredir a partir do nosso SLO de tempo de atividade simples. Planejamos começar a sondar chamadas API individuais e contabilizar a visão de métricas/desempenho do cliente para que possamos representar ainda melhor a QoS do usuário.
Ao fornecer uma maneira padrão e definida de medir QoS, os SLOs permitiram que o Evernote se concentrasse melhor em como nosso serviço está sendo executado. Agora podemos ter conversas baseadas em dados – tanto internamente, como com o Google – sobre o impacto das interrupções, o que nos permite impulsionar melhorias no serviço, resultando em equipes de suporte mais eficazes e clientes mais satisfeitos.
A história do SLO do Home Depot
Escrito por William Bonnell, The Home Depot
The Home Depot (THD) é a maior varejista de artigos para o lar do mundo: temos mais de 2.200 lojas na América do Norte, cada uma com mais de 35.000 produtos exclusivos (e complementados com mais de 1,5 milhão de produtos online). Nossa infraestrutura hospeda uma variedade de aplicações de software que suportam cerca de 400.000 associados e processam mais de 1,5 bilhão de transações de clientes por ano. As lojas estão profundamente integradas com uma cadeia de suprimentos global e um website de comércio eletrônico que recebe mais de 2 mil milhões de visitas por ano.
Numa recente atualização da nossa abordagem operacional destinada a aumentar a velocidade e a qualidade do nosso desenvolvimento de software, a THD impulsionou o desenvolvimento de software Agile e mudou a forma como projetamos e gerenciamos nosso software. Passamos de equipes de suporte centralizadas que davam suporte a grandes pacotes de software monolíticos para uma arquitetura de microsserviços liderada por pequenas equipes de desenvolvimento de software operadas de forma independente. Como resultado, o nosso sistema tinha agora pedaços menores de software em constante mudança, que também precisava ser integrado em toda a pilha.
Nossa mudança para microsserviços foi complementada por uma mudança para uma nova “cultura de liberdade e responsabilidade” de propriedade full-stack. Esta abordagem dá aos programadores liberdade para enviar o código quando querem, mas também os torna conjuntamente responsáveis pelas operações do seu serviço. Para que este modelo de propriedade conjunta funcione, as equipes de operações e de desenvolvimento precisam falar uma linguagem comum que promova a responsabilidade e ultrapasse a complexidade: objetivos de nível de serviço. Os serviços que dependem uns dos outros precisam saber informações como:
- Quão confiável é o seu serviço? É construído para três 9s, três 9s e meio, ou quatro 9s (ou melhor)? Há tempo de inatividade planejado?
- Que tipo de latência posso esperar nos limites superiores?
- Você pode lidar com o volume de solicitações que vou enviar? Como se lida com a sobrecarga? O seu serviço atingiu os seus SLOs ao longo do tempo?
Se cada serviço pudesse fornecer respostas transparentes e consistentes a estas questões, as equipes teriam uma visão clara das suas dependências, o que permite uma melhor comunicação e uma maior confiança e responsabilidade entre as equipes.
O Projeto de Cultura SLO
Antes de começarmos esta mudança no nosso modelo de serviço, a The Home Depot não tinha uma cultura de SLOs. As ferramentas de monitoramento e os painéis de controle eram abundantes, mas estavam espalhados por toda parte e não rastreavam os dados ao longo do tempo. Nem sempre fomos capazes de localizar o serviço na raiz de uma determinada interrupção. Muitas vezes, começamos a solucionar problemas no serviço voltado para o usuário e trabalhamos para trás até encontrar o problema, desperdiçando inúmeras horas. Se um serviço exigia tempo de inatividade planejado, seus serviços dependentes eram surpreendidos. Se uma equipe precisasse construir um serviço de três 9s e meio, eles não saberiam se o serviço do qual dependiam fortemente poderia apoiá-los com um tempo de atividade ainda melhor (quatro 9s). Estas desconexões causaram confusão e desilusão entre as nossas equipes de desenvolvimento de software e de operações.
Precisávamos resolver estas desconexões construindo uma cultura comum de SLOs. Fazer isso exigia uma estratégia abrangente para influenciar pessoas, processos e tecnologia. Os nossos esforços abrangeram quatro áreas gerais:
Vernáculo comum
Defina SLOs no contexto do THD. Defina como medi-los de forma consistente
Espalhe a palavra por toda a empresa.
- Crie material de treinamento para vender por que os SLOs são importantes, road shows em toda a empresa, blogs internos e materiais promocionais, como camisetas e adesivos.
- Recrute alguns adotantes iniciais para implementar SLOs e demonstrar o valor para outras pessoas.
- Estabeleça um acrônimo atraente (VALET; conforme discutido posteriormente) para ajudar a espalhar a ideia.
- Crie um programa de treinamento (FiRE Academy: Fundamentos em Engenharia de Confiabilidade) para treinar desenvolvedores em SLOs e outros conceitos de confiabilidade.
Automação
Para reduzir o atrito de adoção, implemente uma plataforma de coleta de métricas para coletar automaticamente indicadores de nível de serviço para qualquer serviço implantado na produção. Estes SLIs podem mais tarde ser transformados mais facilmente em SLOs.
Incentivo
Estabeleça metas anuais para todos os gerentes de desenvolvimento para definir e medir SLOs para seus serviços.
O estabelecimento de um vernáculo comum foi fundamental para colocar todos na mesma página. Queríamos também manter este quadro tão simples quanto possível para ajudar a difundir a ideia mais rapidamente. Para começar, fizemos uma análise crítica das métricas que monitoramos através dos nossos vários serviços e descobrimos alguns padrões. Cada serviço monitorava alguma forma do seu volume de tráfego, latência, erros, e métricas de utilização que mapeiam de perto os Quatro Sinais Dourados do Google SRE. Além disso, muitos serviços monitoravam o tempo de atividade ou a disponibilidade de forma distinta dos erros. Infelizmente, de um modo geral, todas as categorias de métricas foram monitoradas de forma inconsistente, foram nomeadas de forma diferente, ou tinham dados insuficientes.
Nenhum dos nossos serviços tinha SLOs. A métrica mais próxima que os nossos sistemas de produção tinham de um SLO voltado para o cliente eram os tickets de suporte. A principal (e muitas vezes única) forma de medirmos a confiabilidade das aplicações implantadas nas nossas lojas era através do rastreio do número de chamadas de apoio recebidas pela nossa central de suporte interna.
O nosso primeiro conjunto de SLOs
Não podíamos criar SLOs para todos os aspectos de nossos sistemas que pudessem ser medidos, então tivemos que decidir quais métricas ou SLIs também deveriam ter SLOs.
Disponibilidade e latência para chamadas API
Decidimos que cada microsserviço tinha que ter disponibilidade e latência de SLOs para as suas chamadas API que eram chamadas por outros microsserviços. Por exemplo, o microsserviço Carrinho chamou o microsserviço Inventário. Para essas chamadas API, o microsserviço Inventário publicou SLOs que o microsserviço Carrinho (e outros microsserviços que precisavam de Inventário) podia consultar para determinar se o microsserviço Inventário podia satisfazer os seus requisitos de confiabilidade.
Utilização da infraestrutura
As equipes da THD medem a utilização da infraestrutura de diferentes maneiras, mas a medição mais típica é a utilização da infraestrutura em tempo real com uma granularidade de um minuto. Decidimos contra a definição de SLOs de utilização por algumas razões. Para começar, os microsserviços não estão excessivamente preocupados com esta métrica – os seus usuários não se preocupam realmente com a utilização desde que consiga lidar com o volume de tráfego, seu microsserviço está ativo, está respondendo rapidamente, não está gerando erros e você não corre o risco de ficar sem capacidade. Além disso, a nossa iminente mudança para a nuvem significava que a utilização seria menos preocupante, de modo que o planejamento de custos ofuscaria o planejamento de capacidade. (Ainda precisaríamos monitorar a utilização e realizar o planejamento de capacidade, mas não precisamos incluí-lo em nossa estrutura de SLO).
Volume de tráfego
Como a THD ainda não tinha uma cultura de planejamento de capacidades, precisávamos de um mecanismo para que as equipes de software e de operações comunicassem quanto volume seu serviço poderia suportar. O tráfego era fácil de definir como solicitações para um serviço, mas precisávamos decidir se deveríamos rastrear solicitações médias por segundo, solicitações de pico por segundo ou o volume de solicitações durante o período do relatório. Decidimos seguir os três e deixar cada serviço selecionar a métrica mais apropriada. Debatemos se deveríamos ou não definir um SLO para o volume de tráfego porque esta métrica é determinada pelo comportamento do usuário, em vez de fatores internos que podemos controlar. Por fim, decidimos que, como varejistas, precisávamos dimensionar nosso serviço para picos como a Black Friday, então definimos um SLO de acordo com a capacidade de pico esperada.
Latência
Deixamos cada serviço definir o seu SLO para a latência e determinar onde melhor o medir. O nosso único pedido era que um serviço complementasse nosso monitoramento de desempenho de caixa branca comum com monitoramento de caixa preta para detectar problemas causados pela rede ou outras camadas, como caches e proxies, que falham fora do microsserviço. Decidimos também que os percentis eram mais apropriados do que as médias aritméticas. No mínimo, os serviços precisavam atingir um alvo do percentil 90; os serviços voltados para o usuário tinham um alvo preferencial de 95º e/ou 99º percentil.
Erros
Os erros eram de certa forma complicados de explicar. Como estávamos lidando principalmente com serviços da web, tivemos que padronizar o que constitui um erro e como retornar erros. Se um serviço web encontrasse um erro, naturalmente padronizávamos em códigos de resposta HTTP:
- Um serviço não deve indicar um erro no corpo de uma resposta 2xx; pelo contrário, deve gerar um 4xx ou um 5xx.
- Um erro causado por um problema com o serviço (por exemplo, falta de memória) deve gerar um erro 5xx.
- Um erro causado pelo cliente (por exemplo, o envio de uma solicitação malformada) deve gerar um erro 4xx.
Após muita deliberação, decidimos rastrear erros 4xx e 5xx, mas usamos erros 5xx apenas para definir SLOs. À semelhança da nossa abordagem para outros elementos relacionados com SLO, mantivemos esta dimensão genérica para que diferentes aplicações a pudessem utilizar em contextos diferentes. Por exemplo, para além dos erros HTTP, os erros para um serviço de processamento em lote podem ser o número de registros que não foram processados.
Tickets
Como mencionado anteriormente, os tickets eram originalmente a principal forma de avaliarmos a maior parte do nosso software de produção. Por razões históricas, decidimos continuar rastreando tickets juntamente com os nossos outros SLOs. Podemos considerar esta métrica como análoga a algo como “nível de operação de software”.
VALET
Resumimos os nossos novos SLOs numa sigla útil: VALET.
Volume (tráfego)
Qual o volume de negócios que o meu serviço pode suportar?
Disponibilidade
O serviço está pronto quando eu preciso dele?
Latência
O serviço responde rapidamente quando eu o utilizo?
Erros
O serviço gera um erro quando eu o uso?
Tickets
O serviço requer intervenção manual para completar minha solicitação?
Evangelização de SLOs
Armados com um acrônimo fácil de lembrar, nos propusemos a evangelizar os SLOs para a empresa:
- Por que os SLOs são importantes
- Como os SLOs apoiam a nossa cultura de “liberdade e responsabilidade
- O que deve ser medido
- O que fazer com os resultados
Uma vez que os desenvolvedores eram agora responsáveis pelo funcionamento do seu software, precisavam estabelecer SLOs para demonstrar a sua capacidade de construir e oferecer suporte a softwares confiáveis e também para se comunicar com os consumidores de seus serviços e gerentes de produtos para serviços orientado para o cliente. No entanto, a maioria deste público não estava familiarizada com conceitos como SLAs e SLOs, então eles precisavam ser educados sobre essa nova estrutura de VALET.
Uma vez que precisávamos obter apoio executivo para a nossa mudança para os SLOs, a nossa campanha de educação começou com a liderança sênior. Em seguida, nos reunimos com as equipes de desenvolvimento, uma a uma, para defender os valores dos SLOs. Encorajamos as equipes a migrarem de seus mecanismos de rastreamento de métricas personalizados (que eram frequentemente manuais) para a estrutura VALET. Para manter a dinâmica, enviamos um relatório semanal de SLO em formato VALET, que combinamos com comentários sobre conceitos gerais de confiabilidade e lições aprendidas em eventos internos para a liderança sênior. Isto também ajudou a enquadrar métricas empresariais como ordens de compra criadas (Volume) ou ordens de compra que não conseguiram processar (Erros) em termos de VALET.
Também escalamos o nosso evangelismo de várias maneiras:
- Criamos um site WordPress interno para hospedar blogs sobre VALET e confiabilidade, com links para recursos úteis.
- Realizamos Tech Talks internos (incluindo um orador convidado do Google SRE) para discutir conceitos gerais de confiabilidade e como medir com VALET.
- Realizamos uma série de workshops de treinamento VALET (que mais tarde evoluiriam para FiRE Academy), e abrimos o convite a quem quisesse participar. A participação nestes seminários permaneceu forte durante vários meses.
- Até criamos adesivos e camisetas VALET para laptop para apoiar uma campanha de marketing interna abrangente.
Logo todos na empresa conheceram o VALET, e a nossa nova cultura de SLOs começou a instalar-se. A implementação do SLO começou a ser considerada oficialmente nas avaliações anuais de desempenho da THD para gerentes de desenvolvimento. Enquanto cerca de 50 serviços recolhiam e apresentavam relatórios semanais sobre os seus SLOs, nós armazenávamos as métricas ad hoc numa planilha. Embora a ideia de VALET tivesse pegado fogo como um incêndio, precisávamos automatizar a coleta de dados para promover a adoção generalizada.
Automatizando a coleta de dados VALET
Embora a nossa cultura de SLOs tivesse agora uma base forte, a automatização da recolha de dados VALET aceleraria a adoção de SLO.
Relatórios TPS
Construímos uma estrutura para capturar automaticamente dados VALET para qualquer serviço que tenha sido implantado no nosso novo ambiente GCP. Chamamos a esta estrutura Relatórios TPS, uma brincadeira com o termo que utilizamos para testes de volume e desempenho (transações por segundo), e, claro, para zombar da ideia de que vários gestores poderiam querer revisar estes dados. Construímos a estrutura dos Relatórios TPS em cima da plataforma de base de dados BigQuery da GCP. Todos os logs gerados pelo nosso frontend de servidores da Web foram introduzidos no BigQuery para processamento pelos Relatórios TPS. Eventualmente, também incluímos métricas de vários outros sistemas de monitoramento, como a sonda de disponibilidade do Stackdriver.
Os Relatórios TPS transformaram estes dados em métricas VALET de hora em hora, que qualquer pessoa poderia consultar. Os serviços recém-criados eram automaticamente registados nos Relatórios TPS e, portanto, podiam ser imediatamente consultados. Uma vez que os dados eram todos armazenados em BigQuery, podíamos reportar eficientemente as métricas VALET ao longo de intervalos de tempo. Utilizamos estes dados para construir uma variedade de relatórios e alertas automatizados. A integração mais interessante foi um chatbot que nos permitiu reportar diretamente sobre a VALET de serviços numa plataforma de chat comercial. Por exemplo, qualquer serviço podia exibir VALET na última hora, VALET versus semana anterior, serviços fora de SLO, e uma variedade de outros dados interessantes diretamente no canal de chat.
Serviço VALET
O nosso passo seguinte foi criar uma aplicação VALET para armazenar e reportar dados SLO. Como os SLOs são mais bem aproveitados como uma ferramenta de tendências, o serviço rastreia os SLOs em granularidade diária, semanal e mensal. Note que os nossos SLOs são uma ferramenta de tendências que podemos utilizar para orçamentos de erro, mas não estão diretamente ligados aos nossos sistemas de monitoramento. Em vez disso, temos uma variedade de plataformas de monitoramento diferentes, cada uma com o seu próprio alerta. Estes sistemas de monitoramento agregam os seus SLOs diariamente e publicam ao serviço VALET para obter tendências. O lado negativo desta configuração é que os limiares de alerta estabelecidos nos sistemas de monitoramento não estão integrados nos SLOs; contudo, temos a flexibilidade de alterar os sistemas de monitoramento conforme necessário.
Antecipando a necessidade de integrar VALET com outras aplicações que não funcionam em GCP, criamos uma camada de integração VALET que fornece uma API para coletar dados agregados do VALET para um serviço diariamente. O TPS Reports foi o primeiro sistema a se integrar com o serviço VALET, e eventualmente integramos com uma variedade de plataformas de aplicação no local (mais de metade dos serviços registados em VALET).
Dashboard VALET
O Dashboard VALET (mostrado na Figura 3-1) é a nossa UI para visualizar e relatar estes dados e é relativamente simples. Ele permite que os usuários:
- Registre um novo serviço. Isso normalmente significa atribuir o serviço a uma ou mais URLs, que já podem ter dados de VALET coletados.
- Estabeleça objetivos SLO para qualquer uma das cinco categorias VALET.
- Adicione novos tipos de métricas em cada uma das categorias VALET. Por exemplo, um serviço pode rastrear a latência no percentil 99, enquanto outro rastreia a latência no percentil 90 (ou ambos). Ou, um sistema de processamento backend pode rastrear o volume a um nível diário (ordens de compra criadas num dia), enquanto um frontend de serviço ao cliente pode rastrear as transações de pico por segundo.
O Dashboard VALET permite os usuários relatar SLOs para vários serviços de uma só vez e dividir e segmentar os dados de várias maneiras. Por exemplo, uma equipe pode visualizar as estatísticas de todos os seus serviços que falharam com o SLO na semana passada. Uma equipe que procura revisar o desempenho dos serviços pode ver a latência de todos os seus serviços e os serviços dos quais dependem. O Dashboard VALET armazena os dados numa simples base de dados Cloud SQL, e os programadores utilizam uma popular ferramenta de relatórios comerciais para construir relatórios.
Estes relatórios tornaram-se a base para uma nova melhor prática com os programadores: revisões regulares SLO dos seus serviços (normalmente, semanais ou mensais). Com base nestas revisões, os programadores podem criar itens de ação para devolver um serviço ao seu SLO, ou talvez decidir que um SLO irrealista precisa ser ajustado.
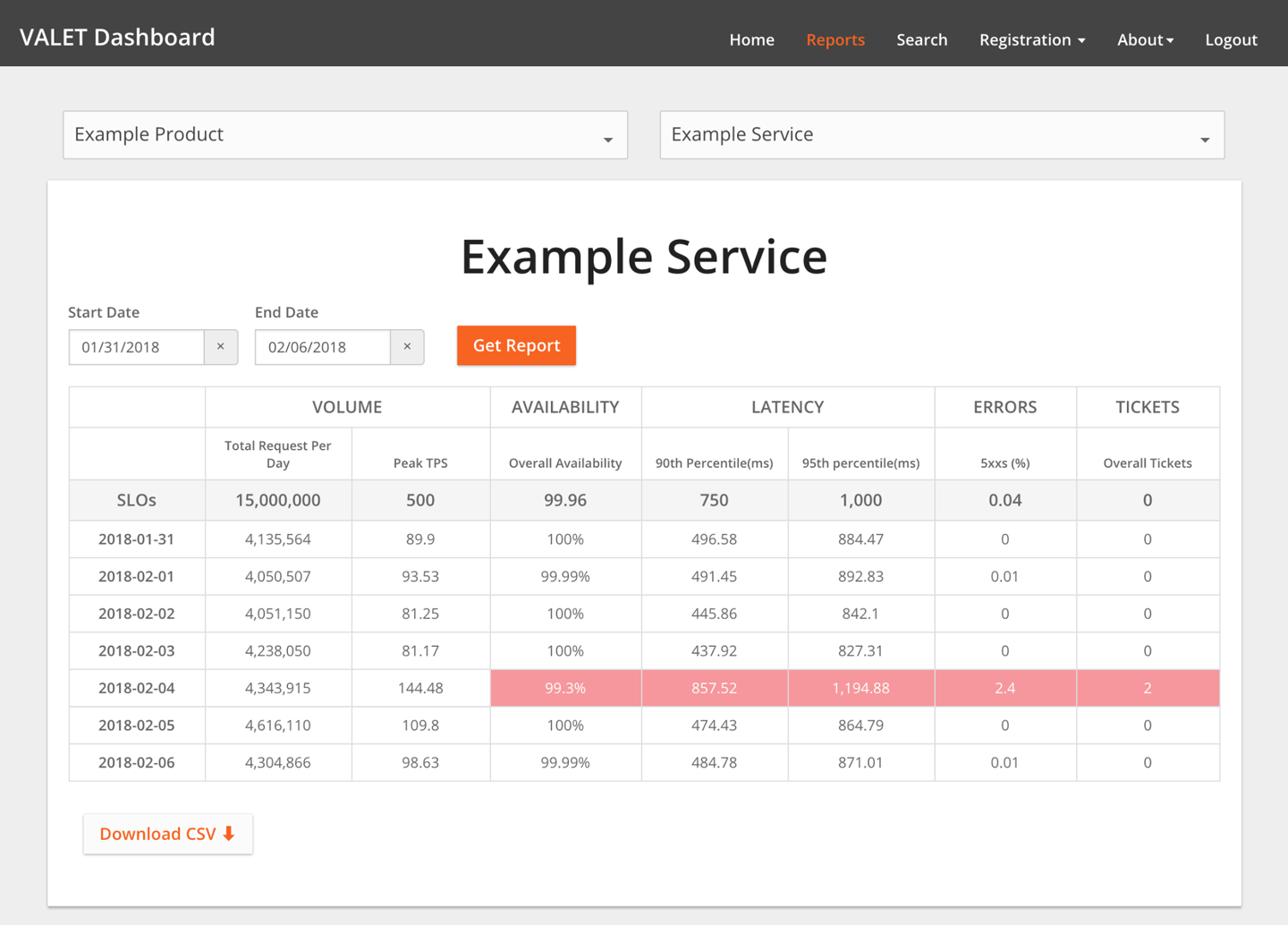
Figura 3-1.O Painel VALET
A Proliferação de SLOs
Depois que os SLOs foram firmemente consolidados na mente coletiva da organização e a automação e os relatórios eficazes foram implementados, novos SLOs proliferaram rapidamente. Depois de rastrear SLOs para cerca de 50 serviços no início do ano, no final do ano estávamos rastreando SLOs para 800 serviços, com cerca de 50 novos serviços por mês sendo registrados com VALET.
Uma vez que o VALET nos permitiu escalar a adoção de SLO através do THD, o esforço de tempo necessário para desenvolver a automação valeu bem a pena. No entanto, outras empresas não devem ter medo de adotar uma abordagem baseada em SLO se não puderem desenvolver uma automação igualmente complexa. Embora a automação tenha proporcionado benefícios extra ao THD, há vantagens em escrever apenas SLOs em primeiro lugar.
Aplicando VALET a aplicações em lote
À medida que desenvolvemos relatórios sólidos em torno dos SLOs, descobrimos algumas utilizações adicionais para o VALET. Com um pequeno ajuste, as aplicações em lote podem enquadrar-se nesta estrutura da seguinte forma:
Volume
O volume de registros processados
Disponibilidade
Com que frequência (em porcentagem) o trabalho foi concluído em um determinado tempo
Latência
O tempo necessário para a execução do trabalho
Erros
Os registros que não foram processados
Tickets
O número de vezes que um operador tem que corrigir manualmente os dados e reprocessar um trabalho
Utilizando VALET em testes
Como estávamos desenvolvendo uma cultura SRE ao mesmo tempo, descobrimos que o VALET suportava nossa automação de testes destrutivos (engenharia do caos) em nossos ambientes de teste. Com a estrutura dos Relatórios TPS em vigor, pudemos executar automaticamente testes destrutivos e registrar o impacto (ou, esperamos, a falta de impacto) nos dados VALET do serviço.
Aspirações Futuras
Com 800 serviços (e em crescimento) coletando dados de VALET, temos muitos dados operacionais úteis à nossa disposição. Temos várias aspirações para o futuro.
Agora que estamos coletando SLOs efetivamente, queremos usar esses dados para agir. O nosso próximo passo é uma cultura de orçamento de erro semelhante à do Google, em que uma equipe deixa de enviar novas funcionalidades (além de melhorias na confiabilidade) quando um serviço está fora do SLO. Para proteger as demandas de velocidade de nossos negócios, teremos que nos esforçar para encontrar um bom equilíbrio entre o período de relatório de SLO (semanal ou mensal) e a frequência de violação de SLOs. Como muitas empresas que adotam orçamentos de erro, estamos avaliando os prós e contras de janelas contínuas versus janelas fixas.
Queremos aperfeiçoar ainda mais o VALET para rastrear endpoints detalhados e os consumidores de um serviço. Atualmente, mesmo que um determinado serviço tenha vários endpoints, rastreamos o VALET apenas em todo o serviço. Como resultado, é difícil distinguir entre diferentes operações (por exemplo, uma escrita no catálogo versus uma leitura no catálogo; enquanto monitoramos e alertamos sobre estas operações separadamente, não rastreamos SLOs). Da mesma forma, gostaríamos também de diferenciar os resultados VALET para diferentes consumidores de um serviço.
Embora atualmente acompanhemos SLOs de latência na camada de serviço da Web, gostaríamos também de rastrear um SLO de latência para os usuários finais. Esta medida capturaria como fatores como etiquetas de terceiros, latência da Internet, e cache CDN afetam quanto tempo leva para uma página iniciar e concluir a renderização.
Gostaríamos também de estender os dados VALET a implementações de aplicações. Especificamente, gostaríamos de utilizar a automação para verificar se o VALET está dentro da tolerância antes de implementar uma mudança para o próximo servidor, zona, ou região.
Começamos a coletar informações sobre dependências de serviço e criamos um protótipo de um gráfico visual que mostra onde não estamos atingindo as métricas de VALET ao longo de uma árvore de chamadas. Esse tipo de análise se tornará ainda mais fácil com as plataformas de rede de serviços emergentes.
Finalmente, acreditamos firmemente que os SLOs para um serviço devem ser definidos pelo proprietário do negócio do serviço (muitas vezes chamado de gerente de produto) com base em sua importância para o negócio. No mínimo, queremos que os proprietários da empresa estabeleçam a exigência de tempo de atividade de um serviço e utilizem esse SLO como um objetivo compartilhado entre a gestão e o desenvolvimento do produto. Embora os tecnólogos considerassem o VALET intuitivo, o conceito não era tão intuitivo para os gestores de produto. Estamos nos esforçando para simplificar os conceitos de VALET usando terminologia relevante para eles: simplificamos o número de opções de tempo de atividade e fornecemos métricas de exemplo. Também enfatizamos o investimento significativo necessário para passar de um nível para outro. Aqui está um exemplo de métricas VALET simplificadas que podemos fornecer:
- 99.5%: Aplicações que não são utilizadas por associados da loja ou por um MVP de um novo serviço
- 99.9%: Adequado para a maioria dos sistemas não vendidos na THD
- 99.95%: Sistemas de venda (ou serviços que apoiam sistemas de venda)
- 99.99%: Serviços de infraestruturas compartilhadas
Lançar métricas em termos comerciais e compartilhar um objetivo visível (um SLO!) entre produto e desenvolvimento reduzirá muitas expectativas desalinhadas sobre confiabilidade muitas vezes vistas em grandes empresas.
Resumo
Introduzir um novo processo, quanto mais uma nova cultura, a uma grande empresa requer uma boa estratégia, a adesão de executivos, um evangelismo forte, padrões de adoção fácil e, acima de tudo, paciência. Pode levar anos até que uma mudança significativa como os SLOs se estabeleça firmemente numa empresa. Gostaríamos de enfatizar que The Home Depot é uma empresa tradicional; se conseguirmos introduzir uma mudança tão grande com sucesso, você também pode. Você também não precisa abordar essa tarefa de uma só vez. Embora tenhamos implementado SLOs peça por peça, o desenvolvimento de uma estratégia de evangelismo abrangente e uma clara estrutura de incentivos facilitou uma rápida transformação: passamos de 0 a 800 serviços apoiados pelo SLO em menos de um ano.
Conclusão
SLOs e orçamentos de erro são conceitos poderosos que ajudam a resolver muitos conjuntos de problemas diferentes. Estes estudos de caso da Evernote e The Home Depot apresentam exemplos muito reais de como a implementação de uma cultura SLO pode aproximar o desenvolvimento de produtos e operações. Isso pode facilitar a comunicação e informar melhor as decisões de desenvolvimento. Em última análise, resultará em melhores experiências para os seus clientes – sejam eles internos, externos, humanos, ou outros serviços.
Estes dois estudos de caso realçam que a cultura SLO é um processo contínuo e não uma correção ou solução única. Embora partilhem os fundamentos filosóficos, os estilos de medição de THD e Evernote, SLIs, SLOs, e detalhes de implementação são marcadamente diferentes. Ambas as histórias complementam a própria tomada de posição do Google sobre SLOs, demonstrando que a implementação de SLO não precisa ser específica para o Google. Tal como estas empresas adaptaram os SLOs aos seus próprios ambientes únicos, o mesmo pode acontecer com outras empresas e organizações.
Fonte: Google SRE Work Book