Escrito por John Lunney, Robert van Gent, e Scott Ritchie
Com Diane Bates e Niall Richard Murphy
” Um sistema complexo que funciona invariavelmente evoluiu de um sistema simples que funcionou. “
Lei de Gall
A simplicidade é um objetivo importante para os SREs, pois está fortemente correlacionado com a confiabilidade: software simples quebra com menos frequência e é mais fácil e rápido de corrigir quando ele quebra. Sistemas simples são mais fáceis de entender, mais fáceis de manter e mais fáceis de testar.
Para os SREs, a simplicidade é um objetivo de ponta a ponta: deve se estender além do próprio código para a arquitetura do sistema e as ferramentas e processos usados para gerenciar o ciclo de vida do software. Este capítulo explora alguns exemplos que demonstram como os SREs podem medir, pensar e incentivar a simplicidade.
Medindo a complexidade
A medição da complexidade dos sistemas de software não é uma ciência absoluta. Há várias formas de medir a complexidade do código do software, a maioria das quais são bastante objetivas. Talvez o padrão mais conhecido e mais amplamente disponível seja a complexidade do código ciclomático, que mede o número de caminhos de código distintos por meio de um conjunto específico de instruções. Por exemplo, um bloco de código sem loops ou condicionantes tem um número de complexidade ciclomática (CCN) de 1. A comunidade de software é realmente muito boa em medir a complexidade do código, e existem ferramentas de medição para vários ambientes de desenvolvimento integrados (incluindo Visual Studio, Eclipse e IntelliJ). Estamos menos aptos a compreender se a complexidade medida resultante é necessária ou acidental, como a complexidade de um método pode influenciar um sistema maior, e que abordagens são melhores para o refactoring.
Por outro lado, as metodologias formais para medir a complexidade do sistema são raras. Poderá sentir-se tentado a tentar uma abordagem do tipo CCN de contagem do número de entidades distintas (por exemplo, microserviços) e possíveis vias de comunicação entre elas. No entanto, para a maioria dos sistemas de grande dimensão, esse número pode crescer muito rapidamente.
Alguns proxies mais práticos para complexidade em nível de sistema incluem:
Tempo de treinamento
Quanto tempo leva para um novo membro da equipe ficar de plantão? Documentação deficiente ou ausente pode ser uma fonte significativa de complexidade subjetiva.
Tempo de explicação
Quanto tempo leva para explicar uma visão abrangente de alto nível do serviço para um novo membro da equipe (por exemplo, diagramar a arquitetura do sistema em um quadro branco e explicar a funcionalidade e as dependências de cada componente)?
Diversidade administrativa
Quantas maneiras existem para definir configurações semelhantes em diferentes partes do sistema? A configuração é armazenada em um local centralizado ou em vários locais?
Diversidade de configurações implantadas
Quantas configurações exclusivas são implantadas na produção (incluindo binários, versões binárias, sinalizadores e ambientes)?
Idade
Quantos anos tem o sistema? A Lei de Hyrum afirma que, ao longo do tempo, os usuários de uma API dependem de todos os aspectos de sua implementação, resultando em comportamentos frágeis e imprevisíveis.
Embora medir a complexidade às vezes valha a pena, é difícil. No entanto, parece não haver oposição séria às observações de que:
- Em geral, a complexidade aumentará nos sistemas de software vivos, a menos que haja um esforço compensatório.
- Desde que esse esforço seja uma coisa que valha a pena fazer.
A simplicidade é de ponta a ponta, e os SREs são bons para isso
Geralmente, os sistemas de produção não são projetados de forma holística; em vez disso, eles crescem organicamente. Eles acumulam componentes e conexões ao longo do tempo à medida que as equipes adicionam novos recursos e lançam novos produtos. Embora uma única mudança possa ser relativamente simples, cada mudança tem impacto sobre os componentes à sua volta. Portanto, a complexidade geral pode rapidamente se tornar esmagadora. Por exemplo, adicionar novas tentativas em um componente pode sobrecarregar uma base de dados e desestabilizar todo o sistema, ou tornar mais difícil raciocinar sobre o caminho que uma determinada consulta segue através do sistema.
Frequentemente, o custo da complexidade não afeta diretamente o indivíduo, a equipe ou a função que o apresenta — em termos econômicos, a complexidade é uma externalidade. Em vez disso, a complexidade afeta aqueles que continuam a trabalhar nela e em torno dela. Assim, é importante ter um campeão para a simplicidade do sistema de ponta a ponta.
Os SREs são adequados para essa função porque seu trabalho exige que eles tratem o sistema como um todo. Além de oferecer suporte a seus próprios serviços, os SREs também devem ter informações sobre os sistemas com os quais seu serviço interage. As equipes de desenvolvimento de produtos do Google geralmente não têm visibilidade dos problemas em toda a produção, por isso consideram importante consultar os SREs para obter conselhos sobre o design e a operação de seus sistemas.
Nota
Ação do leitor: Antes de um engenheiro ficar de plantão pela primeira vez, incentive-o a desenhar (e redesenhar) diagramas de sistema. Mantenha um conjunto canônico de diagramas em sua documentação: eles são úteis para novos engenheiros e ajudam os engenheiros mais experientes a acompanhar as mudanças.
Em nossa experiência, os desenvolvedores de produtos geralmente acabam trabalhando em um subsistema ou componente restrito. Como resultado, eles não têm um modelo mental para o sistema geral e suas equipes não criam diagramas de arquitetura ao nível do sistema. Esses diagramas são úteis porque ajudam os membros da equipe a visualizar as interações do sistema e articular problemas usando um vocabulário comum. Na maioria das vezes, encontramos a equipe do SRE para o serviço desenhar os diagramas de arquitetura ao nível do sistema.
Nota
Ação do leitor: Certifique-se de que um SRE revise todos os principais documentos de design e que os documentos da equipe mostrem como o novo design afeta a arquitetura do sistema. Se um design adiciona complexidade, o SRE pode sugerir alternativas que simplifiquem o sistema.
Estudo de Caso 1: Simplicidade de API de Ponta-a-Ponta
Background
Em uma função anterior, um dos autores do capítulo trabalhou em uma startup que usava uma estrutura de dados bag chave/valor nas suas bibliotecas centrais. Os RPCs (chamadas de procedimento remoto) pegaram um bag e devolveram um bag; os parâmetros reais foram armazenados como pares chave/valor dentro do bag. As bibliotecas centrais suportavam operações comuns em bagS, tais como serialização, criptografia, e log. Todas as bibliotecas e APIs principais eram extremamente simples e flexíveis — sucesso, certo?
Infelizmente, não: os clientes das bibliotecas acabaram por pagar uma penalização pela natureza abstrata dos APIs principais. O conjunto de chaves e valores (e tipos de valor) precisava ser cuidadosamente documentado para cada serviço, mas geralmente não era. Além disso, manter a compatibilidade com versões anteriores e posteriores tornou-se difícil à medida que os parâmetros eram adicionados, removidos ou alterados ao longo do tempo.
Lições aprendidas
Tipos de dados estruturados como os Buffers de Protocolo do Google ou Apache Thrift podem parecer mais complexos do que as suas alternativas abstratas de uso geral, mas resultam em soluções mais simples de ponta a ponta porque forçam decisões de projeto e documentação antecipadas.
Estudo de Caso 2: Complexidade do ciclo de vida do projeto
Quando você revisa o espaguete emaranhado do seu sistema existente, pode ser tentador substituí-lo por um sistema novo, limpo e simples que resolva o mesmo problema. Infelizmente, o custo de criar um novo sistema mantendo o atual pode não valer a pena.
Background
Borg é o sistema interno de gerenciamento de contêineres do Google. Ele executa um grande número de contêineres Linux e possui uma ampla variedade de padrões de uso: batch versus produção, pipelines versus servidores, e muito mais. Ao longo dos anos, Borg e o seu ecossistema ao redor cresceram à medida que o hardware mudava, recursos eram acrescentados, e a sua escala aumentava.
Omega destinava-se a ser uma versão de Borg mais limpa e com mais princípios que suportasse os mesmos casos de uso. No entanto, a mudança planejada de Borg para Omega teve alguns problemas sérios:
- O Borg continuou a evoluir à medida que o Omega se desenvolvia, então o Omega estava sempre perseguindo um alvo em movimento.
- As primeiras estimativas da dificuldade de melhorar Borg revelaram-se excessivamente pessimistas, enquanto as expectativas para Omega se revelaram demasiado otimistas (na prática, a grama nem sempre é mais verde).
- Não avaliamos completamente o quão difícil seria migrar de Borg para Omega. Milhões de linhas de código de configuração em milhares de serviços e muitas equipes de SRE significavam que a migração seria extremamente cara em termos de engenharia e tempo de calendário. Durante o período de migração, que provavelmente levaria anos, teríamos que dar suporte e manter os dois sistemas.
O que decidimos fazer
Eventualmente, alimentamos algumas das ideias que surgiram ao projetar o Omega de volta ao Borg. Também usamos muitos dos conceitos da Omega para impulsionar o Kubernetes, um sistema de gerenciamento de contêineres de código aberto.
Lições aprendidas
Ao considerar uma reescrita, pense no ciclo de vida completo do projeto, incluindo o desenvolvimento para um alvo em movimento, um plano de migração completo, e custos adicionais que poderá incorrer durante a janela de tempo de migração. Grandes APIs com muitos usuários são muito difíceis de migrar. Não compare o resultado esperado com o seu sistema atual. Em vez disso, compare o resultado esperado com o que o seu sistema atual seria se investisse o mesmo esforço em melhorá-lo. Às vezes, uma reescrita é o melhor caminho a seguir, mas certifique-se de pesar os custos e benefícios e não subestime os custos.
Recuperar a Simplicidade
A maior parte do trabalho de simplificação consiste na remoção de elementos de um sistema. Às vezes, a simplificação é direta (por exemplo, remover uma dependência de um dado não utilizado obtido de um sistema remoto). Outras vezes, a simplificação requer um redesenho. Por exemplo, duas partes de um sistema podem necessitar de acesso aos mesmos dados remotos. Em vez de buscá-los duas vezes, um sistema mais simples pode buscar os dados uma vez e encaminhar o resultado.
Qualquer que seja o trabalho, a liderança deve garantir que os esforços de simplificação sejam celebrados e explicitamente priorizados. A simplificação é eficiência – em vez de economizar recursos de computação ou rede, economiza tempo de engenharia e carga cognitiva. Trate projetos de simplificação bem sucedidos tal como trata os lançamentos de funcionalidades úteis, e meça e celebre igualmente a adição e remoção de código. Por exemplo, a intranet do Google exibe um selo “Zombie Code Slayer” para engenheiros que excluem quantidades significativas de código.
A simplificação é uma funcionalidade. É necessário estabelecer prioridades e projetos de simplificação do pessoal e reservar tempo para que os SREs trabalhem neles. Se os desenvolvedores de produtos e SREs não veem os projetos de simplificação como benéficos para suas carreiras, eles não realizarão esses projetos. Considere tornar a simplicidade um objetivo explícito para sistemas particularmente complexos ou equipes sobrecarregadas. Crie um intervalo de tempo separado para fazer esse trabalho. Por exemplo, reserve 10% do tempo do projeto de engenharia para projetos de “simplicidade”.
Nota
Ação do leitor: Fazer um brainstorming de engenheiros para conhecer as complexidades do sistema e discutir ideias para as reduzir.
À medida que um sistema cresce em complexidade, existe a tentação de dividir as equipes de SRE, concentrando cada nova equipe em partes menores do sistema. Embora isso às vezes seja necessário, o escopo reduzido das novas equipes pode diminuir sua motivação ou capacidade de conduzir projetos de simplificação maiores. Considere designar um pequeno grupo rotativo de SREs que mantenham o conhecimento de trabalho de toda a pilha (provavelmente com menos profundidade), e que possa impulsionar a conformidade e a simplificação através dela.
Como mencionado anteriormente, o ato de diagramar seu sistema pode ajudá-lo a identificar problemas de projeto mais profundos que dificultam sua capacidade de entender o sistema e prever seu comportamento. Por exemplo, ao diagramar seu sistema, você pode procurar o seguinte:
Amplificação
Quando uma chamada retorna um erro ou atinge o tempo limite e é repetida em vários níveis, isso faz com que o número total de RPCs se multiplique.
Dependências cíclicas
Quando um componente depende de si mesmo (muitas vezes indiretamente), a integridade do sistema pode ser gravemente comprometida – em particular, um arranque a frio de todo o sistema pode se tornar impossível.
Estudo de caso 3: Simplificação da Spiderweb dos anúncios de publicidade
Background
O negócio de Anúncios de Visualização do Google tem muitos produtos relacionados, incluindo alguns que tiveram origem em aquisições (DoubleClick, AdMob, Invite Media, etc.). Esses produtos tiveram que ser adaptados para funcionar com a infraestrutura do Google e os produtos existentes. Por exemplo, queríamos que um website que utilizasse DoubleClick for Publishers pudesse mostrar anúncios escolhidos pelo AdSense do Google; do mesmo modo, queríamos que os licitantes que utilizassem DoubleClick Bid Manager tivessem acesso aos leilões em tempo real realizados no Ad Exchange do Google.
Estes produtos desenvolvidos independentemente formavam um sistema de backends interligados que era difícil de raciocinar. Observar o que acontecia ao tráfego à medida que passava pelos componentes era difícil, e provisionar a quantidade certa de capacidade para cada peça era inconveniente e impreciso. A dada altura, adicionamos testes para garantir que removemos todos os loops infinitos no fluxo de consulta.
O que decidimos fazer
Os anúncios que veiculavam SREs eram os impulsionadores naturais da padronização: enquanto cada componente tinha uma equipe de desenvolvedores específica, os SREs estavam de plantão para toda a pilha. Um dos nossos primeiros compromissos foi elaborar padrões de uniformidade e trabalhar com equipes de desenvolvedores para adotá-los de forma incremental. Esses padrões:
- Estabeleceu uma única maneira de copiar grandes conjuntos de dados
- Estabeleceu uma única maneira de realizar pesquisas de dados externos
- Forneceu modelos comuns para monitoramento, provisionamento e configuração
Antes desta iniciativa, programas separados forneciam funcionalidades de frontend e de leilão para cada produto. Como mostrado na Figura 7-1, quando uma solicitação de anúncio pode atingir dois sistemas de segmentação, reescrevemos a solicitação para satisfazer as expectativas do segundo sistema. Isto exigiu código e processamento adicionais, e também abriu a possibilidade de loops indesejáveis.
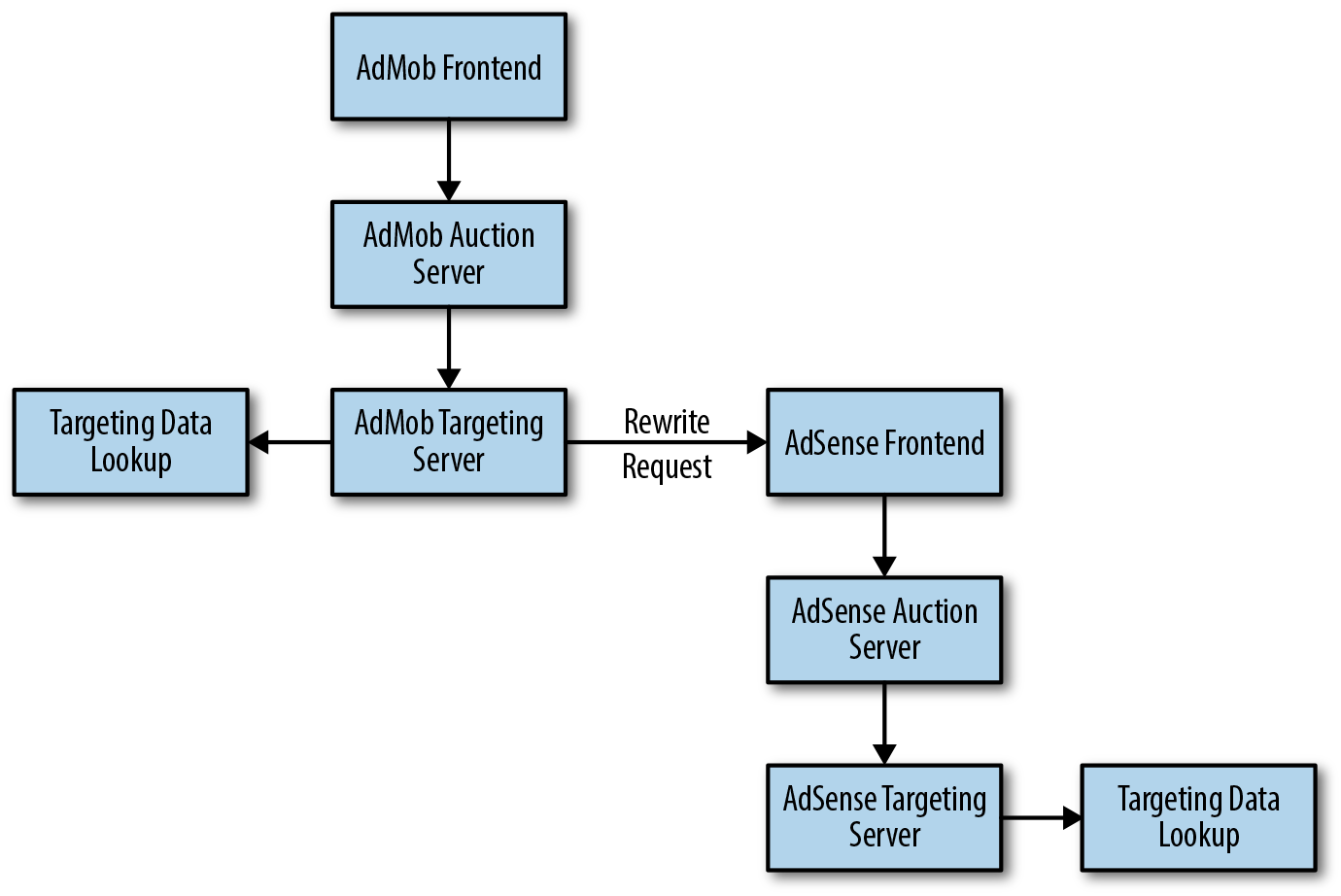
Figura 7-1. Anteriormente, uma solicitação de anúncio podia atingir os sistemas AdMob e AdSense.
Para simplificar o sistema, adicionamos lógica a programas comuns que satisfaziam todos os nossos casos de uso, juntamente com sinalizadores para proteger os programas. Com o tempo, removemos os sinalizadores e consolidamos a funcionalidade em menos backends de servidor
Uma vez unificados os servidores, o servidor de leilão pode falar diretamente com os dois servidores de segmentação. Como mostrado na Figura 7-2, quando vários servidores alvo precisavam de consultas de dados, a consulta precisava acontecer apenas uma vez no servidor de leilão unificado.
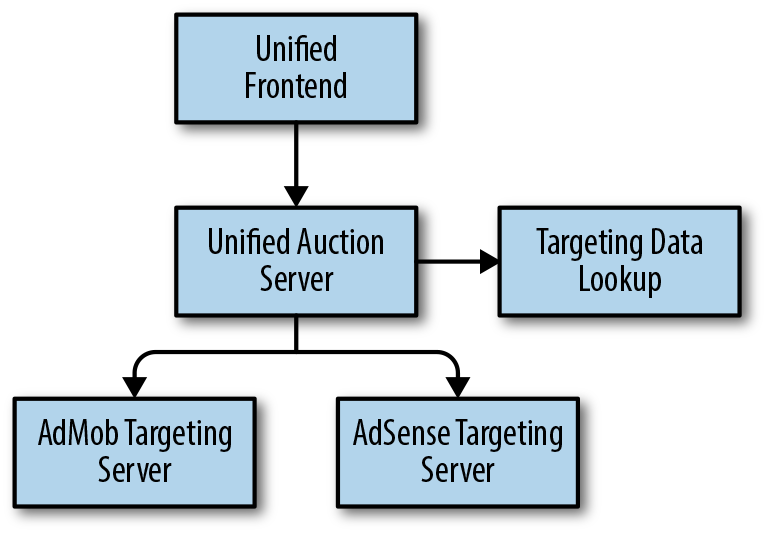
Figura 7-2. O servidor unificado de leilão realiza agora uma consulta de dados apenas uma vez
Lições aprendidas
É melhor integrar um sistema já em execução em sua própria infraestrutura de forma incremental.
Assim como a presença de funções muito semelhantes em um único programa representa um “cheiro de código” que indica problemas de design mais profundos, consultas redundantes em uma única solicitação representam um “cheiro de sistema”.
Ao criar padrões bem definidos com a adesão de SRE e desenvolvedores, você pode fornecer um plano claro para remover a complexidade que os gerentes têm mais probabilidade de endossar e recompensar.
Estudo de Caso 4: Execução de Centenas de Microserviços em uma plataforma compartilhada
Escrito por Mike Curtis
Background
Ao longo dos últimos 15 anos, o Google desenvolveu vários produtos verticais de sucesso (Pesquisa, Anúncios e Gmail, para citar alguns) e produziu um fluxo constante de sistemas novos e refatorados. Muitos desses sistemas têm uma equipe SRE dedicada e uma pilha de produção específica de domínio correspondente que inclui um fluxo de trabalho de desenvolvimento sob medida, ciclos de software de integração e entrega contínua (CI/CD) e monitoramento. Estas pilhas de produção únicas incorrem em despesas gerais significativas em termos de manutenção, custos de desenvolvimento e envolvimento independente da SRE. Também dificultam a movimentação de serviços (ou engenheiros!) entre equipes, ou a adição de novos serviços.
O que decidimos fazer
Um conjunto de equipes de SRE no espaço de rede social trabalhou para convergir as pilhas de produção de seus serviços em uma única plataforma de microsserviços gerenciada, gerenciada por um único grupo de SREs. A plataforma compartilhada está em conformidade com as melhores práticas e agrupa e configura automaticamente muitos recursos anteriormente subutilizados que melhoram a confiabilidade e facilitam a depuração. Independentemente do nível de envolvimento do SRE, os novos serviços no escopo da equipe do SRE eram obrigados a usar a plataforma comum, e os serviços legados precisavam migrar para a nova plataforma ou ser descontinuados.
Após seu sucesso no espaço de rede social, a plataforma compartilhada está ganhando adoção com outras equipes SRE e não SRE em todo o Google.
Design
Usamos microsserviços para que pudéssemos atualizar e implantar recursos rapidamente – um único serviço monolítico muda lentamente. Os serviços são gerenciados, não hospedados: em vez de remover o controle e a responsabilidade de equipes individuais, nós os capacitamos a gerenciar seus serviços de forma eficaz. Fornecemos ferramentas de fluxo de trabalho que as equipes de serviço podem usar para liberar, monitorar e muito mais.
As ferramentas que fornecemos incluem uma interface do usuário, API e uma interface de linha de comando que SREs e desenvolvedores usam para interagir com sua pilha. As ferramentas fazem com que a experiência do desenvolvedor pareça unificada, mesmo quando envolve muitos sistemas subjacentes.
Resultados
A alta qualidade e o conjunto de recursos da plataforma tiveram um benefício inesperado: as equipes de desenvolvedores podem executar centenas de serviços sem nenhum envolvimento profundo do SRE.
A plataforma comum também mudou a relação SRE-desenvolvedor. Como resultado, o engajamento SRE em camadas está se tornando comum no Google. O envolvimento em camadas inclui um espectro de envolvimento do SRE, desde consultoria leve e revisões de design até um envolvimento profundo (ou seja, os SREs compartilham tarefas de plantão).
Lições aprendidas
Mudar de padrões esparsos ou mal definidos para uma plataforma altamente padronizada é um investimento de longo prazo. Cada etapa pode parecer incremental, mas, em última análise, essas etapas reduzem a sobrecarga e possibilitam a execução de serviços em escala.
É importante que os desenvolvedores vejam o valor dessa transição. Almeje por ganhos incrementais de produtividade que são desbloqueados em cada fase de desenvolvimento. Não tente convencer as pessoas a realizar uma grande refatoração que só compensa no final.
Estudo de Caso 5: pDNS não depende mais de si mesmo
Background
Quando um cliente na produção do Google quer pesquisar o endereço IP para um serviço, ele geralmente usa um serviço de pesquisa chamado Svelte. No passado, para encontrar o endereço IP do Svelte, o cliente usava um serviço de nomenclatura do Google chamado pDNS (DNS de produção). O serviço pDNS é acessado por meio de um balanceador de carga, que procura os endereços IP dos servidores pDNS reais… usando o Svelte.
Declaração do problema
O pDNS tinha uma dependência transitória de si próprio, que foi introduzida involuntariamente em algum momento e só mais tarde identificada como uma preocupação de confiabilidade. As pesquisas normalmente não se deparavam com problemas porque o serviço pDNS era replicado, e os dados necessários para sair do loop de dependência sempre estavam disponíveis em algum lugar na produção do Google. No entanto, um arranque a frio teria sido impossível. Nas palavras de um SRE, “Nós éramos como moradores de cavernas que só podiam acender fogueiras correndo com uma tocha acesa na última fogueira”.
O que decidimos fazer
Modificamos um componente de baixo nível na produção do Google para manter uma lista de endereços IP atuais para servidores Svelte próximos em armazenamento local para todas as máquinas de produção do Google. Além de quebrar a dependência circular descrita anteriormente, esta alteração eliminou também uma dependência implícita do pDNS para a maioria dos outros serviços Google.
Para evitar questões semelhantes, introduzimos também um método de listagem branca do conjunto de serviços permitidos para comunicar com o pDNS, e trabalhamos lentamente para reduzir esse conjunto. Como resultado, cada pesquisa de serviços em produção tem agora um caminho mais simples e mais confiável através do sistema.
Lições aprendidas
Tenha cuidado com as dependências do seu serviço – utilize uma lista branca explícita para evitar adições acidentais. Além disso, esteja atento às dependências circulares.
Conclusão
A simplicidade é um objetivo natural para SREs porque sistemas simples tendem a ser confiáveis e fáceis de executar. Não é fácil medir quantitativamente a simplicidade (ou seu inverso, a complexidade) para sistemas distribuídos, mas existem proxies razoáveis, e vale a pena escolher alguns e trabalhar para melhorá-los.
Devido à sua compreensão de ponta a ponta de um sistema, os SREs estão em uma excelente posição para identificar, prevenir e corrigir fontes de complexidade, sejam elas encontradas em design de software, arquitetura de sistema, configuração, processos de implantação ou em outros lugares. Os SREs devem estar envolvidos nas discussões de design desde o início para fornecer sua perspectiva única sobre os custos e benefícios das alternativas, com um olhar especial para a simplicidade. Os SREs também podem desenvolver proativamente padrões para homogeneizar a produção.
Como SRE, a promoção da simplicidade é uma parte importante da descrição do seu trabalho. Recomendamos enfaticamente que a liderança do SRE capacite as equipes do SRE para promover a simplicidade e recompensar explicitamente esses esforços. Os sistemas inevitavelmente se aproximam da complexidade à medida que evoluem, de modo que a luta pela simplicidade requer atenção e comprometimento contínuos, mas vale muito a pena persegui-la.
Fonte: Google SRE Work Book