A editora e plataforma de ensino O’Reilly lançou uma publicação, em 2018, intitulada “Distributed Systems Observability”. Nessa obra, o capítulo 4 oferece uma visão ampla do que ficou conhecido como “Os 3 Pilares da Observabilidade”. Muito embora esses 3 pilares sejam descritos separadamente, inclusive neste post, necessitam ser analisados em conjunto, dentro de uma abordagem coesa, capaz de oferecer uma visão ampla do estado completo do sistema sob difentes aspectos. Assim, para que uma abordagem unificada faça sentido, é necessário tratar o todo, e não somente a mera soma de cada parte, individualmente, compondo o contexto geral do sistema.
Mas, para efeito de estudo, trataremos separadamente e de forma aprofundada cada um dos 3 pilares, quais sejam:
Logs
Métricas
Rastreamento de dados (tracing)
Embora ter acesso completo aos três não necessariamente torne o sistema mais “observável”, esses são elementos-chave que, se bem compreendidos, poderão levar a sistemas melhores e mais eficientes e em uma boa experiência do usuário.
Logs de eventos
Um log de evento é um registro imutável com carimbo de data/hora de eventos discretos que aconteceram ao longo do tempo. Os logs de eventos em geral vêm em 3 formas, mas são fundamentalmente os mesmos: um carimbo de data/hora e uma carga útil de algum contexto. As três 3 formas são:
Texto. Um registro de log pode em formato texto. Este também é o formato mais comum de log que existe.
Estruturado. Muito “evangelizado” e defendido nos últimos tempos. Normalmente, esses logs são emitidos no formato JSON.
Binário. Pense em logs no formato Protobuf, binlogs MySQL usados para replicação e point-in-time recovery, systemd journal logs, o formato pflog usado pelo firewall BSD pf que frequentemente serve como um frontend para a ferramenta tcpdump.
O debug de patologias raras ou infrequentes de sistemas geralmente envolve o debug em um nível muito fino de granularidade. Logs de eventos, em particular, são preciosos quando se trata de fornecer insights valiosos juntamente com amplo contexto sobre a cauda longa que médias e porcentagens não trazem à tona. Como tal, os logs de eventos são especialmente úteis para descobrir comportamentos emergentes e imprevisíveis exibidos por componentes de um sistema distribuído.
Falhas em sistemas distribuídos complexos raramente surgem devido à ocorrência de um evento específico em um componente específico do sistema. Frequentemente, vários gatilhos possíveis em um gráfico altamente interconectado de componentes estão envolvidos na causa raiz e no contexto do problema. Olhar, simplesmente, para eventos discretos que ocorreram em qualquer sistema em algum ponto no tempo, torna impossível determinar todos esses gatilhos. Para definir os diferentes gatilhos, é necessário ser capaz de fazer o seguinte:
- Começar com um sintoma identificado por uma métrica de alto nível ou um log de evento em um sistema específico
- Inferir o ciclo de vida da solicitação em diferentes componentes da arquitetura distribuída
- Iterativamente, faça perguntas sobre as interações entre as várias partes do sistema
Além de inferir o destino de uma solicitação ao longo de seu ciclo de vida (que geralmente é de curta duração), também se torna necessário ser capaz de inferir o destino de um sistema como um todo (medido ao longo de uma duração que, por sua vez, é da ordem de magnitude mais longa do que o ciclo de vida de uma única solicitação).
Os rastreamentos (traces) e as métricas são uma abstração construída sob os logs que pré-processam e codificam as informações ao longo de dois eixos ortogonais, um sendo centrado na solicitação (rastreamento) e o outro no sistema (métrica).
Os prós e contras dos logs
Logs são, de longe, os mais fáceis de gerar. O fato de um log ser apenas uma string ou um blob de JSON ou ainda pares de valores-chave digitados facilita a representação de quaisquer dados na forma de uma linha de log. A maioria das linguagens, frameworks de aplicação e bibliotecas vem com suporte para log. Logs também são fáceis de instrumentar, já que adicionar uma linha de log é tão trivial quanto adicionar uma instrução de impressão. Os logs têm um desempenho muito bom em termos de revelar informações altamente granulares repletas de contexto local rico, desde que o espaço de pesquisa seja localizado para eventos que ocorreram em um único serviço.
A utilidade dos logs, contudo, termina aí. Embora a geração de log possa ser fácil, as idiossincrasias de desempenho de várias bibliotecas de log populares deixam muito a desejar. A maioria das bibliotecas de log de desempenho aloca muito pouco, se muito, e é extremamente rápida. No entanto, as bibliotecas de log padrão de muitas linguagens e estruturas também não são lá aquelas coisas, o que significa que a aplicação como um todo se torna suscetível a um desempenho abaixo do ideal devido à sobrecarga de log. Além disso, as mensagens de log também podem ser perdidas, a menos que se use um protocolo como RELP para garantir a entrega confiável de mensagens. Isso se torna especialmente importante quando os dados de log são usados para fins de cobrança ou pagamento.
Por último, a menos que a biblioteca de log possa amostrar logs dinamicamente, logs excessivos têm a capacidade de afetar adversamente o desempenho da aplicação como um todo. Isso é exacerbado quando o log não é assíncrono e o processamento da requisição é bloqueado ao gravar uma linha de log no disco ou na stdout.
No lado do processamento, os logs brutos são quase sempre normalizados, filtrados e processados por uma ferramenta como Logstash, fluentd, Scribe ou Heka antes de serem persistidos em um armazenamento de dados como Elasticsearch ou BigQuery. Se um aplicativo gerar um grande volume de logs, os logs podem exigir armazenamento em buffer adicional em um broker como o Kafka antes de serem processados pelo Logstash. Soluções hospedadas como o BigQuery têm cotas que não podem ser excedidas.
Do lado do armazenamento, embora o Elasticsearch possa ser um mecanismo de pesquisa fantástico, executá-lo acarreta um custo operacional real. Mesmo que uma organização tenha uma equipe de engenheiros de operações especialistas na operação do Elasticsearch, podem existir outras desvantagens. Caso em questão: não é incomum ver uma queda acentuada nos gráficos em Kibana, não porque o tráfego para o serviço esteja caindo, mas porque o Elasticsearch não consegue acompanhar a indexação do grande volume de dados que está sendo jogado nele. Mesmo que o processamento de ingestão de log não seja um problema com o Elasticsearch, o mesmo não ocorre com a IU do Kibana.
Métricas
As métricas são uma representação numérica de dados medidos em intervalos de tempo. As métricas podem aproveitar o poder da modelagem matemática e da análise preditiva para derivar o conhecimento do comportamento de um sistema em intervalos de tempo no presente e no futuro.
Como os números são otimizados para armazenamento, processamento, compactação e recuperação, as métricas permitem uma retenção de dados mais longa, bem como consultas mais fáceis. Isso torna as métricas perfeitamente adequadas para a construção de painéis que refletem tendências históricas. As métricas também permitem a redução gradual da resolução de dados. Após um determinado período de tempo, os dados podem ser agregados em frequência diária ou semanal.
A anatomia de uma métrica moderna
Uma das maiores desvantagens dos bancos de dados de séries temporais históricas tem sido a identificação de métricas que não se prestam muito bem à análise exploratória ou filtragem de dados.
O modelo métrico hierárquico e a falta de tags ou rótulos nas versões mais antigas do Graphite prejudicam especialmente este cenário. Sistemas de monitoramento modernos como o Prometheus e versões mais recentes do Graphite representam cada série temporal usando um nome de métrica, bem como pares de valores-chave adicionais chamados rótulos. Isso permite um alto grau de dimensionalidade no modelo de dados.
Uma métrica no Prometheus, conforme mostra a figura abaixo, é identificada usando o nome da métrica e os rótulos. Os dados reais armazenados na série temporal são chamados de amostra e consistem em dois componentes: um valor float64 e um carimbo de data/hora de precisão na ordem de milissegundos.
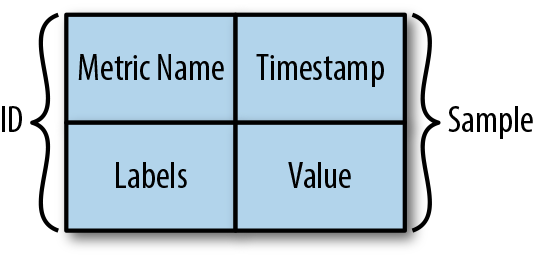
É importante ter em mente que as métricas no Prometheus são imutáveis. Alterar o nome da métrica ou adicionar ou remover um rótulo resultará em uma nova série temporal.
Vantagens das métricas em relação a logs de eventos
Em geral, a maior vantagem da observabilidade e do monitoramento baseado em métricas sobre logs é que, ao contrário da geração e do armazenamento de logs, a transferência e o armazenamento de métricas têm uma sobrecarga constante. Ao contrário dos logs, o custo das métricas não aumenta em sincronia com o tráfego do usuário ou qualquer outra atividade do sistema que possa resultar em um aumento acentuado nos dados.
Com as métricas, um aumento no tráfego de uma aplicação não acarretará em um aumento significativo na utilização do disco, complexidade de processamento, velocidade de visualização e custos operacionais como os logs. O armazenamento de métricas aumenta com mais permutações de valores de rótulo (por exemplo, quando mais hosts ou containers são ativados, ou quando novos serviços são adicionados ou ainda quando os serviços existentes são mais instrumentados), mas a agregação do lado do cliente pode garantir que o tráfego de métrica não aumente proporcionalmente ao tráfego do usuário.
As métricas, uma vez coletadas, são mais maleáveis para transformações matemáticas, probabilísticas e estatísticas, como amostragem, agregação, sumarização e correlação. Essas características tornam as métricas mais adequadas para reportar a integridade geral de um sistema.
As métricas também são mais adequadas para acionar alertas, uma vez que executar queries em um banco de dados de série temporal in-memory é muito mais eficiente, para não mencionar mais confiável, do que executar uma query em um sistema distribuído como Elasticsearch e, em seguida, agregar os resultados antes de decidir se um alerta precisa ser acionado. Obviamente, os sistemas que consultam estritamente apenas dados de eventos estruturados in-memory para gerar alertas podem ser um pouco mais baratos do que o Elasticsearch. A desvantagem aqui é que a sobrecarga operacional de executar um grande banco de dados in-memory em cluster, mesmo se fosse em código aberto, não vale o trabalho operacional para a maioria das organizações, especialmente quando há maneiras muito mais fáceis de derivar igualmente alertas acionáveis.
As métricas são mais adequadas para fornecer essas informações.
As desvantagens das métricas
A maior desvantagem com os logs e métricas do aplicativo é que eles têm o escopo do sistema, tornando difícil entender qualquer outra coisa além do que está acontecendo dentro de um sistema específico. Claro, as métricas também podem ter o escopo de requisiçao, mas isso acarreta um aumento concomitante no fan-out de rótulos, o que resulta em um aumento no armazenamento de métricas.
Com logs sem junções sofisticadas, uma única linha não fornece muitas informações sobre o que aconteceu com uma requisição em todos os componentes de um sistema. Embora seja possível construir um sistema que correlacione métricas e logs em todo o espaço de endereço ou fronteiras RPC, tais sistemas requerem uma métrica para transportar um UID como um rótulo.
Usar valores de alta cardinalidade como UIDs como rótulos de métricas pode sobrecarregar os bancos de dados de série temporal. Embora o novo mecanismo de armazenamento do Prometheus tenha sido otimizado para lidar com a rotatividade de séries temporais, as consultas em intervalos de tempo mais longos ainda serão lentas. (Prometheus foi apenas um exemplo. Todas as soluções populares de banco de dados de série temporal apresentam desempenho sob rotulagem de alta cardinalidade).
Quando usados de maneira ideal, logs e métricas fornecem onisciência completa em um silo, mas nada mais. Embora possam ser suficientes para compreender o desempenho e o comportamento de sistemas individuais, tanto com estado quanto sem estado, eles não são suficientes para entender o tempo de vida de uma requisição que atravessa vários sistemas.
O rastreamento distribuído é uma técnica que aborda o problema de trazer visibilidade ao tempo de vida de uma requisição em vários sistemas.
Rastreamento
Um rastreamento (trace ou tracing) é uma representação de uma série de eventos distribuídos, causalmente relacionados, que codificam o fluxo de requisição de ponta a ponta através de um sistema distribuído.
Os rastreios são uma representação de logs; a estrutura de dados dos rastreios se parece quase com a de um log de eventos. Um único rastreamento pode fornecer visibilidade tanto do caminho percorrido por uma requisição quanto da estrutura de uma requisição. O caminho percorrido por uma requisição permite que engenheiros de software e SREs entendam os diferentes serviços envolvidos nesse caminho, e a estrutura de uma requisição ajuda a entender as conjunturas e os efeitos da assincronia na execução dela.
Embora as discussões sobre rastreamento tendam a girar em torno de sua utilidade em um ambiente de microsserviços, é justo sugerir que qualquer aplicativo suficientemente complexo que interaja com – ou melhor, disputa por – recursos como rede, disco ou um mutex de uma maneira não trivial pode se beneficiar das vantagens que o rastreamento oferece.
A ideia básica por trás do rastreamento é direta – identificar pontos específicos (chamadas de função, fronteiras RPC ou segmentos de simultaneidade, como threads, continuações ou filas) em uma aplicação, proxy, framework, biblioteca, tempo de execução, middleware e qualquer outra coisa no caminho de uma requisição que representa o seguinte:
- Forks no fluxo de execução (thread do sistema operacional ou thread verde)
- Um hop ou um fan-out através dos limites da rede ou do processo
Os rastreamentos são usados para identificar a quantidade de trabalho realizado em cada camada, preservando a causalidade ao se valer da semântica do “acontece antes”. A figura abaixo mostra o fluxo de uma única solicitação por meio de um sistema distribuído. A representação de rastreamento desse fluxo de solicitação é mostrada logo abaixo. Um traço é um gráfico acíclico direcionado (DAG) de spans, onde as arestas entre os spans são chamadas de referências.
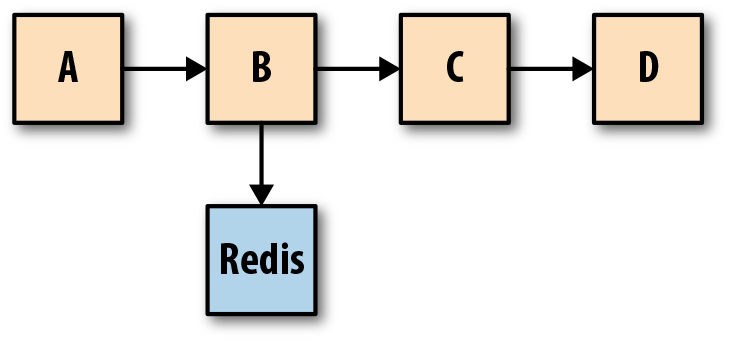
Quando uma solicitação começa, é atribuído um ID globalmente unico, que é então propagado por todo o caminho da requisição para que cada ponto de instrumentação seja capaz de inserir ou enriquecer metadados antes de passar o ID para o próximo hop no fluxo sinuoso de uma requisição. Cada hop ao longo do fluxo é representado como um span. Quando o fluxo de execução atinge o ponto instrumentado em um desses serviços, um registro é emitido junto com os metadados. Esses registros são geralmente logados de forma assíncrona no disco antes de serem enviados fora da banda a um coletor, que então pode reconstruir o fluxo de execução com base em diferentes registros emitidos por diferentes partes do sistema.
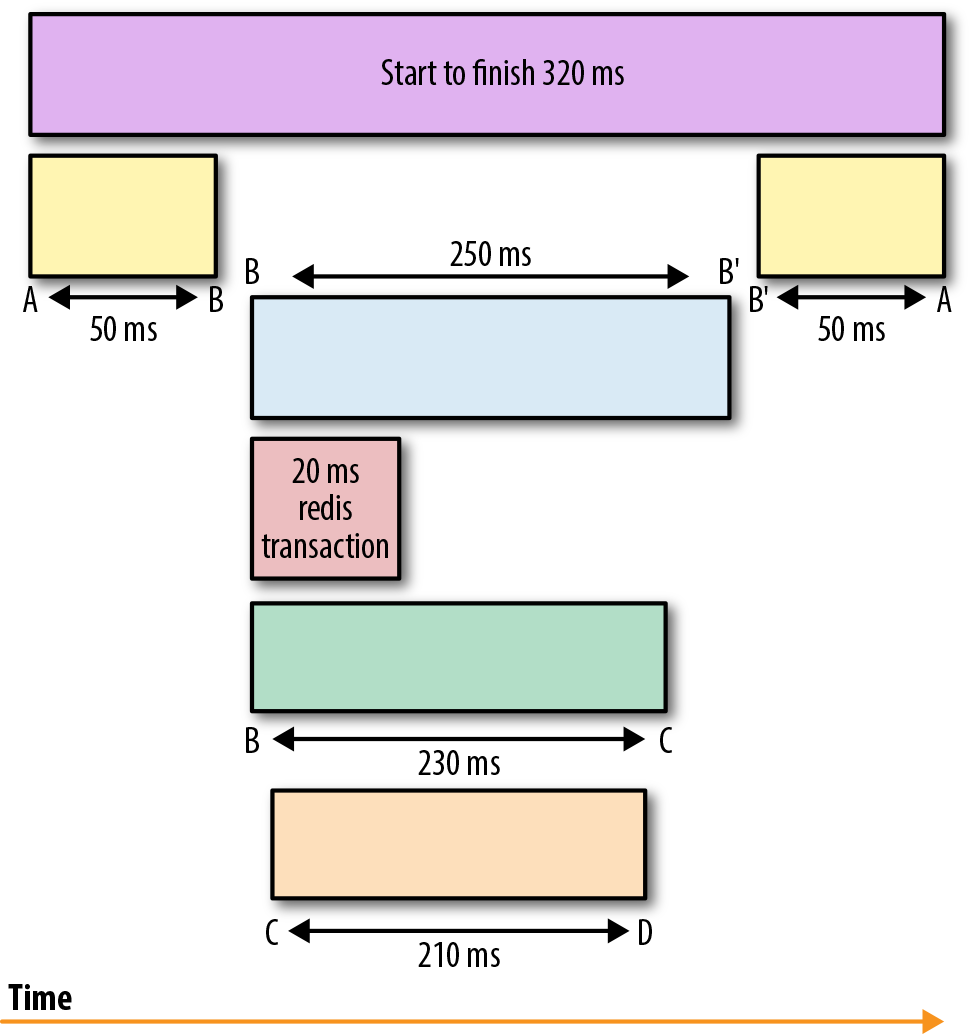
Coletar essas informações e reconstruir o fluxo de execução enquanto se preserva a causalidade para análise retrospectiva e resolução de problemas permite compreender melhor o ciclo de vida de uma requisição.
E mais importante ainda, ter uma compreensão de todo o ciclo de vida da requisição torna possível fazer o debug de requisições que abrangem vários serviços para identificar a origem do aumento da latência ou da utilização de recursos. Por exemplo, a figura que representa o rastreamento por spans indica que a interação entre o serviço C e o serviço D foi o que demorou mais. Os rastreamentos, como tal, ajudam muito a entender o que e às vezes até o porquê (por exemplo, qual componente de um sistema é tocado durante o ciclo de vida de uma requisição e está retardando a resposta?).
Os casos de uso de rastreamento distribuído são inúmeros. Embora seja usado principalmente para análise de dependência entre serviços, criação de perfil distribuído e debug de problemas de estado estável, o rastreio também pode ajudar no chargeback e no planejamento de capacidade.
Zipkin e Jaeger são duas das mais populares soluções de rastreamento distribuído de código aberto compatível com o OpenTracing, uma especificação de fornecedor independente e bibliotecas de instrumentação para APIs de rastreamento distribuído.
Observabilidade e monitoramento: conclusão
Logs, métricas e rastreamentos atendem a seu propósito único e são complementares. Em uníssono, elas fornecem visibilidade máxima sobre o comportamento de sistemas distribuídos. Por exemplo, faz sentido ter o seguinte:
Um contador e um log em cada entrada principal e ponto de saída de uma requisição
Um log e rastreamento em cada ponto de decisão de uma requisição
Também faz sentido ter todos os três linkados semanticamente de forma que seja possível no momento do debug:
Reconstruir o codepath tomado pela leitura de um rastreio
Derivar a requisição ou razão de erro de qualquer ponto único no codepath
Fazer amostragem de exemplos de rastreios ou eventos e correlacioná-los a métricas desbloqueia a capacidade de clicar em uma métrica, ver exemplos de rastreios e inspecionar o fluxo de requisição através de vários sistemas. Essas percepções obtidas a partir de uma combinação de diferentes sinais de observabilidade tornam-se essenciais para realmente seja possível fazer o debug de sistemas distribuídos.

