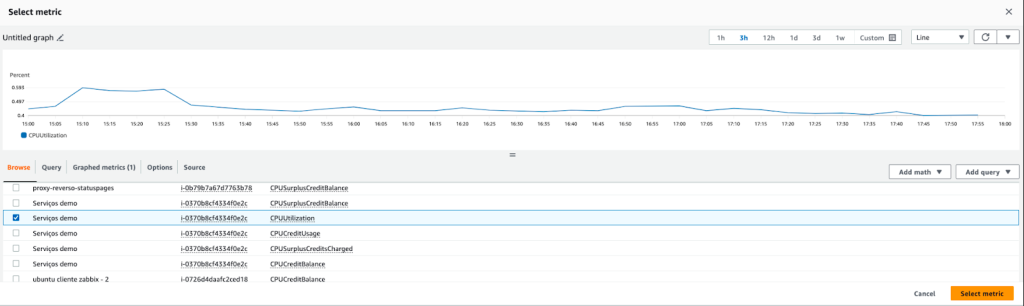
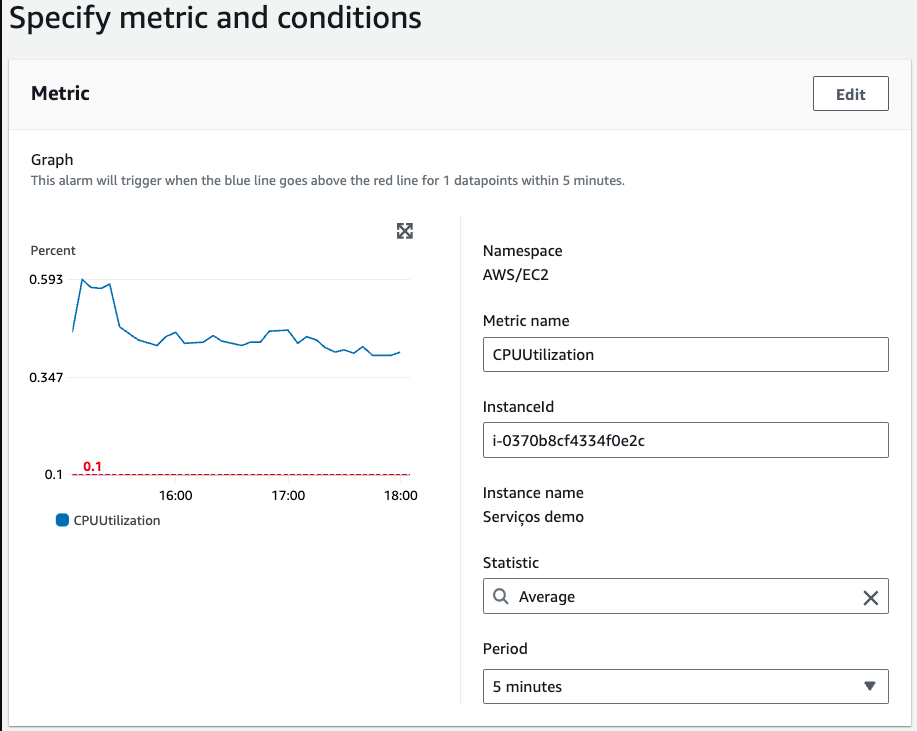
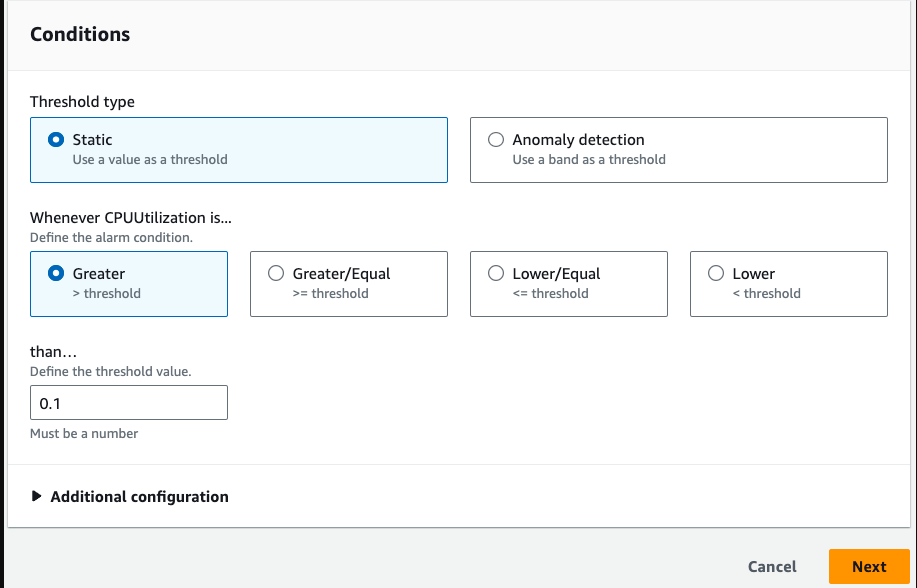
The Resource Monitoring Center is designed to facilitate the efficient visualization and management of different resource states. This guide provides an overview of the available filtering functionalities to optimize monitoring.
In resource monitoring, filters are used to efficiently visualize and manage different states of resources. Below are the available filter categories:
- All: Displays all resources regardless of their status.
- Inactive: Shows only inactive resources.
- Operational: Filters and displays only operational resources.
- Pending: Lists resources that are pending, awaiting some action or decision.
- In Maintenance: Displays resources that are currently undergoing maintenance.
- Not Operational: Shows resources that are not operational.
Each filter allows you to focus on specific resources, facilitating management and tracking as needed.
In addition to filtering resources by status, you can also view them based on different time intervals. The available period options are:
- All: Shows resources from all periods.
- Last Day: Displays resources that have had activities in the last 24 hours.
- Last Week: Filters resources with activities in the last week.
- Last Month: Lists resources that were active in the last month.
- Last Year: Shows resources that have had activities in the last year.
These time filters help analyze trends and changes in resource usage over different periods, facilitating decision-making and strategic planning.
The Custom Range option offers maximum flexibility by allowing you to set a specific date and time interval for resource monitoring. Here’s how to use it:
- Start Date: Select the start date and time of the interval.
- End Date: Choose the end date and time of the interval.
After setting the desired parameters:
- Click on Apply Time Range to apply the filter.
- If you wish to cancel the selections made, click on Cancel.
This functionality is ideal for precise and detailed analysis, allowing you to track activities in specific periods tailored to your needs.