Teste de confiabilidade
Escrito por Alex Perry e Max Luebbe
Editado por Diane Bates
“Se você ainda não experimentou, suponha que esteja quebrado.”
Este capítulo explica como maximizar o valor derivado do investimento do esforço de engenharia em testes. Uma vez que um engenheiro define os testes adequados (para um determinado sistema) de uma forma generalizada, o trabalho restante é comum a todas as equipes SRE e, portanto, pode ser considerado uma infraestrutura compartilhada. Essa infraestrutura consiste em um agendador (para compartilhar recursos orçados em projetos não relacionados de outra forma) e executores (esse sandbox testa os binários para evitar que sejam considerados confiáveis). Cada um desses dois componentes de infraestrutura pode ser considerado um serviço comum compatível com SRE (muito parecido com o armazenamento em escala de cluster) e, portanto, não será discutido aqui em profundidade.
Uma das principais responsabilidades de engenheiros de confiabilidade do site é quantificar a confiança nos sistemas que eles mantêm. Os SREs realizam essa tarefa adaptando técnicas clássicas de teste de software a sistemas em escala. A confiança pode ser medida tanto pela confiabilidade passada quanto pela confiabilidade futura. A primeira é capturada pela análise dos dados fornecidos pelo histórico de monitoramento do comportamento do sistema, enquanto a confiabilidade futura é quantificada a partir de previsões sobre o comportamento anterior do sistema.
Para que essas previsões sejam fortes o suficiente para serem úteis, uma das seguintes condições deve ser válida:
- O site permanece completamente inalterado ao longo do tempo, sem lançamentos de software ou mudanças na frota de servidores, o que significa que o comportamento futuro será semelhante ao comportamento anterior.
- Você pode descrever com segurança todas as alterações no site, para que uma análise permita a incerteza incorrida por cada uma dessas alterações.
Teste é o mecanismo que você usa para demonstrar áreas específicas de equivalência quando ocorrem alterações. (Para ler mais sobre equivalência, acesse aqui). Cada teste que passa antes e depois de uma alteração reduz a incerteza que a análise precisa permitir. Testes completos nos ajudam a prever a confiabilidade futura de um determinado site com detalhes suficientes para serem úteis na prática.
A quantidade de testes que você precisa realizar depende dos requisitos de confiabilidade do seu sistema. Conforme a porcentagem de sua base de código coberta pelos testes aumenta, você reduz a incerteza e a diminuição potencial na confiabilidade de cada alteração. A cobertura de teste adequada significa que você pode fazer mais alterações antes que a confiabilidade caia abaixo de um nível aceitável. Se você fizer muitas alterações muito rapidamente, a confiabilidade prevista se aproxima do limite de aceitabilidade. Neste ponto, você pode querer parar de fazer alterações enquanto novos dados de monitoramento se acumulam. Os dados acumulados complementam a cobertura testada, que valida a confiabilidade sendo afirmada para caminhos de execução revisados. Supondo que os clientes atendidos sejam distribuídos aleatoriamente, as estatísticas de amostragem podem extrapolar a partir das métricas monitoradas se o comportamento agregado está fazendo uso de novos caminhos. Essas estatísticas identificam as áreas que precisam de melhores testes ou outras adaptações.
Relações entre teste e tempo médio de resposta
Passar em um teste ou em uma série de testes não necessariamente prova confiabilidade. No entanto, os testes que estão falhando geralmente provam a ausência de confiabilidade.
Um sistema de monitoramento pode descobrir bugs, mas apenas tão rapidamente quanto o pipeline de relatórios pode reagir. O Tempo Médio de Resposta (MTTR) mede quanto tempo leva para a equipe de operações corrigir o bug, seja por meio de uma reversão ou outra ação.
É possível para um sistema de teste identificar um bug com MTTR zero. Zero MTTR ocorre quando um teste de nível de sistema é aplicado a um subsistema e esse teste detecta exatamente o mesmo problema que o monitoramento detectaria. Esse teste permite que o push seja bloqueado para que o bug nunca chegue à produção (embora ainda precise ser reparado no código-fonte). Reparar erros de MTTR zero bloqueando um push é rápido e conveniente. Quanto mais bugs você encontrar com zero MTTR, maior será o Tempo Médio entre Falhas (MTBF) experimentado por seus usuários.
À medida que o MTBF aumenta em resposta a melhores testes, os desenvolvedores são incentivados a lançar features mais rapidamente. Alguns desses recursos, é claro, têm bugs. Novos bugs resultam em um ajuste oposto à velocidade de liberação à medida que esses bugs são encontrados e corrigidos.
Autores que escrevem sobre teste de software concordam amplamente sobre qual cobertura é necessária. A maioria dos conflitos de opinião se origina de terminologia conflitante, diferentes ênfases no impacto do teste em cada uma das fases do ciclo de vida do software ou nas particularidades dos sistemas usados para realizar o teste. As seções a seguir especificam como a terminologia relacionada ao teste de software é usada neste capítulo.
Tipos de teste de software
Os testes de software geralmente se enquadram em duas categorias: tradicional e produção. Os testes tradicionais são mais comuns no desenvolvimento de software para avaliar a exatidão do software offline, durante o desenvolvimento. Os testes de produção são executados em um serviço live da web para avaliar se um sistema de software implantado está funcionando corretamente.
Testes tradicionais
Conforme mostrado na figura abaixo, o teste de software tradicional começa com testes de unidade. O teste de funcionalidades mais complexas é feito em camadas sobre os testes de unidade.
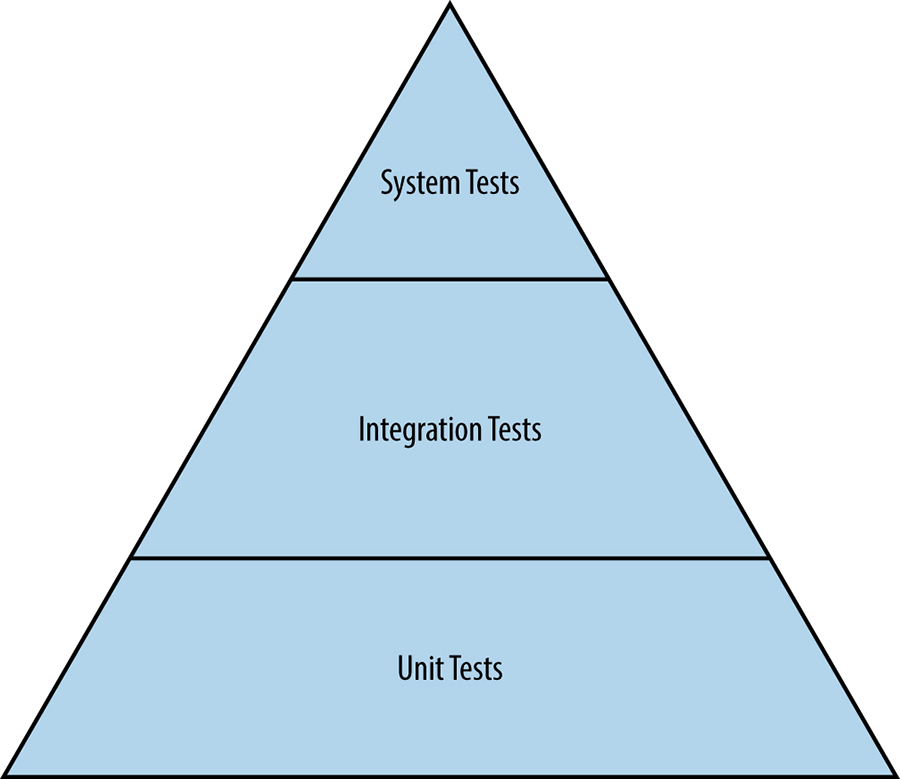
Testes de unidade
Um teste de unidade é a forma menor e mais simples de teste de software. Esses testes são empregados para avaliar uma unidade separável de software, como uma classe ou função, quanto à exatidão, independentemente do sistema de software maior que contém a unidade. Os testes de unidade também são empregados como uma forma de especificação para garantir que uma função ou módulo execute exatamente o comportamento exigido pelo sistema. Os testes de unidade são comumente usados para introduzir conceitos de desenvolvimento orientados a testes.
Testes de integração
Os componentes de software que passam nos testes de unidade individuais são montados em componentes maiores. Os engenheiros então executam um teste de integração em um componente montado para verificar se ele funciona corretamente. A injeção de dependência, que é realizada com ferramentas como Dagger, é uma técnica extremamente poderosa para criar simulações de dependências complexas para que um engenheiro possa testar um componente de forma limpa. Um exemplo comum de injeção de dependência é substituir um banco de dados stateful por um mock leve que tem um comportamento precisamente especificado.
Testes de sistema
Um teste de sistema é o teste de maior escala que os engenheiros executam para um sistema não implantado. Todos os módulos pertencentes a um componente específico, como um servidor que passou nos testes de integração, são montados no sistema. Em seguida, o engenheiro testa a funcionalidade de ponta a ponta no sistema. Os testes de sistema vêm em muitos sabores diferentes:
Testes de fumaça
Os testes de fumaça (“smoke tests”), nos quais os engenheiros testam um comportamento muito simples, mas crítico, estão entre os tipos mais simples de testes de sistema. Os testes de fumaça também são conhecidos como testes de sanidade (sanity tests) e servem como curto-circuito em testes adicionais e mais caros.
Testes de performance
Uma vez que a correção básica é estabelecida por meio de um teste de fumaça, uma próxima etapa comum é escrever outra variante de um teste de sistema para garantir que o desempenho do sistema permaneça aceitável ao longo do seu ciclo de vida. Como os tempos de resposta para dependências ou requisitos de recursos podem mudar drasticamente durante o curso de desenvolvimento, um sistema precisa ser testado para garantir que não fique cada vez mais lento sem que ninguém perceba (antes de ser lançado para os usuários). Por exemplo, um determinado programa pode evoluir para precisar de 32 GB de memória quando antes precisava apenas de 8 GB, ou um tempo de resposta de 10 ms pode se transformar em 50 ms e depois em 100 ms. Um teste de desempenho garante que, com o tempo, um sistema não se degrade ou se torne muito caro.
Testes de regressão
Outro tipo de teste de sistema envolve evitar que bugs voltem sorrateiramente para a base de código. Os testes de regressão podem ser comparados a uma galeria de bugs nocivos que historicamente causaram falhas no sistema ou produziram resultados incorretos. Ao documentar esses bugs como testes em nível de sistema ou integração, os engenheiros que refatoram a base de código podem ter certeza de que não introduzirão acidentalmente bugs que já investiram tempo e esforço para eliminar.
É importante notar que os testes têm um custo, tanto em termos de tempo quanto de recursos computacionais. Por um lado, os testes de unidade são muito baratos em ambas as dimensões, pois geralmente podem ser concluídos em milissegundos com os recursos disponíveis em um laptop. No outro extremo do espectro, trazer um servidor completo com dependências necessárias (ou equivalentes simulados) para executar testes relacionados pode levar muito mais tempo – de vários minutos a várias horas – e possivelmente exigir recursos de computação dedicados. A atenção a esses custos é essencial para a produtividade do desenvolvedor e também incentiva o uso mais eficiente dos recursos de teste.
Testes de produção
Os testes de produção interagem com um sistema de produção ativo, ao contrário de um sistema em um ambiente de teste hermético. Esses testes são, em muitos aspectos, semelhantes ao monitoramento de caixa preta (consulte Monitorando Sistemas Distribuídos) e, portanto, às vezes são chamados de teste de caixa preta. Os testes de produção são essenciais para executar um serviço de produção confiável.
Testes de lançamentos emaranhados
Costuma-se dizer que o teste é (ou deveria ser) realizado em um ambiente hermético. Esta afirmação implica que a produção não é hermética. Claro, a produção geralmente não é hermética, porque as cadências de lançamento fazem alterações no ambiente de produção em tempo real a partir de pedaços pequenos e bem compreendidos.
Para gerenciar a incerteza e ocultar o risco dos usuários, as alterações podem não ser enviadas live na mesma ordem em que foram adicionadas ao controle de origem. Os rollouts geralmente acontecem em estágios, usando mecanismos que embaralham gradualmente os usuários, além de monitorar cada estágio para garantir que o novo ambiente não esteja atingindo problemas previstos, mas inesperados. Como resultado, todo o ambiente de produção não é intencionalmente representativo de qualquer versão de um binário que é verificado no controle de origem.
É possível que o controle de origem tenha mais de uma versão de um binário e seu arquivo de configuração associado aguardando para ser ativado. Este cenário pode causar problemas quando os testes são conduzidos no ambiente ativo. Por exemplo, o teste pode usar a versão mais recente de um arquivo de configuração localizado no controle de origem junto com uma versão mais antiga do binário que está ativo. Ou pode testar uma versão mais antiga do arquivo de configuração e encontrar um bug que foi corrigido em uma versão mais recente do arquivo.
Da mesma forma, um teste de sistema pode usar os arquivos de configuração para montar seus módulos antes de executar o teste. Se o teste passar, mas sua versão for a que o teste de configuração (discutido na seção seguinte) falha, o resultado do teste é válido hermeticamente, mas não operacionalmente. Esse resultado é inconveniente.
Teste de configuração
No Google, as configurações de serviço web são descritas em arquivos armazenados em nosso sistema de controle de versão. Para cada arquivo de configuração, um teste de configuração separado examina a produção para ver como um binário específico está realmente configurado e relata as discrepâncias em relação a esse arquivo. Esses testes não são inerentemente herméticos, pois operam fora da área restrita da infraestrutura de teste.
Os testes de configuração são criados e testados para uma versão específica do arquivo de configuração verificado. Comparar qual versão do teste está passando em relação à versão desejada para automação indica implicitamente o quanto a produção real atualmente está atrasada em relação ao trabalho de engenharia em andamento.
Esses testes de configuração não hermética tendem a ser especialmente valiosos como parte de uma solução de monitoramento distribuída, uma vez que o padrão de aprovações/falhas na produção pode identificar caminhos através da pilha de serviço que não têm combinações sensatas das configurações locais. As regras da solução de monitoramento tentam combinar os caminhos das solicitações reais do usuário (dos logs de rastreamento) com esse conjunto de caminhos indesejáveis. Quaisquer correspondências encontradas pelas regras tornam-se alertas de que as versões e/ou pushes contínuos não estão ocorrendo com segurança e uma ação corretiva é necessária.
Os testes de configuração podem ser muito simples quando a implantação de produção usa o conteúdo real do arquivo e oferece uma consulta em tempo real para recuperar uma cópia do conteúdo. Nesse caso, o código de teste simplesmente emite essa consulta e difere a resposta do arquivo. Os testes tornam-se mais complexos quando a configuração executa uma das seguintes ações:
- Implicitamente incorpora padrões que são integrados ao binário (o que significa que os testes são versionados separadamente como resultado)
- Passa por um pré-processador, como bash, em flags de linha de comando (tornando os testes sujeitos a regras de expansão)
- Especifica o contexto comportamental para um tempo de execução compartilhado (fazendo com que os testes dependam da programação de lançamento desse tempo de execução)
Teste de stress
Para operar um sistema com segurança, os SREs precisam entender seus limites e componentes. Em muitos casos, os componentes individuais não degradam normalmente além de um certo ponto – em vez disso, eles falham catastroficamente. Os engenheiros usam testes de stress para encontrar os limites de um serviço web. Os testes de stress respondem a perguntas como:
- Quanto um banco de dados pode aguentar antes que as escritas comecem a falhar?
- Quantas consultas por segundo podem ser enviadas a um servidor de aplicativos antes que ele fique sobrecarregado, fazendo com que as solicitações falhem?
Teste Canary
O teste Canary está visivelmente ausente desta lista de testes de produção. O termo canary vem da frase “canário em uma mina de carvão” e se refere à prática de usar um pássaro vivo para detectar gases tóxicos antes que os humanos sejam envenenados.
Para conduzir um teste Canary, um subconjunto de servidores é atualizado para uma nova versão ou configuração e, em seguida, deixado em um período de incubação. Se nenhuma variação inesperada ocorrer, o lançamento continua e o restante dos servidores é atualizado de maneira progressiva. Se algo der errado, os servidores modificados podem ser revertidos rapidamente para um estado conhecido. Normalmente nos referimos ao período de incubação dos servidores atualizados como “preparando o binário”. (Uma regra prática padrão é começar tendo o impacto de lançamento em 0,1% do tráfego do usuário e, em seguida, escalonar em ordens de magnitude a cada 24 horas enquanto varia a localização geográfica dos servidores que estão sendo atualizados (então no dia 2: 1%, dia 3: 10%, dia 4: 100%).
Um teste Canary não é realmente um teste; em vez disso, é a aceitação estruturada por parte do usuário. Enquanto a configuração e os testes de stress confirmam a existência de uma condição específica em relação ao software determinístico, um teste canary é mais ad hoc. Ele apenas expõe o código em teste para tráfego de produção ao vivo menos previsível e, portanto, não é perfeito e nem sempre detecta falhas recém-introduzidas.
Para fornecer um exemplo concreto de como um canary pode proceder: considere uma determinada falha subjacente que afeta raramente o tráfego do usuário e está sendo implantada com uma implementação de atualização que é exponencial. Esperamos um número cumulativo crescente de variações relatadas CU = RK, onde R é a taxa desses relatórios, U é a ordem da falha (definida posteriormente) e K é o período durante o qual o tráfego cresce por um fator de e, ou 172%. (Por exemplo, assumindo um intervalo de 24 horas de crescimento exponencial contínuo entre 1% e 10%, K = 37523 segundos, ou cerca de 10 horas e 25 minutos).
Para evitar o impacto do usuário, uma implementação que desencadeia variações indesejáveis precisa ser rapidamente revertida para a configuração anterior. No curto tempo que a automação leva para observar as variações e responder, é provável que vários relatórios adicionais sejam gerados. Uma vez que a poeira assentou, esses relatórios podem estimar o número cumulativo C e a taxa R.
Dividindo e corrigindo para K dá uma estimativa de U, a ordem da falha subjacente. (Estamos usando a noção de ordem aqui no sentido de complexidade da “grande notação O“). Alguns exemplos:
U=1: a solicitação do usuário encontrou um código que está simplesmente quebrado.
U=2: a solicitação deste usuário danifica aleatoriamente os dados que a solicitação de um futuro usuário pode ver.
U=3: Os dados danificados aleatoriamente também são um identificador válido para uma solicitação anterior.
A maioria dos bugs são de ordem um: eles escalam linearmente com a quantidade de tráfego do usuário. Geralmente, você pode rastrear esses bugs convertendo os logs de todas as solicitações com respostas incomuns em novos testes de regressão. Essa estratégia não funciona para bugs de ordem superior; uma solicitação que falha repetidamente se todas as solicitações anteriores forem tentadas em ordem será aprovada repentinamente se algumas solicitações forem omitidas. É importante detectar esses bugs de ordem superior durante o lançamento, caso contrário, a carga de trabalho operacional pode aumentar muito rapidamente.
Mantendo a dinâmica dos bugs de ordem superior versus inferior em mente, quando você está usando uma estratégia de implementação exponencial, não é necessário tentar obter justiça entre as frações do tráfego do usuário. Contanto que cada método para estabelecer uma fração use o mesmo intervalo K, a estimativa de U será válida, embora você ainda não possa determinar qual método foi fundamental para iluminar a falha. O uso de muitos métodos sequencialmente, embora permitindo alguma sobreposição, mantém o valor de K pequeno. Essa estratégia minimiza o número total de variações visíveis ao usuário C, enquanto ainda permite uma estimativa inicial de U (esperando 1, é claro).
Criação de um ambiente de build e teste
Embora seja maravilhoso pensar sobre esses tipos de testes e cenários de falha no primeiro dia de um projeto, frequentemente os SREs se juntam a uma equipe de desenvolvedores quando um projeto já está em andamento – uma vez que a equipe de projeto valida seu modelo de pesquisa, sua biblioteca prova que o algoritmo da base do projeto é escalável, ou talvez quando todas as simulações da interface do usuário forem finalmente aceitáveis. A base de código da equipe ainda é um protótipo e testes abrangentes ainda não foram projetados ou implantados. Em tais situações, onde seus esforços de teste devem começar? A realização de testes de unidade para cada função e classe é uma perspectiva completamente assustadora se a cobertura de teste atual for baixa ou inexistente. Em vez disso, comece com testes que proporcionem o maior impacto com o mínimo de esforço.
Você pode iniciar sua abordagem com as seguintes perguntas:
- Você pode priorizar a base de código de alguma forma? Para emprestar uma técnica do desenvolvimento de features e gerenciamento de projetos, se todas as tarefas são de alta prioridade, nenhuma das tarefas é de alta prioridade. Você pode classificar os componentes do sistema que está testando por meio de qualquer medida de importância?
- Existem funções ou classes específicas que sejam de missão crítica críticas para os negócios? Por exemplo, o código que envolve faturamento é comumente crítico para os negócios. O código de faturamento também pode ser facilmente separado de outras partes do sistema.
Com quais APIs as outras equipes estão se integrando? Até mesmo o tipo de falha que nunca passa do teste de versão para um usuário pode ser extremamente prejudicial se confundir outra equipe de desenvolvedores, fazendo com que escrevam clientes errados (ou mesmo subótimos) para sua API.
Enviar software que está obviamente corrompido está entre os pecados mais graves de um desenvolvedor. Não é preciso muito esforço para criar uma série de testes de fumaça a serem executados a cada versão. Esse tipo de primeira etapa de baixo esforço e alto impacto pode resultar em um software altamente testado e confiável.
Uma maneira de estabelecer uma forte cultura de teste é começar a documentar todos os bugs relatados como casos de teste. Se cada bug for convertido em um teste, cada teste deve inicialmente falhar porque o bug ainda não foi corrigido. Conforme os engenheiros corrigem os bugs, o software passa no teste e você está no caminho para desenvolver uma suite de testes de regressão abrangente.
Outra tarefa importante para a criação de software bem testado é configurar uma infraestrutura de teste. A base para uma forte infraestrutura de teste é um sistema de controle de origem com versão que rastreia todas as alterações na base de código.
Depois que o controle de origem estiver em ordem, você pode adicionar um sistema de build contínuo que constrói o software e executa testes sempre que o código é enviado. Achamos ótimo se o sistema de build notifica os engenheiros no momento em que uma alteração interrompe um projeto de software. Correndo o risco de parecer óbvio, é essencial que a versão mais recente de um projeto de software no controle de origem esteja funcionando completamente. Quando o sistema de build notifica os engenheiros sobre código quebrado, eles devem abandonar todas as suas outras tarefas e priorizar a correção do problema. É apropriado tratar os defeitos com seriedade por alguns motivos:
- Geralmente é mais difícil consertar o que está quebrado se houver alterações na base de código depois que o defeito é introduzido.
- O software danificado desacelera a equipe porque eles precisam contornar a falha.
- As cadências de lançamento, como builds noturnos e semanais, perdem seu valor.
- A capacidade da equipe de responder a uma solicitação de liberação de emergência (por exemplo, em resposta a uma divulgação de vulnerabilidade de segurança) torna-se muito mais complexa e difícil.
Os conceitos de estabilidade e agilidade estão tradicionalmente em tensão no mundo SRE. O último ponto fornece um caso interessante em que a estabilidade realmente leva à agilidade. Quando a construção é previsivelmente sólida e confiável, os desenvolvedores podem iterar mais rápido!
Alguns sistemas de build como o Bazel contemplam recursos valiosos que permitem um controle mais preciso sobre os testes. Por exemplo, o Bazel cria gráficos de dependência para projetos de software. Quando uma alteração é feita em um arquivo, o Bazel faz o rebuilt apenas da parte do software que depende desse arquivo. Esses sistemas fornecem builds reproduzíveis. Em vez de executar todos os testes a cada envio, os testes são executados apenas para o código alterado. Como resultado, os testes são executados de forma mais barata e rápida.
Há uma variedade de ferramentas para ajudar a quantificar e visualizar o nível de cobertura de teste de que você precisa. Use essas ferramentas para moldar o foco do seu teste: aborde a perspectiva de criar um código altamente testado como um projeto de engenharia, em vez de um exercício mental filosófico. Em vez de repetir o refrão ambíguo “Precisamos de mais testes”, estabeleça metas e prazos explícitos.
Lembre-se de que nem todos os softwares são criados iguais. Os sistemas críticos para a vida ou para os negócios exigem níveis substancialmente mais altos de qualidade de testes e cobertura do que um script de não produção com uma vida útil curta.
Teste em escala
Agora que cobrimos os fundamentos do teste, vamos examinar como o SRE leva a uma perspectiva de sistema para o testes, a fim de impulsionar a confiabilidade em escala.
Um pequeno teste de unidade pode ter uma pequena lista de dependências: um arquivo de origem, a biblioteca de teste, as bibliotecas de tempo de execução, o compilador e o hardware local executando os testes. Um ambiente de teste robusto determina que cada uma dessas dependências tenha sua própria cobertura de teste, com testes que tratam especificamente de casos de uso esperados por outras partes do ambiente. Se a implementação desse teste de unidade depende de um caminho de código dentro de uma biblioteca de tempo de execução que não tem cobertura de teste, uma mudança não relacionada no ambiente pode levar o teste de unidade a passar consistentemente no teste, independentemente das falhas no código em teste.
Por exemplo, o código em teste que envolve uma API não trivial para fornecer uma abstração mais simples e compatível com versões anteriores. A API que costumava ser síncrona, em vez disso, retorna um futuro. Erros de argumento de chamada ainda fornecem uma exceção, mas não até que o futuro seja avaliado. O código em teste passa o resultado da API diretamente de volta para o responsável pela chamada. Muitos casos de uso indevido de argumentos podem não ser detectados.
Em contraste, um teste de liberação pode depender de tantas partes que tem uma dependência transitiva de cada objeto no repositório de código. Se o teste depender de uma cópia limpa do ambiente de produção, em princípio, cada pequeno patch vai requerer a execução de uma iteração completa de recuperação de desastres. Ambientes de teste prático tentam selecionar pontos de ramificação entre as versões e merges. Isso resolve a quantidade máxima de incerteza dependente para o número mínimo de iterações. Claro, quando uma área de incerteza se transforma em uma falha, você precisa selecionar pontos de ramificação adicionais.
Testando ferramentas escaláveis
Como peças de software, as ferramentas SRE também precisam ser testadas. Esta seção fala especificamente sobre as ferramentas usadas pelo SRE que precisam ser escalonáveis. No entanto, o SRE também desenvolve e usa ferramentas que não necessariamente precisam ser escalonáveis. As ferramentas que não precisam ser escalonáveis também precisam ser testadas, mas essas ferramentas estão fora do escopo desta seção e, portanto, não serão discutidas aqui. Porque sua pegada de risco é semelhante a aplicativos voltados para o usuário, estratégias de teste semelhantes são aplicáveis em tais ferramentas desenvolvidas pelos SREs.
As ferramentas desenvolvidas por SREs podem realizar tarefas como as seguintes:
- Recuperar e propagar métricas de desempenho do banco de dados
- Previsão de métricas de uso para planejar riscos de capacidade
- Refatoração de dados em uma réplica de serviço que não é acessível ao usuário
- Alterar arquivos em um servidor
As ferramentas SRE compartilham duas características:
- Seus efeitos colaterais permanecem dentro da API principal testada
- Elas estão isoladas da produção voltada para o usuário por uma validação e barreira de liberação
Barreira de defesa contra software arriscado
O software que contorna a API usual bastante testada pode causar estragos em um serviço ativo (mesmo que o faça por uma boa causa). Por exemplo, uma implementação de mecanismo de banco de dados pode permitir que os administradores desliguem temporariamente as transações para reduzir as janelas de manutenção. Se a implementação for usada por software de atualização em lote, o isolamento do usuário pode ser perdido se esse utilitário for acidentalmente iniciado em uma réplica do usuário. Evite este risco de destruição com o design:
- Use uma ferramenta separada para colocar uma barreira na configuração de replicação para que a réplica não passe na verificação de integridade. Como resultado, a réplica não é liberada para os usuários.
- Configure o software de risco para verificar a barreira na inicialização. Permita que o software de risco acesse apenas réplicas não íntegras.
- Use a ferramenta de validação de integridade de réplica que você usa para o monitoramento de caixa preta para remover a barreira.
As ferramentas de automação também são softwares. Como sua pegada de risco aparece fora de banda para uma camada diferente do serviço, suas necessidades de teste são mais sutis. As ferramentas de automação realizam tarefas como as seguintes:
- Seleção de índice de banco de dados
- Balanceamento de carga entre datacenters
- Misturar relay logs para rápida remasterização
As ferramentas de automação compartilham duas características:
- A operação real desempenhada é contra uma API robusta, previsível e bem testada
- O objetivo da operação é o efeito colateral que é uma descontinuidade invisível para outro cliente da API
O teste pode demonstrar o comportamento desejado da outra camada de serviço, antes e depois da alteração. Muitas vezes, é possível testar se o estado interno, conforme visto por meio da API, é constante em toda a operação. Por exemplo, bancos de dados buscam respostas corretas, mesmo se um índice adequado não estiver disponível para a consulta. Por outro lado, algumas invariantes de API documentadas (como um cache DNS que mantém até o TTL) podem não se manter durante a operação. Por exemplo, se uma mudança de nível de execução substituir um servidor de nomes local por um proxy de armazenamento em cache, ambas as opções podem prometer reter pesquisas concluídas por muitos segundos. É improvável que o estado do cache seja transferido de um para o outro.
Considerando que as ferramentas de automação implicam em testes de lançamento adicionais para outros binários para lidar com transientes ambientais, como você define o ambiente no qual essas ferramentas de automação são executadas? Afinal, a automação para embaralhar containers e melhorar seu uso provavelmente tentará embaralhar a si mesma em algum ponto se também for executada em um container. Seria constrangedor se um novo lançamento do seu algoritmo interno gerasse páginas de memória sujas tão rapidamente que a largura de banda da rede do espelhamento associado acabasse impedindo o código de finalizar a migração live. Mesmo se houver um teste de integração para o qual o binário se embaralha intencionalmente, o teste provavelmente não usa um modelo de tamanho de produção da frota de containers. É quase certo que não é permitido usar a escassa largura de banda intercontinental de alta latência para testar essas corridas.
Ainda mais divertido, uma ferramenta de automação pode alterar o ambiente no qual outra ferramenta de automação é executada. Ou ambas as ferramentas podem alterar o ambiente da outra ferramenta de automação simultaneamente! Por exemplo, uma ferramenta de atualização de frota provavelmente consome a maior parte dos recursos ao enviar atualizações. Como resultado, o rebalanceamento do container seria tentado a mover a ferramenta. Por sua vez, a ferramenta de rebalanceamento de container ocasionalmente precisa ser atualizada. Essa dependência circular é adequada se as APIs associadas tiverem semântica de reinicialização, se alguém tiver lembrado de implementar a cobertura de teste para essas semânticas e a integridade do ponto de verificação for garantida de forma independente.
Testando desastres
Muitas ferramentas de recuperação de desastres podem ser projetadas cuidadosamente para operar offline. Essas ferramentas fazem o seguinte:
- Calculam um estado de ponto de verificação equivalente a interromper o serviço de forma limpa
- Levam o estado do ponto de verificação para ser carregado por ferramentas de validação de desastres
- Apoiam as ferramentas usuais de liberação de barreiras, que acionam o procedimento de inicialização limpa
Em muitos casos, você pode implementar essas fases para que os testes associados sejam fáceis de escrever e ofereçam uma cobertura excelente. Se qualquer uma das restrições (offline, ponto de verificação, carregamento, barreira ou inicialização limpa) deve ser quebrada, é muito mais difícil mostrar confiança de que a implementação da ferramenta associada funcionará a qualquer momento em curto prazo.
As ferramentas de reparo online operam inerentemente fora da API principal e, portanto, tornam-se mais interessantes para testar. Um desafio que você enfrenta em um sistema distribuído é determinar se o comportamento normal, que pode ser consistente por natureza, irá interagir mal com o reparo. Por exemplo, considere uma condição de corrida que você pode tentar analisar usando as ferramentas offline. Uma ferramenta offline geralmente é escrita para esperar consistência instantânea, em oposição à consistência eventual, porque a consistência instantânea é menos desafiadora de testar. Essa situação se torna complicada porque o binário de reparo geralmente é construído separadamente do binário em produção contra o qual está competindo. Consequentemente, pode ser necessário construir um binário instrumentado unificado para ser executado nesses testes para que as ferramentas possam observar as transações.
Usando testes estatísticos
Técnicas estatísticas, como Lemon para fuzzing e Chaos Monkey e Jepsen para estado distribuído, não são necessariamente testes repetíveis. Simplesmente reexecutar esses testes após uma alteração no código não prova definitivamente que a falha observada foi corrigida. (Mesmo que a execução do teste seja repetida com a mesma semente aleatória, de forma que as mortes de tarefas fiquem na mesma ordem, não há serialização entre as mortes e o tráfego de usuário falso. Portanto, não há garantia de que o caminho do código real anteriormente observado será agora exercido novamente).
No entanto, essas técnicas podem ser úteis:
- Elas podem fornecer um registro de todas as ações selecionadas aleatoriamente que são realizadas em uma determinada execução – às vezes simplesmente registrando a semente do gerador de número aleatório.
- Se este log for imediatamente refatorado como um teste de lançamento, executá-lo algumas vezes antes de iniciar o relatório de bug pode ser útil. A taxa de não falha na reprodução informa como será difícil afirmar posteriormente que a falha foi corrigida.
- Variações em como a falha é expressa ajudam a identificar áreas suspeitas no código.
- Algumas dessas execuções posteriores podem demonstrar situações de falha mais graves do que as da execução original. Em resposta, você pode querer escalar a gravidade e o impacto do bug.
A necessidade de velocidade
Para cada versão (patch) no repositório de código, cada teste definido fornece uma indicação de aprovação ou reprovação. Essa indicação pode mudar para execuções repetidas e aparentemente idênticas. Você pode estimar a probabilidade real de aprovação ou reprovação de um teste calculando a média dessas muitas execuções e a incerteza estatística dessa probabilidade. No entanto, realizar esse cálculo para cada teste em cada ponto de versão é computacionalmente inviável.
Em vez disso, você deve formular hipóteses sobre os muitos cenários de interesse e executar o número apropriado de repetições de cada teste e versão para permitir uma inferência razoável. Alguns desses cenários são benignos (no sentido de qualidade do código), enquanto outros são acionáveis. Esses cenários afetam todas as tentativas de teste em extensões variadas e, porque eles são acoplados, obter de forma confiável e rápida uma lista de hipóteses acionáveis (ou seja, componentes que estão realmente quebrados) significa estimar todos os cenários ao mesmo tempo.
Os engenheiros que usam a infraestrutura de teste querem saber se o seu código – geralmente uma pequena fração de toda a fonte por trás de uma determinada execução de teste – está quebrado. Muitas vezes, não estar quebrado implica que qualquer falha observada pode ser atribuída ao código de outra pessoa. Em outras palavras, o engenheiro quer saber se seu código tem uma condição de corrida imprevista que torna o teste instável (ou mais instável do que o teste já era devido a outros fatores).
Testando prazos
A maioria dos testes é simples, no sentido de que são executados como um binário hermético autocontido que cabe em um pequeno container de computação por alguns segundos. Esses testes fornecem aos engenheiros feedback interativo sobre os erros antes que eles alternem o contexto para o próximo bug ou tarefa.
Os testes que requerem orquestração em muitos binários e/ou em uma frota com muitos containers tendem a ter tempos de inicialização medidos em segundos. Esses testes geralmente não são capazes de oferecer feedback interativo, portanto, podem ser classificados como testes em lote (batch tests). Em vez de dizer “não feche a guia do editor” para o engenheiro, essas falhas de teste estão dizendo “este código não está pronto para revisão” para o revisor do código.
O prazo final informal para o teste é o ponto em que o engenheiro faz a próxima troca de contexto. Os resultados dos testes são melhor fornecidos ao engenheiro antes que ele alterne o contexto, porque, do contrário, o próximo contexto pode envolver a compilação do XKCD.
Suponha que um engenheiro esteja trabalhando em um serviço com mais de 21.000 testes simples e, ocasionalmente, proponha um patch contra a base de código do serviço. Para testar o patch, você deseja comparar o vetor de resultados de aprovação/reprovação da base de código antes do patch com o vetor de resultados da base de código após o patch. Uma comparação favorável desses dois vetores provisoriamente qualifica a base de código como liberável. Essa qualificação cria um incentivo para executar os vários testes de liberação e integração, bem como outros testes binários distribuídos que examinam o dimensionamento do sistema (no caso de o patch usar significativamente mais recursos de computação locais) e complexidade (no caso de o patch criar uma carga de trabalho superlinear em outro lugar).
Com qual taxa você pode sinalizar incorretamente o patch de um usuário como prejudicial, calculando mal a instabilidade do ambiente? Parece provável que os usuários reclamariam veementemente se 1 em cada 10 patches fosse rejeitado. Mas a rejeição de 1 patch entre 100 patches perfeitos pode passar sem comentários.
Isso significa que você está interessado na raiz 42.000 (uma para cada teste definido antes do patch e uma para cada teste definido após o patch) de 0,99 (a fração de patches que são aceitos). Este cálculo:
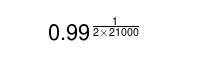
sugere que esses testes individuais devem ser executados corretamente em 99,9999% do tempo. Hmm.
Empurrando para produção
Embora o gerenciamento de configuração de produção seja normalmente mantido em um repositório de controle de origem, a configuração geralmente é separada do código-fonte do desenvolvedor. Da mesma forma, a infraestrutura de teste de software muitas vezes não consegue ver a configuração de produção. Mesmo se os dois estiverem localizados no mesmo repositório, as alterações para gerenciamento de configuração são feitas em ramos e/ou uma árvore de diretório segregada que a automação de teste tem historicamente ignorado.
Em um ambiente corporativo legado, onde engenheiros de software desenvolvem binários e os lançam para os administradores que atualizam os servidores, a segregação da infraestrutura de teste e da configuração de produção é, na melhor das hipóteses, irritante e, na pior, pode prejudicar a confiabilidade e a agilidade. Essa segregação também pode levar à duplicação de ferramentas. Em um ambiente Ops nominalmente integrado, essa segregação degrada a resiliência porque cria inconsistências sutis entre o comportamento dos dois conjuntos de ferramentas. Essa segregação também limita a velocidade do projeto por causa das corridas de commit entre os sistemas de controle de versão.
No modelo SRE, o impacto de segregar a infraestrutura de teste da configuração de produção é consideravelmente pior, pois evita relacionar o modelo que descreve a produção ao modelo que descreve o comportamento do aplicativo. Essa discrepância afeta os engenheiros que desejam encontrar inconsistências estatísticas nas expectativas no momento do desenvolvimento. No entanto, essa segregação não retarda o desenvolvimento tanto quanto evita que a arquitetura do sistema mude, porque não há como eliminar o risco de migração.
Considere um cenário de controle de versão e teste unificados, de forma que a metodologia SRE seja aplicável. Que impacto teria a falha de uma migração de arquitetura distribuída? Provavelmente ocorrerá uma boa quantidade de testes. Até agora, presume-se que um engenheiro de software provavelmente aceitaria o sistema de teste dando a resposta errada 1 vez em 10 ou mais. Qual risco você está disposto a correr com a migração se sabe que o teste pode retornar um falso negativo e a situação pode se tornar muito emocionante, muito rapidamente? Claramente, algumas áreas de cobertura de teste precisam de um nível mais alto de paranóia do que outras. Essa distinção pode ser generalizada: algumas falhas de teste são indicativas de um risco de impacto maior do que outras.
Esperar falha no teste
Não muito tempo atrás, um produto de software poderia ser lançado uma vez por ano. Seus binários eram gerados por uma cadeia de ferramentas do compilador ao longo de muitas horas ou dias, e a maioria dos testes era realizada por humanos com instruções escritas manualmente. Este processo de lançamento era ineficiente, mas havia pouca necessidade de automatizá-lo. O esforço de lançamento foi dominado por documentação, migração de dados, reciclagem do usuário e outros fatores. O Tempo Médio entre Falhas (MTBF) para essas versões era de um ano, não importando a quantidade de testes realizados. Tantas mudanças aconteciam a cada versão que alguma quebra visível ao usuário estava fadada a se esconder no software. Efetivamente, os dados de confiabilidade da versão anterior eram irrelevantes para a próxima versão.
Ferramentas eficazes de gerenciamento de API/ABI e linguagens interpretadas que escalam para grandes quantidades de código agora oferecem suporte à construção e execução de uma nova versão de software a cada poucos minutos. Em princípio, um exército de humanos suficientemente grande – talvez adquirido através do Mechanical Turk ou serviços semelhantes – poderia completar os testes em cada nova versão usando os métodos descritos anteriormente e atingir a mesma barra de qualidade para cada versão incremental. Mesmo que, em última análise, apenas os mesmos testes sejam aplicados ao mesmo código, a versão final do software tem qualidade superior na versão resultante que é enviada anualmente. Isso porque, além das versões anuais, também estão sendo testadas as versões intermediárias do código. Usando intermediários, você pode mapear de forma inequívoca os problemas encontrados durante o teste de volta às suas causas subjacentes e ter certeza de que todo o problema, e não apenas o sintoma limitado que foi exposto, foi corrigido. Este princípio de um ciclo de feedback mais curto é igualmente eficaz quando aplicado à cobertura de teste automatizado.
Se você permitir que os usuários experimentem mais versões do software durante o ano, o MTBF sofre porque há mais oportunidades de quebra visíveis para o usuário. No entanto, você também pode descobrir áreas que se beneficiariam de uma cobertura de teste adicional. Se esses testes forem implementados, cada melhoria protege contra alguma falha futura. O gerenciamento cuidadoso da confiabilidade combina os limites da incerteza devido à cobertura do teste com os limites das falhas visíveis ao usuário para ajustar a cadência de liberação. Essa combinação maximiza o conhecimento que você obtém das operações e dos usuários finais. Esses ganhos impulsionam a cobertura do teste e, por sua vez, a velocidade de lançamento do produto.
Se um SRE modifica um arquivo de configuração ou ajusta a estratégia de uma ferramenta de automação (em oposição à implementação de um recurso do usuário), o trabalho de engenharia corresponde ao mesmo modelo conceitual. Quando você está definindo uma cadência de lançamento com base na confiabilidade, geralmente faz sentido segmentar o orçamento de confiabilidade por funcionalidade ou (mais convenientemente) por equipe. Em tal cenário, a equipe de engenharia de recursos visa atingir um determinado limite de incerteza que afeta a cadência de liberação da sua meta. A equipe SRE tem um orçamento separado com sua própria incerteza associada e, portanto, um limite superior em sua taxa de liberação.
Para permanecer confiável e evitar o dimensionamento do número de SREs que dão suporte a um serviço de maneira linear, o ambiente de produção deve ser executado principalmente sem supervisão. Para permanecer sem vigilância, o ambiente deve ser resiliente contra pequenas falhas. Quando ocorre um evento importante que exige intervenção manual do SRE, as ferramentas utilizadas pelo SRE devem ser testadas adequadamente. Caso contrário, essa intervenção diminui a confiança de que os dados históricos são aplicáveis a um futuro próximo. A redução da confiança requer a espera por uma análise dos dados de monitoramento, a fim de eliminar a incerteza incorrida. Considerando que a discussão anterior neste capítulo em “Testando ferramentas escaláveis” se concentrou em como atender à oportunidade de cobertura de teste para uma ferramenta SRE, aqui você vê que o teste determina com que frequência é apropriado usar essa ferramenta na produção.
Os arquivos de configuração geralmente existem porque alterar a configuração é mais rápido do que reconstruir uma ferramenta. Essa baixa latência costuma ser um fator para manter o MTTR baixo. No entanto, esses mesmos arquivos também são alterados com frequência por motivos que não precisam dessa latência reduzida. Quando visto do ponto de vista da confiabilidade:
- Um arquivo de configuração que existe para manter o MTTR baixo, e só é modificado quando há uma falha, tem uma cadência de liberação mais lenta que o MTBF. Pode haver uma grande incerteza quanto a se uma determinada edição manual é realmente ideal, sem que a edição afete a confiabilidade geral do site.
- Um arquivo de configuração que muda mais de uma vez por versão do aplicativo voltado para o usuário (por exemplo, porque contém o estado de versão) pode ser um grande risco se essas alterações não forem tratadas da mesma forma que as versões do aplicativo. Se a cobertura de teste e monitoramento desse arquivo de configuração não for consideravelmente melhor do que a do aplicativo do usuário, esse arquivo dominará a confiabilidade do site de maneira negativa.
Um método de lidar com arquivos de configuração é certificar-se de que cada um seja categorizado em apenas uma das opções na lista anterior e, de alguma forma, impor essa regra. Se você seguir a segunda estratégia, certifique-se do seguinte:
- Cada arquivo de configuração tem cobertura de teste suficiente para oferecer suporte à edição regular de rotina.
- Antes dos lançamentos, as edições de arquivo são um pouco atrasadas enquanto aguardam o teste de versão.
- Forneça um mecanismo break glass para fazer o push do arquivo antes de concluir o teste. Visto que isso prejudica a confiabilidade, geralmente é uma boa ideia tornar essa quebra barulhenta (por exemplo) registrando um bug que solicita uma resolução mais robusta para a próxima vez.
Break-Glass e testes
Você pode implementar um mecanismo break-glass para desabilitar o teste de liberação. Fazer isso significa que quem quer que faça uma edição manual apressada não seja informado sobre nenhum erro até que o impacto real sobre o usuário seja relatado pelo monitoramento. É melhor deixar os testes em execução, associar o evento de push anterior ao evento de teste pendente e (o mais rápido possível) anotar novamente o push com quaisquer testes interrompidos. Dessa forma, um push manual defeituoso pode ser seguido rapidamente por outro (esperançosamente menos defeituoso) push manual. Idealmente, esse mecanismo de break-glass aumenta automaticamente a prioridade desses testes de liberação para que eles possam antecipar a validação incremental de rotina e a carga de trabalho de cobertura que a infraestrutura de teste já está processando.
Integração
Além de testar a unidade de um arquivo de configuração para reduzir o risco de confiabilidade, também é importante considerar os arquivos de configuração de teste de integração. O conteúdo do arquivo de configuração é (para fins de teste) conteúdo potencialmente hostil para o interpretador que lê a configuração. Linguagens interpretadas como Python são comumente usadas para arquivos de configuração porque seus interpretadores podem ser incorporados, e alguns sandboxing simples estão disponíveis para proteção contra erros de codificação não maliciosos.
Gravar seus arquivos de configuração em uma linguagem interpretada é arriscado, pois essa abordagem está repleta de falhas latentes que são difíceis de resolver definitivamente. Como o carregamento do conteúdo, na verdade, consiste na execução de um programa, não há limite superior inerente de quão ineficiente o carregamento pode ser. Além de qualquer outro teste, você deve parear este tipo de teste de integração com a verificação cuidadosa do prazo em todos os métodos de teste de integração, a fim de rotular como falha os testes que não são executados até a conclusão em um período de tempo razoável.
Se, em vez disso, a configuração for escrita como texto em uma sintaxe personalizada, cada categoria de teste precisa de cobertura separada desde o início. Usar uma sintaxe existente, como YAML, em combinação com um parser altamente testado, como o safe_load do Python, remove parte do trabalho incorrido pelo arquivo de configuração. A escolha cuidadosa da sintaxe e do parser pode garantir que haja um limite superior rígido de quanto tempo a operação de carregamento pode levar. No entanto, o implementador precisa abordar as falhas de schema e as estratégias mais simples para fazer isso não têm um limite superior no tempo de execução. Pior ainda, essas estratégias tendem a não ser testadas em unidades de maneira robusta.
O benefício de usar buffers de protocolo é que o schema é definido com antecedência e verificado automaticamente no momento do carregamento, removendo ainda mais o trabalho, mas ainda oferecendo o tempo de execução limitado.
A função do SRE geralmente inclui escrever ferramentas de engenharia de sistemas e adicionar validação robusta com cobertura de teste. (Nota: Não que os engenheiros de software não devam escrever ferramentas de engenharia de sistemas. As ferramentas que se cruzam entre verticais de tecnologia e abrangem camadas de abstração tendem a ter associações fracas com muitas equipes de software e uma associação um pouco mais forte com equipes de sistemas). Todas as ferramentas podem se comportar de maneira inesperada devido a bugs não detectados pelo teste, portanto, é aconselhável uma defesa profunda. Quando uma ferramenta se comporta de maneira inesperada, os engenheiros precisam estar tão confiantes quanto possível de que a maioria de suas outras ferramentas estão funcionando corretamente e podem, portanto, mitigar ou resolver os efeitos colaterais desse mau comportamento. Um elemento chave para fornecer confiabilidade ao site é encontrar cada forma antecipada de mau comportamento e certificar-se de que algum teste (ou o validador de entrada testado de outra ferramenta) relata esse mau comportamento. A ferramenta que encontra o problema pode não ser capaz de consertar ou mesmo interrompê-lo, mas deve pelo menos relatar o problema antes que ocorra uma interrupção catastrófica.
Por exemplo, considere a lista configurada de todos os usuários (como /etc/passwd em uma máquina estilo Unix sem rede) e imagine uma edição que involuntariamente faz com que o parser pare após analisar apenas metade do arquivo. Como os usuários criados recentemente não foram carregados, a máquina provavelmente continuará a funcionar sem problemas e muitos usuários podem não notar a falha. A ferramenta que mantém os diretórios pessoais pode facilmente notar a incompatibilidade entre os diretórios reais presentes e aqueles implícitos pela lista de usuários (parcial) e relatar a discrepância com urgência. O valor desta ferramenta está em relatar o problema e deve evitar a tentativa de correção por conta própria (excluindo muitos dados do usuário).
Probes na produção
Dado que o teste especifica um comportamento aceitável em face de dados conhecidos, enquanto o monitoramento confirma o comportamento aceitável em face de dados de usuário desconhecidos, parece que as principais fontes de risco – tanto o conhecido quanto o desconhecido – são cobertas pela combinação de testes e monitoramento. Infelizmente, o risco real é mais complicado.
Solicitações válidas conhecidas devem funcionar, enquanto solicitações incorretas conhecidas devem gerar erros. Implementar os dois tipos de cobertura como um teste de integração geralmente é uma boa ideia. Você pode reproduzir o mesmo banco de solicitações de teste como um teste de liberação. Dividir as solicitações válidas conhecidas entre as que podem ser reproduzidas na produção e aquelas que não podem gera três conjuntos de solicitações:
- Solicitações inválidas conhecidas
- Solicitações boas conhecidas que podem ser reproduzidas em produção
- Solicitações boas conhecidas que não podem ser reproduzidas em produção
Você pode usar cada conjunto como testes de integração e liberação. A maioria desses testes também pode ser usada como probe de monitoramento.
Pareceria supérfluo e, em princípio, inútil implantar esse monitoramento porque essas mesmas solicitações já foram tentadas de duas outras maneiras. No entanto, essas duas maneiras eram diferentes por alguns motivos:
- O teste de lançamento provavelmente envolveu o servidor integrado com um frontend e um backend falso.
- O teste de investigação provavelmente envolveu o binário de lançamento com um frontend de balanceamento de carga e um backend persistente escalonável separado.
- Os frontends e backends provavelmente têm ciclos de lançamento independentes. É provável que os cronogramas para esses ciclos ocorram em taxas diferentes (devido às suas cadências de liberação adaptativa).
Portanto, o probe de monitoramento em execução na produção é uma configuração que não foi testada anteriormente.
Esses probes nunca devem falhar, mas o que significa se falharem? A API de frontend (do balanceador de carga) ou a API de backend (para o armazenamento persistente) não é equivalente entre os ambientes de produção e lançamento. A menos que você já saiba por que os ambientes de produção e lançamento não são equivalentes, o site provavelmente está quebrado.
O mesmo atualizador de produção que substitui gradualmente o aplicativo também substitui gradualmente os probes, de forma que todas as quatro combinações de probes antigos ou novos que enviam solicitações para aplicativos antigos ou novos sejam geradas continuamente. Esse atualizador pode detectar quando uma das quatro combinações está gerando erros e reverter para o último estado bom conhecido. Normalmente, o atualizador espera que cada instância de aplicativo recém-iniciada não seja íntegra por um curto período, enquanto se prepara para começar a receber muito tráfego de usuário. Se os probes já foram inspecionados como parte da verificação de prontidão, a atualização falhará com segurança indefinidamente e nenhum tráfego de usuário será roteado para a nova versão. A atualização permanece pausada até que os engenheiros tenham tempo e disposição para diagnosticar a condição de falha e então encorajar o atualizador de produção a reverter de forma limpa.
Este teste de produção por probe realmente oferece proteção ao site, além de feedback claro para os engenheiros. Quanto mais cedo o feedback for dado aos engenheiros, mais útil será. Também é preferível que o teste seja automatizado para que a entrega de avisos aos engenheiros seja escalonável.
Suponha que cada componente tenha a versão de software mais antiga que está sendo substituída e a versão mais recente que está sendo lançada (agora ou muito em breve). A versão mais recente pode estar se comunicando com o peer da versão anterior, o que o força a usar a API obsoleta. Ou a versão mais antiga pode estar se comunicando com a versão mais recente de um peer, usando a API que (no momento em que a versão mais antiga foi lançada) ainda não funcionava corretamente. Mas agora funciona! É melhor você torcer para que esses testes de compatibilidade futura (que estão sendo executados como probes de monitoramento) tenham uma boa cobertura de API.
Versões falsas de backend
Ao implementar testes de versão, o backend falso é frequentemente mantido pela equipe de engenharia do serviço e meramente referenciado como uma dependência de build. O teste hermético que é executado pela infraestrutura de teste sempre combina o backend falso e o frontend de teste no mesmo ponto de build no histórico de controle de revisão.
Essa dependência de build pode fornecer um binário hermético executável e, idealmente, a equipe de engenharia que o mantém corta uma versão desse binário de backend falso ao mesmo tempo que corta seu aplicativo de backend principal e suas probes. Se essa versão de backend estiver disponível, pode valer a pena incluir testes de versão herméticos de frontend (sem o binário de backend falso) no pacote de lançamento de frontend.
Seu monitoramento deve estar ciente de todas as versões de lançamento em ambos os lados de uma determinada interface de serviço entre dois peers. Essa configuração garante que recuperar todas as combinações das duas versões e determinar se o teste ainda passa não exige muita configuração extra. Esse monitoramento não precisa acontecer continuamente – você só precisa executar novas combinações que são o resultado de qualquer uma das equipes cortando uma nova versão. Esses problemas não precisam bloquear essa nova versão em si.
Por outro lado, a automação do rollout deve, idealmente, bloquear o rollout de produção associado até que as combinações problemáticas não sejam mais possíveis. Da mesma forma, a automação da equipe de peers pode considerar drenar (e atualizar) as replicas que ainda não foram movidas de uma combinação problemática.
Conclusão
O teste é um dos investimentos mais lucrativos que os engenheiros podem fazer para melhorar a confiabilidade de seu produto. O teste não é uma atividade que acontece uma ou duas vezes no ciclo de vida de um projeto; é contínuo. A quantidade de esforço necessária para escrever bons testes é substancial, assim como o esforço para construir e manter uma infraestrutura que promova uma forte cultura de teste. Você não pode consertar um problema até entendê-lo; e, na engenharia, você só pode entender um problema medindo-o. As metodologias e técnicas contidas neste capítulo fornecem uma base sólida para medir falhas e incertezas em um sistema de software e ajudam os engenheiros a raciocinar sobre a confiabilidade do software conforme ele é escrito e lançado para os usuários.
Fonte: Google SRE Book