1 – No menu lateral, clique em Services Hub

2 – Na categoria Monitoring, clique no card Website POST

3 – Você será direcionado para o formulário de configuração do Website POST, preencha os campos


Obs.: Por motivos de segurança, não é permitido inserir um IP no campo de healthcheck URL. Para monitorar um IP, é necessário inserí-lo em uma secret e usá-la no healthcheck URL.
4 – Caso queira, você poderá configurar a abertura automática de incidente. Na seção Open automatic incident, preencha os campos:
- Severity -> Escolha entre “SEV-1 – Critical”, “SEV-2 – High”, “SEV-3 – Moderate”, “SEV-4 – Low”, “SEV-5 – Informational” ou “Not Classified”;
- Check Interval in seconds -> É o intervalo em que haverá checagem (este intervalo não pode ser menor que o número de falhas x o Interval configurado no formulário do monitoramento;
- Failures to open automatic incident -> É a quantidade de falhas necessárias para abertura do incidente automático;
- Check Interval in seconds -> É o intervalo em que haverá checagem (este intervalo não pode ser menor que o número de hits x o Interval configurado no formulário do monitoramento;
- Hits to close automatic incident -> É a quantidade de hits necessários para o fechamento do incidente automático;
- Responders -> São os times que serão notificados caso haja incidentes neste monitoramento, podendo adicionar um ou múltiplos times
Caso necessite, poderá criar um time clicando em + RESPONDER, será direcionado para o formulário de criação do time, em seguida clique no botão para o novo time aparecer na listagem
para o novo time aparecer na listagem
***Não se esqueça de ativar a chave Enable to set up automatic incidents opening para salvar as configurações de abertura de incidente automático

5 – Clique em CREATE MONITORING

Mais abaixo, vemos a sessão de Event History, onde temos uma time line dos incidentes abertos neste monitoramento

Podemos filtrar pelo Status ou severidade do incidente
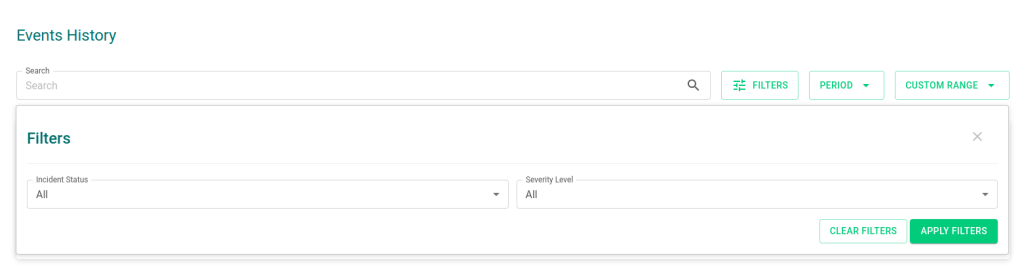
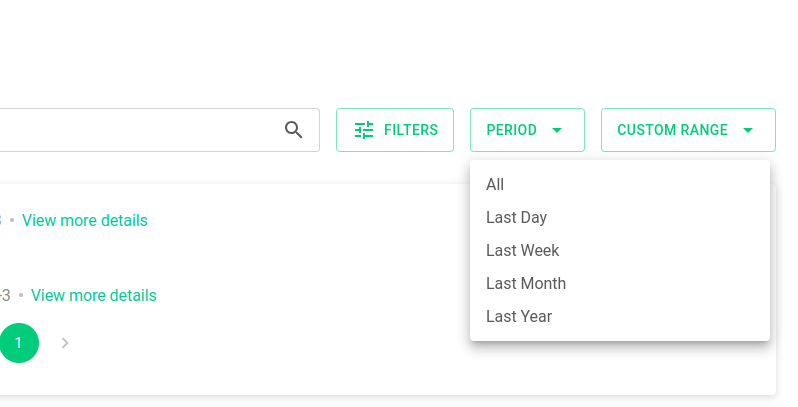
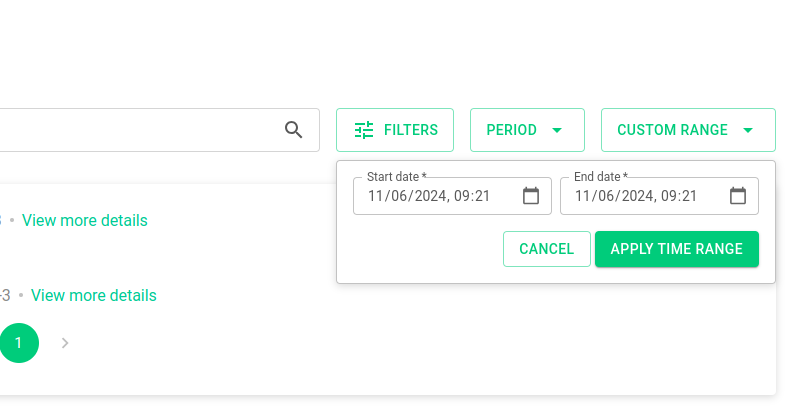
E também o período (pré estabelecido ou customizado)
Clicando em View more details, será encaminhado ao incidente em questão




















































