Escrito por Laura Nolan
Editado por Tim Harvey
Os processos falham ou podem precisar ser reiniciados. Os discos rígidos falham. Desastres naturais podem destruir vários datacenters em uma região. Os engenheiros de confiabilidade do site precisam antecipar esses tipos de falhas e desenvolver estratégias para manter os sistemas funcionando, apesar delas. Essas estratégias geralmente envolvem a execução desses sistemas em vários sites. Distribuir geograficamente um sistema é relativamente simples, mas também introduz a necessidade de manter uma visão consistente do estado do sistema, que é uma tarefa mais complexa e difícil.
Grupos de processos podem querer concordar de forma confiável em questões como:
- Qual processo é o líder de um grupo de processos?
- Qual é o conjunto de processos em um grupo?
- Uma mensagem foi confirmada com sucesso em uma fila distribuída?
- Um processo tem ou não um contrato de concessão envolvido
- O que é um valor em um armazenamento de dados para uma determinada chave?
Descobrimos que o consenso distribuído é eficaz na construção de sistemas confiáveis e altamente disponíveis que exigem uma visão consistente de algum estado do sistema. O problema do consenso distribuído trata de chegar a um acordo entre um grupo de processos conectados por uma rede de comunicação não confiável. Por exemplo, vários processos em um sistema distribuído podem precisar ser capazes de formar uma visão consistente de uma parte crítica da configuração, se um bloqueio distribuído é mantido ou não, ou se uma mensagem em uma fila foi processada. É um dos conceitos mais fundamentais em computação distribuída e em que confiamos para praticamente todos os serviços que oferecemos. A figura abaixo ilustra um modelo simples de como um grupo de processos pode obter uma visão consistente do estado do sistema por meio de um consenso distribuído.
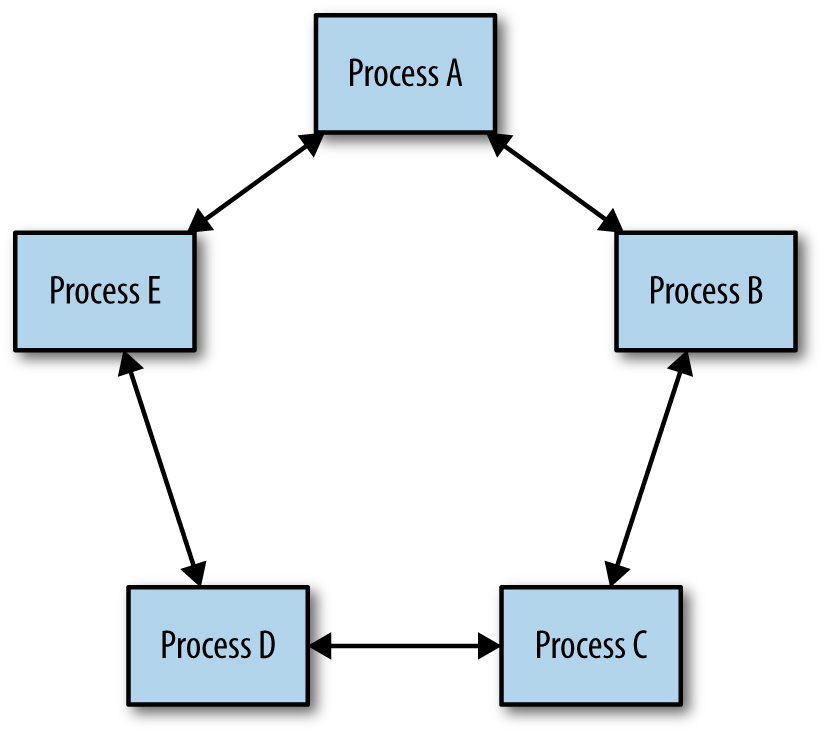
[Figura] – Legenda: Consenso distribuído: “acordo” entre um grupo de processos
Sempre que você visualizar a eleição do líder, o estado compartilhado crítico ou o bloqueio distribuído, recomendamos o uso de sistemas de consenso distribuídos que foram formalmente comprovados e testados exaustivamente. Abordagens informais para resolver esse problema podem levar a interrupções e, mais insidiosamente, a problemas de consistência de dados sutis e difíceis de corrigir que podem prolongar interrupções desnecessárias em seu sistema.
Teorema CAP
O teorema CAP (disponíveis em mais detalhes em dois documentos, aqui e aqui) sustenta que um sistema distribuído não pode ter simultaneamente todas as três propriedades a seguir:
- Visualizações consistentes dos dados em cada nó
- Disponibilidade dos dados em cada nó
- Tolerância a partições de rede (consulte mais detalhes aqui)
A lógica é intuitiva: se dois nós não podem se comunicar (porque a rede é particionada), então o sistema como um todo pode parar de atender algumas ou todas as solicitações em alguns ou todos os nós (reduzindo assim a disponibilidade), ou pode atender solicitações como de costume, o que resulta em visualizações inconsistentes dos dados em cada nó.
Como as partições de rede são inevitáveis (cabos são cortados, pacotes são perdidos ou atrasados devido a congestionamento, quebras de hardware, componentes de rede são configurados incorretamente etc.), entender o consenso distribuído realmente equivale a entender como a consistência e a disponibilidade funcionam para uma aplicação específica. As pressões comerciais geralmente exigem altos níveis de disponibilidade e muitos aplicativos exigem visualizações consistentes de seus dados.
Engenheiros de sistemas e software geralmente estão familiarizados com a semântica tradicional de armazenamento de dados ACID (Atomicidade, Consistência, Isolamento e Durabilidade), mas um número crescente de tecnologias de armazenamento de dados distribuído fornece um conjunto diferente de semântica conhecido como BASE (Basicamente Disponível, Soft state e consistência eventual). Datastores que suportam a semântica BASE têm aplicações úteis para certos tipos de dados e podem lidar com grandes volumes de dados e transações que seriam muito mais caras, e talvez totalmente inviáveis, com datastores que suportam a semântica ACID.
A maioria desses sistemas que suportam a semântica BASE depende da replicação multimaster, onde as gravações podem ser confirmadas em diferentes processos simultaneamente, e há algum mecanismo para resolver conflitos (geralmente tão simples quanto “o último timestamp vence”). Essa abordagem é geralmente conhecida como consistência eventual. No entanto, a consistência eventual pode levar a resultados surpreendentes, particularmente no caso de clock drift (o que é inevitável em sistemas distribuídos) ou particionamento de rede. (Kyle Kingsbury escreveu uma extensa série de artigos sobre correção de sistemas distribuídos, que contém muitos exemplos de comportamento inesperado e incorreto nesses tipos de armazenamentos de dados).
Também é difícil para os desenvolvedores projetar sistemas que funcionem bem com datastores que suportem apenas a semântica BASE. Jeff Shute, por exemplo, afirmou: “descobrimos que os desenvolvedores gastam uma fração significativa de seu tempo construindo mecanismos extremamente complexos e propensos a erros para lidar com a consistência eventual e lidar com dados que podem estar desatualizados. Achamos que esse é um fardo inaceitável para os desenvolvedores e que os problemas de consistência devem ser resolvidos no nível do banco de dados.”
Os designers de sistemas não podem sacrificar a exatidão para obter confiabilidade ou desempenho, principalmente em torno do estado crítico. Por exemplo, considere um sistema que lida com transações financeiras: requisitos de confiabilidade ou desempenho não fornecem muito valor se os dados financeiros não estiverem corretos. Os sistemas precisam ser capazes de sincronizar de forma confiável o estado crítico em vários processos. Algoritmos de consenso distribuído fornecem essa funcionalidade.
Motivando o uso do consenso: falha na coordenação de sistemas distribuídos
Os sistemas distribuídos são complexos e sutis para entender, monitorar e solucionar problemas. Os engenheiros que executam esses sistemas geralmente ficam surpresos com o comportamento na presença de falhas. As falhas são eventos relativamente raros e não é uma prática comum testar sistemas nessas condições. É muito difícil raciocinar sobre o comportamento do sistema durante as falhas. As partições de rede são particularmente desafiadoras – um problema que parece ser causado por uma partição completa pode ser o resultado de:
- Uma rede muito lenta
- Algumas mensagens, mas não todas, sendo descartadas
- Estrangulamento ocorrendo em uma única direção
As seções a seguir fornecem exemplos de problemas que ocorreram em sistemas distribuídos do mundo real e discutem como a eleição do líder e os algoritmos de consenso distribuído podem ser usados para evitar esses problemas.
Estudo de caso 1: o problema do cérebro dividido
Um serviço é um repositório de conteúdo que permite a colaboração entre vários usuários. Ele usa conjuntos de dois servidores de arquivos replicados em diferentes racks para confiabilidade. O serviço precisa evitar gravar dados simultaneamente em ambos os servidores de arquivos em um conjunto, pois isso pode resultar em corrupção de dados (e possivelmente dados irrecuperáveis).
Cada par de servidores de arquivos tem um líder e um seguidor. Os servidores monitoram uns aos outros por meio de pulsações. Se um servidor de arquivos não puder contatar seu parceiro, ele emite um comando STONITH (“Shoot The Other Node in the Head” – “acerte o nó na cabeça”) para seu nó parceiro para encerrar o nó e, em seguida, assumir o controle de seus arquivos. Essa prática é um método padrão da indústria para reduzir instâncias de cérebro dividido, embora, como veremos a seguir, seja conceitualmente infundado.
O que acontece se a rede ficar lenta ou começar a descartar pacotes? Nesse cenário, os servidores de arquivos excedem seus tempos limite de pulsação e, conforme projetado, enviam comandos STONITH para seus nós parceiros e assumem o controle. No entanto, alguns comandos podem não ser entregues devido à rede comprometida. Os pares de servidores de arquivos agora podem estar em um estado no qual ambos os nós devem estar ativos para o mesmo recurso ou em que ambos estão inativos porque ambos emitiram e receberam comandos STONITH. Isso acaba resultando em uma corrupção ou indisponibilidade de dados.
O problema aqui é que o sistema está tentando resolver um problema de eleição de líder usando tempos limite simples. A eleição do líder é uma reformulação do problema do consenso assíncrono distribuído, que não pode ser resolvido corretamente usando pulsações.
Estudo de caso 2: failover requer intervenção humana
Um sistema de banco de dados altamente fragmentado tem um primário para cada fragmento, que é replicado de forma síncrona para um secundário em outro datacenter. Um sistema externo verifica a integridade das primárias e, se elas não estiverem mais íntegras, promove a secundária para primária. Se o primário não puder determinar a saúde de seu secundário, ele se torna indisponível e escala para um humano para evitar o cenário de cérebro dividido visto no Estudo de caso 1.
Esta solução não incorre no risco de perda de dados, mas afeta negativamente a disponibilidade dos mesmos. Também aumenta desnecessariamente a carga operacional dos engenheiros que executam o sistema, e a intervenção humana é escalonada. Esse tipo de evento, em que um primário e um secundário têm problemas de comunicação, é altamente provável de ocorrer no caso de um problema de infraestrutura maior, quando os engenheiros encarregados da resposta já podem estar sobrecarregados com outras tarefas. Se a rede é tão afetada que um sistema de consenso distribuído não pode eleger um mestre, um humano provavelmente não está melhor posicionado para fazê-lo.
Estudo de caso 3: algoritmos de associação de grupo defeituosos
Um sistema possui um componente que executa serviços de indexação e pesquisa. Ao iniciar, os nós usam um protocolo “gossip” para descobrir uns aos outros e ingressar no cluster. O cluster elege um líder, que realiza a coordenação. No caso de uma partição de rede que divide o cluster, cada lado (incorretamente) elege um mestre e aceita gravações e exclusões, levando a um cenário de divisão cerebral e corrupção de dados.
O problema de determinar uma visão consistente da associação de grupo em um grupo de processos é outra instância do problema de consenso distribuído.
De fato, muitos problemas de sistemas distribuídos são versões diferentes de consenso distribuído, incluindo eleição de mestre, associação de grupo, todos os tipos de bloqueio e concessão distribuídos, enfileiramento e mensagens distribuídas confiáveis e manutenção de qualquer tipo de estado compartilhado crítico que devem ser vistos de forma consistente em um grupo de processos. Todos esses problemas devem ser resolvidos apenas usando algoritmos de consenso distribuído que tenham sido comprovados formalmente corretos e cujas implementações tenham sido testadas extensivamente. Meios ad hoc de resolver esses tipos de problemas (como heartbeats e gossip protocols) sempre terão problemas de confiabilidade na prática.
Como funciona o consenso distribuído
O problema do consenso tem múltiplas variantes. Ao lidar com sistemas de software distribuídos, estamos interessados no consenso distribuído assíncrono, que se aplica a ambientes com atrasos potencialmente ilimitados na passagem de mensagens. (O consenso síncrono se aplica a sistemas de tempo real, nos quais hardware dedicado significa que as mensagens sempre serão transmitidas com garantias de tempo específicas).
Os algoritmos de consenso distribuídos podem ser do tipo crash-fail (que pressupõe que os nós com falha nunca retornam ao sistema) ou do tipo crash-recover. Os algoritmos de crash-recover (de recuperação de falhas) são muito mais úteis, porque a maioria dos problemas em sistemas reais são transitórios por natureza devido a uma rede lenta, reinicializações e assim por diante.
Os algoritmos podem lidar com falhas bizantinas ou não bizantinas. A falha bizantina (Byzantine failure) ocorre quando um processo passa mensagens incorretas devido a um bug ou atividade maliciosa, e são comparativamente dispendiosos de manusear e encontrados com menos frequência.
Tecnicamente, resolver o problema de consenso distribuído assíncrono em tempo limitado é impossível. Conforme comprovado pelo resultado de impossibilidade FLP vencedor do Prêmio Dijkstra, nenhum algoritmo de consenso distribuído assíncrono pode garantir progresso na presença de uma rede não confiável.
Na prática, abordamos o problema do consenso distribuído em tempo limitado, garantindo que o sistema tenha réplicas íntegras e conectividade de rede suficientes para progredir de maneira confiável na maioria das vezes. Além disso, o sistema deve ter backoffs com atrasos aleatórios. Essa configuração evita que as tentativas causem efeitos em cascata e evita o problema dos proponentes de duelo descrito mais adiante neste capítulo. Os protocolos garantem a segurança e a redundância adequada no sistema estimula a vivacidade.
A solução original para o problema do consenso distribuído foi o protocolo Paxos de Lamport, mas existem outros protocolos que resolvem o problema, incluindo Raft, o Zab e o Mencius. O próprio Paxos tem muitas variações destinadas a aumentar o desempenho. Eles geralmente variam apenas em um único detalhe, como dar uma função de líder especial a um processo para simplificar o protocolo.
Visão geral do Paxos: um protocolo de exemplo
O Paxos funciona como uma sequência de propostas, que podem ou não ser aceitas pela maioria dos processos do sistema. Se uma proposta não for aceita, ela falha. Cada proposta possui um número de sequência, que impõe uma ordenação estrita a todas as operações do sistema.
Na primeira fase do protocolo, o proponente envia um número de sequência aos aceitadores. Cada aceitante concordará em aceitar a proposta somente se ainda não tiver visto uma proposta com um número de sequência superior. Os proponentes podem tentar novamente com um número de sequência mais alto, se necessário. Os proponentes devem usar números de sequência únicos (desenhados de conjuntos desmembrados ou incorporando seu nome de host ao número da sequência, por exemplo).
Se um proponente receber a concordância da maioria dos aceitantes, ele poderá confirmar a proposta enviando uma mensagem de confirmação com um valor.
O estrito sequenciamento das propostas resolve qualquer problema relacionado à ordenação das mensagens no sistema. A exigência de uma maioria para confirmar significa que dois valores diferentes não podem ser confirmados para a mesma proposta, porque quaisquer duas maiorias se sobrepõem em pelo menos um nó. Os aceitantes devem escrever um diário sobre armazenamento persistente sempre que concordarem em aceitar uma proposta, porque os aceitantes precisam honrar essas garantias após o reinício.
O Paxos por si só não é tão útil: tudo o que permite fazer é concordar com um valor e número de proposta uma vez. Como apenas um quorum de nós precisa concordar com um valor, qualquer nó pode não ter uma visão completa do conjunto de valores que foram acordados. Essa limitação é verdadeira para a maioria dos algoritmos de consenso distribuídos.
Padrões de arquitetura de sistema para consenso distribuído
Os algoritmos de consenso distribuído são primitivos e de baixo nível: eles simplesmente permitem que um conjunto de nós concorde com um valor, uma vez. Eles não mapeiam bem as tarefas reais de design. O que torna o consenso distribuído útil é a adição de componentes de sistema de nível superior, como armazenamentos de dados, armazenamentos de configuração, filas, bloqueio e serviços de eleição de líderes para fornecer a funcionalidade prática do sistema que os algoritmos de consenso distribuído não abordam. O uso de componentes de nível superior reduz a complexidade para os projetistas de sistemas. Ele também permite que algoritmos de consenso distribuído subjacentes sejam alterados, se necessário, em resposta a alterações no ambiente no qual o sistema é executado ou alterações em requisitos não funcionais.
Muitos sistemas que usam algoritmos de consenso com sucesso, na verdade o fazem como clientes de algum serviço que implementa esses algoritmos, como Zookeeper, Consul e etcd. O Zookeeper foi o primeiro sistema de consenso de código aberto a ganhar força no setor porque era fácil de usar, mesmo com aplicações que não foram projetadas para usar consenso distribuído. O serviço Chubby preenche um nicho semelhante no Google. Seus autores apontam que fornecer primitivas de consenso como um serviço em vez de bibliotecas que os engenheiros criam em suas aplicações libera os mantenedores de aplicações de fazer o deploy de seus sistemas de maneira compatível com um serviço de consenso altamente disponível (executando o número certo de replicas, lidando com a participação do grupo, com o desempenho etc.).
Replicação confiável de máquina de estado
Uma máquina de estado replicada (RSM) é um sistema que executa o mesmo conjunto de operações, na mesma ordem, em vários processos. As RSMs representam o building block fundamental de componentes e serviços úteis de sistemas distribuídos, como armazenamento de dados ou configuração, bloqueio e eleição de líderes (descritos com mais detalhes posteriormente).
As operações em um RSM são ordenadas globalmente por meio de um algoritmo de consenso. Este é um conceito poderoso: vários artigos ([aqui], [aqui], e [aqui]) mostram que qualquer programa determinístico pode ser implementado como um serviço replicado de alta disponibilidade sendo implementado como uma RSM.
Conforme mostrado na figura abaixo, as máquinas de estado replicadas são um sistema implementado em uma camada lógica acima do algoritmo de consenso. O algoritmo de consenso lida com o acordo sobre a sequência de operações, e a RSM executa as operações nessa ordem. Como nem todos os membros do grupo de consenso são necessariamente membros de cada quorum de consenso, as RSMs podem precisar sincronizar o estado dos pares. Conforme descrito por Kirsch e Amir, você pode usar um protocolo de janela deslizante para reconciliar o estado entre os processos pares em uma RSM.

[Figura] – Legenda: A relação entre algoritmos de consenso e máquinas de estado replicadas
Armazenamentos de dados replicados confiáveis e armazenamentos de configuração
O armazenamento de dados replicados confiáveis é uma aplicação das máquinas de estado replicadas. Os datastores replicados usam algoritmos de consenso no caminho crítico de seu trabalho. Assim, o desempenho, a taxa de transferência e a capacidade de dimensionamento são muito importantes nesse tipo de design. Assim como os armazenamentos de dados criados com outras tecnologias subjacentes, o armazenamento de dados baseado em consenso pode fornecer uma variedade de semânticas de consistência para operações de leitura, o que faz uma grande diferença no dimensionamento do armazenamento de dados. Essas compensações são discutidas mais adiante, no tópico “Desempenho de consenso distribuído”.
Outros sistemas (baseados em consenso não distribuído) geralmente dependem de carimbos de data/hora para fornecer limites sobre a idade dos dados retornados. Os carimbos de data/hora são altamente problemáticos em sistemas distribuídos porque é impossível garantir que os relógios sejam sincronizados em várias máquinas. O banco de dados Spanner aborda esse problema modelando a incerteza do pior caso envolvido e desacelerando o processamento quando necessário para resolver essa incerteza.
Processamento altamente disponível usando eleição de líder
A eleição de líder em sistemas distribuídos é um problema equivalente ao consenso distribuído. Serviços replicados que utilizam um único líder para realizar algum tipo específico de trabalho no sistema são muito comuns; o mecanismo de líder único é uma forma de garantir a exclusão mútua em um nível grosseiro.
Esse tipo de design é apropriado quando o trabalho do líder de serviço pode ser executado por um processo ou é fragmentado. Os projetistas de sistema podem construir um serviço altamente disponível escrevendo-o como se fosse um programa simples, replicando esse processo e usando a eleição do líder para garantir que apenas um líder esteja trabalhando a qualquer momento (como mostrado na figura acima). Muitas vezes, o trabalho do líder é coordenar algum grupo de colaboradores no sistema. Esse padrão foi usado no Google File System (que foi substituído pelo Colossus) e no armazenamento de valores-chave do Bigtable.
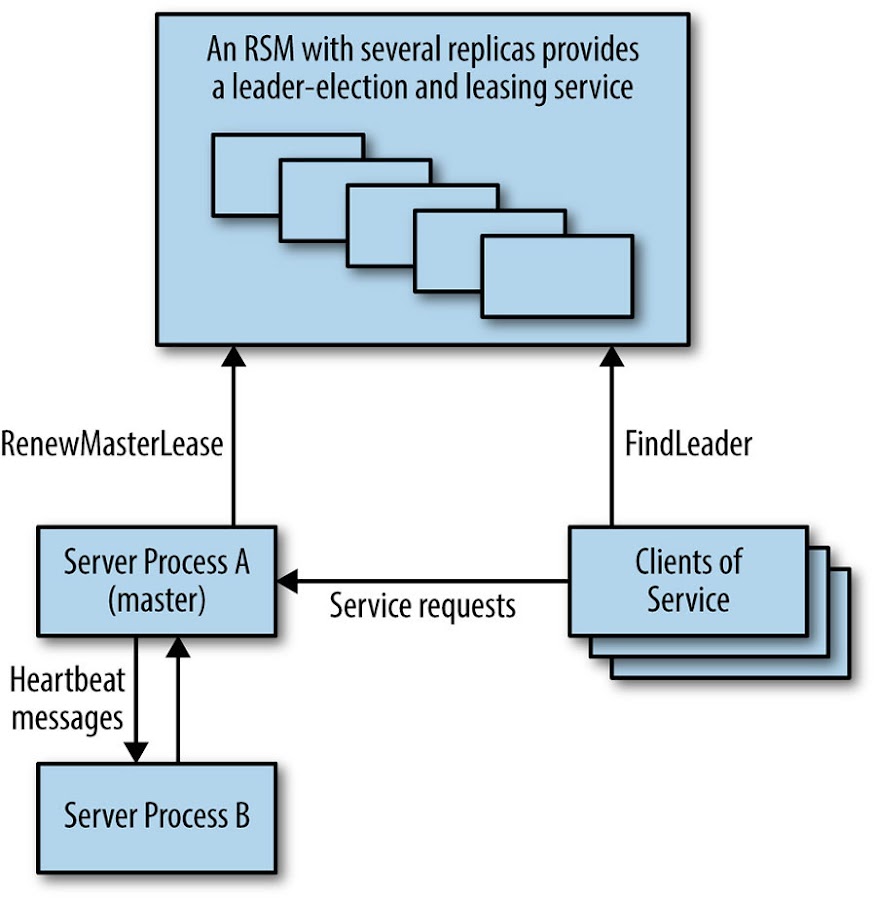
[Figura] – Legenda: A figura acima mostra um sistema altamente disponível usando um serviço replicado para eleição de mestre
Nesse tipo de componente, diferentemente do armazenamento de dados replicado, o algoritmo de consenso não está no caminho crítico do trabalho principal que o sistema está realizando, portanto, a taxa de transferência geralmente não é uma grande preocupação.
Serviços distribuídos de coordenação e bloqueio
Uma barreira em uma computação distribuída é uma primitiva que bloqueia um grupo de processos de prosseguir até que alguma condição seja atendida (por exemplo, até que todas as partes de uma fase de uma computação sejam concluídas). O uso de uma barreira divide efetivamente uma computação distribuída em fases lógicas. Por exemplo, como mostrado na figura abaixo, uma barreira pode ser usada na implementação do modelo MapReduce para garantir que toda a fase Map seja concluída antes que a parte Reduce da computação aconteça.
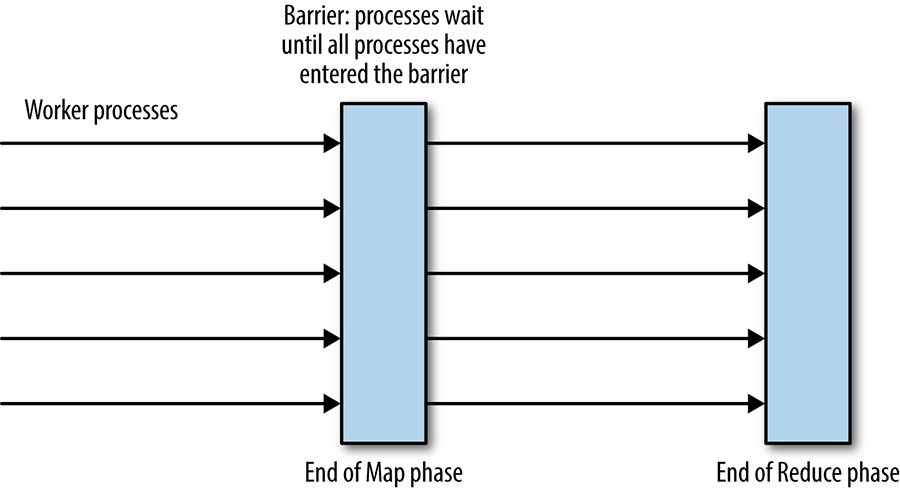
[Figura] – Legenda: Barreiras para coordenação de processos na computação MapReduce
A barreira pode ser implementada por um único processo coordenador, mas essa implementação adiciona um único ponto de falha que geralmente é inaceitável. A barreira também pode ser implementada como um RSM. O serviço de consenso Zookeeper pode implementar o padrão de barreira: veja aqui e aqui.
Os locks são outra primitiva de coordenação útil que pode ser implementada como uma RSM. Considere um sistema distribuído no qual os processos de trabalho consomem atomicamente alguns arquivos de entrada e gravam resultados. Os bloqueios distribuídos (distributed locks) podem ser usados para impedir que vários colaboradores processem o mesmo arquivo de entrada. Na prática, é essencial usar concessões renováveis com timeouts em vez de bloqueios indefinidos, pois isso evita que os bloqueios sejam mantidos indefinidamente por processos que falham. O bloqueio distribuído está além do escopo deste capítulo, mas tenha em mente que os bloqueios distribuídos são uma primitiva de sistema de baixo nível que deve ser usada com cuidado. A maioria das aplicações deve usar um sistema de nível superior que forneça transações distribuídas.
Filas e mensagens distribuídas confiáveis
As filas são uma estrutura de dados comum, geralmente usadas como forma de distribuir tarefas entre vários processos de trabalho.
Os sistemas baseados em filas podem tolerar falhas e perdas de nós de trabalho com relativa facilidade. No entanto, o sistema deve garantir que as tarefas reivindicadas sejam processadas com êxito. Para isso, recomenda-se um sistema de concessão (discutido anteriormente em relação aos bloqueios) em vez de uma remoção total da fila. A desvantagem dos sistemas baseados em filas é que a perda da fila impede que todo o sistema funcione. A implementação da fila como uma RSM pode minimizar o risco e tornar todo o sistema muito mais robusto.
O atomic broadcast é uma primitiva de sistemas distribuídos em que as mensagens são recebidas de forma confiável e na mesma ordem por todos os participantes. Este é um conceito de sistemas distribuídos incrivelmente poderoso e muito útil na concepção de sistemas práticos. Existe um grande número de infraestruturas de mensagens de publicação-assinatura para uso de designers de sistema, embora nem todas forneçam garantias atômicas. Chandra e Toueg demonstram a equivalência de transmissão atômica e consenso.
O padrão de enfileiramento como distribuição de trabalho, (queuing-as-work-distribution) que usa a fila como um dispositivo de balanceamento de carga, conforme mostrado na figura abaixo, pode ser considerado um sistema de mensagens ponto a ponto. Os sistemas de mensagens geralmente também implementam uma fila de publicação-assinatura, em que as mensagens podem ser consumidas por muitos clientes que assinam um canal ou tópico. Nesse caso de um para muitos, as mensagens na fila são armazenadas como uma lista ordenada persistente. Os sistemas de publicação-assinatura (publish-subscribe systems) podem ser usados para muitos tipos de aplicações que exigem que os clientes assinem para receber notificações de algum tipo de evento. Os sistemas de publicação-assinatura também podem ser usados para implementar caches distribuídos coerentes.
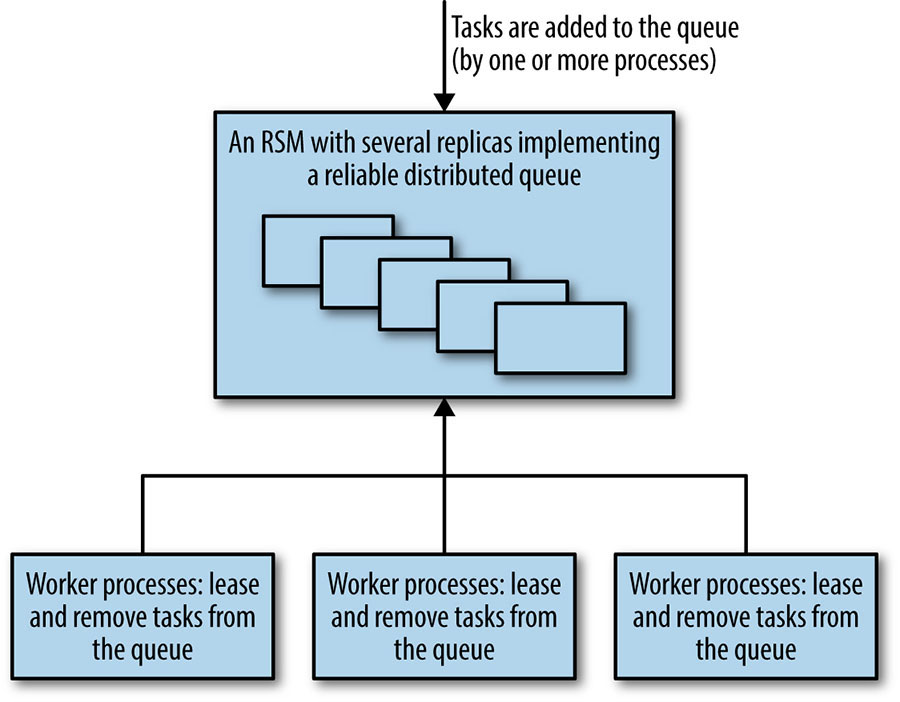
[Figura] – Legenda: Sistema de distribuição de trabalho orientado a filas usando um componente de filas baseado em consenso confiável
Os sistemas de enfileiramento e mensagens geralmente precisam de excelente taxa de transferência, mas não precisam de latência extremamente baixa (devido a raramente serem diretamente voltados para o usuário). No entanto, latências muito altas em um sistema como o que acabamos de descrever, que tem vários colaboradores solicitando tarefas de uma fila, podem se tornar um problema se a porcentagem de tempo de processamento de cada tarefa aumentar significativamente.
Desempenho de consenso distribuído
A sabedoria convencional geralmente sustenta que os algoritmos de consenso são muito lentos e caros para usar em muitos sistemas que exigem alto rendimento e baixa latência. Essa concepção simplesmente não é verdadeira – embora as implementações possam ser lentas, há vários truques que podem melhorar o desempenho. Os algoritmos de consenso distribuído estão no centro de muitos dos sistemas críticos do Google, descritos [aqui], [aqui], [aqui] e [aqui], e provaram ser extremamente eficazes na prática. A escala do Google não é uma vantagem aqui: na verdade, nossa escala é mais uma desvantagem porque apresenta dois desafios principais: nossos conjuntos de dados tendem a ser grandes e nossos sistemas funcionam em uma grande distância geográfica. Conjuntos de dados maiores multiplicados por várias replicas representam custos de computação significativos e distâncias geográficas maiores aumentam a latência entre as réplicas, o que, por sua vez, reduz o desempenho.
Não existe um consenso distribuído e algoritmo de replicação de máquina de estado “melhores” para desempenho, porque o desempenho depende de vários fatores relacionados à carga de trabalho, objetivos de desempenho do sistema e como o sistema deve ser implementado. (Em particular, o desempenho do algoritmo original do Paxos não é o ideal, mas melhorou bastante ao longo dos anos). Embora algumas das seções a seguir apresentem pesquisas, com o objetivo de aumentar a compreensão do que é possível alcançar com o consenso distribuído, muitos dos sistemas descritos estão disponíveis e estão em uso agora.
Os workloads podem variar de várias maneiras e entender como eles podem variar é fundamental para discutir o desempenho. No caso de um sistema de consenso, o workload pode variar em termos de:
- Taxa de transferência: o número de propostas feitas por unidade de tempo no pico de carga
- Tipo de requisições: proporção de operações que mudam de estado
- Semântica de consistência necessária para operações de leitura
- Tamanhos de solicitação, se o tamanho da carga útil de dados puder variar
As estratégias de deploy também variam. Por exemplo:
- A implementação é de área local ou de área ampla?
- Que tipos de quórum são usados e onde estão a maioria dos processos?
- O sistema usa sharding, pipelining e batching?
Muitos sistemas de consenso usam um processo de líder distinto e exigem que todas as requisições sejam direcionadas a esse nó especial. Como mostrado na figura abaixo, como resultado, o desempenho do sistema percebido pelos clientes em diferentes localizações geográficas pode variar consideravelmente, simplesmente porque nós mais distantes têm tempos de ida e volta mais longos para o processo líder.
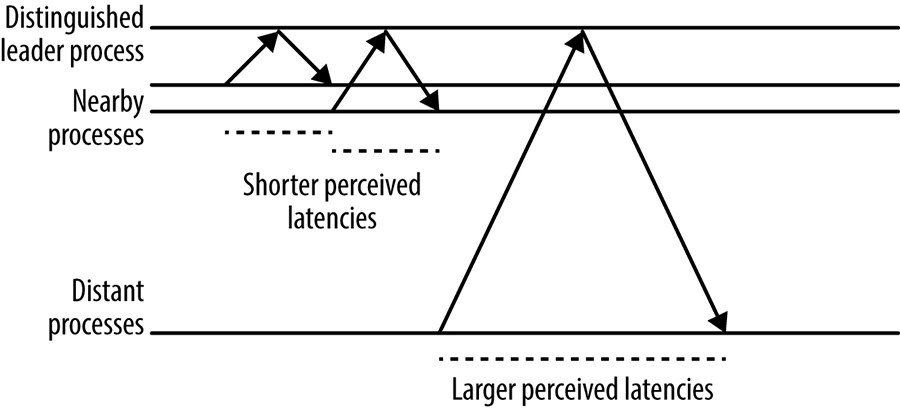
[Figura] – Legenda: O efeito da distância de um processo do servidor sobre a latência percebida no cliente
Multi-Paxos: fluxo de mensagens detalhado
O protocolo Multi-Paxos usa um processo de líder forte: a menos que um líder ainda não tenha sido eleito ou ocorra alguma falha, é necessário apenas uma viagem de ida e volta do proponente a um quórum de aceitantes para chegar a um consenso. O uso de um processo líder forte é ótimo em termos do número de mensagens a serem passadas, e é típico de muitos protocolos de consenso.
A figura abaixo mostra um estado inicial com um novo proponente executando a primeira fase Prepare/Promise do protocolo. A execução desta fase estabelece uma nova visão numerada, ou termo líder. Nas execuções subsequentes do protocolo, enquanto a visão permanece a mesma, a primeira fase é desnecessária porque o proponente que estabeleceu a visão pode simplesmente enviar mensagens de Accept, e o consenso é alcançado quando um quorum de respostas é recebido (incluindo o próprio proponente).
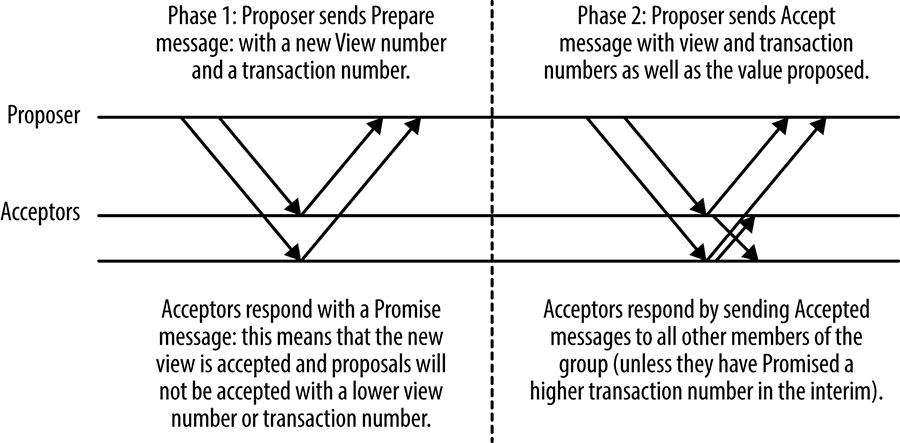
[Figura] – Legenda: Fluxo básico de mensagens Multi-Paxos
Outro processo no grupo pode assumir o papel de proponente para propor mensagens a qualquer momento, mas mudar o proponente tem um custo de desempenho. Ele exige a viagem de ida e volta extra para executar a Fase 1 do protocolo, mas, mais importante, pode causar uma situação de duelo de proponentes na qual as propostas se interrompem repetidamente e nenhuma proposta pode ser aceita, conforme mostrado na figura abaixo. Como esse cenário é uma forma de livelock – situação em que uma solicitação de bloqueio exclusivo é negada repetidamente, pois muitos bloqueios compartilhados sobrepostos continuam interferindo uns nos outros – ele pode continuar indefinidamente.
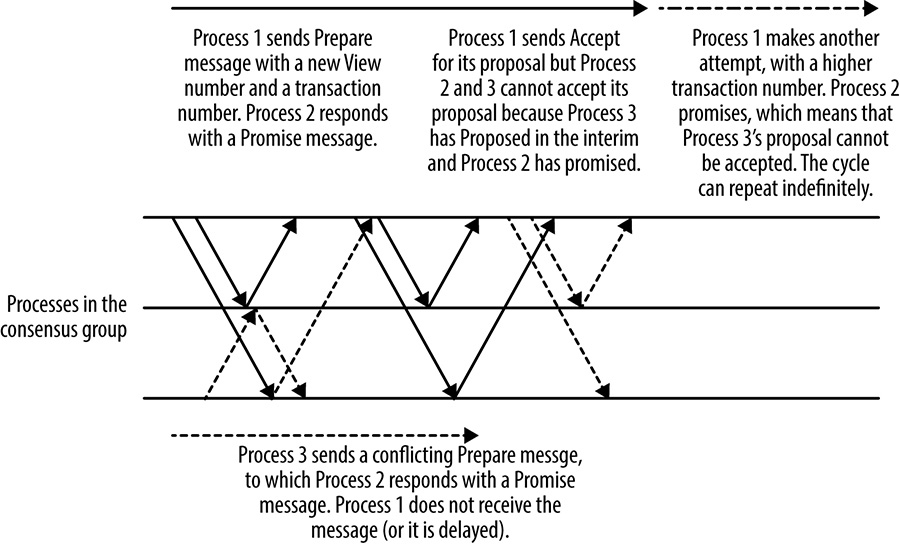
[Figura] – Legenda: Proponentes de duelo em Multi-Paxos
Todos os sistemas de consenso prático abordam essa questão de colisões, geralmente elegendo um processo proponente, que faz todas as propostas no sistema, ou usando um proponente rotativo que aloca a cada processo slots específicos para suas propostas.
Para sistemas que usam um processo de líder, o processo de eleição de líder deve ser ajustado cuidadosamente para equilibrar a indisponibilidade do sistema, que ocorre quando nenhum líder está presente com o risco de duelo de proponentes. É importante implementar os tempos limite e as estratégias de recuo corretas. Se vários processos detectarem que não há líder e todos tentarem se tornar líderes ao mesmo tempo, nenhum dos processos provavelmente terá sucesso (novamente, proponentes duelando). Neste caso, introduzir aleatoriedade é a melhor abordagem. O Raft, por exemplo, tem um método bem pensado de abordar o processo de eleição do líder.
Escalonamento de workloads de leitura pesados
O dimensionamento de workload de leitura geralmente é fundamental porque muitos workloads são de leitura pesada. O armazenamento de dados replicados tem a vantagem dos dados estarem disponíveis em vários locais, o que significa que, se uma consistência forte não for necessária para todas as leituras, os dados poderão ser lidos de qualquer replica. Essa técnica de leitura de replicas funciona bem para certas aplicações, como o sistema Photon do Google, que usa consenso distribuído para coordenar o trabalho de vários pipelines. O Photon usa uma operação atômica de comparação e definição para modificação de estado (inspirada em registros atômicos), que deve ser absolutamente consistente; mas as operações de leitura podem ser atendidas a partir de qualquer replica, porque dados obsoletos resultam em trabalho extra sendo executado, mas não em resultados incorretos. A troca vale a pena.
Para garantir que os dados que estão sendo lidos estejam atualizados e consistentes com quaisquer alterações feitas antes da execução da leitura, é necessário fazer o seguinte:
- Executar uma operação de consenso somente leitura
- Ler os dados de uma replica com garantia de ser a mais atualizada. Em um sistema que usa um processo líder estável (como fazem muitas implementações de consenso distribuído), o líder pode fornecer essa garantia
- Usar concessões de quorum, nas quais algumas replicas recebem uma concessão de todos ou parte dos dados no sistema, permitindo leituras locais fortemente consistentes ao custo de algum desempenho de escrita. Essa técnica é discutida em detalhes na seção a seguir.
Concessões de quorum
As concessões de quorum são uma otimização de desempenho de consenso distribuído recentemente desenvolvida com o objetivo de reduzir a latência e aumentar a taxa de transferência para operações de leitura. Como mencionado anteriormente, no caso do Paxos clássico e da maioria dos outros protocolos de consenso distribuído, a execução de uma leitura fortemente consistente (isto é, que garante ter a visão mais atualizada do estado) requer uma operação de consenso distribuído que lê de um quorum de replicas ou de uma replica líder estável que garante ter visto todas as operações recentes de mudança de estado. Em muitos sistemas, as operações de leitura superam amplamente as gravações, portanto, essa dependência de uma operação distribuída ou de uma única replica prejudica a latência e a taxa de transferência do sistema.
A técnica de concessão de quorum simplesmente concede uma concessão de leitura em algum subconjunto do estado do armazenamento de dados replicado para um quorum de replicas. A locação é por um período de tempo específico (geralmente breve). Qualquer operação que altere o estado desses dados deve ser reconhecida por todas as replicas no quorum de leitura. Se alguma dessas replicas ficar indisponível, os dados não poderão ser modificados até que a concessão expire.
As concessões de quorum são particularmente úteis para workloads de leitura intensa nas quais as leituras de subconjuntos específicos dos dados estão concentradas em uma única região geográfica.
Desempenho de consenso distribuído e de latência de rede
Os sistemas de consenso enfrentam duas grandes restrições físicas no desempenho ao confirmar alterações de estado. Um é o tempo de ida e volta da rede e o outro é o tempo necessário para gravar dados no armazenamento persistente, que será examinado posteriormente.
Os tempos de ida e volta da rede variam enormemente dependendo do local de origem e destino, que são afetados tanto pela distância física entre a origem e o destino quanto pela quantidade de congestionamento na rede. Em um único datacenter, os tempos de ida e volta entre as máquinas devem ser da ordem de milissegundos. Um tempo de ida e volta típico (RTT) dentro dos Estados Unidos é de 45 milissegundos e de Nova York a Londres é de 70 milissegundos.
O desempenho do sistema de consenso em uma rede local pode ser comparável ao de um sistema de replicação assíncrona líder-seguidor [asynchronous leader-follower replication system] – o mesmo que muitos bancos de dados tradicionais usam para replicação. No entanto, muitos dos benefícios de disponibilidade dos sistemas de consenso distribuído exigem que as replicas sejam “distantes” umas das outras, para estarem em diferentes domínios de falha.
Muitos sistemas de consenso usam TCP/IP como protocolo de comunicação. O TCP/IP é orientado à conexão e fornece algumas garantias de confiabilidade em relação ao sequenciamento FIFO de mensagens. No entanto, configurar uma nova conexão TCP/IP requer uma viagem de ida e volta de rede para executar o handshake de três vias que configura uma conexão antes que qualquer dado possa ser enviado ou recebido. O início lento do TCP/IP inicialmente limita a largura de banda da conexão até que seus limites sejam estabelecidos. Os tamanhos iniciais da janela TCP/IP variam de 4 KB a 15 KB.
O início lento do TCP/IP provavelmente não é um problema para os processos que formam um grupo de consenso: eles estabelecerão conexões entre si e manterão essas conexões abertas para reutilização porque estarão em comunicação frequente. No entanto, para sistemas com um número muito alto de clientes, pode não ser prático para todos os clientes manter uma conexão persistente aberta com os clusters de consenso, porque as conexões TCP/IP abertas consomem alguns recursos – por exemplo, descritores de arquivo – além de gerar tráfego de manutenção. Essa sobrecarga pode ser um problema importante para aplicativos que usam armazenamentos de dados baseados em consenso altamente fragmentados contendo milhares de replicas e um número ainda maior de clientes. Uma solução é usar um conjunto de proxies regionais, conforme mostrado na figura abaixo, que mantém conexões TCP/IP persistentes com o grupo de consenso para evitar a sobrecarga de configuração em longas distâncias. Os proxies também podem ser uma boa maneira de encapsular estratégias de fragmentação e balanceamento de carga, bem como a descoberta de membros e líderes de cluster.
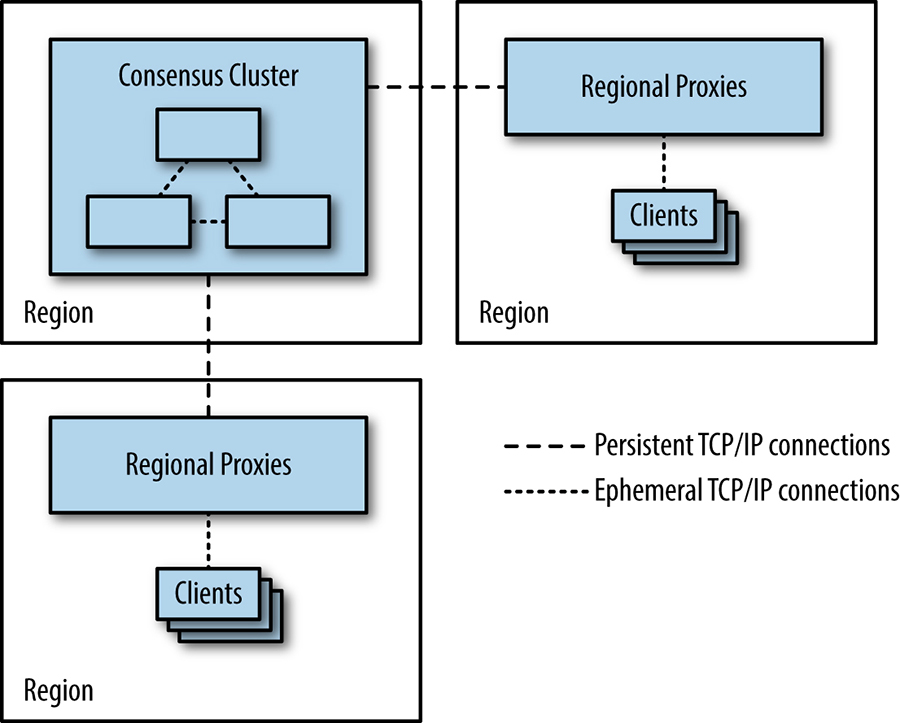
[Figura] – Legenda: Usando proxies para reduzir a necessidade de clientes abrirem conexões TCP/IP entre regiões
Raciocínio sobre o desempenho: Fast Paxos
O Fast Paxos é uma versão do algoritmo Paxos projetada para melhorar seu desempenho em redes de longa distância. Usando Fast Paxos, cada cliente pode enviar mensagens de Propose diretamente para cada membro de um grupo de aceitantes, ao invés de através de um líder, como no Classic Paxos ou Multi-Paxos. A ideia é substituir um envio de mensagem paralela do cliente para todos os aceitadores no Fast Paxos por duas operações de envio de mensagem no Classic Paxos:
- Uma mensagem do cliente para um único proponente
- Uma operação de envio de mensagem paralela do proponente para as outras replicas
Intuitivamente, parece que o Fast Paxos deve ser sempre mais rápido que o Classic Paxos. No entanto, isso não é verdade: se o cliente no sistema Fast Paxos tiver um RTT (tempo de ida e volta) alto para os aceitadores e os aceitadores tiverem conexões rápidas entre si, substituímos N mensagens paralelas nos links de rede mais lentos (no Fast Paxos) para uma mensagem no link mais lento mais N mensagens paralelas nos links mais rápidos (Classic Paxos). Devido ao efeito de cauda de latência, na maioria das vezes uma única viagem de ida e volta em um link lento com uma distribuição de latências é mais rápida que um quorum (como mostrado [aqui]) e, portanto, Fast Paxos acaba sendo mais lento que o Classic Paxos nesse caso.
Muitos sistemas agrupam várias operações em uma única transação no aceitador para aumentar o rendimento. Ter clientes atuando como proponentes também torna muito mais difícil fazer propostas em lote. A razão para isso é que as propostas chegam independentemente aos aceitantes, então você não pode agrupá-las de maneira consistente.
Líderes estáveis
Vimos como o Multi-Paxos elege um líder estável para melhorar o desempenho. O Zab e o Raft também são exemplos de protocolos que elegem um líder estável por questões de desempenho. Essa abordagem pode permitir otimizações de leitura, pois o líder possui o estado mais atualizado, mas também apresenta vários problemas:
- Todas as operações que mudam de estado devem ser enviadas por meio do líder, requisito que adiciona latência de rede para clientes que não estão localizados próximos ao líder.
- A largura de banda da rede de saída do processo líder é um gargalo do sistema, porque a mensagem Accept do líder contém todos os dados relacionados a qualquer proposta, enquanto outras mensagens contêm apenas reconhecimentos de uma transação numerada sem carga útil de dados.
- Se o líder estiver em uma máquina com problemas de desempenho, o rendimento de todo o sistema será reduzido.
Quase todos os sistemas de consenso distribuído que foram projetados com o desempenho em mente usam o padrão de líder estável único ou um sistema de liderança rotativa em que cada algoritmo de consenso distribuído numerado é pré-atribuído a uma replica (geralmente por um módulo simples do ID da transação). Algoritmos que usam essa abordagem incluem o Mencius e o Paxos Igualitário [Egalitarian Paxos].
Em uma rede de longa distância com clientes espalhados geograficamente e replicas do grupo de consenso localizadas razoavelmente perto dos clientes, essa eleição de líder leva a uma menor latência percebida para os clientes porque o RTT da sua rede para a replica mais próxima será, em média, menor que isso a um líder arbitrário.
Processamento em lote
O batching (processamento em lote), conforme descrito no tópico acima “Raciocínio sobre o desempenho: Fast Paxos”, aumenta a taxa de transferência do sistema, mas ainda deixa as replicas ociosas enquanto aguardam respostas às mensagens que enviaram. As ineficiências apresentadas pelas replicas ociosas podem ser resolvidas através do pipelining, que permite que várias propostas sejam executadas de uma só vez. Essa otimização é muito semelhante ao caso do TCP/IP, no qual o protocolo tenta “manter o canal cheio” usando uma abordagem de janela deslizante. O pipelining é normalmente usado em combinação com batching.
Os lotes de solicitações no pipeline ainda são ordenados globalmente com um número de exibição e um número de transação, portanto, esse método não viola as propriedades de ordenação global necessárias para executar uma máquina de estado replicada. Se quiser saber mais, esse método de otimização é discutido [aqui] e [aqui].
Acesso ao disco
O registro no armazenamento persistente é necessário para que um nó, tendo travado e retornado ao cluster, honre quaisquer compromissos anteriores que tenha feito em relação às transações de consenso em andamento. No protocolo Paxos, por exemplo, os aceitantes não podem concordar com uma proposta quando já concordaram com uma proposta com um número de sequência maior. Se os detalhes das propostas acordadas e confirmadas não forem registrados no armazenamento persistente, um aceitador poderá violar o protocolo se ele travar e for reiniciado, levando a um estado inconsistente.
O tempo necessário para gravar uma entrada em um log no disco varia muito dependendo de qual hardware ou ambiente virtualizado é usado, mas provavelmente levará entre um e vários milissegundos.
O fluxo de mensagens para Multi-Paxos foi discutido mais acima em “Multi-Paxos: fluxo de mensagens detalhado”, mas esse tópico não mostrou onde o protocolo deve registrar as alterações de estado no disco. Uma gravação em disco deve acontecer sempre que um processo faz um compromisso que deve honrar. Na segunda fase de desempenho crítico do Multi-Paxos, esses pontos ocorrem antes que um aceitante envie uma mensagem Accepted em resposta a uma proposta e antes que o proponente envie a mensagem Accept, porque essa mensagem Accept também é uma mensagem Accepted implícita.
Isso significa que a latência para uma única operação de consenso envolve o seguinte:
- Uma gravação de disco no proponente
- Mensagens paralelas para os aceitadores
- Gravações de disco paralelas nos aceitadores
- As mensagens de retorno
Existe uma versão do protocolo Multi-Paxos que é útil para casos em que o tempo de gravação do disco domina: essa variante não considera a mensagem Accept do proponente como uma mensagem Accepted implícita. Em vez disso, o proponente grava no disco em paralelo com os outros processos e envia uma mensagem Accept explícita. A latência torna-se então proporcional ao tempo necessário para enviar duas mensagens e para que um quorum de processos execute uma gravação síncrona no disco em paralelo.
Se a latência para executar uma pequena gravação aleatória no disco for da ordem de 10 milissegundos, a taxa de operações de consenso será limitada a aproximadamente 100 por segundo. Esses tempos assumem que os tempos de ida e volta da rede são desprezíveis e o proponente realiza seu log em paralelo com os aceitadores.
Como já vimos, algoritmos de consenso distribuído são frequentemente usados como base para construir uma máquina de estado replicada. As RSMs também precisam manter logs de transações para fins de recuperação (pelos mesmos motivos que qualquer armazenamento de dados). O log do algoritmo de consenso e o log de transações da RSM podem ser combinados em um único log. A combinação desses logs evita a necessidade de alternar constantemente entre a gravação em dois locais físicos diferentes no disco, reduzindo o tempo gasto nas operações de busca. Os discos podem sustentar mais operações por segundo e, portanto, o sistema como um todo pode realizar mais transações.
Em um armazenamento de dados, os discos têm outras finalidades além da manutenção de logs: o estado do sistema geralmente é mantido no disco. As gravações de log devem ser descarregadas diretamente no disco, mas as gravações para alterações de estado podem ser gravadas em um cache de memória e descarregadas no disco posteriormente, reordenadas para usar o agendamento mais eficiente [Bol11].
Outra otimização possível é agrupar várias operações do cliente em uma operação no proponente (saiba mais [aqui], [aqui], [aqui], [aqui], [aqui] e [aqui]). Isso amortiza os custos fixos do log em disco e a latência da rede no maior número de operações, aumentando a taxa de transferência.
Deploy de sistemas distribuídos baseados em consenso
As decisões mais críticas que os designers de sistemas devem tomar ao fazer o deploy de um sistema baseado em consenso dizem respeito ao número de replicas a serem implementadas e à localização dessas replicas.
Número de replicas
Em geral, os sistemas baseados em consenso operam usando quorums majoritários, ou seja, um grupo de 2f + 1 replicas pode tolerar f falhas (se for necessária tolerância a falhas bizantina, na qual o sistema é resistente a réplicas que retornam resultados incorretos, então 3f + 1 replicas podem tolerar f falhas. Para falhas não bizantinas, o número mínimo de replicas que podem ser implementadas é três — se duas forem implementadas, não haverá tolerância à falha de nenhum processo. Três replicas podem tolerar uma falha. A maior parte do tempo de inatividade do sistema é resultado da manutenção planejada: três replicas permitem que um sistema opere normalmente quando uma replica estiver inativa para manutenção (assumindo que as duas replicas restantes possam lidar com a carga do sistema com um desempenho aceitável).
Se ocorrer uma falha não planejada durante uma janela de manutenção, o sistema de consenso ficará indisponível. A indisponibilidade do sistema de consenso geralmente é inaceitável e, portanto, cinco replicas devem ser executadas, permitindo que o sistema opere com até duas falhas. Nenhuma intervenção é obrigatoriamente necessária se quatro das cinco replicas em um sistema de consenso permanecerem, mas se três forem deixadas, uma ou duas replicas adicionais devem ser adicionadas.
Se um sistema de consenso perde tantas de suas replicas que não pode formar um quórum, então esse sistema está, em teoria, em um estado irrecuperável porque os logs duráveis de pelo menos uma das replicas ausentes não podem ser acessadas. Se não houver quórum, é possível que tenha sido tomada uma decisão que foi vista apenas pelas replicas ausentes. Os administradores podem forçar uma alteração na associação do grupo e adicionar novas replicas que se igualam à existente para prosseguir, mas a possibilidade de perda de dados sempre permanece – uma situação que deve ser evitada, se possível.
Em um desastre, os administradores precisam decidir se devem executar uma reconfiguração tão forçada ou aguardar algum período de tempo para que as máquinas com estado do sistema fiquem disponíveis. Quando tais decisões estão sendo tomadas, o tratamento do log do sistema (além do monitoramento) torna-se crítico. Artigos teóricos geralmente apontam que o consenso pode ser usado para construir um log replicado, mas não discutem como lidar com replicas que podem falhar e se recuperar (e, portanto, perder alguma sequência de decisões de consenso) ou atrasar devido à lentidão. Para manter a robustez do sistema, é importante que essas replicas sejam atualizadas.
O log replicado (replicated log) nem sempre é um cidadão de primeira classe na teoria do consenso distribuído, mas é um aspecto muito importante dos sistemas de produção. O Raft descreve um método para gerenciar a consistência de logs replicados, definindo explicitamente como quaisquer lacunas no log de uma réplica são preenchidas. Se um sistema Raft de cinco instâncias perder todos os seus membros, exceto seu líder, o líder ainda terá total conhecimento de todas as decisões comprometidas. Por outro lado, se a maioria ausente dos membros incluía o líder, não há garantias fortes sobre a atualização das replicas restantes.
Existe uma relação entre o desempenho e o número de replicas em um sistema que não precisam fazer parte de um quorum: uma minoria de replicas mais lentas pode ficar para trás, permitindo que o quorum de replicas de melhor desempenho seja executado mais rapidamente (desde que o líder tenha um bom desempenho). Se o desempenho da replica variar significativamente, cada falha poderá reduzir o desempenho geral do sistema, pois os valores discrepantes lentos serão necessários para formar um quorum. Quanto mais falhas ou replicas atrasadas um sistema puder tolerar, melhor será o desempenho geral do sistema.
A questão do custo também deve ser considerada no gerenciamento de replicas: cada replica usa recursos de computação dispendiosos. Se o sistema em questão for um único cluster de processos, o custo de execução de replicas provavelmente não será uma grande consideração. No entanto, o custo das replicas pode ser uma consideração séria para sistemas como o Photon, que usa uma configuração shard na qual cada shard é um grupo completo de processos executando um algoritmo de consenso. À medida que o número de shards cresce, o mesmo acontece com o custo de cada replica adicional, porque um número de processos igual ao número de shards deve ser adicionado ao sistema.
A decisão sobre o número de replicas para qualquer sistema é, portanto, uma compensação entre os seguintes fatores:
- A necessidade de confiabilidade
- A frequência de manutenção planejada que afeta o sistema
- O risco envolvido
- Desempenho
- Custo
Esse cálculo será diferente para cada sistema: os sistemas têm objetivos de nível de serviço diferentes para disponibilidade; algumas organizações realizam manutenção com mais regularidade do que outras; e organizações usam hardware de custo, qualidade e confiabilidade variados.
Localização das replicas
As decisões sobre onde fazer o deploy dos processos que compõem um cluster de consenso são tomadas com base em dois fatores: 1) compensação entre os domínios de falha que o sistema deve manipular e 2) os requisitos de latência para o sistema. Vários problemas complexos estão em jogo ao decidir onde posicionar as replicas.
Um domínio de falha é o conjunto de componentes de um sistema que pode ficar indisponível como resultado de uma única falha. Exemplos de domínios de falha incluem:
- Uma máquina física
- Um rack em um datacenter servido por uma única fonte de alimentação
- Vários racks em um datacenter que são atendidos por um equipamento de rede
- Um datacenter que pode ficar indisponível por um corte de cabo de fibra ótica
- Um conjunto de datacenters em uma única área geográfica que pode ser afetado por um único desastre natural, como um furacão
Em geral, à medida que a distância entre as replicas aumenta, também aumenta o tempo de ida e volta entre elas, bem como o tamanho da falha que o sistema poderá tolerar. Para a maioria dos sistemas de consenso, aumentar o tempo de ida e volta entre as replicas também aumentará a latência das operações.
A extensão em que a latência é importante, bem como a capacidade de sobreviver a uma falha em um domínio específico, depende muito do sistema. Algumas arquiteturas de sistema de consenso não exigem taxa de transferência particularmente alta ou baixa latência: por exemplo, um sistema de consenso que existe para fornecer serviços de associação de grupo e eleição de líder para um serviço altamente disponível provavelmente não está muito carregado e, se a transação de consenso tempo é apenas uma fração do tempo de concessão do líder, seu desempenho não é crítico. Os sistemas orientados a lotes (batch-oriented) também são menos afetados pela latência: os tamanhos dos lotes de operação podem ser aumentados para aumentar também o rendimento.
Nem sempre faz sentido aumentar continuamente o tamanho do domínio de falha cuja perda o sistema pode suportar. Por exemplo, se todos os clientes que usam um sistema de consenso estiverem executando em um domínio de falha específico (digamos, a área de Nova York) e o deploy de um sistema baseado em consenso distribuído em uma área geográfica mais ampla permitiria que ele continuasse atendendo durante interrupções nesse domínio de falha (digamos, com o furacão Sandy passando), valeria a pena? Provavelmente não, porque os clientes do sistema também estarão inativos, então o sistema não verá tráfego. O custo extra em termos de latência, taxa de transferência e recursos de computação não traria nenhum benefício.
Você deve levar em consideração a recuperação de desastres ao decidir onde localizar suas replicas: em um sistema que armazena dados críticos, as replicas de consenso também são essencialmente cópias online dos dados do sistema. No entanto, quando dados críticos estão em jogo, é importante fazer backup de snapshots regulares em outros lugares, mesmo no caso de sistemas sólidos baseados em consenso que são implementados em diversos domínios de falha. Existem dois domínios de falha os quais você nunca poderá escapar: 1) o próprio software e 2) erro humano por parte dos administradores do sistema. Bugs no software podem surgir em circunstâncias incomuns e causar perda de dados, enquanto a configuração incorreta do sistema pode ter efeitos semelhantes. Operadores humanos também podem errar ou realizar algum tipo de sabotagem que irá ocasionar a perda de dados.
Ao tomar decisões sobre a localização de replicas, lembre-se de que a medida mais importante de desempenho é a percepção do cliente: idealmente, o tempo de ida e volta da rede dos clientes até as réplicas do sistema de consenso deve ser minimizado. Em uma rede de longa distância, protocolos sem líder como o Mencius ou o Egalitarian Paxos podem ter uma vantagem de desempenho, principalmente se as restrições de consistência da aplicação significarem que é possível executar operações somente leitura em qualquer replica do sistema sem realizar uma operação de consenso.
Capacidade e balanceamento de carga
Ao projetar um deploy, você deve verificar se há capacidade suficiente para lidar com a carga. No caso de sharded deployments, você pode ajustar a capacidade ajustando o número de shards. No entanto, para sistemas que podem ler de membros do grupo de consenso que não são o líder, você pode aumentar a capacidade de leitura adicionando mais replicas. Adicionar mais replicas, contudo, tem um custo: em um algoritmo que usa um líder forte, adicionar replicas impõe mais carga ao processo líder, enquanto em um protocolo peer-to-peer, adicionar replicas impõe mais carga a todos os processos. No entanto, se houver ampla capacidade para operações de escrita, onde um workload pesado de leitura estiver sobrecarregando o sistema, adicionar replicas pode ser a melhor abordagem.
Deve-se observar que adicionar uma replica em um sistema de quorum majoritário pode diminuir um pouco a disponibilidade do sistema (como mostrado na figura abaixo). Um deploy típico para Zookeeper ou Chubby usa cinco replicas, portanto, um quorum majoritário requer três replicas. O sistema continuará progredindo se duas replicas, ou 40%, estiverem indisponíveis. Com seis replicas, um quorum requer quatro replicas: apenas 33% das replicas podem ficar indisponíveis se o sistema permanecer ativo.
Considerações sobre domínios de falha, portanto, se aplicam ainda mais fortemente quando uma sexta replica é adicionada: se uma organização tem cinco datacenters e geralmente executa grupos de consenso com cinco processos, um em cada datacenter, a perda de um datacenter ainda deixa uma replica de reserva em cada grupo. Se uma sexta replica for implementada em um dos cinco datacenters, uma interrupção nesse datacenter removerá ambas as replicas de reserva do grupo, reduzindo assim a capacidade em 33%.
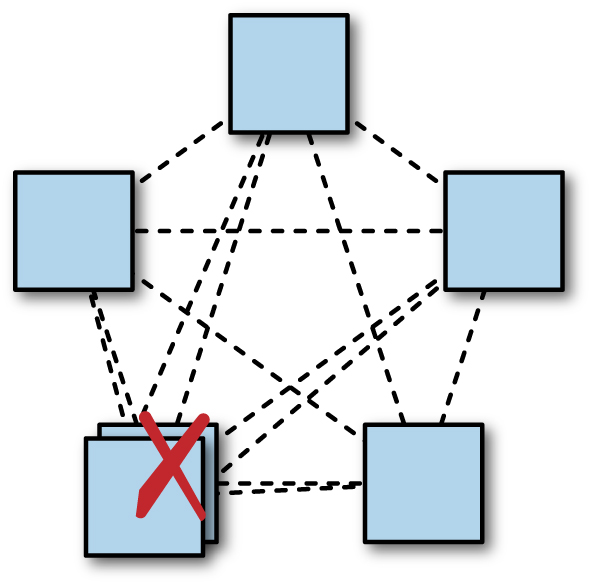
[Figura] – Legenda: Adicionar uma replica extra em uma região pode reduzir a disponibilidade do sistema. Colocar várias replicas em um único datacenter pode reduzir a disponibilidade do sistema: aqui, há um quorum sem qualquer redundância restante.
Se os clientes forem densos para uma determinada região geográfica, é melhor localizar replicas próximas a eles. No entanto, decidir onde exatamente localizar as replicas pode exigir uma reflexão cuidadosa sobre o balanceamento de carga e como um sistema lida com a sobrecarga. Conforme mostrado na figura abaixo, se um sistema simplesmente rotear solicitações de leitura do cliente para a replica mais próxima, um grande pico de carga concentrado em uma região pode sobrecarregar a replica mais próxima e, em seguida, a replica seguinte e assim por diante – esta é uma falha em cascata (consulte o Capítulo 22 para mais detalhes sobre falhas em cascata). Esse tipo de sobrecarga geralmente pode ocorrer como resultado do início de trabalhos em lote, especialmente se vários começarem ao mesmo tempo.
Já vimos o motivo pelo qual muitos sistemas de consenso distribuído usam um processo líder para melhorar o desempenho. No entanto, é importante entender que as replicas líderes usarão mais recursos computacionais, principalmente a capacidade da rede de saída. Isso ocorre porque o líder envia mensagens de proposta que incluem os dados propostos, mas as replicas enviam mensagens menores, geralmente contendo apenas a concordância com um determinado ID de transação de consenso. As organizações que executam sistemas de consenso altamente fragmentados com um número muito grande de processos podem achar necessário garantir que os processos líderes para os diferentes shards sejam equilibrados de maneira relativamente uniforme em diferentes datacenters. Isso evita que o sistema como um todo tenha gargalos na capacidade da rede de saída para apenas um datacenter e aumenta a capacidade geral do sistema.
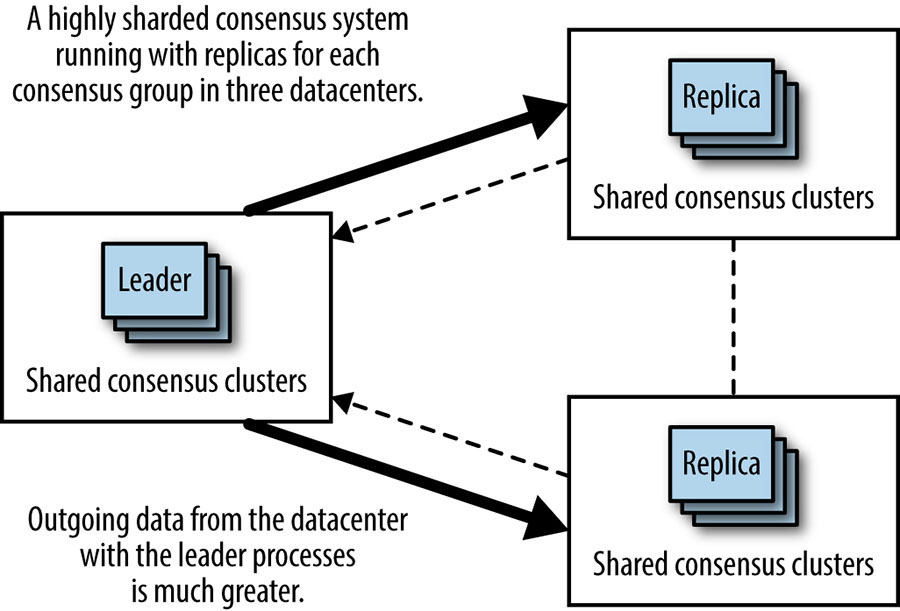
[Figura] – Legenda: Colocação de processos líderes levam ao uso desigual de largura de banda
Outra desvantagem do deploy de grupos de consenso em vários datacenters (mostrado na figura acima) é a mudança muito extrema no sistema, que pode ocorrer se o datacenter que hospeda os líderes sofrer uma falha generalizada (de energia, falha de equipamento de rede ou corte de fibra, por exemplo). Conforme mostra a figura abaixo, nesse cenário de falha, todos os líderes devem fazer failover para outro datacenter, divididos igualmente ou em massa em um datacenter. Em ambos os casos, o link entre os outros dois datacenters receberá de repente muito mais tráfego de rede desse sistema. Este seria um momento inoportuno para descobrir que a capacidade naquele link é insuficiente.
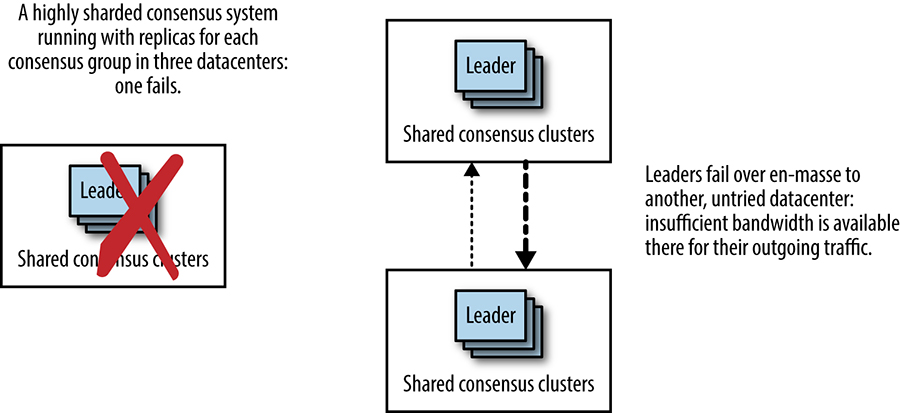
[Figura] – Legenda: Quando os líderes colocalizados fazem failover em massa, os padrões de uso da rede mudam drasticamente
No entanto, esse tipo de deploy pode facilmente ser um resultado não intencional de processos automáticos no sistema que influenciam a forma como os líderes são escolhidos. Por exemplo:
- Os clientes experimentarão melhor latência para qualquer operação realizada por meio do líder se o líder estiver localizado mais próximo deles. Um algoritmo que tenta localizar líderes próximos da maioria dos clientes pode tirar proveito dessa abordagem.
- Um algoritmo pode tentar localizar líderes em máquinas com melhor desempenho. Uma armadilha dessa abordagem é que, se um dos três datacenters abrigar máquinas mais rápidas, uma quantidade desproporcional de tráfego será enviada para esse datacenter, resultando em alterações extremas de tráfego caso esse datacenter fique offline. Para evitar esse problema, o algoritmo também deve levar em consideração o equilíbrio de distribuição em relação aos recursos de cada máquina ao selecioná-las.
Um algoritmo líder de eleição pode favorecer processos que estão em execução há mais tempo. Os processos de execução mais longos provavelmente estarão correlacionados com a localização se as versões de software forem executadas por datacenter.
Composição do quorum
Ao determinar onde localizar replicas em um grupo de consenso, é importante considerar o efeito da distribuição geográfica (ou, mais precisamente, as latências de rede entre as replicas) no desempenho do grupo.
Uma abordagem é distribuir as replicas o mais uniformemente possível, com RTTs semelhantes entre todas elas. Todos os outros fatores sendo iguais (como workload, hardware e desempenho de rede), esse arranjo deve levar a um desempenho bastante consistente em todas as regiões, independentemente de onde o líder do grupo esteja localizado (ou para cada membro do grupo de consenso, se um líder sem protocolo estiver em uso).
A geografia pode complicar muito essa abordagem. Isto é particularmente verdadeiro para tráfego intracontinental versus tráfego transpacífico e transatlântico. Considere um sistema que abrange a América do Norte e a Europa: é impossível localizar replicas equidistantes umas das outras porque sempre haverá um atraso maior para o tráfego transatlântico do que para o tráfego intracontinental. Não importa o que aconteça, as transações de uma região precisarão fazer uma viagem transatlântica de ida e volta para chegar a um consenso.
No entanto, conforme mostra a figura abaixo, para tentar distribuir o tráfego da maneira mais uniforme possível, os designers de sistemas podem optar por localizar cinco replicas, com duas replicas situadas aproximadamente no centro dos EUA, uma na costa leste e duas na Europa. Tal distribuição significaria que, na média, o consenso poderia ser alcançado na América do Norte sem esperar por respostas da Europa, ou que, da Europa, o consenso pode ser alcançado trocando mensagens apenas com a replica da costa leste. A replica da costa leste atua como uma espécie de eixo, onde dois quóruns possíveis se sobrepõem.
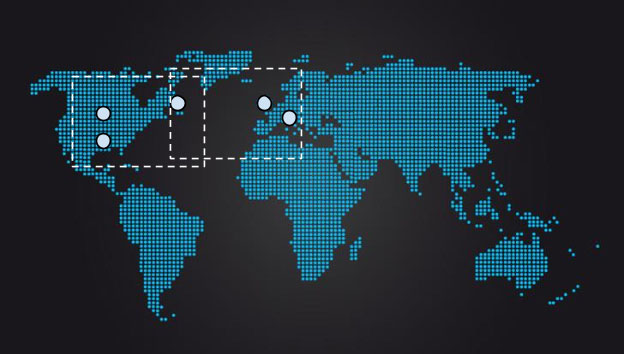
[Figura] – Legenda: Sobreposição de quoruns com uma replica atuando como link
Conforme mostra a figura abaixo, a perda dessa replica significa que a latência do sistema provavelmente mudará drasticamente: em vez de ser amplamente influenciada pelo RTT central dos EUA para a costa leste ou RTT da UE para a costa leste, a latência será baseada na UE para o centro RTT, que é cerca de 50% superior ao RTT da costa leste da UE. A distância geográfica e o RTT da rede entre o quorum mais próximo possível aumenta enormemente.
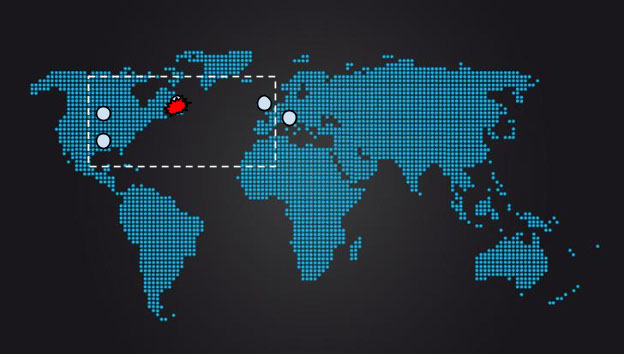
[Figura] – Legenda: A perda da replica do link leva imediatamente a um RTT mais longo para qualquer quorum
Esse cenário é um ponto fraco importante do quorum de maioria simples quando aplicado a grupos compostos de replicas com RTTs muito diferentes entre os membros. Nesses casos, uma abordagem de quorum hierárquico pode ser útil. Conforme diagramado na figura abaixo, nove replicas podem ser implementadas em três grupos de três. Um quorum pode ser formado pela maioria dos grupos, e um grupo pode ser incluído no quorum se a maioria dos membros do grupo estiver disponível. Isso significa que uma replica pode ser perdida no grupo central sem causar um grande impacto no desempenho geral do sistema porque o grupo central ainda pode votar em transações com duas de suas três replicas.
Há, no entanto, um custo de recurso associado à execução de um número maior de replicas. Em um sistema com alto nível de sharding, e com um workload de leitura pesada que é amplamente preenchível por replicas, podemos mitigar esse custo usando menos grupos de consenso. Tal estratégia significa que o número total de processos no sistema pode não mudar.
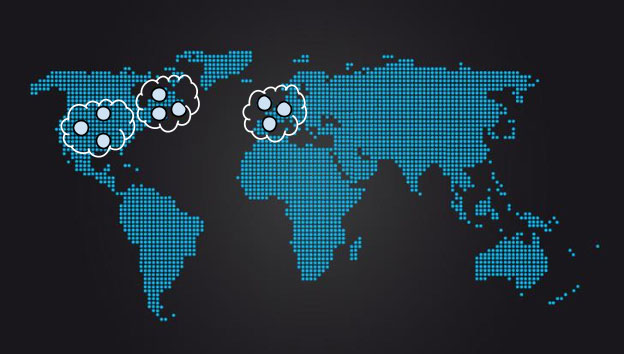
[Figura] – Legenda: Quoruns hierárquicos podem ser usados para reduzir a dependência da replica central
Monitoramento de sistemas de consenso distribuídos
Como já vimos, os algoritmos de consenso distribuído estão no centro de muitos dos sistemas críticos do Google ([aqui], [aqui], [aqui], e [aqui]). Todos os sistemas de produção importantes precisam de monitoramento para detectar interrupções ou problemas e para solucionar problemas. A experiência nos mostrou que existem certos aspectos específicos dos sistemas de consenso distribuído que merecem atenção especial.
São os seguintes:
O número de membros em execução em cada grupo de consenso e o status de cada processo (saudável ou não)
Um processo pode estar em execução, mas incapaz de progredir por algum motivo (por exemplo, algo relacionado ao hardware).
Replicas com atraso persistente
Membros saudáveis de um grupo de consenso ainda podem estar em vários estados diferentes. Um membro do grupo pode estar recuperando o estado dos pares após a inicialização ou atrasado em relação ao quorum do grupo, ou pode estar atualizado e participando totalmente, e pode ser o líder.
Se existe ou não um líder
Um sistema baseado em um algoritmo como o Multi-Paxos que usa um papel de líder deve ser monitorado para garantir que exista um líder, pois se o sistema não tiver líder, ele estará totalmente indisponível.
Número de mudanças de líder
Mudanças rápidas de liderança prejudicam o desempenho de sistemas de consenso que usam um líder estável, portanto, o número de mudanças de líder deve ser monitorado. Os algoritmos de consenso geralmente marcam uma mudança de liderança com um novo termo ou número de visualização, portanto, esse número fornece uma métrica útil para monitorar. Um aumento muito rápido nas mudanças de líder sinaliza que o líder está oscilando, talvez devido a problemas de conectividade de rede. Uma diminuição no número de visualizações pode sinalizar um bug sério.
Número de transação de consenso
Os operadores precisam saber se o sistema de consenso está progredindo ou não. A maioria dos algoritmos de consenso usa um número de transação de consenso crescente para indicar o progresso. Esse número deve aumentar ao longo do tempo se um sistema estiver saudável.
Número de propostas vistas; número de propostas acordadas
Esses números indicam se o sistema está funcionando corretamente ou não.
Taxa de transferência e latência
Embora não sejam específicas para sistemas de consenso distribuído, essas características de seu sistema de consenso devem ser monitoradas e compreendidas pelos seus administradores.
Para entender o desempenho do sistema e ajudar a solucionar problemas de desempenho, você também pode monitorar:
- Distribuições de latência para aceitação de propostas
- Distribuições de latências de rede observadas entre partes do sistema em diferentes locais
- A quantidade de tempo que os aceitadores gastam no logging durável
- Bytes gerais aceitos por segundo no sistema
Conclusão
Neste capítulo, exploramos a definição do problema de consenso distribuído e apresentamos alguns padrões de arquitetura para sistemas baseados em consenso distribuído, bem como examinamos as características de desempenho e algumas das preocupações operacionais em torno de sistemas baseados em consenso distribuído.
Deliberadamente evitamos uma discussão aprofundada sobre algoritmos, protocolos ou implementações específicas neste capítulo. Os sistemas de coordenação distribuídos e as tecnologias subjacentes a eles estão evoluindo rapidamente, e essas informações também se tornariam desatualizadas muito rápido, ao contrário dos fundamentos discutidos aqui. No entanto, esses fundamentos, juntamente com os artigos mencionados ao longo deste capítulo, permitirão que você use as ferramentas de coordenação distribuídas disponíveis hoje, bem como softwares futuros.
Se você não se lembrar de mais nada deste capítulo, tenha em mente os tipos de problemas que o consenso distribuído pode resolver, bem como os tipos de problemas que podem surgir quando métodos ad hoc, como HeartBeats, são usados em lugar do consenso distribuído. Sempre que você observar a eleição de um líder, estado compartilhado crítico ou bloqueio distribuído, pense no consenso distribuído: qualquer abordagem menor é uma bomba-relógio esperando para explodir em seus sistemas.
Fonte: Google SRE Book