Escrito por Štěpán Davidovič
Editado por Kavita Guliani
Este capítulo descreve a implementação do Google de um serviço cron distribuído que atende a vasta maioria das equipes internas que precisam de agendamento periódico de trabalhos de computação. Ao longo da existência do cron, aprendemos muitas lições sobre como projetar e implementar o que pode parecer um serviço básico. Aqui, discutimos os problemas que os crons distribuídos enfrentam e descrevemos algumas soluções potenciais.
Cron é um utilitário comum do Unix projetado para lançar periodicamente trabalhos arbitrários em horários ou intervalos definidos pelo usuário. Primeiro analisamos os princípios básicos do cron e suas implementações mais comuns e, em seguida, revisamos como um aplicativo como o cron pode funcionar em um ambiente grande e distribuído para aumentar a confiabilidade do sistema contra falhas em uma única máquina. Descrevemos um sistema cron distribuído que é implantado em um pequeno número de máquinas, mas pode iniciar cron jobs em um datacenter inteiro em conjunto com um sistema de agendamento de datacenter como o Borg.
Cron
Vamos discutir como o cron é normalmente usado, no caso de uma única máquina, antes de começar a executá-lo como um serviço entre datacenters.
Introdução
O Cron foi projetado para que os administradores do sistema e os usuários comuns do sistema possam especificar comandos para serem executados e quando esses comandos são executados. O cron executa vários tipos de trabalhos, incluindo recolha de lixo e análise periódica de dados. O formato de especificação de tempo mais comum é chamado de “crontab”. Este formato suporta intervalos simples (por exemplo, “uma vez por dia ao meio-dia” ou “em uma hora específica”). Intervalos complexos, como “todos os sábados, que é o 30º dia do mês”, também podem ser configurados.
O cron é geralmente implementado usando um único componente, que é comumente referido como crond. crond é um “daemon” que carrega a lista de cron jobs programados. Os trabalhos são lançados de acordo com seus tempos de execução especificados.
Perspectiva de confiabilidade
Vários aspectos do serviço cron são notáveis do ponto de vista da confiabilidade:
- O domínio de falha do cron é essencialmente apenas uma máquina. Se a máquina não estiver em execução, nem o agendador cron nem os trabalhos que ele inicia podem ser executados. Considere um caso distribuído muito simples com duas máquinas, no qual seu agendador cron inicia trabalhos em uma máquina de trabalho diferente (por exemplo, usando SSH). Este cenário apresenta dois domínios de falha distintos que podem afetar nossa capacidade de iniciar trabalhos: a máquina do agendador ou a máquina de destino pode falhar.
- O único estado que precisa persistir nas reinicializações do crond (incluindo reinicializações da máquina) é a própria configuração do crontab. Os lançamentos do cron são disparados e esquecidos, e o crond não faz nenhuma tentativa de rastrear esses lançamentos.
- Anacron é uma exceção notável. O anacron tenta iniciar trabalhos que seriam lançados quando o sistema estivesse inoperante. As tentativas de reinicialização são limitadas a trabalhos executados diariamente ou com menos frequência. Essa funcionalidade é muito útil para executar tarefas de manutenção em estações de trabalho e notebooks e é facilitada por um arquivo que retém o registro de data/hora da última inicialização para todos os cron jobs registrados.
Cron jobs e idempotência
Os cron jobs são concebidos para realizar trabalhos periódicos, mas para além disso, é difícil saber antecipadamente que funções têm. A variedade de requisitos que o conjunto diversificado de cron jobs inclui obviamente impacta nos requisitos de confiabilidade.
Alguns cron jobs, tais como processos de recolha de lixo, são idempotentes. Em caso de mau funcionamento do sistema, é seguro lançar esses trabalhos várias vezes. Outros cron jobs, tais como um processo que envia boletins informativos por e-mail para uma ampla distribuição, não devem ser lançados mais do que uma vez.
Para tornar as coisas mais complicadas, o não lançamento é aceitável para alguns cron jobs, mas não para outros. Por exemplo, um cron job de recolha de lixo programado para funcionar a cada cinco minutos pode ser capaz de pular um lançamento, mas um cron job de folha de pagamento programado para funcionar uma vez por mês não deve ser pulado.
Esta grande variedade de cron jobs torna difícil o raciocínio sobre os modos de falha: num sistema como o serviço cron, não há uma resposta única que se adapte a cada situação. Em geral, preferimos pular lançamentos em vez de arriscar lançamento duplo, tanto quanto a infraestrutura permite. Isto é porque a recuperação de um lançamento pulado é mais viável do que a recuperação de um lançamento duplo. Os donos de cron jobs podem (e devem!) monitorizar os seus cron jobs; por exemplo, um proprietário pode ter o serviço cron expondo o estado para os seus cron jobs gerenciados, ou criar um controle independente do efeito dos cron jobs. No caso de um lançamento pulado, os donos de um cron job podem tomar medidas que correspondam adequadamente à natureza do trabalho do cron job. No entanto, desfazer um lançamento duplo, como o exemplo do boletim informativo por e-mail anteriormente mencionado, pode ser difícil ou mesmo totalmente impossível. Portanto, preferimos “fail closed” para evitar criar sistemicamente um mau estado.
Cron em larga escala
Mover-se de máquinas únicas para implantações em larga escala requer uma reflexão fundamental de como fazer o cron funcionar em tal ambiente. Antes de apresentarmos os detalhes da solução cron do Google, discutiremos essas diferenças entre a implantação em pequena escala e em larga escala, e descreveremos quais mudanças de design as implantações em grande escala necessitam.
Infraestrutura estendida
Nas suas implementações “regulares”, o cron está limitado a uma única máquina. As implementações em grande escala do sistema estendem a nossa solução cron a várias máquinas.
Hospedar o seu serviço cron numa única máquina pode ser catastrófico em termos de confiabilidade. Suponha que esta máquina está localizada em um datacenter com exatamente 1.000 máquinas. Uma falha de apenas 1/1000º das suas máquinas disponíveis poderia derrubar todo o serviço cron. Por razões óbvias, esta implementação não é aceitável.
Para aumentar a confiabilidade do cron, desacoplamos os processos das máquinas. Se quiser executar um serviço, basta especificar os requisitos do serviço e em que datacenter deve funcionar. O sistema de programação do datacenter (que por si só deve ser confiável) determina a máquina ou as máquinas em que deve ser implementado o seu serviço, além de tratar das mortes de máquinas. O lançamento de um trabalho num datacenter transforma-se então efetivamente no envio de um ou mais RPCs para o agendador do datacenter.
Este processo não é, contudo, instantâneo. Descobrir uma máquina morta implica a realização de checkouts de saúde, enquanto a reprogramação do seu serviço para uma máquina diferente requer tempo para instalar software e iniciar o novo processo.
Uma vez que mover um processo para uma máquina diferente pode significar a perda de qualquer estado local armazenado na máquina antiga (a menos que seja utilizada migração ao vivo), e o tempo de reprogramação pode exceder o menor intervalo de programação de um minuto, precisamos de procedimentos em vigor para mitigar tanto a perda de dados como os requisitos excessivos de tempo. Para manter o estado local da máquina antiga, pode-se simplesmente persistir o estado num sistema de ficheiros distribuído como o GFS, e utilizar este sistema de ficheiros durante o arranque para identificar trabalhos que não foram lançados devido à reprogramação. No entanto, esta solução fica aquém das expectativas em termos de pontualidade: se executar um cron job a cada cinco minutos, um atraso de um a dois minutos causado pelo custo total da reprogramação do sistema cron é potencialmente inaceitável. Neste caso, hot spares, que seriam capazes de saltar rapidamente e retomar a operação, podem encurtar significativamente esta janela de tempo.
Requisitos estendidos
Tipicamente, os sistemas de uma única máquina apenas colocam todos os processos em funcionamento com isolamento limitado. Embora os containers sejam agora comuns, não é necessário ou comum utilizar containers para isolar todos os componentes de um serviço que é implantado numa única máquina. Portanto, se o cron fosse implantado numa única máquina, o crond e todos os cron jobs executados provavelmente não estariam isolados.
A implantação em escala de datacenter geralmente significa a implantação em containers que forçam ao isolamento. O isolamento é necessário porque a expectativa básica é que os processos independentes que correm no mesmo datacenter não devem ter um impacto negativo uns nos outros. A fim de fazer cumprir essa expectativa, deve-se saber a quantidade de recursos que se precisa adquirir antecipadamente para qualquer processo que se queira executar – tanto para o sistema cron como para os trabalhos que este lança. Um cron job pode ser atrasado se o datacenter não tiver recursos disponíveis para satisfazer as exigências do cron job. Os requisitos de recursos, para além da procura dos utilizadores para monitorização dos lançamentos de cron job, significa que precisamos acompanhar o estado completo dos nossos lançamentos de cron job, desde o lançamento programado até ao seu término.
Os lançamentos do processo de desacoplamento de máquinas específicas expõe o sistema cron a falhas parciais de lançamento. A versatilidade das configurações do cron job também significa que o lançamento de um novo cron job num datacenter pode necessitar de múltiplos RPCs, de tal forma que por vezes nos deparamos com um cenário em que alguns RPCs tiveram sucesso, mas outros não (por exemplo, porque o processo de envio dos RPCs morreu no meio da execução destas tarefas). O processo de recuperação dos ERTs também deve ser responsável por este cenário.
Em termos do modo de falha, um datacenter é um ecossistema substancialmente mais complexo do que uma única máquina. O serviço de cron que começou como um binário relativamente simples numa única máquina tem agora muitas dependências óbvias e não óbvias quando implantado a uma escala maior. Para um serviço tão básico como o cron, queremos assegurar que mesmo que o datacenter sofra uma falha parcial (por exemplo, corte parcial de energia ou problemas com os serviços de armazenamento), o serviço ainda é capaz de funcionar. Ao exigir que o agendador do datacenter localize réplicas do cron em diversos locais dentro do datacenter, evitamos o cenário em que a falha de uma única unidade de distribuição de energia elimina todos os processos do serviço do cron.
Pode ser possível implantar um único serviço cron global, mas implantar cron dentro de um único datacenter tem benefícios: o serviço goza de baixa latência e partilha o destino com o agendador do datacenter, a principal dependência do cron.
Construir o Cron no Google
Esta seção aborda os problemas que devem ser resolvidos a fim de proporcionar uma implantação distribuída em grande escala de forma confiável. Destaca também algumas decisões importantes tomadas em relação ao cron distribuído no Google.
Acompanhamento do estado do Cron Jobs
Tal como discutido nas seções anteriores, precisamos manter certa quantidade de estado sobre os Cron jobs, e ser capazes de restaurar rapidamente essa informação em caso de falha. Além disso, a consistência desse estado é primordial. Recorde-se que muitos cron jobs, como uma folha de pagamentos ou o envio de um boletim informativo por e-mail, não são idempotentes.
Temos duas opções para acompanhar o estado do cron jobs:
- Armazenar dados externamente em armazenamento distribuído geralmente disponível
- Utilizar um sistema que armazena um pequeno volume de estado como parte do próprio serviço cron.
Ao projetar o cron distribuído, escolhemos a segunda opção. Fizemos esta escolha por várias razões:
- Os sistemas de ficheiros distribuídos, tais como GFS ou HDFS, servem muitas vezes para a utilização de ficheiros muito grandes (por exemplo, a saída de web crawling programs), enquanto a informação que precisamos armazenar sobre os cron jobs é muito pequena. As pequenas escritas num sistema de ficheiros distribuído são muito caras e vêm com alta latência, porque o sistema de ficheiros não está otimizado para este tipo de escritas.
- Os serviços de base para os quais as interrupções têm grande impacto (como o Cron) devem ter muito poucas dependências. Mesmo que partes do datacenter desapareçam, o serviço cron deve ser capaz de funcionar pelo menos durante algum tempo. Mas este requisito não significa que o armazenamento tem de fazer parte do processo cron diretamente (a forma como o armazenamento é tratado é essencialmente um detalhe de implementação). Contudo, o cron deve ser capaz de funcionar independentemente dos sistemas downstream que atendem a um grande número de utilizadores internos.
O uso de Paxos
Implementamos múltiplas réplicas do serviço cron e usamos o algoritmo de consenso distribuído Paxos (Leia Capítulo 23: Critical state management: distributed consensus for reliability) para assegurar que têm um estado consistente. Contanto que a maioria dos membros do grupo esteja disponível, o sistema distribuído como um todo pode processar com sucesso novas mudanças de estado, apesar da falha de subconjuntos limitados da infraestrutura.
Como mostrado na Figura 24-1, o cron distribuído utiliza um único trabalho de líder, que é a única réplica que pode modificar o estado partilhado, bem como a única réplica que pode lançar cron jobs. Aproveitamos o fato de que a variante de Paxos que utilizamos, Fast Paxos [Lam06], utiliza uma réplica líder internamente como otimização – a réplica líder Fast Paxos actua também como líder do serviço cron.
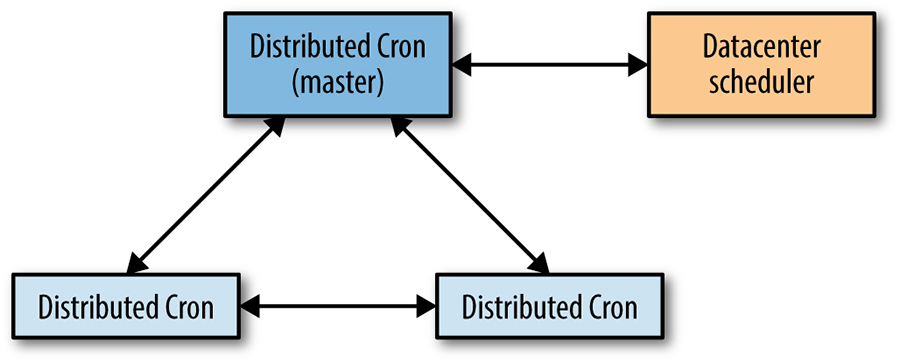
Figura 24-1: As interações entre réplicas cron distribuídas
Se a réplica do líder morrer, o mecanismo de verificação de saúde do grupo Paxos descobre este evento rapidamente (em segundos). Uma vez que outro processo cron já foi iniciado e está disponível, podemos eleger um novo líder. Assim que o novo líder é eleito, seguimos um protocolo de eleição de líder específico para o serviço cron, que é responsável por assumir todo o trabalho deixado inacabado pelo líder anterior. O líder específico do serviço cron é o mesmo que o líder de Paxos, mas o serviço cron precisa tomar medidas adicionais após a promoção. O tempo de reação rápida para a reeleição do líder permite-nos permanecer bem dentro de um tempo de falha geralmente tolerável de um minuto.
O estado mais importante que mantemos em Paxos é a informação sobre quais os trabalhos de cron são lançados. Informamos sincronicamente um quórum de réplicas do início e do fim de cada lançamento agendado para cada cron job.
As funções do Líder e do Seguidor
Como acabamos de descrever, a nossa utilização de Paxos e a sua implantação no serviço cron tem duas funções atribuídas: o líder e o seguidor. As seções seguintes descrevem cada papel.
O líder
A réplica líder é a única réplica que lança ativamente cron jobs. O líder tem um agendador interno que, tal como o simples crond descrito no início deste capítulo, mantém a lista de cron jobs ordenados pela sua hora de lançamento agendada. A réplica do líder espera até à hora programada de lançamento do primeiro trabalho.
Ao atingir a hora de lançamento programada, a réplica líder anuncia que está prestes a iniciar o lançamento deste cron job em particular, e calcula a nova hora de lançamento programada, tal como uma implementação regular de crond. Claro que, tal como no caso de uma crond regular, uma especificação de lançamento de um cron job pode ter mudado desde a última execução, e esta especificação de lançamento deve ser mantida em sincronia com os seguidores também. A simples identificação do cron job não é suficiente: devemos também identificar de forma única o lançamento específico utilizando a hora de início; caso contrário, pode ocorrer ambiguidade no rastreamento de lançamento do cron job. (Tal ambiguidade é especialmente provável no caso de cron jobs de alta frequência, tais como os que decorrem a cada minuto). Como se vê na Figura 24-2, esta comunicação é efetuada sobre Paxos.
É importante que a comunicação Paxos permaneça síncrona, e que o lançamento do trabalho cron efetivo não prossiga até receber a confirmação de que o quorum Paxos recebeu a notificação de lançamento. O serviço cron precisa compreender se cada cron job foi lançado a fim de decidir o próximo curso de ação em caso de falha do líder. Não executar esta tarefa em sincronismo pode significar que todo o lançamento do cron job acontece no líder sem informar as réplicas do seguidor. Em caso de falha, as réplicas do seguidor podem tentar executar novamente o mesmo lançamento porque não estão conscientes de que o lançamento já ocorreu.
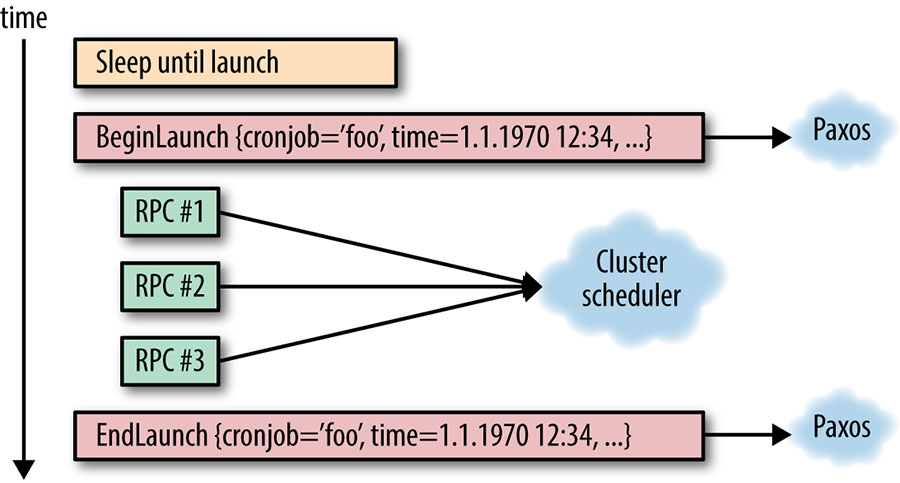
Figura 24-2: Ilustração do progresso de um lançamento de cron job, da perspectiva do líder
A conclusão do lançamento do cron job é anunciada via Paxos para as outras réplicas de forma síncrona. Note-se que não importa se o lançamento foi bem sucedido ou falhou por razões externas (por exemplo, se o programador do datacenter não estava disponível). Aqui, estamos simplesmente acompanhando o fato de que o serviço cron tentou o lançamento na hora marcada. Também precisamos ser capazes de resolver falhas do sistema cron no meio desta operação, tal como discutido na seção seguinte.
Outra característica extremamente importante do líder é que, assim que perde a sua liderança por qualquer razão, deve parar imediatamente de interagir com o programador do datacenter. A posse da liderança deve garantir a exclusão mútua do acesso ao agendador do centro de dados. Na ausência desta condição de exclusão mútua, os antigos e os novos líderes podem realizar ações conflituosas no agendador do datacenter.
O seguidor
As réplicas seguintes mantêm-se a par do estado do mundo, conforme fornecido pelo líder, a fim de assumirem o controle num determinado momento, se necessário. Todas as mudanças de estado seguidas pelas réplicas são comunicadas via Paxos, a partir da réplica do líder. Tal como o líder, os seguidores também mantêm uma lista de todas as réplicas cron jobs no sistema, e esta lista deve ser mantida consistente entre as réplicas (através da utilização de Paxos).
Ao receber notificação sobre um lançamento iniciado, a réplica seguinte atualiza a sua próxima hora de lançamento local agendada para o cron job dado. Esta mudança de estado muito importante (que é realizada de forma síncrona) garante que todos os agendamentos de cron job no sistema sejam consistentes. Acompanhamos todos os lançamentos abertos (lançamentos que começaram mas não terminaram).
Se uma réplica de líder morrer ou apresentar qualquer outra avaria (por exemplo, for separada das outras réplicas na rede), um seguidor deve ser eleito como um novo líder. A eleição deve convergir mais rapidamente do que um minuto, a fim de evitar o risco de faltar ou de atrasar irrazoavelmente o lançamento de um cron job. Uma vez eleito um líder, todos os lançamentos em aberto (ou seja, falhas parciais) devem ser concluídos. Este processo pode ser bastante complicado, impondo requisitos adicionais tanto ao sistema cron como à infraestrutura do datacenter. A seção seguinte discute a forma de resolver falhas parciais deste tipo.
Resolução de falhas parciais
Como mencionado, a interação entre a réplica líder e o agendador do datacenter pode falhar entre o envio de múltiplos RPCs que descrevem um único lançamento lógico de cron job. Os nossos sistemas devem ser capazes de lidar com esta condição.
Recorde-se que cada lançamento de cron job tem dois pontos de sincronização:
- Quando estamos prestes a realizar o lançamento
- Quando tivermos terminado o lançamento
Estes dois pontos permitem-nos delimitar o lançamento. Mesmo que o lançamento seja composto por um único RPC, como sabemos se o RPC foi realmente enviado? Considere o caso em que sabemos que o lançamento previsto começou, mas não fomos notificados da sua conclusão antes da morte do líder.
A fim de determinar se o RPC foi realmente enviado, uma das seguintes condições deve ser cumprida:
- Todas as operações em sistemas externos, que possamos ter de continuar após a reeleição, devem ser idempotentes (ou seja, podemos voltar a realizar as operações em segurança)
- Devemos ser capazes de verificar o estado de todas as operações em sistemas externos, a fim de determinar inequivocamente se foram concluídas ou não
Cada uma destas condições impõe restrições significativas, e pode ser difícil de implementar, mas ser capaz de satisfazer pelo menos uma destas condições é fundamental para o funcionamento preciso de um serviço cron num ambiente distribuído que poderia sofrer uma única ou várias falhas parciais. O não tratamento adequado desta situação pode levar a lançamentos perdidos ou a lançamento duplo do mesmo cron job.
A maioria das infraestruturas que lançam trabalhos lógicos em datacenters (Mesos, por exemplo) fornece nomes para esses trabalhos de datacenter, tornando possível consultar o estado dos trabalhos, interromper os trabalhos, ou efetuar outras manutenções. Uma solução razoável para o problema da idempotência é construir os nomes dos trabalhos antecipadamente (evitando assim causar quaisquer operações mutantes no agendador do datacenter), e depois distribuir os nomes por todas as réplicas do seu serviço cron. Se o líder do serviço cron morre durante o lançamento, o novo líder simplesmente procura o estado de todos os nomes pré-computados e lança os nomes em falta.
Note que, à semelhança do nosso método de identificação dos lançamentos individuais de cron jobs pelo seu nome e hora de lançamento, é importante que os nomes dos trabalhos construídos no agendador do datacenter incluam a hora específica de lançamento programada (ou que esta informação possa ser recuperada de outra forma). Em funcionamento regular, o serviço cron deve “failover” rapidamente em caso de falha do líder, mas um “failover” rápido nem sempre acontece.
Recorde-se de que acompanhamos a hora programada de lançamento ao manter o estado interno entre as réplicas. Da mesma forma, precisamos desambiguar a nossa interação com o agendador do datacenter, também utilizando a hora de lançamento agendada. Por exemplo, considerar um cron job de curta duração mas frequentemente executado. O cron job lança, mas antes que o lançamento seja comunicado a todas as réplicas, o líder cai e ocorre um failover incomumente longo – longo o suficiente para que o cron job seja concluído com êxito. O novo líder procura o estado do cron job, observa a sua conclusão, e tenta lançar o trabalho de novo. Se o tempo de lançamento tivesse sido incluído, o novo líder saberia que o trabalho no agendador do datacenter é o resultado deste lançamento específico do cron job, e este lançamento duplo não teria acontecido.
A implementação efetiva tem um sistema mais complicado de procura do estado, impulsionado pelos detalhes de implementação da infraestrutura subjacente. Contudo, a descrição anterior abrange os requisitos independentes da implementação de qualquer sistema deste tipo. Dependendo da infraestrutura disponível, poderá também ser necessário considerar o compromisso entre arriscar um lançamento duplo e o risco de pular um lançamento.
Armazenando o estado
A utilização de Paxos para obter consenso é apenas uma parte do problema de como lidar com o estado. Paxos é essencialmente um registo contínuo de mudanças de estado, anexado de forma síncrona à medida que ocorrem mudanças de estado. Esta característica de Paxos tem duas implicações:
- O log precisa ser compactado, para evitar o seu crescimento infinito
- O próprio log deve ser armazenado em algum lugar
A fim de evitar o crescimento infinito do Paxos log, podemos simplesmente tirar um snapshot do estado atual, o que significa que podemos reconstruir o estado sem necessidade de reproduzir todas as entradas do registo de mudança de estado que conduzem ao estado atual. Para dar um exemplo: se as nossas alterações de estado armazenadas em logs são “Incrementar um contador por 1”, então após mil iterações, temos mil entradas de logs que podem ser facilmente alteradas para um snapshot de “Definir contador para 1.000”.
Em caso de perda de logs, só perdemos o estado desde o último snapshot. Os snapshots são de fato o nosso estado mais crítico – se perdermos os nossos snapshots, temos essencialmente de recomeçar do zero porque perdemos o nosso estado interno. A perda de logs, por outro lado, apenas causa uma perda limitada do estado e envia o sistema cron de volta no tempo ao ponto em que a último snapshot foi tirado.
Temos duas opções principais para o armazenamento dos nossos dados:
- Externamente, no armazenamento distribuído geralmente disponível
- Num sistema que armazena o pequeno volume do estado como parte do próprio serviço cron
Ao projetar o sistema, combinamos elementos de ambas as opções.
Armazenamos os Paxos logs no disco local da máquina onde as réplicas do serviço cron estão programadas. Ter três réplicas em operação padrão implica que temos três cópias dos logs. Armazenamos os snapshots também no disco local. No entanto, por serem críticos, também os apoiamos num sistema de ficheiros distribuído, protegendo assim contra falhas que afetem as três máquinas.
Não armazenamos logs no nosso sistema de ficheiros distribuídos. Decidimos conscientemente que a perda de logs, que representam uma pequena quantidade das mais recentes mudanças de estado, é um risco aceitável. O armazenamento de logs num sistema de ficheiros distribuído pode implicar uma penalização substancial de desempenho causada por pequenas escritas frequentes. A perda simultânea das três máquinas é improvável, e se a perda simultânea ocorrer, restauramos automaticamente a partir do snapshot. Perdemos assim apenas uma pequena quantidade de logs: os que foram tirados desde o último snapshot, que realizamos em intervalos configuráveis. É claro que estas trocas podem ser diferentes dependendo dos detalhes da infraestrutura, bem como dos requisitos colocados no sistema cron.
Para além dos logs e snapshots armazenados no disco local e das cópias de segurança de snapshot no sistema de ficheiros distribuídos, uma réplica recém iniciada pode ir buscar o estado de snapshot e todos os logs a partir de uma já em execução na rede. Essa capacidade torna a inicialização da réplica independente de qualquer estado na máquina local. Por conseguinte, reprogramar uma réplica para uma máquina diferente no reinício (ou morte da máquina) é essencialmente uma questão que não tem a ver com a confiabilidade do serviço.
Executando Cron Grande
Existem outras implicações menores, mas igualmente interessantes, de executar uma grande implantação do cron. Um cron tradicional é pequeno: no máximo, provavelmente contém na ordem das dezenas de cron jobs. Contudo, se executar um serviço de cron para milhares de máquinas num datacenter, a sua utilização irá crescer, e poderá deparar-se com problemas.
Cuidado com o grande e bem conhecido problema dos sistemas distribuídos: o rebanho trovejante. Com base na configuração do utilizador, o serviço cron pode causar picos substanciais na utilização do datacenter. Quando as pessoas pensam num “cron job diário”, normalmente configuram este trabalho para funcionar à meia-noite. Esta configuração funciona perfeitamente se o cron job for lançado na mesma máquina, mas e se o seu cron job puder gerar um MapReduce com milhares de trabalhadores? E se 30 equipes diferentes decidirem executar um cron job diário como este, no mesmo datacenter? Para resolver este problema, introduzimos uma extensão ao formato crontab.
No crontab comum, os utilizadores especificam o minuto, hora, dia do mês (ou semana), e mês em que o cron job deve ser lançado, ou asterisco para especificar qualquer valor. Executando à meia-noite, diariamente, teria então a especificação da crontab de “0 0 * * *” (ou seja, zero minuto, zero hora, todos os dias da semana, todos os meses, e todos os dias da semana). Também introduzimos a utilização do ponto de interrogação, o que significa que qualquer valor é aceitável, e é dada ao sistema cron a liberdade de escolher o valor. Os utilizadores escolhem este valor, apressando a configuração do cron job ao longo do intervalo de tempo dado (por exemplo, 0..23 por hora), distribuindo assim os lançamentos de forma mais uniforme.
Apesar desta mudança, a carga causada pelos trabalhos de cron continua a ser muito espinhosa. O gráfico da Figura 24-3 ilustra o número global agregado de lançamentos de cron jobs no Google. Este gráfico destaca os frequentes picos nos lançamentos de cron jobs, que são frequentemente causados por cron jobs que precisam ser lançados num momento específico, por exemplo, devido à dependência temporal de eventos externos.
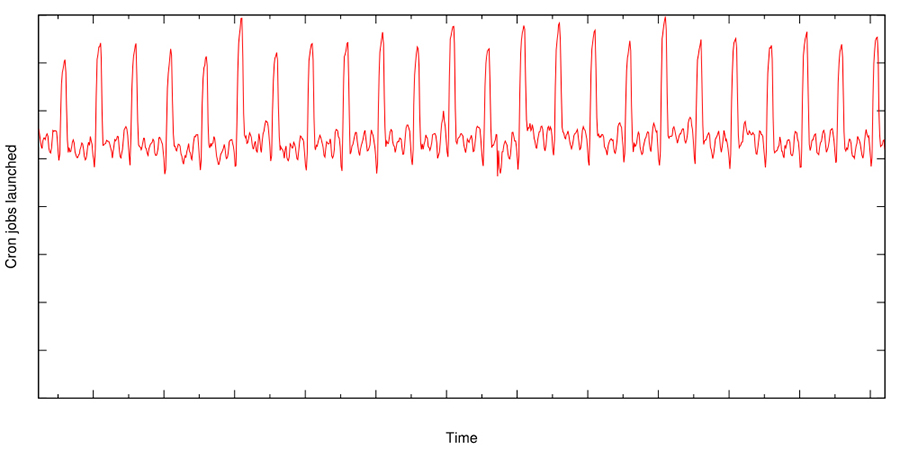
Figura 24-3: O número de cron jobs lançados a nível mundial
Resumo
Um serviço cron tem sido uma característica fundamental nos sistemas UNIX durante muitas décadas. A mudança do setor para grandes sistemas distribuídos, nos quais um datacenter pode ser a menor unidade efetiva de hardware, requer mudanças em grandes quantidades. Cron não é exceção a esta tendência. Uma análise cuidadosa das propriedades necessárias de um serviço cron e dos requisitos dos cron jobs impulsiona o novo design do Google.
Discutimos as novas restrições exigidas por um ambiente de sistema distribuído, e uma possível concepção do serviço cron baseada na solução do Google. Esta solução requer fortes garantias de consistência no ambiente distribuído. O núcleo da implementação do cron distribuído é portanto o Paxos, um algoritmo comum para se chegar a consenso num ambiente não confiável. A utilização de Paxos e a análise correta de novos modos de falha de cron jobs num ambiente distribuído e em larga escala permitiu-nos construir um serviço cron robusto que é muito utilizado no Google.