Escrito por Mike Ulrich
“Se no início você não conseguir, recue exponencialmente.”
Dan Sandler, engenheiro de software do Google
“Por que as pessoas sempre esquecem que você precisa adicionar um pouco de jitter?”
Ade Oshieye, desenvolvedor porta-voz do Google
Uma falha em cascata é uma falha que cresce ao longo do tempo como resultado de feedback positivo. Pode ocorrer quando uma parte de um sistema geral falha, aumentando a probabilidade de que outras partes do sistema falhem. Por exemplo, uma única réplica de um serviço pode falhar devido à sobrecarga, aumentando a carga nas réplicas restantes e aumentando sua probabilidade de falha, causando um efeito dominó que desativa todas as réplicas de um serviço.
Usaremos o serviço de busca de Shakespeare discutido em “Shakespeare: um serviço de exemplo” (ver Capítulo 2) como um exemplo ao longo deste capítulo. Sua configuração de produção pode se parecer com a da figura abaixo.
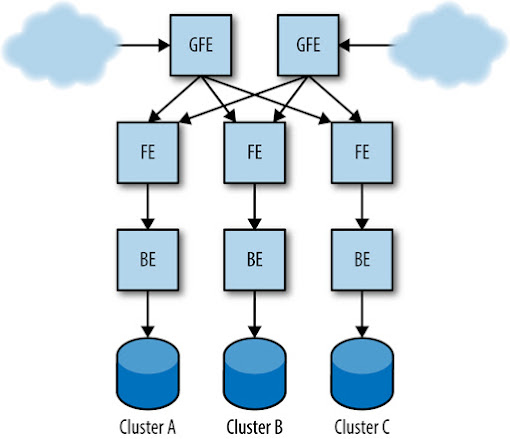
[Figura] – Legenda: Exemplo de configuração de produção para o serviço de pesquisa Shakespeare
Causas de falhas em cascata e projetando para evitá-las
O design de sistema bem pensado deve levar em consideração alguns cenários típicos que respondem pela maioria das falhas em cascata.
Sobrecarga no servidor
A causa mais comum de falhas em cascata é a sobrecarga. A maioria das falhas em cascata descritas aqui estão diretamente relacionadas à sobrecarga do servidor ou devido a extensões ou variações desse cenário.
Suponha que o frontend no cluster A esteja processando 1.000 solicitações por segundo (QPS), como na figura abaixo.
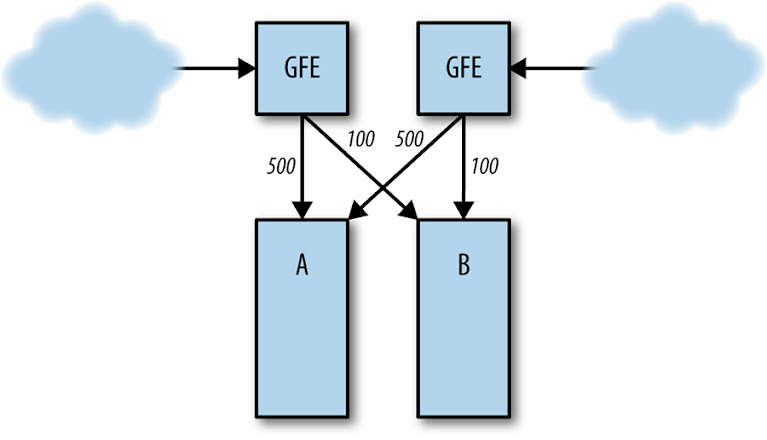
[Figura] – Legenda: Distribuição normal de carga do servidor entre os clusters A e B
Se o cluster B falhar (veja figura abaixo), as solicitações para o cluster A aumentam para 1.200 QPS. Os frontends em A não são capazes de lidar com requisições em 1.200 QPS e, portanto, começam a ficar sem recursos, o que os faz travar, perder prazos ou se comportar mal. Como resultado, a taxa de requisições tratadas com sucesso em A cai bem abaixo de 1.000 QPS.
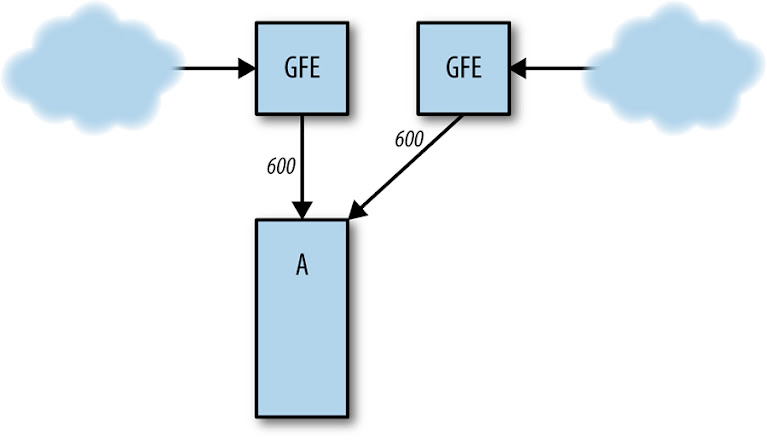
[Figura] – Legenda: O cluster B falha, enviando todo o tráfego para o cluster A
Essa redução na taxa de trabalho útil que está sendo feito pode se espalhar para outros domínios de falha, se espalhando potencialmente, em nível global. Por exemplo, a sobrecarga local em um cluster pode levar à falha de seus servidores; em resposta, o controlador de balanceamento de carga envia solicitações para outros clusters, sobrecarregando seus servidores, levando a uma falha de sobrecarga em todo o serviço. Pode não demorar muito para que esses eventos ocorram (por exemplo, na ordem de alguns minutos), porque o balanceador de carga e os sistemas de agendamento de tarefas envolvidos podem agir muito rapidamente.
Esgotamento de recursos
A falta de um recurso pode resultar em maior latência, taxas de erro elevadas ou substituição de resultados de qualidade inferior. Esses são, na verdade, efeitos desejados da falta de recursos: algo eventualmente precisa ceder à medida que a carga aumenta além do que um servidor pode suportar.
Dependendo de qual recurso se esgota em um servidor e de como o servidor é construído, o esgotamento de recursos pode tornar o servidor menos eficiente ou fazer com que o servidor falhe, solicitando que o balanceador de carga distribua os problemas de recursos para outros servidores. Quando isso acontece, a taxa de requisições tratadas com êxito pode cair e possivelmente enviar o cluster ou um serviço inteiro para uma falha em cascata.
Diferentes tipos de recursos podem ser esgotados, resultando em efeitos variados nos servidores.
CPU
Se houver CPU insuficiente para lidar com a carga da requisição, normalmente todas as solicitações ficam mais lentas. Este cenário pode resultar em vários efeitos secundários, incluindo os seguintes:
Aumento do número de solicitações in-flight (solicitações que foram iniciadas, mas ainda não foram concluídas)
Como as requisições demoram mais para serem tratadas, mais solicitações são tratadas simultaneamente (até uma capacidade máxima possível onde o enfileiramento pode ocorrer). Isso afeta quase todos os recursos, incluindo memória, número de threads ativas (em um modelo de servidor do tipo thread por requisição), número de descritores de arquivo e recursos de backend (que, por sua vez, podem ter outros efeitos).
Comprimentos de fila excessivamente longos
Se não houver capacidade suficiente para lidar com todas as requisições em um estado mais estável, o servidor irá saturar suas filas. Isso significa que a latência aumenta (as solicitações são enfileiradas por mais tempo) e a fila usa mais memória. (Veja logo abaixo neste artigo, em “Gerenciamento de filas”, uma discussão mais a fundo sobre estratégias de mitigação).
Thread starvation
Quando uma thread não pode progredir porque está aguardando um bloqueio, as verificações de integridade podem falhar se o endpoint de verificação de integridade não puder ser atendido a tempo.
CPU ou request starvation
Watchdogs internos no servidor detectam que o servidor não está progredindo, fazendo com que os servidores travem devido à falta de CPU ou devido à falta de solicitação se os eventos de watchdog forem acionados remotamente e processados como parte da fila de requisições.
Observação: Um watchdog é frequentemente implementado como uma thread que “acorda” periodicamente para ver se o trabalho foi feito desde a última vez que foi verificado. Caso contrário, ela assume que o servidor está travado e o elimina. Por exemplo, solicitações de um tipo conhecido podem ser enviadas ao servidor em intervalos regulares; se um não foi recebido ou processado quando esperado, isso pode indicar falha – do servidor, do sistema enviando solicitações ou mesmo da rede intermediária.
Prazos de RPC perdidos
À medida que um servidor fica sobrecarregado, suas respostas aos RPCs de seus clientes chegam mais tarde, o que pode exceder os prazos definidos por esses clientes. O trabalho que o servidor fez para responder é desperdiçado e os clientes podem tentar novamente os RPCs, levando a uma sobrecarga ainda maior.
Benefícios reduzidos de cache da CPU
À medida que mais CPU é usada, a chance de se espalhar para mais núcleos aumenta, resultando em menor uso de caches locais e diminuição de eficiência da CPU.
Memória
Se mais nada existir, mais solicitações em andamento consomem mais RAM da alocação da requisição, resposta e objetos RPC. O esgotamento da memória pode causar os seguintes efeitos:
Tarefas mortas
Por exemplo, uma tarefa pode ser descartada pelo gerenciador de container (VM ou outro) por exceder os limites de recursos disponíveis, ou falhas específicas da aplicação podem fazer com que as tarefas morram.
Aumento da taxa de garbage collection (GC) no Java, resultando em maior uso da CPU
Um ciclo vicioso pode ocorrer nesse cenário: menos CPU está disponível, resultando em solicitações mais lentas, que levam a maior uso de RAM, consequentemente mais GC, e por fim a uma disponibilidade ainda menor da CPU. Isso é conhecido coloquialmente como a “espiral da morte do GC”.
Redução nas taxas de acerto do cache
A redução na RAM disponível pode reduzir as taxas de acerto do cache em nível de aplicação, resultando em mais RPCs para os backends, o que pode fazer com que os backends fiquem sobrecarregados.
Threads
Thread starvation pode causar erros diretamente ou levar a falhas na verificação de integridade. Se o servidor adicionar threads conforme necessário, a sobrecarga de thread pode usar muita RAM. Em casos extremos, a thread starvation também pode fazer com que você fique sem IDs de processo.
Descritores de arquivo
A falta de descritores de arquivo pode levar à incapacidade de inicializar conexões de rede, o que, por sua vez, pode causar falhas nas verificações de integridade.
Dependências entre recursos
Observe que muitos desses cenários de esgotamento de recursos se alimentam uns dos outros — um serviço com sobrecarga geralmente contempla uma série de sintomas secundários que podem parecer a causa raiz, dificultando o debug.
Por exemplo, imagine o seguinte cenário:
- Um frontend Java possui parâmetros de garbage collection (GC) mal ajustados.
- Sob alta (mas esperada) carga, o frontend fica sem CPU devido ao GC.
- O esgotamento da CPU retarda a conclusão das solicitações.
- O aumento do número de requisições em andamento faz com que mais RAM seja usada para processar as solicitações.
- A pressão de memória devido a solicitações, em combinação com uma alocação de memória fixa para o processo de frontend como um todo, deixa menos RAM disponível para armazenamento em cache.
- O tamanho reduzido do cache significa menos entradas no cache, além de uma menor taxa de acertos.
- O aumento nas faltas de cache significa que mais requisições chegam ao backend para manutenção.
- O backend, por sua vez, fica sem CPU ou threads.
- Por fim, a falta de CPU faz com que as verificações de integridade básicas falhem, iniciando uma falha em cascata.
Em situações tão complexas quanto o cenário anterior, é improvável que a cadeia causal seja totalmente diagnosticada durante uma interrupção. Pode ser muito difícil determinar que a falha de backend foi causada por uma diminuição na taxa de cache no frontend, principalmente se os componentes de frontend e backend tiverem proprietários diferentes.
Indisponibilidade do serviço
O esgotamento de recursos pode levar ao travamento dos servidores; por exemplo, os servidores podem travar quando muita RAM é alocada para um container. Uma vez que alguns servidores travam por sobrecarga, a carga nos servidores restantes pode aumentar, fazendo com que eles também travem. O problema tende a se tornar uma bola de neve e logo todos os servidores começam a travar. Muitas vezes, é difícil escapar desse cenário porque, assim que os servidores voltam a ficar online, são bombardeados com uma taxa extremamente alta de requisições e falham quase que imediatamente.
Por exemplo, se um serviço estava íntegro em 10.000 QPS, mas iniciou uma falha em cascata devido a falhas em 11.000 QPS, reduzir a carga para 9.000 QPS quase certamente não interromperá as falhas. Isso porque o serviço atenderá ao aumento da demanda com capacidade reduzida; apenas uma pequena fração de servidores normalmente estará íntegra o suficiente para lidar com requisições. A fração de servidores que estarão íntegros depende de alguns fatores: a rapidez com que o sistema é capaz de iniciar as tarefas, a rapidez com que o binário pode começar a servir com capacidade total e por quanto tempo uma tarefa recém-iniciada é capaz de sobreviver à carga. Neste exemplo, se 10% dos servidores estiverem íntegros o suficiente para lidar com requisições, a taxa de requisição precisaria cair para cerca de 1.000 QPS para que o sistema se estabilizasse e se recuperasse.
Da mesma forma, os servidores podem parecer insalubres para a camada de balanceamento de carga, resultando em capacidade reduzida de balanceamento de carga: os servidores podem entrar no estado “lame duck” – consulte “Uma abordagem robusta para tarefas insalubres: estado lame duck” no Capítulo 20 – ou falhar nas verificações de integridade sem travar. O efeito pode ser muito semelhante ao travamento: mais servidores parecem íntegros, os servidores íntegros tendem a aceitar requisições por um período muito breve antes de se tornarem íntegros e menos servidores participam do tratamento de requisições.
As políticas de balanceamento de carga que evitam servidores que atenderam a erros podem agravar ainda mais os problemas – alguns backends atendem a alguns erros, portanto, não contribuem para a capacidade disponível de serviço. Isso aumenta a carga nos servidores restantes, iniciando o efeito bola de neve.
Prevenindo a sobrecarga do servidor
A lista a seguir apresenta estratégias para evitar a sobrecarga do servidor em ordem aproximada de prioridade:
Teste a carga dos limites de capacidade do servidor e teste o modo de falha para sobrecarga
Esse é o exercício mais importante que você deve realizar para evitar a sobrecarga do servidor. A menos que você teste em um ambiente realista, é muito difícil prever exatamente qual recurso será esgotado e como esse esgotamento de recurso se manifestará. Para mais detalhes, veja a seção “Teste para falhas em cascata”, mais abaixo neste artigo.
Exiba resultados degradados
Forneça resultados de menor qualidade e mais baratos para o usuário. Sua estratégia aqui será específica do serviço. Veja abaixo a seção “Descarte de carga e degradação suave”.
Instrumente sistemas de nível superior para rejeitar requisições, em vez de sobrecarregar os servidores
Observe que, como a limitação de taxa geralmente não leva em consideração a integridade geral do serviço, talvez não seja possível interromper uma falha que já começou. Implementações simples de limitação de taxa também podem resultar em capacidade não utilizada. A limitação de taxa pode ser implementada em vários locais:
- Nos proxies reversos, limitando o volume de requisições por critérios como endereço IP para mitigar tentativas de ataques de negação de serviço e clientes abusivos.
- Nos balanceadores de carga, descartando requisições quando o serviço entra em sobrecarga global. Dependendo da natureza e complexidade do serviço, essa limitação de taxa pode ser indiscriminada (“descartar todo o tráfego acima de X requisições por segundo”) ou mais seletiva (“descartar requisições que não são de usuários que interagiram recentemente com o serviço” ou ainda “descarte de requisições para operações de baixa prioridade, como sincronização em segundo plano, mas continue atendendo a sessões interativas de usuário”).
- Em tarefas individuais, para evitar que flutuações aleatórias no balanceamento de carga sobrecarreguem o servidor.
Faça o planejamento de capacidade
Um bom planejamento de capacidade pode reduzir a probabilidade de ocorrência de uma falha em cascata. O planejamento de capacidade deve ser combinado com testes de desempenho para determinar a carga na qual o serviço falhará. Por exemplo, se o ponto de interrupção de cada cluster for 5.000 QPS, a carga for distribuída uniformemente pelos clusters – essa em geral não é uma boa suposição devido à geografia; veja também o tópico “Organização de jobs e dados” no Capítulo 2 – e a carga de pico do serviço for 19.000 QPS, então serão necessários aproximadamente seis clusters para executar o serviço em N + 2.
O planejamento de capacidade reduz a probabilidade de acionar uma falha em cascata, mas não é suficiente para proteger o serviço de falhas em cascata. Quando você perde partes importantes da sua infraestrutura durante um evento planejado ou não planejado, nenhuma quantidade de planejamento de capacidade pode ser suficiente para evitar falhas em cascata. Problemas de balanceamento de carga, partições de rede ou aumentos inesperados de tráfego podem criar bolsões de carga alta além do planejado. Alguns sistemas podem aumentar o número de tarefas para seu serviço sob demanda, o que pode evitar sobrecarga; no entanto, ainda é necessário um planejamento de capacidade adequado.
Gerenciamento de filas
A maioria dos servidores thread-per-request usa uma fila na frente de um pool de threads para lidar com as requisições. As requisições chegam, ficam em uma fila e, em seguida, as threads retiram as requisições da fila e executam o trabalho real (ou seja, quaisquer ações exigidas pelo servidor). Normalmente, se a fila estiver cheia, o servidor rejeitará novas requisições.
Se a taxa de requisição e a latência de uma determinada tarefa forem constantes, não há motivo para enfileirar requisições: um número constante de threads deve ser ocupado. Nesse cenário idealizado, as solicitações só serão enfileiradas se a taxa de estado estável de requisições recebidas exceder a taxa na qual o servidor pode processá-las, o que resultará na saturação do pool de threads e da fila.
As solicitações enfileiradas consomem memória e aumentam a latência. Por exemplo, se o tamanho da fila for 10x o número de threads, o tempo para tratar a requisição em uma thread será de 100 milissegundos. Se a fila estiver cheia, uma requisição levará 1,1 segundo para ser processada, a maior parte do tempo gasto na fila.
Para um sistema com tráfego bastante estável ao longo do tempo, geralmente é melhor ter pequenos comprimentos de fila em relação ao tamanho do pool de threads (por exemplo, 50% ou menos), o que resulta na rejeição antecipada de solicitações pelo servidor quando não pode sustentar a taxa de requisições recebidas. Por exemplo, o Gmail geralmente usa servidores sem fila, contando com failover para outras tarefas do servidor quando as threads estão cheias. Na outra extremidade do espectro, sistemas com carga “bursty” para os quais os padrões de tráfego flutuam drasticamente podem se sair melhor com um tamanho de fila baseado no número atual de threads em uso, tempo de processamento para cada solicitação e tamanho e frequência de bursts.
Descarte de carga e degradação elegante
O descarte de carga reduz uma parte da carga ao descartar o tráfego à medida que o servidor se aproxima das condições de sobrecarga. O objetivo é evitar que o servidor fique sem RAM, falhe nas verificações de integridade, atenda com latência extremamente alta ou qualquer outro sintoma associado à sobrecarga, enquanto ainda faz o máximo de trabalho útil possível.
Uma maneira direta de reduzir a carga é fazer a limitação por tarefa com base na CPU, na memória ou no comprimento da fila; limitar o comprimento da fila, conforme acima discutido em “Gerenciamento de filas”, é uma forma de compor essa estratégia. Por exemplo, uma abordagem eficaz é retornar um HTTP 503 (serviço indisponível) para qualquer solicitação recebida quando houver mais de um determinado número de requisições de clientes em andamento.
Alterar o método de enfileiramento do padrão first-in, first-out (FIFO) para last-in, first-out (LIFO) ou usar o algoritmo de atraso controlado (CoDel), ou ainda abordagens semelhantes podem reduzir a carga removendo solicitações que dificilmente valerão a pena ser processadas. Se a pesquisa na web de um usuário estiver lenta porque um RPC ficou na fila por 10 segundos, há uma boa chance de o usuário ter desistido e atualizado seu navegador, emitindo outra solicitação: ou seja, não adianta responder à primeira, pois ela será ignorada! Essa estratégia funciona bem quando combinada com a propagação de prazos RPC em toda a stack, descritos mais abaixo em Latência e prazos.
Abordagens mais sofisticadas incluem identificar clientes para ser mais seletivo sobre qual trabalho é descartado ou selecionar requisições mais importantes e priorizar. Essas estratégias são mais prováveis de serem necessárias para serviços compartilhados.
A degradação suave leva o conceito de redução de carga a um passo além, reduzindo a quantidade de trabalho que precisa ser realizada. Em algumas aplicações, é possível diminuir significativamente a quantidade de trabalho ou tempo necessário, diminuindo a qualidade das respostas. Por exemplo, um aplicativo de pesquisa pode pesquisar apenas um subconjunto de dados armazenados em um cache de memória em vez do banco de dados completo em disco, ou ainda usar um algoritmo de classificação menos preciso (porém mais rápido) quando se encontrar sobrecarregado.
Ao avaliar as opções de redução de carga ou degradação suave para seu serviço, considere o seguinte:
- Quais métricas você deve usar para determinar quando o corte de carga ou a degradação suave devem ser ativados? (por exemplo, uso da CPU, latência, comprimento da fila, número de threads usados, se seu serviço entra no modo degradado automaticamente ou se a intervenção manual é necessária)
- Quais ações devem ser tomadas quando o servidor estiver em modo degradado?
- Em qual camada devem ser implementados o descarte de carga e a degradação suave? Faz sentido implementar essas estratégias em todas as camadas da stack ou é suficiente ter um ponto de estrangulamento de alto nível?
Ao avaliar as opções e fazer o deploy, lembre-se do seguinte:
- A degradação suave não deve ser acionada com muita frequência, geralmente em casos de falha no planejamento de capacidade ou mudança inesperada de carga. Mantenha o sistema simples e compreensível, principalmente se não for usado com frequência.
- Lembre-se de que o caminho do código que você nunca usa é o caminho do código que (muitas vezes) não funciona. Na operação em estado estacionário, o modo de degradação suave não será usado, o que implica que você terá muito menos experiência operacional com esse modo e qualquer uma de suas peculiaridades, consequentemente aumentando o nível de risco. Você pode garantir que a degradação normal continue funcionando ao executar regularmente um pequeno subconjunto de servidores próximo à sobrecarga para exercitar esse caminho de código.
- Monitore e alerte quando muitos servidores entrarem nesses modos.
- A eliminação de carga complexa e a degradação suave podem causar problemas por si só — a complexidade excessiva pode fazer com que o servidor entre em um modo degradado quando não for desejado ou entre em ciclos de feedback em momentos indesejados. Projete uma maneira de desativar rapidamente a degradação suave complexa ou ajuste os parâmetros, se necessário. Armazenar essa configuração em um sistema consistente que cada servidor possa observar as alterações, como é o caso do Chubby, pode aumentar a velocidade de deploy, mas também apresenta seus próprios riscos de falha sincronizada.
Novas tentativas
Suponha que o código no frontend que fala com o backend implemente novas tentativas ingenuamente. Ele tenta novamente após encontrar uma falha e limita o número de RPCs de backend por requisição lógica para 10. Considere o código abaixo no frontend, usando gRPC em Go:
func exampleRpcCall(client pb.ExampleClient, request pb.Request) *pb.Response {
// Set RPC timeout to 5 seconds.
opts := grpc.WithTimeout(5 * time.Second)
// Try up to 10 times to make the RPC call.
attempts := 10
for attempts > 0 {
conn, err := grpc.Dial(*serverAddr, opts...)
if err != nil {
// Something went wrong in setting up the connection. Try again.
attempts--
continue
}
defer conn.Close()
// Create a client stub and make the RPC call.
client := pb.NewBackendClient(conn)
response, err := client.MakeRequest(context.Background, request)
if err != nil {
// Something went wrong in making the call. Try again.
attempts--
continue
}
return response
}
grpclog.Fatalf("ran out of attempts")
}
Este sistema pode entrar em cascata da seguinte maneira:
- Assumindo que nosso backend tenha um limite conhecido de 10.000 QPS por tarefa, após o qual todas as requisições adicionais serão rejeitadas em uma tentativa de degradação normal.
- O frontend chama MakeRequest a uma taxa constante de 10.100 QPS e sobrecarrega o backend em 100 QPS, que o backend rejeita.
- Esses 100 QPS com falha são repetidos no MakeRequest a cada 1.000 ms e provavelmente são bem sucedidos. Mas as tentativas estão se somando às solicitações enviadas ao backend, que agora recebe 10.200 QPS — 200 QPS, os quais estão falhando devido à sobrecarga.
- O volume de novas tentativas cresce: 100 QPS de tentativas no primeiro segundo levam a 200 QPS, depois a 300 QPS e assim por diante. Cada vez menos solicitações são bem sucedidas na primeira tentativa, de modo que o trabalho menos útil está sendo executado como uma fração das solicitações para o backend.
Se a tarefa de backend não for capaz de lidar com o aumento na carga — que está consumindo descritores de arquivo, memória e tempo de CPU no backend — ela pode derreter e travar sob a simples carga de solicitações e novas tentativas. Essa falha redistribui as solicitações recebidas pelas tarefas de backend restantes, sobrecarregando ainda mais essas tarefas.
Algumas suposições simplificadoras foram feitas aqui para ilustrar esse cenário, mas a questão é que novas tentativas podem desestabilizar um sistema. Observe que picos de carga temporários e aumentos lentos no uso podem causar esse efeito. (Um exercício instrutivo, deixado a cargo do leitor: escreva um simulador simples e veja como a quantidade de trabalho útil que o backend pode fazer varia com o quanto ele está sobrecarregado e quantas tentativas são permitidas). .
Mesmo que a taxa de chamadas para MakeRequest diminua para os níveis anteriores ao colapso (9.000 QPS, por exemplo), dependendo de quanto o retorno de uma falha custa ao backend, o problema pode não desaparecer. Dois fatores estão em jogo aqui:
- Se o backend gastar uma quantidade significativa de recursos processando solicitações que acabarão falhando devido à sobrecarga, as próprias tentativas podem estar mantendo o backend em um modo sobrecarregado.
- Os próprios servidores de backend podem não ser estáveis. Novas tentativas podem amplificar os efeitos vistos no tópico “sobrecarga no servidor”, no início deste capítulo.
Se uma dessas condições for verdadeira, para sair dessa interrupção você deve reduzir ou eliminar drasticamente a carga nos frontends até que as tentativas parem e os backends se estabilizem.
Esse padrão tem contribuído para várias falhas em cascata. Se os frontends e backends se comunicam por meio de mensagens RPC, o “frontend” é o código JavaScript do cliente que emite chamadas XmlHttpRequest para um endpoint e tenta novamente em caso de falha – ou as tentativas se originam de um protocolo de sincronização offline que tenta novamente de forma agressiva quando encontra uma falha.
Ao emitir novas tentativas automáticas, tenha em mente as seguintes considerações:
- A maioria das estratégias de proteção de backend descritas no tópico “Prevenindo a sobrecarga do servidor” se aplicam. Em particular, testar o sistema pode evidenciar problemas e a degradação suave pode reduzir o efeito das novas tentativas no backend.
- Sempre use o recuo exponencial aleatório ao agendar novas tentativas. Consulte também “Recuo exponencial e instabilidade” no Blog de arquitetura da AWS. Se as novas tentativas não forem distribuídas aleatoriamente pela janela de novas tentativas, uma pequena perturbação (por exemplo, um ruído na rede) pode fazer com que ondulações de novas tentativas sejam agendadas ao mesmo tempo, que podem então se amplificar.
- Limite as tentativas por solicitação. Não repita uma determinada solicitação indefinidamente.
- Considere ter um orçamento de repetição por todo o servidor. Por exemplo, permita apenas 60 tentativas por minuto em um processo e, se o orçamento de novas tentativas for excedido, não tente novamente; apenas falhe o pedido. Essa estratégia pode conter o efeito de repetição e ser a diferença entre uma falha de planejamento de capacidade que leva a algumas consultas descartadas e uma falha global em cascata.
- Pense no serviço de forma holística e decida se você realmente precisa realizar novas tentativas em um determinado nível. Em particular, evite amplificar novas tentativas emitindo novas tentativas em vários níveis: uma única solicitação na camada mais alta pode produzir um número de tentativas tão grande quanto o produto do número de tentativas em cada camada para a camada mais baixa. Se o banco de dados não puder atender a solicitações porque está sobrecarregado e as camadas de backend, frontend e JavaScript emitirem 3 tentativas (4 esforços), uma única ação do usuário poderá criar 64 tentativas (4^3) no banco de dados. Esse comportamento é indesejável quando o banco de dados está retornando esses erros porque está sobrecarregado.
- Use códigos de resposta claros e considere como os diferentes modos de falha devem ser tratados. Por exemplo, separe as condições de erro passíveis de recuperação das não recuperáveis. Não tente novamente erros permanentes ou solicitações malformadas em um cliente, porque nenhum dos dois terá sucesso. Retorne um status específico quando sobrecarregado para que os clientes e outras camadas recuem e não tentem novamente.
Em uma emergência, pode não ser óbvio que uma interrupção é devido a um mau comportamento de repetição. Gráficos de taxas de repetição podem ser uma indicação de mau comportamento de repetição, mas podem ser confundidos como um sintoma em vez de uma causa composta. Em termos de mitigação, este é um caso especial do problema de capacidade insuficiente, com a ressalva adicional de que você deve corrigir o comportamento de repetição (geralmente exigindo um push de código), reduzir a carga significativamente ou ainda cortar as solicitações por completo.
Latência e prazos
Quando um frontend envia um RPC para um servidor backend, o frontend consome recursos aguardando uma resposta. Os prazos de RPC definem quanto tempo uma solicitação pode esperar antes que o frontend desista, limitando o tempo que o backend pode consumir os recursos do frontend.
Escolhendo um prazo
Geralmente é aconselhável definir um prazo. A definição de nenhum prazo ou de um prazo extremamente alto pode causar problemas de curto prazo que já passaram há muito tempo para continuar a consumir recursos do servidor até que o servidor seja reiniciado.
Prazos altos podem resultar em consumo de recursos em níveis mais altos da stack quando os níveis mais baixos da stack estão tendo problemas. Prazos curtos podem fazer com que algumas requisições mais caras falhem de forma consistente. Equilibrar essas restrições para escolher um bom prazo pode ser considerada uma arte.
Prazos perdidos
Um tema comum em muitas interrupções em cascata é que os servidores gastam recursos tratando de solicitações que excederão seus prazos no cliente. Como resultado, os recursos são gastos enquanto nenhum progresso é feito: você não recebe crédito por atribuições atrasadas com RPCs.
Suponha que um RPC tenha um prazo de 10 segundos, conforme definido pelo cliente. O servidor está muito sobrecarregado e, como resultado, leva 11 segundos para passar de uma fila para um pool de threads. Neste ponto, o cliente já desistiu do pedido. Na maioria das circunstâncias, seria imprudente para o servidor tentar lidar com essa solicitação, porque estaria fazendo um trabalho para o qual nenhum crédito será concedido – o cliente não se importa com o trabalho que o servidor faz após o prazo ter passado, porque já desistiu do pedido.
Se o tratamento de uma solicitação for realizado em vários estágios (por exemplo, há alguns retornos de chamadas e chamadas RPC), o servidor deve verificar o prazo restante em cada etapa antes de tentar executar mais trabalho na requisição. Por exemplo, se uma requisição for dividida em etapas de análise, solicitação de backend e processamento, pode fazer sentido verificar se há tempo suficiente para lidar com a solicitação antes de cada etapa.
Propagação do prazo
Em vez de inventar um prazo final ao enviar RPCs para backends, os servidores devem empregar a propagação de prazo.
Com a propagação de prazo, um prazo é definido no alto da stack (por exemplo, no frontend). A árvore de RPCs que emanam de uma solicitação inicial terão todos o mesmo deadline absoluto. Por exemplo, se o servidor A selecionar um prazo de 30 segundos e processar a solicitação por 7 segundos antes de enviar um RPC ao servidor B, o RPC de A para B terá um prazo de 23 segundos. Se o servidor B demorar 4 segundos para processar a solicitação e enviar um RPC para o servidor C, o RPC de B para C terá um prazo de 19 segundos e assim por diante. Idealmente, cada servidor na árvore de solicitações deve implementar a propagação de prazos.
Sem a propagação de prazo, pode ocorrer o seguinte cenário:
- O servidor A envia um RPC ao servidor B com um prazo de 10 segundos.
- O servidor B leva 8 segundos para iniciar o processamento da solicitação e, em seguida, envia um RPC para o servidor C.
- Se o servidor B usa propagação de prazo, ele deve definir um prazo de 2 segundos, mas suponha que, em vez disso, use um prazo de 20 segundos codificado para o RPC para o servidor C.
- O servidor C retira a solicitação de sua fila após 5 segundos.
Se o servidor B tivesse usado a propagação de prazo, o servidor C poderia desistir imediatamente da solicitação porque o prazo de 2 segundos foi excedido. No entanto, neste cenário, o servidor C processa a solicitação pensando que tem 15 segundos de sobra, mas não está fazendo um trabalho útil, pois a solicitação do servidor A para o servidor B já ultrapassou seu prazo.
Você pode querer reduzir um pouco o prazo de saída (por exemplo, algumas centenas de milissegundos) para levar em conta os tempos de trânsito da rede e o pós-processamento no cliente.
Considere também definir um limite superior para prazos de saída. Você pode querer limitar quanto tempo o servidor espera por RPCs de saída para backends não críticos ou por RPCs para backends que normalmente são concluídos em um curto período. No entanto, certifique-se de entender sua combinação de tráfego, pois, de outra forma, você pode inadvertidamente fazer com que determinados tipos de requisições falhem o tempo todo (por exemplo, requisições com grandes cargas úteis ou requisições que exigem resposta a muitos cálculos).
Existem algumas exceções para as quais os servidores podem desejar continuar processando uma solicitação após o término do prazo. Por exemplo, se um servidor recebe uma requisição que envolve a execução de alguma operação de recuperação cara e periodicamente verifica o andamento da recuperação, seria uma boa ideia verificar o prazo somente após escrever o ponto de verificação, em vez de após processar a operação onerosa.
Propagação de cancelamento
A propagação de cancelamentos reduz o trabalho desnecessário ou condenado ao avisar os servidores em uma stack de chamadas RPC que seus esforços não são mais necessários. Para reduzir a latência, alguns sistemas usam “solicitações protegidas” para enviar RPCs para um servidor primário e, algum tempo depois, enviar a mesma solicitação para outras instâncias do mesmo serviço, caso o servidor primário seja lento para responder; uma vez que o cliente tenha recebido uma resposta de qualquer servidor, ele envia mensagens para os outros servidores para cancelar as solicitações agora supérfluas. Essas solicitações podem se espalhar de forma transitiva para muitos outros servidores, portanto, os cancelamentos devem ser propagados por toda a stack.
Essa abordagem também pode ser usada para evitar o vazamento potencial que ocorre se um RPC inicial tiver um prazo longo, mas os RPCs críticos subsequentes entre camadas mais profundas da stack receberem erros que não podem ser bem-sucedidos na repetição ou têm prazos curtos e tempo limite. Usando apenas a propagação de prazo simples, a chamada inicial continua a usar os recursos do servidor até atingir o tempo limite, apesar de estar fadada ao fracasso. O envio de erros fatais ou timeouts na stack e o cancelamento de outros RPCs na árvore de chamadas evita o trabalho desnecessário se a solicitação como um todo não puder ser atendida.
Latência bimodal
Suponha que o frontend do exemplo anterior consista em 10 servidores, cada um com 100 threads de trabalho. Isso significa que o frontend tem um total de 1.000 threads de capacidade. Durante a operação normal, os frontends executam 1.000 QPS e as solicitações são concluídas em 100 ms. Isso significa que os frontends geralmente têm 100 threads de trabalho ocupadas das 1.000 threads de trabalho configuradas (ou seja, 1.000 QPS * 0,1 segundos).
Suponha que um evento faça com que 5% das requisições nunca sejam concluídas. Isso pode ser o resultado da indisponibilidade de alguns intervalos de linhas do Bigtable, o que torna as requisições correspondentes a esse keyspace do Bigtable sem a possibilidade de serem atendidas. Como resultado, 5% das solicitações atingem o tempo de conclusão, enquanto os 95% restantes das solicitações demoram os habituais 100 ms.
Com um prazo de 100 segundos, 5% das solicitações consumiriam 5.000 threads (50 QPS * 100 segundos), mas o frontend não tem tantas threads disponíveis. Supondo que não haja outros efeitos secundários, o frontend só será capaz de lidar com 19,6% das solicitações (1.000 threads disponíveis / (5.000 + 95) threads de trabalho), resultando em uma taxa de erro de 80,4%.
Portanto, em vez de apenas 5% das solicitações receberem um erro (aquelas que não foram concluídas devido à indisponibilidade do keyspace), a maioria das solicitações recebe um erro.
As diretrizes a seguir podem ajudar a resolver essa classe de problemas:
- Detectar esse problema pode ser muito difícil. Em particular, pode não estar claro que a latência bimodal é a causa de uma interrupção quando você está analisando a latência média. Quando você observar um aumento de latência, tente observar a distribuição de latências além das médias.
- Esse problema pode ser evitado se as requisições que não forem concluídas retornarem com um erro antes, ao invés de esperar o prazo completo. Por exemplo, se um backend não estiver disponível, geralmente é melhor retornar imediatamente um erro para esse backend, em vez de consumir recursos até que o backend esteja disponível. Se a sua camada RPC suportar uma opção fail-fast, use-a.
- Ter prazos várias ordens de magnitude maiores do que a latência média de solicitação geralmente é ruim. No exemplo anterior, um pequeno número de solicitações atingiu inicialmente o prazo, mas o prazo foi três ordens de grandeza maior do que a latência média normal, levando ao esgotamento da thread.
- Ao usar recursos compartilhados que podem ser esgotados por algum keyspace, considere limitar as solicitações em andamento por esse keyspace ou usar outros tipos de rastreamento de abuso. Suponha que seu backend processe solicitações para clientes diferentes que têm desempenho e características de solicitação muito diferentes. Você pode considerar permitir que apenas 25% das suas threads sejam ocupadas por qualquer cliente para que haja um equilíbrio diante da carga pesada de qualquer cliente que se comporte mal.
Inicialização lenta e cache a frio
Os processos geralmente são mais lentos para responder às requisições imediatamente tão logo iniciam do que estão em estado estável. Essa lentidão pode ser causada por uma ou ambas as opções abaixo:
Inicialização necessária
Configurando conexões ao receber a primeira solicitação que precisa de um determinado backend
Melhorias de desempenho em tempo de execução em algumas linguagens, principalmente Java
Compilação Just-In-Time, otimização de hotspot e carregamento de classe adiado.
Da mesma forma, alguns binários são menos eficientes quando os caches não são preenchidos. Por exemplo, no caso de alguns serviços do Google, a maioria das solicitações é atendida fora dos caches, portanto, as solicitações que perdem o cache são significativamente mais caras. Na operação de estado estável com um cache quente, ocorrem apenas algumas falhas de cache, mas quando o cache está completamente vazio, 100% das solicitações são caras. Outros serviços podem empregar caches para manter o estado de um usuário na RAM. Isso pode ser feito através de aderência rígida ou suave entre proxies reversos e frontends de serviço.
Se o serviço não for provisionado para lidar com solicitações de cache frio, ele corre maior risco de interrupções e deve tomar medidas para evitá-las.
Os seguintes cenários podem levar a um cache frio:
Ativando um novo cluster
Um cluster adicionado recentemente terá um cache vazio.
Retornando um cluster ao serviço após a manutenção
O cache pode estar obsoleto.
Reinicializações
Se uma tarefa com cache foi reiniciada recentemente, o preenchimento do cache levará algum tempo. Pode valer a pena mover o cache de um servidor para um binário separado como o memcache, que também permite o compartilhamento de cache entre muitos servidores, embora ao custo de introduzir outro RPC e uma pequena latência adicional.
Se o armazenamento em cache tiver um efeito significativo no serviço, convém usar uma ou algumas das seguintes estratégias:
- Superprovisionar o serviço. É importante observar a distinção entre um cache de latência versus um cache de capacidade: quando um cache de latência é empregado, o serviço pode sustentar sua carga esperada com um cache vazio, mas um serviço que usa um cache de capacidade não pode sustentar sua carga esperada com um cache vazio. Os proprietários de serviço devem estar atentos ao adicionar caches ao serviço e certificar-se de que quaisquer novos caches sejam caches de latência ou sejam suficientemente bem projetados para funcionar com segurança como caches de capacidade. Às vezes, os caches são adicionados a um serviço para melhorar o desempenho, mas na verdade acabam sendo dependências rígidas.
- Empregar técnicas gerais de prevenção de falhas em cascata. Em particular, os servidores devem rejeitar solicitações quando estiverem sobrecarregados ou entrar em modos degradados, e os testes devem ser realizados para ver como o serviço se comporta após eventos como uma grande reinicialização.
- Ao adicionar carga a um cluster, aumente a carga lentamente. A taxa de solicitação inicialmente pequena aquece o cache; uma vez que o cache está quente, mais tráfego pode ser adicionado. É uma boa ideia garantir que todos os clusters carreguem carga nominal e que os caches sejam mantidos aquecidos.
Observação: Às vezes, você descobre que uma proporção significativa de sua capacidade real de atendimento é uma função de serviço a partir de um cache e, se você perdesse o acesso a esse cache, não seria capaz de atender a tantas consultas. Uma observação semelhante vale para a latência: um cache pode ajudar a atingir metas de latência (reduzindo o tempo médio de resposta quando a consulta pode ser veiculada a partir do cache) que você possivelmente não poderia atender sem esse cache.
Sempre siga em direção descendente na stack
No serviço Shakespeare de exemplo, o frontend fala com um backend, que por sua vez fala com a camada de armazenamento. Um problema que se manifesta na camada de armazenamento pode causar problemas para os servidores que se comunicam com ela, mas a correção da camada de armazenamento geralmente repara as camadas de backend e frontend.
No entanto, suponha que os backends se comuniquem entre si. Por exemplo, os backends podem fazer proxy de solicitações entre si para alterar quem é o proprietário de um usuário quando a camada de armazenamento não puder atender a uma solicitação. Essa comunicação intra-camada pode ser problemática por vários motivos:
- A comunicação é suscetível a um deadlock distribuído. Os backends podem usar o mesmo pool de threads para aguardar RPCs enviados para backends remotos que estão recebendo simultaneamente solicitações de backends remotos. Suponha que o pool de threads do backend A esteja cheio. O backend B envia uma solicitação ao backend A e usa uma thread no backend B até que o pool de thread do backend A esteja limpo. Esse comportamento pode fazer com que a saturação do pool de threads se espalhe.
- Se a comunicação intracamada aumentar em resposta a algum tipo de falha ou condição de carga pesada (por exemplo, reequilíbrio de carga que é mais ativo sob alta carga), a comunicação intracamada pode alternar rapidamente de um modo de solicitação intracamada baixa para alta quando a carga aumenta o suficiente. Por exemplo, suponha que um usuário tenha um backend primário e um backend secundário de hot standby predeterminado em um cluster diferente que possa assumir o controle do usuário. Os proxies de backend primários solicitam ao backend secundário como resultado de erros da camada inferior ou em resposta a uma carga pesada na master. Se todo o sistema estiver sobrecarregado, o proxy primário para secundário provavelmente aumentará e adicionará ainda mais carga ao sistema, devido ao custo adicional de analisar e aguardar a solicitação para o secundário no primário.
Dependendo da criticidade da comunicação entre camadas, a inicialização do sistema pode se tornar mais complexa. Geralmente é melhor evitar a comunicação intracamada – ou seja, possíveis ciclos no caminho de comunicação – no caminho de solicitação do usuário. Em vez disso, faça com que o cliente opere a comunicação. Por exemplo, se um frontend falar com um backend, mas adivinhar o backend errado, o backend não deve fazer o proxy para o backend correto. Em vez disso, o backend deve informar ao frontend para tentar novamente sua solicitação no backend correto.
Condições de acionamento para falhas em cascata
Quando um serviço é suscetível a falhas em cascata, existem vários distúrbios possíveis que podem iniciar o efeito dominó. Este tópico identifica alguns dos fatores que desencadeiam falhas em cascata.
Processo de “Query of Death”
Algumas tarefas do servidor podem morrer, reduzindo a quantidade de capacidade disponível. As tarefas podem morrer devido a uma Query of Death (um RPC cujo conteúdo desencadeia uma falha no processo), problemas de cluster, falhas de asserção ou vários outros motivos. Um evento muito pequeno (por exemplo, algumas falhas ou tarefas reprogramadas para outras máquinas) pode causar a interrupção de um serviço à beira de cair.
Atualizações do processo
O envio de uma nova versão do binário ou a atualização de sua configuração podem iniciar uma falha em cascata se um grande número de tarefas for afetado simultaneamente. Para evitar esse cenário, considere a sobrecarga de capacidade necessária ao configurar a infraestrutura de atualização do serviço ou empurre para fora do horário de pico. Ajustar dinamicamente o número de atualizações de tarefas em andamento com base no volume de solicitações e na capacidade disponível pode ser uma abordagem viável.
Novos lançamentos
Um novo binário, alterações de configuração ou uma alteração na stack de infraestrutura subjacente podem resultar em alterações nos perfis de solicitação, uso e limites de recursos, backends ou vários outros componentes do sistema que podem desencadear uma falha em cascata.
Durante uma falha em cascata, geralmente é aconselhável verificar as alterações recentes e revertê-las, principalmente se essas alterações afetaram a capacidade ou alteraram o perfil da solicitação.
Seu serviço deve implementar algum tipo de registro de alterações, que pode ajudar a identificar rapidamente as alterações recentes.
Crescimento orgânico
Em muitos casos, uma falha em cascata não é desencadeada por uma alteração de serviço específica, mas sim por um crescimento no uso que não foi acompanhado por um ajuste de capacidade.
Mudanças, drenos ou rejeições planejadas
Se seu serviço for multihome (ou seja, possui um host ou uma rede de computadores conectados a mais de uma rede), parte de sua capacidade pode estar indisponível devido a manutenção ou interrupções em um cluster. Da mesma forma, uma das dependências críticas do serviço pode ser drenada, resultando em uma redução na capacidade do serviço upstream – em qualquer interação HTTP, o serviço solicitante é downstream; o serviço de resposta é upstream – devido a dependências de drenagem, ou um aumento na latência devido à necessidade de enviar as solicitações para um cluster mais distante.
Solicitar alterações de perfil
Um serviço de backend pode receber solicitações de clusters diferentes porque um serviço de frontend mudou seu tráfego devido a alterações na configuração de balanceamento de carga, alterações na combinação de tráfego ou volume do cluster. Além disso, o custo médio para lidar com uma carga útil individual pode ter mudado devido a alterações no código do frontend ou na configuração. Da mesma forma, os dados tratados pelo serviço podem ter mudado organicamente devido ao uso crescente ou diferente pelos usuários existentes: por exemplo, o número e tamanho das imagens por usuário para um serviço de armazenamento de fotos tendem a aumentar com o tempo.
Limites de recursos
Alguns sistemas operacionais de cluster permitem o comprometimento excessivo de recursos. CPU é um recurso fungível; muitas vezes, algumas máquinas têm uma certa quantidade de CPU disponível, o que fornece uma rede de segurança contra picos de CPU. A disponibilidade dessa folga de CPU difere entre as células e também entre as máquinas dentro da célula.
Depender dessa folga de CPU como sua rede de segurança é perigoso. Sua disponibilidade depende inteiramente do comportamento dos outros trabalhos no cluster, portanto, ela pode cair repentinamente a qualquer momento. Por exemplo, se uma equipe iniciar um MapReduce que consome muita CPU e escala em muitas máquinas, a quantidade agregada de folga de CPU pode diminuir repentinamente e acionar condições de CPU starvation para trabalhos não relacionados. Portanto, ao realizar testes de carga, certifique-se de permanecer dentro dos limites de recursos confirmados.
Teste de falhas em cascata
As maneiras específicas pelas quais um serviço irá falhar podem ser muito difíceis de prever a partir dos primeiros princípios. Este tópico aborda estratégias de teste que podem detectar se os serviços são suscetíveis a falhas em cascata.
Você deve testar seu serviço para determinar como ele se comporta sob carga pesada para ganhar a confiança de que ele não entrará em uma falha em cascata sob várias circunstâncias.
Teste até a falha e além
Compreender o comportamento do serviço sob uma carga pesada talvez seja o primeiro passo mais importante para evitar falhas em cascata. Saber como seu sistema se comporta quando está sobrecarregado ajuda a identificar quais tarefas de engenharia são as mais importantes para correções de longo prazo; no mínimo, esse conhecimento pode ajudar a inicializar o processo de debug para engenheiros que estiverem de plantão quando surgir uma emergência.
Carregue os componentes de teste até que eles quebrem. À medida que a carga aumenta, um componente normalmente trata as requisições com sucesso até atingir um ponto em que não pode mais lidar com mais requisições. Nesse ponto, o componente deve começar a fornecer erros ou resultados degradados em resposta à carga adicional, mas não reduzir significativamente a taxa na qual ele trata as solicitações com êxito. Um componente que é altamente suscetível a uma falha em cascata começará a travar ou apresentar uma taxa muito alta de erros quando estiver sobrecarregado; um componente melhor projetado será capaz de rejeitar algumas requisições e sobreviver.
O teste de carga também revela onde está o ponto de ruptura, conhecimento fundamental para o processo de planejamento de capacidade. Ele permite que você teste regressões, provisione os limites do pior caso e negocie a utilização versus as margens de segurança.
Devido aos efeitos do cache, aumentar gradualmente a carga pode gerar resultados diferentes do que aumentar imediatamente para os níveis de carga esperados. Portanto, considere testar os padrões de carga gradual e de impulso.
Você também deve testar e entender como o componente se comporta ao retornar à carga nominal depois de ter sido forçado muito além dessa carga. Esses testes podem responder a perguntas como:
- Se um componente entrar em modo degradado com carga pesada, ele é capaz de sair do modo degradado sem intervenção humana?
- Se alguns servidores falharem sob carga pesada, quanto a carga precisa cair para que o sistema se estabilize?
Se você estiver testando a carga de um serviço com status ou um serviço que emprega armazenamento em cache, seu teste de carga deve rastrear o estado entre várias interações e verificar a correção em alta carga, que geralmente é onde ocorrem bugs sutis de simultaneidade.
Lembre-se de que componentes individuais podem ter pontos de ruptura diferentes, portanto, teste cada componente separadamente. Você não saberá de antemão qual componente pode atingir a ruptura primeiro, mas, antes, deseja saber como seu sistema se comporta quando isso acontecer.
Se você acredita que seu sistema possui proteções adequadas contra sobrecarga, considere realizar testes de falha em uma pequena fatia da produção para encontrar o ponto em que os componentes do sistema falham sob tráfego real. Esses limites podem não ser refletidos adequadamente pelo tráfego de teste de carga sintético, portanto, os testes de tráfego reais podem fornecer resultados mais realistas do que os testes de carga, com o risco de causar problemas visíveis ao usuário. Tenha cuidado ao testar em tráfego real: certifique-se de ter capacidade extra disponível caso suas proteções automáticas não funcionem e você precise fazer failover manualmente.
Considere alguns dos seguintes testes de produção:
- Redução da contagem de tarefas de forma rápida ou lenta ao longo do tempo, além dos padrões de tráfego esperados
- Perda rápida da capacidade de um cluster
- Blackholing de vários backends
Testar clientes populares
Entenda como grandes clientes usam seu serviço. Por exemplo, você quer saber se os clientes:
- Podem enfileirar o trabalho enquanto o serviço está inativo
- Usam a retirada exponencial aleatória em erros
- São vulneráveis a gatilhos externos que podem criar grandes quantidades de carga (por exemplo, uma atualização de software acionada externamente pode limpar o cache de um cliente offline)
Dependendo do seu serviço, você pode ou não estar no controle de todo o código do cliente que se comunica com o seu serviço. No entanto, ainda é boa ideia entender como os clientes grandes que interagem com o seu serviço se irão se comportar.
Os mesmos princípios se aplicam a grandes clientes internos. Teste as falhas do sistema com os maiores clientes para ver como eles reagem. Pergunte aos clientes internos como eles acessam seu serviço e quais mecanismos eles usam para lidar com falhas de backend.
Teste backends não críticos
Teste seus backends não críticos e certifique-se de que a indisponibilidade deles não interfira nos componentes críticos do seu serviço.
Por exemplo, suponha que seu frontend tenha backends críticos e não críticos. Muitas vezes, uma determinada requisição inclui componentes críticos (por exemplo, resultados da consulta) e componentes não críticos (por exemplo, sugestões de ortografia). Suas requisições podem desacelerar significativamente e consumir recursos aguardando a conclusão de backends não críticos.
Além de testar o comportamento quando o backend não crítico estiver indisponível, teste como o frontend se comporta se o backend não crítico nunca responder (por exemplo, se houver solicitações de blackholing). Os backends anunciados como não críticos ainda podem causar problemas nos frontends quando as requisições têm prazos longos. O frontend não deve começar a rejeitar muitas requisições, ficar sem recursos ou servir com latência muito alta quando um backend não crítico entra em buracos negros.
Etapas imediatas para solucionar falhas em cascata
Depois de identificar que seu serviço está passando por uma falha em cascata, você pode usar algumas estratégias diferentes para remediar a situação – e, claro, uma falha em cascata é uma boa oportunidade para usar seu protocolo de gerenciamento de incidentes (Capítulo 14).
Aumento de recursos
Se o seu sistema estiver funcionando com capacidade reduzida e você tiver recursos ociosos, adicionar tarefas pode ser a maneira mais conveniente de se recuperar da interrupção. No entanto, se o serviço entrou em uma espiral de morte de algum tipo, adicionar mais recursos pode não ser suficiente para recuperá-lo.
Interrupção de falhas/mortes na verificação de integridade
Alguns sistemas de agendamento de cluster, como o Borg, verificam a integridade das tarefas em um trabalho e reiniciam as tarefas que não estão íntegras. Essa prática pode criar um modo de falha no qual a própria verificação de integridade torna o serviço não íntegro. Por exemplo, se metade das tarefas não puder realizar nenhum trabalho porque estão sendo iniciadas e a outra metade será eliminada em breve porque estão sobrecarregadas e falhando nas verificações de integridade, desabilitar temporariamente as verificações de integridade pode permitir que o sistema se estabilize até que todas as tarefas estejam em execução.
A verificação da integridade do processo (“este binário está respondendo?”) e a verificação da integridade do serviço (“esse binário é capaz de responder a essa classe de solicitações agora?”) são duas operações conceitualmente distintas. A verificação de integridade do processo é relevante para o agendador de cluster, enquanto a verificação de integridade do serviço é relevante para o balanceador de carga. A distinção clara entre os dois tipos de verificações de integridade pode ajudar a evitar esse cenário.
Reinicialização de servidores
Se os servidores estiverem de alguma forma bloqueados e não estiverem progredindo, reiniciá-los pode ajudar. Tente reiniciar os servidores quando:
- Os servidores Java estiverem em uma espiral de morte do garbage collector
- Algumas solicitações em andamento não tiverem prazos, mas estiverem consumindo recursos, levando-as a bloquear threads, por exemplo
- Os servidores estiverem bloqueados
Certifique-se de identificar a origem da falha em cascata antes de reiniciar seus servidores. Certifique-se de que essa ação não irá simplesmente mudar a carga. Use o canary para esta mudança, e faça-o lentamente. Suas ações podem amplificar uma falha em cascata existente se a interrupção for realmente devido a um problema como um cache frio.
Queda de tráfego
A queda de carga é um grande martelo, geralmente reservado para situações em que você tem uma verdadeira falha em cascata em suas mãos e não pode consertá-la por outros meios. Por exemplo, se uma carga pesada fizer com que a maioria dos servidores falhe assim que estiverem íntegros, você poderá colocar o serviço em funcionamento novamente ao:
- Abordar a condição de acionamento inicial (adicionando capacidade, por exemplo).
- Reduzir a carga o suficiente para que o travamento pare. Considere ser agressivo aqui – se todo o serviço estiver em loop de falha, permita apenas, digamos, 1% do tráfego.
- Permitir que a maioria dos servidores se tornem íntegros.
- Aumentar gradualmente a carga.
Essa estratégia permite o aquecimento dos caches, o estabelecimento de conexões etc., antes que a carga retorne aos níveis normais.
Obviamente, essa tática causará muitos danos visíveis ao usuário. Se você pode ou não (ou mesmo se deve) descartar o tráfego indiscriminadamente depende de como o serviço está configurado. Se você tiver algum mecanismo para descartar tráfego menos importante (por exemplo, usando prefetching), use esse mecanismo primeiro.
É importante ter em mente que essa estratégia permite que você se recupere de uma interrupção em cascata assim que o problema subjacente for corrigido. Se o problema que iniciou a falha em cascata não for corrigido (por exemplo, capacidade global insuficiente), a falha em cascata poderá ser acionada logo após o retorno de todo o tráfego. Portanto, antes de usar essa estratégia, considere corrigir (ou pelo menos ocultar) a causa raiz ou a condição de acionamento. Por exemplo, se o serviço ficou sem memória e agora está em uma espiral de morte, adicionar mais memória ou tarefas deve ser o primeiro passo.
Entrar em modos degradados
Sirva resultados degradados fazendo menos trabalho ou eliminando tráfego sem importância. Essa estratégia deve ser projetada em seu serviço e pode ser implementada somente se você souber qual tráfego pode ser degradado e tiver a capacidade de diferenciar entre as várias cargas úteis.
Eliminar a carga em lote
Alguns serviços têm carga importante, mas não crítica. Considere desligar essas fontes de carga. Por exemplo, se atualizações de índice, cópias de dados ou coleta de estatísticas consumirem recursos do caminho de serviço, considere desativar essas fontes de carga durante uma interrupção.
Elimine o tráfego ruim
Se algumas consultas estiverem criando carga pesada ou travamentos (por exemplo, consultas de morte), considere bloqueá-las ou eliminá-las por outros meios.
Falha em cascata e Shakespeare
Um documentário sobre as obras de Shakespeare vai ao ar no Japão e aponta explicitamente para o nosso serviço Shakespeare como um excelente local para realizar pesquisas adicionais. Após a transmissão, o tráfego para nosso datacenter asiático aumenta além da capacidade do serviço. Esse problema de capacidade é agravado por uma grande atualização no serviço Shakespeare que ocorre simultaneamente nesse datacenter.
Felizmente, existem várias salvaguardas que ajudam a mitigar o potencial de falha. O processo “The Production Readiness Review” – que examina um programa para determinar se o projeto está pronto para produção e se foi realizado um planejamento e processo de produção adequados – identificou alguns problemas que a equipe já havia abordado. Por exemplo, os desenvolvedores criaram uma degradação elegante no serviço. À medida que a capacidade se torna escassa, o serviço não retorna mais imagens ao lado de texto ou pequenos mapas que ilustram onde uma história ocorre. E dependendo de sua finalidade, um RPC que expira ou não é repetido (por exemplo, no caso das imagens acima mencionadas) ou é repetido com uma retirada exponencial aleatória. Apesar dessas salvaguardas, as tarefas falham uma a uma e são reiniciadas pelo Borg, o que reduz ainda mais o número de tarefas em andamento.
Como resultado, alguns gráficos no painel de serviço ficam com um tom alarmante de vermelho e o SRE é acionado. Em resposta, os SREs adicionam capacidade temporariamente ao datacenter asiático aumentando o número de tarefas disponíveis para o trabalho do Shakespeare. Ao fazer isso, eles podem restaurar o serviço do Shakespeare no cluster asiático.
Depois, a equipe de SRE escreve um postmortem detalhando a cadeia de eventos, o que correu bem, o que poderia ter corrido melhor e vários itens de ação para evitar que esse cenário ocorra novamente. Por exemplo, no caso de uma sobrecarga de serviço, o balanceador de carga GSLB irá redirecionar parte do tráfego para datacenters vizinhos. Além disso, a equipe SRE ativa o escalonamento automático, para que o número de tarefas aumente automaticamente com o tráfego, e para que eles não precisem se preocupar com esse tipo de problema novamente.
Observações Finais
Quando os sistemas estão sobrecarregados, algo precisa ser dado em troca para remediar a situação. Depois que um serviço passa do ponto de interrupção, é melhor permitir que alguns erros visíveis ao usuário ou resultados de qualidade inferior passem do que tentar atender totalmente a todas as solicitações. Entender onde estão esses pontos de interrupção e como o sistema se comporta além deles é fundamental para os proprietários de serviços que desejam evitar falhas em cascata.
Sem os devidos cuidados, algumas alterações no sistema destinadas a reduzir erros em segundo plano ou a melhorar o estado estável do sistema podem expor o serviço a um risco maior de interrupção total. Tentar novamente em caso de falhas, deslocar a carga de servidores não íntegros, eliminar servidores íntegros, adicionar caches para melhorar o desempenho ou reduzir a latência: tudo isso pode ser implementado para aprimorar o estado normal, mas pode aumentar a chance de causar uma falha em grande escala. Tenha cuidado ao avaliar as alterações para garantir que uma interrupção não seja trocada por outra.
Fonte: Google SRE Book