Escrito por Raymond Blum and Rhandeev Singh
Editado por Betsy Beyer
O que é “integridade de dados”? Quando os usuários estão em primeiro lugar, a integridade de dados é o que os usuários pensam que é.
Poderíamos dizer que a integridade de dados é uma medida da acessibilidade e precisão dos datastores necessários para fornecer aos usuários um nível de serviço adequado. Mas esta definição é insuficiente.
Por exemplo, se um bug de interface do usuário no Gmail exibir uma caixa de entrada vazia durante muito tempo, os usuários podem acreditar que os dados se perderam. Assim, mesmo que nenhum dado fosse realmente perdido, o mundo questionaria a capacidade do Google de agir como um administrador responsável de dados, e a viabilidade da computação em nuvem estaria ameaçada. Se o Gmail exibisse uma mensagem de erro ou de manutenção durante muito tempo enquanto “apenas um pouco de metadados” fosse reparado, a confiança dos usuários do Google igualmente diminuiria.
Quanto tempo é “demasiado longo” para que os dados não estejam disponíveis? Como demonstrado por um incidente real com o Gmail em 2011 quatro dias é um longo tempo – talvez “demasiado longo”. Subsequentemente, acreditamos que 24 horas é um bom ponto de partida para estabelecer o limite de “demasiado tempo” para os Apps do Google.
Raciocínio semelhante se aplica a aplicativos como Google Photos, Drive, Cloud Storage, e Cloud Datastore, porque os usuários não fazem necessariamente uma distinção entre estes produtos discretos (raciocinando, “este produto ainda é Google” ou “Google, Amazon, o que quer que seja; este produto ainda é parte da nuvem”). Perda de dados, corrupção de dados e indisponibilidade prolongada são tipicamente indistinguíveis para os usuários. Por conseguinte, a integridade dos dados aplica-se a todos os tipos de dados em todos os serviços. Ao considerar a integridade dos dados, o que importa é que os serviços na nuvem permaneçam acessíveis aos usuários. O acesso dos usuários aos dados é especialmente importante.
Requisitos rigorosos de integridade dos dados
Ao considerar as necessidades de confiabilidade de um determinado sistema, pode parecer que as necessidades de tempo de atividade (disponibilidade de serviço) são mais rigorosas do que as da integridade dos dados. Por exemplo, os usuários podem considerar inaceitável uma hora de inatividade de e-mail, ao passo que podem viver irritados com uma janela de tempo de quatro dias para recuperar uma caixa de entrada. No entanto, há uma forma mais apropriada de considerar as exigências de tempo de atividade versus a integridade dos dados.
Um SLO de 99,99% de tempo de atividade deixa espaço para apenas uma hora de inatividade durante um ano inteiro. Este SLO estabelece um padrão bastante alto, que provavelmente excede as expectativas da maioria dos usuários da Internet e da Empresa.
Em contraste, um SLO de 99,99% de bons bytes num artefato de 2 GB tornaria os documentos, executáveis, e banco de dados corrompidos (até 200 KB ilegíveis). Esta quantidade de corrupção é catastrófica na maioria dos casos – resultando em executáveis com opcodes aleatórios e bancos de dados completamente descarregáveis.
Da perspectiva do usuário, então, cada serviço tem requisitos independentes de tempo de atividade e integridade de dados, mesmo que estes requisitos estejam implícitos. O pior momento para discordar dos usuários sobre estes requisitos é após o desaparecimento dos seus dados!

Figure 26-1.
Para rever a nossa definição anterior de integridade de dados, podemos dizer que a integridade dos dados significa que os serviços na nuvem permanecem acessíveis aos usuários. O acesso dos usuários aos dados é especialmente importante, portanto, este acesso deve permanecer em perfeitas condições.
Agora, suponha que um artefato fosse corrompido ou perdido exatamente uma vez por ano. Se a perda fosse irrecuperável, o tempo de funcionamento do artefato afetado seria perdido para esse ano. O meio mais provável de evitar tal perda é através de uma detecção proativa, associada a uma reparação rápida.
Em um universo alternativo, suponha que a corrupção foi detectada imediatamente antes que os usuários fossem afetados e que o artefato foi removido, corrigido e devolvido ao serviço em meia hora. Ignorando qualquer outro tempo de inatividade durante esses 30 minutos, esse objeto estaria 99,99% disponível naquele ano.
Surpreendentemente, pelo menos na perspectiva do usuário, neste cenário, a integridade dos dados ainda é 100% (ou próxima dos 100%) durante a vida útil acessível do objeto. Como demonstrado por este exemplo, o segredo para a integridade superior dos dados é a detecção proativa e a rápida reparação e recuperação.
Escolhendo uma estratégia para a integridade superior dos dados
Há muitas estratégias possíveis para a detecção rápida, reparação e recuperação de dados perdidos. Todas estas estratégias trocam tempo de atividade contra a integridade dos dados no que diz respeito aos usuários afetados. Algumas estratégias funcionam melhor do que outras, e algumas estratégias requerem investimentos de engenharia mais complexos do que outras. Com tantas opções disponíveis, que estratégias devem ser utilizadas? A resposta depende do seu paradigma de computação.
A maioria dos aplicativos de computação em nuvem busca otimizar alguma combinação de tempo de atividade, latência, escala, velocidade e privacidade. Para fornecer uma definição funcional para cada um desses termos:
Tempo de atividade
Também referida como disponibilidade, a proporção de tempo que um serviço é utilizável pelos seus usuários.
Latência
Até que ponto um serviço parece responder aos seus usuários.
Escala
O volume de usuários de um serviço e a mistura de cargas de trabalho que o serviço pode suportar antes que a latência sofra ou que o serviço se desfaça.
Velocidade
A rapidez com que um serviço pode inovar para proporcionar aos usuários um valor superior a um custo razoável.
Privacidade
Este conceito impõe requisitos complexos. Como simplificação, este capítulo limita o seu âmbito na discussão da privacidade à eliminação de dados: os dados devem ser destruídos dentro de um prazo razoável depois de os usuários os eliminarem.
Muitos aplicativos de nuvem evoluem continuamente sobre uma mistura de APIs ACID e BASE para satisfazer as exigências destes cinco componentes. A BASE permite uma maior disponibilidade do que o ACID, em troca de uma garantia de consistência distribuída mais suave. Especificamente, a BASE apenas garante que uma vez que um dado deixe de ser atualizado, o seu valor acabará por se tornar consistente em todos os locais de armazenamento (potencialmente distribuídos).
O cenário seguinte fornece um exemplo de como as trocas entre tempo de atividade, latência, escala, velocidade e privacidade podem funcionar.
Quando a velocidade supera outros requisitos, os aplicativos resultantes dependem de uma coleção arbitrária de APIs que são mais familiares aos desenvolvedores específicos que trabalham no aplicativo.
Por exemplo, um aplicativo pode tirar proveito de uma API de armazenamento BLOB125 eficiente, como o Blobstore, que negligencia a consistência distribuída em favor do dimensionamento para cargas de trabalho pesadas com alto tempo de atividade, baixa latência e baixo custo. Para compensar:
- O mesmo aplicativo pode confiar pequenas quantidades de metadados autorizados relativos aos seus blobs a uma latência mais elevada, menos disponível, serviço mais dispendioso baseado em Paxos como o Megastore.
- Certos clientes do aplicativo podem armazenar em cache alguns desses metadados localmente e acessar blobs diretamente, reduzindo a latência ainda mais do ponto de vista dos usuários.
- Outro aplicativo pode manter metadados em Bigtable, sacrificando uma forte consistência distribuída porque os seus criadores estavam familiarizados com Bigtable.
Esses aplicativos em nuvem enfrentam uma variedade de desafios de integridade de dados em tempo de execução, tais como a integridade referencial entre datastores (no exemplo anterior, Blobstore, Megastore, e caches do lado do cliente). Os caprichos da alta velocidade determinam que mudanças de esquema, migrações de dados, empilhamento de novos recursos em cima de recursos antigos, reescritas e pontos de integração em evolução com outros aplicativos conspiram para produzir um ambiente repleto de relacionamentos complexos entre vários dados que nenhum único engenheiro consegue explorar completamente.
Para evitar que os dados desse aplicativo se degradem diante dos olhos de seus usuários, é necessário um sistema de verificações e balanços fora de banda dentro e entre seus datastores. Terceira camada: Detecção Precoce discute um sistema deste tipo.
Além disso, se tal aplicativo se baseia em backups independentes e descoordenados de vários datastores (no exemplo anterior, Blobstore e Megastore), então a sua capacidade de fazer uma utilização eficaz dos dados restaurados durante um esforço de recuperação de dados é complicada pela variedade de relações entre os dados restaurados e os dados ativos. Nosso aplicativo de exemplo teria de ordenar e distinguir entre Blobs restaurados versus Megastore ativos, Megastore restaurado versus Blobs ativos, Blobs restaurados versus Megastore restaurado, e interações com caches do lado do cliente.
Considerando essas dependências e complicações, quantos recursos devem ser investidos em esforços de integridade de dados e onde?
Backups (Versus) Archives
Tradicionalmente, as empresas “protegem” os dados contra perdas, investindo em estratégias de backup. No entanto, o verdadeiro foco desses esforços de backup deve ser a recuperação de dados, o que distingue os backups reais dos archives. Como é por vezes observado: Ninguém quer realmente fazer backups; o que as pessoas realmente querem são restaurações.
O seu “backup” é realmente um archive, e não apropriado para uso em recuperação de desastres?

Figure 26-2.
A diferença mais importante entre backups e archives é que os backups podem ser carregados de volta para um aplicativo, enquanto que os archives não podem. Portanto, os backups e os archives têm casos de utilização bastante diferentes.
Archives protege os dados durante longos períodos de tempo para satisfazer as necessidades de auditoria, descoberta e conformidade. A recuperação de dados para tais fins geralmente não precisa ser concluída dentro dos requisitos de tempo de atividade de um serviço. Por exemplo, pode ser necessário reter dados de transações financeiras durante sete anos. Para atingir esse objetivo, você pode mover os logs de auditoria acumulados para armazenamento de arquivamento de longo prazo em um local externo uma vez por mês. A recuperação e restauração dos logs durante uma auditoria financeira de um mês pode demorar uma semana, e esta janela de tempo de uma semana para recuperação pode ser aceitável para um archive.
Por outro lado, quando ocorre uma catástrofe, os dados devem ser recuperados rapidamente a partir de backups reais, de preferência bem dentro das necessidades de tempo de atividade de um serviço. Caso contrário, os usuários afetados ficarão sem acesso útil ao aplicativo desde o início do problema de integridade de dados até a conclusão do esforço de recuperação.
É também importante considerar que, uma vez que os dados mais recentes estão em risco até que seja efetuado um backup seguro, pode ser ideal programar backups reais (ao invés de archives) para ocorrerem diariamente, de hora a hora, ou com maior frequência, utilizando abordagens completas e incrementais ou contínuas (streaming).
Portanto, ao formular uma estratégia de backup, considere a rapidez com que precisa se recuperar de um problema, e a quantidade de dados recentes que se pode dar ao luxo de perder.
Requisitos do Ambiente Cloud em Perspectiva
Os ambientes de cloud introduzem uma combinação única de desafios técnicos:
- Se o ambiente utilizar uma mistura de soluções de backup e restauração transacionais e não transacionais, os dados recuperados não serão necessariamente corretos.
- Se os serviços tiverem de evoluir sem necessidade de manutenção, diferentes versões da lógica empresarial podem atuar sobre os dados em paralelo.
- Se os serviços de interação forem versionados independentemente, as versões incompatíveis de diferentes serviços podem interagir momentaneamente, aumentando ainda mais a possibilidade de corrupção acidental de dados ou perda de dados.
Além disso, a fim de manter a economia de escala, os prestadores de serviços devem fornecer apenas um número limitado de APIs. Estes APIs devem ser simples e fáceis de utilizar para a grande maioria dos aplicativos, ou poucos clientes irão utilizá-los. Ao mesmo tempo, os APIs devem ser suficientemente robustos para compreenderem o seguinte:
- Localidade e cache de dados
- Distribuição local e global de dados
- Consistência forte e/ou eventual
- Durabilidade, backup, e recuperação de dados
Caso contrário, clientes sofisticados não podem migrar aplicativos para a cloud, e aplicativos simples que se tornam complexos e grandes necessitarão de reescritas completas a fim de utilizar APIs diferentes e mais complexos.
Os problemas surgem quando as características de API anteriores são utilizadas em determinadas combinações. Se o prestador de serviços não resolver estes problemas, então os aplicativos que se depararem com estes desafios devem identificá-los e resolvê-los independentemente.
Objetivos do Google SRE na Manutenção da Integridade e Disponibilidade dos Dados
Embora o objetivo da SRE de “manter a integridade dos dados persistentes” seja uma boa visão, prosperamos em objetivos concretos com indicadores mensuráveis. A SRE define métricas chave que utilizamos para estabelecer expectativas para as capacidades dos nossos sistemas e processos através de testes e para acompanhar o seu desempenho durante um evento real.
A integridade dos dados é o meio; a disponibilidade de dados é o objetivo
A integridade dos dados refere-se à precisão e consistência dos dados ao longo da sua vida útil. Os usuários precisam saber que as informações estarão corretas e não serão alteradas de maneira inesperada desde o momento em que são registradas pela primeira vez até a última vez em que são observadas. Mas será que tal garantia é suficiente?
Considere o caso de um fornecedor de e-mail que sofreu um interrupção de dados de uma semana. No espaço de 10 dias, os usuários tiveram de encontrar outros métodos temporários de conduzir os seus negócios com a expectativa de em breve voltarem às suas contas de e-mail estabelecidas, identidades, e histórias acumuladas.
Depois, chegaram as piores notícias possíveis: o fornecedor anunciou que, apesar das expectativas anteriores, o acervo de e-mail e de contatos passados foi de fato evaporado e nunca mais seria visto. Parecia que uma série de contratempos na gestão da integridade dos dados tinha conspirado para deixar o prestador de serviços sem backups utilizáveis. Os usuários furiosos ou ficaram presos às suas identidades provisórias ou estabeleceram novas identidades, abandonando o seu antigo e perturbado fornecedor de e-mail.
Mas esperem! Vários dias após a declaração de perda absoluta, o fornecedor anunciou que as informações pessoais dos usuários poderiam ser recuperadas. Não houve perda de dados; isto foi apenas uma interrupção. Tudo estava bem!
Só que, nem tudo estava bem. Os dados dos usuários tinham sido preservados, mas os dados não eram acessíveis pelas pessoas que precisavam deles durante demasiado tempo.
A moral deste exemplo: Do ponto de vista do usuário, a integridade dos dados sem a disponibilidade de dados esperada e regular é efetivamente o mesmo que não ter dados.
Fornecer um Sistema de Recuperação, em vez de um Sistema de Backup
Fazer backups é uma tarefa classicamente negligenciada, delegada, e adiada da administração do sistema. Os backups não são uma alta prioridade para ninguém – eles consomem tempo e recursos continuamente e não geram nenhum benefício visível imediato. Por esta razão, a falta de diligência na implementação de uma estratégia de backup é recebida com um revirar de olhos simpático. Pode-se argumentar que, tal como a maioria das medidas de proteção contra perigos de baixo risco, tal atitude é pragmática. O problema fundamental desta estratégia indiferente é que os perigos que ela implica podem ser de baixo risco, mas também são de alto impacto. Quando os dados do seu serviço não estão disponíveis, a sua resposta pode fazer ou quebrar o seu serviço, produto, e mesmo a sua empresa.
Em vez de nos concentrarmos no trabalho ingrato de fazer um backup, é muito mais útil, para não dizer mais fácil, motivar a participação nos backups, concentrando-nos numa tarefa com um pagamento visível: a restauração! Os backups são um imposto, pago numa base contínua pelo serviço municipal de garantia de disponibilidade de dados. Em vez de enfatizar o imposto, chame a atenção para o serviço dos fundos fiscais: a disponibilidade de dados. Não obrigamos as equipes a “praticar” os seus backups, em vez disso:
- As equipes definem objetivos de nível de serviço (SLOs) para a disponibilidade de dados numa variedade de modos de falha.
- Uma equipe pratica e demonstra a sua capacidade de atender a esses SLOs.
Tipos de falhas que levam à perda de dados
Como ilustrado pela Figura 26-3, a um nível muito elevado, existem 24 tipos distintos de falhas quando os 3 fatores podem ocorrer em qualquer combinação. Deverá considerar cada uma destas potenciais falhas ao conceber um programa de integridade de dados. Os fatores de falhas de integridade de dados são os seguintes:
Causa raiz
Uma perda irrecuperável de dados pode ser causada por uma série de fatores: ação do usuário, erro do operador, erros de aplicativos, defeitos nas infraestruturas, hardware defeituoso, ou catástrofes no local.
Extensão
Algumas perdas são generalizadas, afetando muitas entidades. Algumas perdas são estreitas e dirigidas, apagando ou corrompendo dados específicos a um pequeno subconjunto de usuários.
Proporção
Algumas perdas de dados são um evento big bang (por exemplo, 1 milhão de linhas são substituídas por apenas 10 linhas num único minuto), enquanto algumas perdas de dados estão rastejando (por exemplo, 10 linhas de dados são apagadas a cada minuto ao longo de semanas).
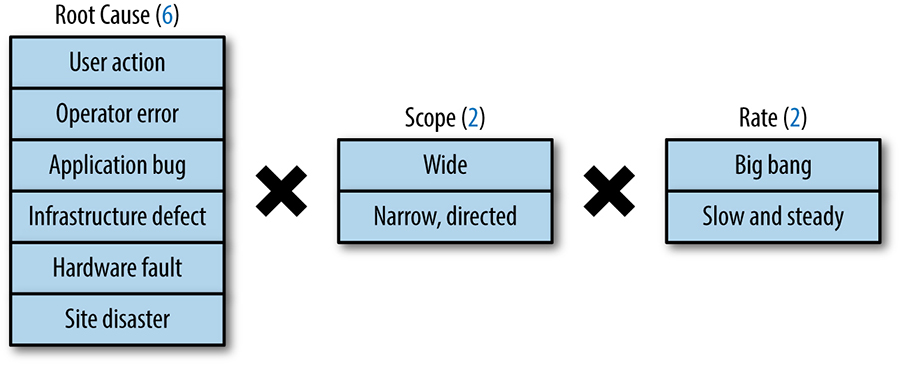
Figura 26-3. Os fatores dos modos de falha da integridade dos dados
Um plano de restauração eficaz deve ser responsável por qualquer um destes modos de falha que ocorram em qualquer combinação concebível. O que pode ser uma estratégia perfeitamente eficaz de proteção contra uma perda de dados causada por um bug de aplicativo rastejante pode não ter qualquer utilidade quando o seu datacenter de colocação pegar fogo.
Um estudo de 19 esforços de recuperação de dados no Google descobriu que os cenários de perda de dados visíveis pelo usuário mais comuns envolviam a eliminação de dados ou perda de integridade referencial causada por bugs de software. As variantes mais desafiantes envolviam corrupção ou eliminação de baixo grau que foi descoberta semanas a meses após os bugs terem sido lançados pela primeira vez no ambiente de produção. Por conseguinte, as salvaguardas que a Google emprega devem ser bem adequadas para prevenir ou se recuperar destes tipos de perda.
Para recuperar de tais cenários, um aplicativo grande e bem sucedido necessita recuperar dados para talvez milhões de usuários espalhados por dias, semanas, ou meses. O aplicativo também pode precisar recuperar cada artefato afetado em um único momento. Esse cenário de recuperação de dados é chamado de “recuperação pontual” fora do Google e “viagem no tempo” dentro do Google.
Uma solução de backup e recuperação que fornece recuperação pontual para um aplicativo em seus datastores ACID e BASE, ao mesmo tempo em que atende a metas rigorosas de tempo de atividade, latência, escalabilidade, velocidade e custo é uma quimera hoje!
Resolver esse problema com seus próprios engenheiros implica sacrificar a velocidade. Muitos projetos se comprometem adotando uma estratégia de backup em camadas sem recuperação pontual. Por exemplo, as APIs abaixo de seu aplicativo podem oferecer suporte a vários mecanismos de recuperação de dados. Os dispendiosos “snapshots” locais podem proporcionar uma proteção limitada contra bugs de aplicativos e oferecer uma funcionalidade de restauração rápida, portanto, poderá reter alguns dias de tais “snapshots” locais, tirados com várias horas de intervalo. Cópias completas e incrementais rentáveis de dois em dois dias podem ser retidas por mais tempo. A recuperação pontual é uma funcionalidade muito agradável de se ter se uma ou mais destas estratégias a suportarem.
Considere as opções de recuperação de dados fornecidas pelas APIs da nuvem que está prestes a utilizar. Negoceie a recuperação pontual contra uma estratégia escalonada, se necessário, mas não recorra à não utilização de nenhuma delas! Se puder ter ambas as funcionalidades, utilize ambas as funcionalidades. Cada uma destas características (ou ambas) será valiosa em algum momento.
Desafios da Manutenção da Integridade dos Dados Profundos e Amplos
Ao conceber um programa de integridade de dados, é importante reconhecer que a replicação e a redundância não são recuperabilidade.
Questões de escalonamento: Plenas, incrementais, e as forças concorrentes de backups e restaurações
Uma resposta clássica, mas imperfeita à pergunta “Tem um backup?” é “Temos algo ainda melhor do que uma réplica de backup!” A replicação oferece muitos benefícios, incluindo a localização dos dados e a proteção contra um desastre específico do site, mas não pode protegê-lo de muitas fontes de perda de dados. Os datastores que sincronizam automaticamente múltiplas réplicas garantem que uma linha de base de dados corrompida ou uma exclusão incorreta seja enviada para todas as suas cópias, provavelmente antes de poder isolar o problema.
Para responder a esta preocupação, poderá fazer cópias não servidas dos seus dados em algum outro formato, como exportações frequentes de bases de dados para um ficheiro nativo. Essa medida adicional acrescenta proteção contra os tipos de erros contra os quais a replicação não protege – erros do usuário e bugs da camada do aplicativo – mas não faz nada para proteger contra perdas introduzidas em uma camada inferior. Esta medida introduz também um risco de bugs durante a conversão de dados (em ambas as direções) e durante o armazenamento do ficheiro nativo, para além de possíveis desajustes na semântica entre os dois formatos. Imagine um ataque de dia zero em algum nível baixo da sua stack, tal como o sistema de ficheiros ou o driver de dispositivo. Quaisquer cópias que dependam do componente de software comprometido, incluindo as exportações da base de dados que foram escritas no mesmo sistema de ficheiros que suporta a sua base de dados, são vulneráveis.
Assim, vemos que a diversidade é fundamental: proteger contra uma falha na camada X exige o armazenamento de dados sobre diversos componentes nessa camada. O isolamento dos suportes protege contra falhas de mídia: é pouco provável que um bug ou um ataque num driver de dispositivo de disco afete as unidades de fita. Se pudéssemos, faríamos cópias de segurança dos nossos valiosos dados em placas de argila.
As forças da atualização dos dados e da conclusão da restauração competem com a proteção abrangente. Quanto mais abaixo a stack empurrar um snapshot dos seus dados, mais tempo levará para fazer uma cópia, o que significa que a frequência de cópias diminui. Ao nível da base de dados, uma transação pode levar a ordem de segundos para se replicar. A exportação de um snapshot da base de dados para o sistema de ficheiros por baixo pode demorar 40 minutos. Uma cópia de segurança completa do sistema de ficheiros subjacente pode demorar horas.
Neste cenário, pode perder até 40 minutos dos dados mais recentes ao restaurar a última cópia de segurança. Uma restauração a partir da cópia de segurança do sistema de ficheiros pode levar horas de transações ausentes. Além disso, a restauração provavelmente demora o mesmo tempo que a cópia de segurança, portanto o carregamento dos dados pode levar horas. Obviamente que gostaria de ter os dados mais recentes de volta o mais rapidamente possível, mas dependendo do tipo de falha, essa cópia mais recente e mais imediatamente disponível pode não ser uma opção.
Retenção
Retenção – durante quanto tempo se mantém cópias dos seus dados em redor – é mais um fator a considerar nos seus planos de recuperação de dados.
Embora seja provável que você ou seus clientes percebam rapidamente o esvaziamento repentino de um banco de dados inteiro, pode levar dias para que uma perda mais gradual de dados atraia a atenção da pessoa certa. Restaurar os dados perdidos neste último cenário requer snapshots mais antigos. Ao chegar até aqui, você provavelmente desejará mesclar os dados restaurados com o estado atual. Isso complica significativamente o processo de restauração.
Como o Google SRE Enfrenta os Desafios da Integridade dos Dados
À semelhança do nosso pressuposto de que os sistemas subjacentes da Google são propensos a falhas, assumimos que qualquer um dos nossos mecanismos de proteção está também sujeito às mesmas forças e pode falhar das mesmas formas e nos momentos mais inconvenientes. A manutenção de uma garantia de integridade dos dados em grande escala, um desafio ainda mais complicado pela elevada taxa de mudança dos sistemas de software envolvidos, requer uma série de práticas complementares mas desacopladas, cada uma delas escolhida para oferecer um elevado grau de proteção por si só.
As 24 Combinações de Modos de Falha de Integridade de Dados
Dadas as muitas formas como os dados podem ser perdidos (como descrito anteriormente), não há bala de prata que proteja contra as muitas combinações de modos de falha. Em vez disso, é necessária uma defesa em profundidade. A defesa em profundidade compreende várias camadas, com cada camada sucessiva de defesa conferindo proteção contra cenários de perda de dados progressivamente menos comuns. A figura 26-4 ilustra o percurso de um objeto desde a eliminação suave até à destruição, e as estratégias de recuperação de dados que devem ser empregadas ao longo deste percurso para assegurar uma defesa em profundidade.
A primeira camada é a eliminação suave (ou “Lazy deletion” no caso de ofertas de API de desenvolvimento), que provou ser uma defesa eficaz contra cenários de eliminação de dados inadvertidos. A segunda linha de defesa são os backups e os seus métodos de recuperação relacionados. A terceira e última camada é a validação regular de dados, coberta pela terceira camada: Detecção precoce. Através de todas estas camadas, a presença de replicação é ocasionalmente útil para a recuperação de dados em cenários específicos (embora os planos de recuperação de dados não devam basear-se na replicação).

Figura 26-4. O percurso de um objeto desde a eliminação suave até à destruição
Primeira camada: Eliminação suave
Quando a velocidade é elevada e a privacidade é importante, os bugs nos aplicativos são responsáveis pela grande maioria dos eventos de perda e corrupção de dados. Na verdade, os bugs de eliminação de dados podem se tornar tão comuns que a capacidade de recuperar dados por um tempo limitado se torna a principal linha de defesa contra a maioria das perdas de dados permanentes e inadvertidas.
Qualquer produto que sustente a privacidade dos seus usuários deve permitir aos usuários apagar subconjuntos selecionados e/ou todos os seus dados. Tais produtos incorrem num encargo de apoio devido à eliminação acidental. Dar aos usuários a capacidade de anular a eliminação dos seus dados (por exemplo, através de uma pasta de lixo) reduz mas não pode eliminar completamente esta carga de suporte, particularmente se o seu serviço também suporta add-ons de terceiros que também podem apagar dados.
A eliminação suave pode reduzir drasticamente ou mesmo eliminar completamente esta carga de suporte. A eliminação suave significa que os dados apagados são imediatamente marcados como tal, tornando-os inutilizáveis por todos exceto pelos caminhos de código administrativo do aplicativo. Os caminhos de código administrativo podem incluir descoberta legal, recuperação de conta desviada, administração de empresas, apoio ao usuário, e resolução de problemas e suas características relacionadas. Conduza eliminação suave quando um usuário esvazia o seu lixo, e forneça uma ferramenta de apoio ao usuário que permita aos administradores autorizados anular qualquer item apagado acidentalmente pelos usuários. A Google implementa esta estratégia para os nossos aplicativos de produtividade mais populares; caso contrário, a carga de engenharia de apoio ao usuário seria insustentável.
É possível alargar ainda mais a estratégia de eliminação suave, oferecendo aos usuários a opção de recuperar os dados eliminados. Por exemplo, a lixeira do Gmail permite que os usuários acessem mensagens que foram excluídas há menos de 30 dias.
Outra fonte comum de eliminação de dados indesejados ocorre como resultado de sequestro de conta. Em cenários de sequestro de conta, um sequestrador apaga normalmente os dados do usuário original antes de utilizar a conta para fins de spam e outros fins ilícitos. Quando se combina a uniformidade da eliminação acidental do usuário com o risco de eliminação de dados por sequestradores, torna-se claro o caso de uma interface programática de eliminação suave e de anulação de eliminação dentro e/ou por baixo de seu aplicativo.
A eliminação suave implica que, uma vez marcados como tal, os dados são destruídos após um atraso razoável. A duração do atraso depende das políticas e leis aplicáveis de uma organização, dos recursos e custos de armazenamento disponíveis, dos preços dos produtos e do posicionamento no mercado, especialmente em casos que envolvam muitos dados de curta duração. As escolhas comuns de atrasos de eliminação suaves são 15, 30, 45, ou 60 dias. Na experiência da Google, a maioria dos desvios de conta e problemas de integridade de dados são comunicados ou detectados no prazo de 60 dias. Por conseguinte, o caso de apagamento suave de dados por mais de 60 dias pode não ser forte.
O Google descobriu também que os casos mais devastadores de eliminação aguda de dados são causados por criadores de aplicativos não familiarizados com o código existente, mas que trabalham em códigos relacionados com a eliminação, especialmente pipelines de processamento de lotes (por exemplo, um pipeline MapReduce ou Hadoop offline). É vantajoso projetar as suas interfaces para impedir os programadores não familiarizados com o seu código de contornar as características de eliminação suave com novo código. Uma forma eficaz de conseguir isso é implementar ofertas de computação em nuvem que incluam APIs de eliminação suave built-in e anulação de eliminação, assegurando a ativação da referida funcionalidade. Mesmo a melhor armadura é inútil se não a colocar.
As estratégias de eliminação suave abrangem funcionalidades de eliminação de dados em produtos de consumo como o Gmail ou Google Drive, mas e se, em vez disso, suportar uma oferta de computação em nuvem? Assumindo que a sua oferta de computação em nuvem já suporta uma funcionalidade de eliminação e anulação programática com padrões razoáveis, os restantes cenários de eliminação acidental de dados terão origem em erros cometidos pelos seus próprios programadores internos ou pelos seus clientes programadores.
Em tais casos, pode ser útil introduzir uma camada adicional de eliminação suave, que designaremos por “eliminação lenta”. Pode pensar na eliminação lenta como eliminação nos bastidores, controlado pelo sistema de armazenamento (enquanto a eliminação suave é controlada e expressa para o aplicativo ou serviço do cliente). Num cenário de eliminação lenta, os dados que são apagados por um aplicativo de nuvem tornam-se imediatamente inacessíveis ao aplicativo, mas são preservados pelo fornecedor do serviço de nuvem por até algumas semanas antes da destruição. A eliminação lenta não é aconselhável em todas as estratégias de defesa em profundidade: um longo período de eliminação lenta é caro em sistemas com muitos dados de curta duração, e impraticável em sistemas que devem garantir a destruição dos dados eliminados dentro de um prazo razoável (ou seja, aqueles que oferecem garantias de privacidade).
Para resumir a primeira camada de defesa em profundidade:
- Uma pasta de lixo que permite aos usuários anular os dados é a principal defesa contra o erro do usuário.
- A eliminação suave é a defesa primária contra erro do programador e a defesa secundária contra erro do usuário.
- Nas ofertas do desenvolvedor, a eliminação lenta é a principal defesa contra erros internos do desenvolvedor e a defesa secundária contra erros externos do desenvolvedor
E o histórico da revisão? Alguns produtos fornecem a capacidade de reverter itens para estados anteriores. Quando tal recurso está disponível para os usuários, é uma forma de lixo. Quando disponível para os criadores, pode ou não substituir a eliminação suave, dependendo da sua implementação.
No Google, o histórico de revisões revelou-se útil na recuperação de certos cenários de corrupção de dados, mas não na recuperação da maioria dos cenários de perda de dados envolvendo eliminação acidental, programática ou outra. Isto porque algumas implementações do histórico de revisões tratam a eliminação como um caso especial em que os estados anteriores devem ser removidos, por oposição à alteração de um item cujo histórico pode ser retido durante um determinado período de tempo. Para proporcionar proteção adequada contra eliminação indesejada, aplicar os princípios de eliminação lenta e/ou suave também ao histórico de revisões.
Segunda camada: Backups e seus métodos de recuperação relacionados
Os backups e a recuperação de dados são a segunda linha de defesa após a eliminação suave. O princípio mais importante nesta camada é que os backups não importam; o que importa é a recuperação. Os fatores que apoiam uma recuperação bem sucedida devem orientar as suas decisões de backup, e não o contrário.
Em outras palavras, os cenários em que pretende que os seus backups o ajudem a recuperar devem ditar o seguinte:
- Quais os métodos de backup e recuperação a utilizar
- Com que frequência você estabelece pontos de restauração fazendo backups completos ou incrementais de seus dados
- Onde se guardam os backups
- Por quanto tempo se mantêm os backups
Quantos dados recentes você pode perder durante um esforço de recuperação? Quanto menos dados você puder perder, mais sério você deve ser sobre uma estratégia de backup incremental. Em um dos casos mais extremos do Google, usamos uma estratégia de backup de streaming quase em tempo real para uma versão mais antiga do Gmail.
Mesmo que o dinheiro não seja uma limitação, backups completos frequentes são caros de outras maneiras. Sobretudo, impõem uma carga computacional sobre os datastores ativos do seu serviço enquanto este serve os usuários, aproximando o seu serviço da sua escalabilidade e limites de desempenho. Para aliviar essa carga, você pode fazer backups completos fora do horário de pico, e depois uma série de backups incrementais quando o seu serviço estiver mais ocupado.
Com que rapidez precisa se recuperar? Quanto mais rápido os seus usuários precisarem ser resgatados, mais locais seus backups deverão ser. Muitas vezes, o Google retém snapshots caros, mas rápidos de recuperar durante períodos de tempo muito curtos dentro da instância de armazenamento, e armazena backups menos recentes em armazenamento distribuído de acesso aleatório dentro do mesmo (ou próximo) datacenter durante um tempo ligeiramente mais longo. Tal estratégia por si só não protegeria de falhas ao nível do site, portanto, esses backups são frequentemente transferidos para locais próximos ou offline durante um período de tempo mais longo antes de expirarem em favor de backups mais recentes.
Até onde seus backups devem chegar? Sua estratégia de backup se torna mais cara à medida que você recua, enquanto os cenários dos quais você pode esperar para recuperar aumentam (embora esse aumento esteja sujeito a retornos decrescentes).
Na experiência do Google, os bugs de baixo grau de mutação ou eliminação de dados dentro no código do aplicativo exigem o maior alcance no tempo, uma vez que alguns desses bugs foram notados meses após o início da primeira perda de dados. Esses casos sugerem que você gostaria de poder voltar no tempo o máximo possível.
Por outro lado, num ambiente de desenvolvimento de alta velocidade, alterações no código e no esquema podem tornar os backups mais antigos caros ou impossíveis de usar. Além disso, é um desafio recuperar diferentes subconjuntos de dados para diferentes pontos de restauração, pois isso envolveria vários backups. No entanto, este é exatamente o tipo de esforço de recuperação exigido por cenários de corrupção ou eliminação de dados de baixo grau.
As estratégias descritas na Terceira Camada: A detecção precoce destina-se a acelerar a detecção de bugs de mutação ou eliminação de dados de baixo grau no código do aplicativo, evitando, pelo menos em parte, a necessidade deste tipo de esforço complexo de recuperação. Ainda assim, como se confere proteção razoável antes de saber quais tipos de problemas detectar? O Google escolheu traçar a linha entre 30 e 90 dias de backups para muitos serviços. Onde um serviço se enquadra nessa janela depende da sua tolerância à perda de dados e dos seus relativos investimentos na detecção precoce.
Para resumir o nosso conselho de proteção contra as 24 combinações de modos de falha de integridade de dados: abordar uma vasta gama de cenários a um custo razoável exige uma estratégia de backup por camadas. A primeira camada compreende muitos backups frequentes e rapidamente restaurados, armazenados mais perto dos datastores ativos, talvez utilizando as mesmas ou similares tecnologias de armazenamento das fontes de dados. Isso confere proteção contra a maioria dos cenários envolvendo bugs de software e erros do desenvolvedor. Devido a despesas relativas, os backups são retidos neste nível durante horas a dias de um dígito, e podem levar alguns minutos para serem restaurados.
A segunda camada compreende menos backups retidos por dias de um ou dois dígitos, em sistemas de ficheiros distribuídos localmente para o site. Esses backups podem levar horas para serem restaurados e conferir proteção adicional contra acidentes que afetam tecnologias de armazenamento específicas na sua pilha de servidores, mas não as tecnologias utilizadas para conter os backups. Esta camada também protege contra bugs em seu aplicativo que são detectados tarde demais para depender do primeira camada da sua estratégia de backup. Se estiver introduzindo novas versões do seu código para produção duas vezes por semana, pode fazer sentido manter esses backups por pelo menos uma semana ou duas antes de excluí-los.
As camadas subsequentes aproveitam o armazenamento próximo da linha, tais como bibliotecas de fitas dedicadas e armazenamento externo dos suportes de backup (por exemplo, fitas ou unidades de disco). Os backups nestas camadas conferem proteção contra problemas ao nível do site, tais como uma falha de energia do datacenter ou corrupção do sistema de ficheiros distribuídos devido a um bug.
É caro mover grandes quantidades de dados de e para as camadas. Por outro lado, a capacidade de armazenamento nas camadas mais avançadas não compete com o crescimento das instâncias de armazenamento de produção ativos do seu serviço. Como resultado, os backups nestss camadas tendem a ser feitos com menos frequência, mas retidos por mais tempo.
Camada superior: Replicação
Num mundo ideal, cada instância de armazenamento, incluindo as instâncias que contêm seus backups, seriam replicadas. Durante um esforço de recuperação de dados, a última coisa que quer é descobrir que seus próprios backups perderam os dados necessários ou que o datacenter que contém o backup mais útil está em manutenção.
À medida que o volume de dados aumenta, a replicação de cada instância de armazenamento nem sempre é viável. Nesses casos, faz sentido escalonar backups sucessivos em sites diferentes, cada um dos quais pode falhar independentemente, e gravar seus backups usando um método de redundância, como RAID, códigos de eliminação Reed-Solomon ou replicação no estilo GFS.
Ao escolher um sistema de redundância, não confie num esquema pouco utilizado, cujos únicos “testes” de eficácia são as suas próprias tentativas esporádicas de recuperação de dados. Em vez disso, escolha um esquema popular que seja de uso comum e contínuo por muitos dos seus usuários.
1T Versus 1E: Não “Apenas” um Backup Maior
Os processos e práticas aplicados a volumes de dados medidos em T (terabytes) não são bem dimensionados para dados medidos em E (exabytes). Validar, copiar, e executar testes de ida e volta em alguns gigabytes de dados estruturados é um problema interessante. No entanto, assumindo que tem conhecimento suficiente do seu esquema e modelo de transação, este exercício não apresenta quaisquer desafios especiais. Normalmente só precisa obter os recursos da máquina para iterar sobre os seus dados, executar alguma lógica de validação, e delegar armazenamento suficiente para manter algumas cópias dos seus dados.
Agora vamos aumentar a aposta: em vez de alguns gigabytes, vamos tentar assegurar e validar 700 petabytes de dados estruturados. Assumindo um desempenho SATA 2.0 ideal de 300 MB/s, uma única tarefa que itera todos os seus dados e executa mesmo as verificações de validação mais básicas demorará 8 décadas. Fazer alguns backups completos, assumindo que tem os meios de comunicação, vai demorar pelo menos o mesmo tempo. O tempo de restauração, com algum pós-processamento, demorará ainda mais tempo. Agora, estamos analisando quase um século inteiro para restaurar um backup que tinha até 80 anos quando começou a restauração. Obviamente, uma tal estratégia precisa ser repensada.
A técnica mais comum e largamente eficaz utilizada para fazer o backup de enormes quantidades de dados é estabelecer “pontos de confiança” nas suas porções de dados armazenados que são verificados depois de se tornarem imutáveis, geralmente com o passar do tempo. Quando sabemos que um determinado perfil de usuário ou transação é fixo e não será sujeito a mais alterações, podemos verificar o seu estado interno e fazer cópias adequadas para efeitos de recuperação. Poderá então fazer backups incrementais que apenas incluem dados que tenham sido modificados ou adicionados desde o seu último backup. Esta técnica alinha o seu tempo de backup com o seu tempo de processamento “principal”, o que significa que os backups incrementais frequentes podem salvá-lo do trabalho de verificação e cópia monolítica de 80 anos.
No entanto, lembre-se que nos preocupamos com restaurações, não com backups. Digamos que fizemos um backup completo há três anos e desde então fazemos backups incrementais diários. Uma restauração completa dos nossos dados processará em série uma cadeia de mais de 1.000 backups altamente interdependentes. Cada backup independente incorre em risco adicional de falha, para não mencionar o fardo logístico da programação e o custo do tempo de execução desses trabalhos.
Outra maneira de reduzir o tempo total de nossos trabalhos de cópia e verificação é distribuir a carga. Se partirmos bem os nossos dados, é possível executar N tarefas em paralelo, sendo cada tarefa responsável pela cópia e verificação de 1/N dos nossos dados. Fazer isso requer alguma premeditação e planejamento no design do esquema e na implantação física de nossos dados para:
- Equilibrar corretamente os dados
- Assegurar a independência de cada fragmento
- Evitar a contenda entre as tarefas irmãs paralelas
Entre distribuir a carga horizontalmente e restringir o trabalho a fatias verticais dos dados demarcados pelo tempo, podemos reduzir essas oito décadas de tempo total em várias ordens de magnitude, tornando as nossas restaurações relevantes.
Terceira camada: Detecção precoce
Os dados “ruins” não ficam parados, se propagam. As referências a dados ausentes ou corrompidos são copiadas, os links se espalham e, a cada atualização, a qualidade geral do seu datastore diminui. As transações dependentes subsequentes e as possíveis alterações no formato de dados tornam a restauração de um determinado backup mais difícil à medida que o relógio avança. Quanto mais cedo souber de uma perda de dados, mais fácil e completa poderá ser a sua recuperação.
Desafios enfrentados pelos criadores de cloud
Em ambientes de alta velocidade, os serviços de aplicativos e infraestruturas em nuvem enfrentam muitos desafios de integridade de dados em tempo de execução, como por exemplo:
- Integridade referencial entre datastores
- Alterações do esquema
- Código de Envelhecimento
- Migrações de dados sem tempo de inatividade
- Pontos de integração evolutivos com outros serviços
Sem um esforço de engenharia consciente para acompanhar as relações emergentes nos seus dados, a qualidade dos dados de um serviço bem sucedido e em crescimento degrada-se com o tempo.
Muitas vezes, o desenvolvedor de nuvem iniciante que escolhe um API de armazenamento consistente distribuído (como a Megastore) delega a integridade dos dados do aplicativo ao algoritmo consistente distribuído implementado sob o API (como o Paxos; ver Capítulo 23). As razões do programador são que só o API selecionado irá manter os dados do aplicativo em boa forma. Como resultado, eles unificam todos os dados do aplicativo numa única solução de armazenamento que garante a consistência distribuída, evitando problemas de integridade referencial em troca de um desempenho e/ou escala reduzidos.
Embora tais algoritmos sejam infalíveis em teoria, as suas implementações são muitas vezes repletas de hacks, otimização, bugs, e suposições educadas. Por exemplo: em teoria, Paxos ignora nós de computação com falhas e pode fazer progressos desde que se mantenha um quórum de nós funcionais. Na prática, contudo, ignorar um nó com falha pode corresponder a timeouts, novas tentativas, e outras abordagens de tratamento de falhas sob a implementação particular de Paxos . Por quanto tempo o Paxos deve tentar entrar em contato com um nó que não responde antes de expirar? Quando uma determinada máquina falha (talvez intermitentemente) de uma certa forma, com um determinado tempo, e num determinado datacenter, o resultado é um comportamento imprevisível. Quanto maior a escala de um aplicativo, mais frequentemente o aplicativo é afetado, sem o conhecimento, por tais inconsistências. Se esta lógica se mantém verdadeira mesmo quando aplicada a implementações do Paxos (como tem sido verdade para o Google), então deve ser mais verdadeira para implementações eventualmente consistentes, tais como a Bigtable (que também se tem mostrado verdadeira). Os aplicativos afetados não têm como saber se 100% de seus dados são bons até que verifiquem: confie nos sistemas de armazenamento, mas verifique!
Para complicar este problema, a fim de recuperar de cenários de corrupção ou eliminação de dados de baixo grau, devemos recuperar diferentes subconjuntos de dados para diferentes pontos de restauração usando backups diferentes, enquanto alterações no código e no esquema podem tornar os backups mais antigos ineficazes em ambientes de alta velocidade.
Validação de dados fora da banda
Para evitar que a qualidade dos dados se degrade perante os olhos dos usuários, e para detectar cenários de corrupção ou perda de dados de baixo grau antes que se tornem irrecuperáveis, é necessário um sistema de verificações e equilíbrios fora da banda, tanto dentro como entre os datastores de um aplicativo.
Na maioria das vezes, esses pipelines de validação de dados são implementados como coleções de reduções de mapa ou trabalhos do Hadoop. Frequentemente, tais pipelines são adicionados como uma consideração posterior a serviços que já são populares e bem sucedidos. Às vezes, esses pipelines são tentados pela primeira vez quando os serviços atingem os limites de escalabilidade e são reconstruídos do zero. A Google construiu validadores em resposta a cada uma destas situações.
Desviar alguns desenvolvedores para trabalhar em um pipeline de validação de dados pode diminuir a velocidade da engenharia no curto prazo. No entanto, dedicar recursos de engenharia à validação de dados dá a outros programadores a coragem de avançar mais rapidamente a longo prazo, porque os engenheiros sabem que os bugs de corrupção de dados têm menos probabilidades de entrar furtivamente na produção sem serem notados. Semelhante aos efeitos desfrutados quando os testes de unidades são introduzidos no início do ciclo de vida do projeto, um pipeline de validação de dados resulta numa aceleração global dos projectos de desenvolvimento de software.
Para citar um exemplo específico: O Gmail dispõe de uma série de validadores de dados, cada um dos quais detectou problemas reais de integridade de dados na produção. Os programadores do Gmail obtêm conforto do conhecimento de que os erros que introduzem inconsistências nos dados de produção são detectados em 24 horas, e tremem só de pensar em utilizar os seus validadores de dados com menos frequência do que diariamente. Estes validadores, juntamente com uma cultura de testes unitários e de regressão e outras melhores práticas, deram aos programadores do Gmail a coragem de introduzir alterações de código na implementação de armazenamento de produção do Gmail com mais frequência do que uma vez por semana.
A validação de dados fora da banda é complicada de implementar corretamente. Quando alterações muito rigorosas, mesmo simples e apropriadas, fazem com que a validação falhe. Como resultado, os engenheiros abandonam completamente a validação de dados. Se a validação de dados não for suficientemente rigorosa, a experiência do usuário – que afeta a corrupção de dados – pode passar despercebida. Para encontrar o equilíbrio certo, valide invariantes que causam devastação aos usuários.
Por exemplo, o Google Drive valida periodicamente o conteúdo do ficheiro alinhado com as listagens nas pastas do Drive. Se estes dois elementos não se alinharem, alguns ficheiros ficariam sem dados – um resultado desastroso. Os criadores de infraestruturas do Drive investiram tanto na integridade dos dados que também aprimoraram seus validadores para corrigir automaticamente essas inconsistências. Esta salvaguarda transformou uma potencial situação de emergência “todos-se-empenhem-arquivos-omigosh-estão-desaparecendo!!” de perda de dados em 2013 numa situação de “vamos para casa e corrigir a causa raiz na segunda-feira”. Ao transformar emergências em negócios como sempre, os validadores melhoram o moral da engenharia, a qualidade de vida e a previsibilidade.
Os validadores fora da banda podem ser caros em escala. Uma parte significativa do volume de recursos de computação do Gmail é compatível com uma coleção de validadores diários. Para agravar esta despesa, estes validadores também reduzem as taxas de acerto da cache do lado do servidor, reduzindo a capacidade de resposta do lado do servidor experimentada pelos usuários. Para atenuar esse impacto na capacidade de resposta, o Gmail fornece vários botões para limitar a taxa de seus validadores e refatora periodicamente os validadores para reduzir a contenção do disco. Num desses esforços de refatoração, reduzimos a contenção de fusos de disco em 60% sem reduzir significativamente o âmbito dos invariantes que cobriam. Embora a maioria dos validadores do Gmail seja executada diariamente, a carga de trabalho do maior validador é dividida em 10 a 14 fragmentos, com um fragmento validado por dia por motivos de escala.
O Google Compute Storage é outro exemplo dos desafios que a escala implica para a validação de dados. Quando os seus validadores fora da banda já não podiam terminar dentro de um dia, os engenheiros da Compute Storage tiveram de conceber uma forma mais eficiente de verificar os seus metadados do que apenas a utilização da força bruta. Semelhante à sua aplicação na recuperação de dados, uma estratégia por níveis também pode ser útil na validação de dados fora da banda. À medida que um serviço cresce, sacrifique o rigor nos validadores diários. Certifique-se de que os validadores diários continuam a capturar os cenários mais desastrosos dentro de 24 horas, mas continue com uma validação mais rigorosa com uma frequência reduzida para conter os custos e a latência.
A resolução de problemas de validação com falha pode exigir um esforço significativo. As causas de uma validação com falha intermitente podem desaparecer em minutos, horas, ou dias. Por conseguinte, a capacidade de pesquisar rapidamente nos logs de auditoria de validação é essencial. Os serviços maduros do Google fornecem aos engenheiros de plantão documentação abrangente e ferramentas para a resolução de problemas. Por exemplo, são fornecidos engenheiros de plantão para o Gmail:
- Um conjunto de entradas de playbook descrevendo como responder a um alerta de falha de validação
- Uma ferramenta de investigação do tipo BigQuery
- Um painel de validação de dados
A validação eficaz de dados fora da banda exige tudo o que se segue:
- Gestão de trabalhos de validação
- Monitorização, alertas, e painéis de bordo
- Características limitadoras da taxa
- Ferramentas de resolução de problemas
- Playbook de produção
- APIs de validação de dados que facilitam a adição e refatoração de validadores
A maioria das pequenas equipes de engenharia que operam a alta velocidade não se podem dar ao luxo de conceber, construir e manter todos estes sistemas. Se forem pressionadas a fazê-lo, o resultado é muitas vezes frágil, limitado, e desperdiçador, que rapidamente cai em desuso. Portanto, estruture as suas equipes de engenharia de modo que uma equipe central de infraestruturas forneça um quadro de validação de dados para múltiplas equipes de engenharia de produtos. A equipe central de infraestruturas mantém a estrutura de validação de dados fora da banda, enquanto as equipes de engenharia de produtos mantêm a lógica comercial personalizada no coração do validador para acompanharem a evolução dos seus produtos.
Sabendo que a recuperação de dados irá funcionar
Quando é que uma lâmpada quebra? Ao acender o interruptor não liga a luz? Nem sempre – muitas vezes a lâmpada já tinha falhado, e você simplesmente percebe a falha ao apertar o interruptor sem resposta. Nessa altura, a sala já está escura e o dedo do pé já se encontra preso.
Da mesma forma, as suas dependências de recuperação (ou seja, na sua maioria, mas não só, o seu backup), podem estar num estado latente quebrado, do qual não tem conhecimento até tentar recuperar os dados.
Se descobrir que o seu processo de recuperação está quebrado antes de precisar dele, pode resolver a vulnerabilidade antes de ser vítima: pode fazer outro backup, fornecer recursos adicionais, e alterar o seu SLO. Mas para realizar essas ações de forma proativa, primeiro tem de saber que elas são necessárias. Para detectar estas vulnerabilidades:
- Teste continuamente o processo de recuperação como parte das suas operações normais
- Estabeleça alertas que disparam quando um processo de recuperação não fornece uma indicação do seu sucesso
O que pode dar errado no seu processo de recuperação? Tudo e qualquer coisa – e é por isso que o único teste que deve deixá-lo dormir à noite é um teste completo de ponta a ponta. Que a prova esteja no pudding. Mesmo que tenha tido uma recuperação bem sucedida recentemente, partes do seu processo de recuperação ainda podem quebrar. Se retirar apenas uma lição deste capítulo, lembre-se que só sabe que pode recuperar o seu estado recente se o fizer de fato.
Se os testes de recuperação forem um evento manual, encenado, o teste se torna um trabalho indesejável que não é realizado com profundidade ou frequência suficiente para merecer sua confiança. Portanto, automatize estes testes sempre que possível e depois execute-os continuamente.
Os aspectos do seu plano de recuperação que deve confirmar são inúmeros:
- As suas cópias de segurança são válidas e completas, ou estão vazias?
- Tem recursos de máquina suficientes para executar todas as tarefas de configuração, restauração e pós-processamento que compõem a sua recuperação?
- O processo de recuperação é concluído em tempo total razoável?
- É capaz de monitorizar o estado do seu processo de recuperação à medida que este avança?
- Está livre de dependências críticas de recursos fora do seu controle, tais como o acesso a um cofre de armazenamento de meios fora do local que não está disponível 24 horas por dia, 7 dias por semana?
Os nossos testes descobriram as falhas acima mencionadas, bem como falhas de muitos outros componentes de uma recuperação de dados bem sucedida. Se não tivéssemos descoberto estas falhas em testes regulares – isto é, se nos deparássemos com as falhas apenas quando precisássemos recuperar dados de usuários em situações de emergência reais – é bem possível que alguns dos produtos mais bem sucedidos da Google hoje em dia possam não ter resistido ao teste do tempo.
As falhas são inevitáveis. Se esperarmos para as descobrir quando estiver sob a mira, enfrentando uma perda real de dados, estará brincando com fogo. Se o teste forçar as falhas a acontecerem antes que ocorra uma catástrofe real, você pode corrigir os problemas antes que qualquer dano se concretize.
Estudos de casos
A vida imita a arte (ou neste caso, a ciência), e como previmos, a vida real deu-nos oportunidades infelizes e inevitáveis de pôr à prova os nossos sistemas e processos de recuperação de dados, sob pressão do mundo real. Duas das mais notáveis e interessantes destas oportunidades são aqui discutidas.
Gmail-Fevereiro, 2011: Restauração a partir de GTape
O primeiro estudo de caso de recuperação que vamos examinar foi único em alguns aspectos: o número de falhas que coincidiram para provocar a perda de dados, e o fato de ter sido a maior utilização da nossa última linha de defesa, o sistema de backup offline GTape.
Domingo, 27 de Fevereiro de 2011, ao fim da noite
O pager do sistema de backup do Gmail é acionado, apresentando um número de telefone para se juntar a uma chamada em conferência. O evento que temíamos há muito tempo – a razão da existência do sistema de backup – aconteceu: O Gmail perdeu uma quantidade significativa de dados do usuário. Apesar das muitas salvaguardas e verificações e redundâncias internas do sistema, os dados desapareceram do Gmail.
Esta foi a primeira utilização em larga escala do GTape, um sistema global de backup para o Gmail, para restaurar dados de clientes em tempo real. Felizmente, não foi a primeira restauração deste tipo, uma vez que situações semelhantes tinham sido simuladas anteriormente muitas vezes. Por conseguinte, foi possível:
- Apresentar uma estimativa de quanto tempo levaria para restaurar a maioria das contas dos usuários afetados
- Restaurar todas as contas dentro de algumas horas da nossa estimativa inicial
- Recuperar mais de 99% dos dados antes do tempo estimado de conclusão
A capacidade de formular uma tal estimativa foi sorte? Não — nosso sucesso foi fruto de planejamento, adesão às melhores práticas, trabalho árduo e cooperação, e ficamos felizes em ver nosso investimento em cada um desses elementos dar tão certo quanto deu. A Google foi capaz de restaurar os dados perdidos em tempo útil, executando um plano concebido de acordo com as melhores práticas de Defesa em Profundidade e Preparação de Emergência.
Quando o Google revelou publicamente que recuperámos estes dados a partir do nosso sistema de backup em fita anteriormente não revelado, a reação pública foi uma mistura de surpresa e diversão. Fita? O Google não tem muitos discos e uma rede rápida para replicar dados tão importantes? Claro que a Google tem tais recursos, mas o princípio da Defesa em Profundidade dita fornecer múltiplas camadas de proteção para se proteger contra a quebra ou comprometimento de qualquer mecanismo de proteção único. O backup de sistemas online como o Gmail fornece defesa em profundidade em duas camadas:
- Uma falha dos subsistemas internos de redundância e backup do Gmail
- Uma falha generalizada ou vulnerabilidade de dia zero em um driver de dispositivo ou sistema de ficheiros que afeta o meio de armazenamento subjacente (disk)
Esta falha específica resultou do primeiro cenário – enquanto o Gmail tinha meios internos para recuperar os dados perdidos, esta perda ia além dos meios internos que podiam ser recuperados.
Um dos aspectos mais celebrados internamente da recuperação de dados do Gmail foi o grau de cooperação e boa coordenação que compreendeu a recuperação. Muitas equipes, algumas completamente alheias ao Gmail ou à recuperação de dados, empenharam-se em ajudar. A recuperação não poderia ter sido tão bem sucedida sem um plano central para coreografar um esforço hercúleo tão amplamente distribuído; este plano foi o produto de ensaios gerais regulares. A devoção do Google à preparação para emergências leva-nos a encarar tais falhas como inevitáveis. Aceitando esta inevitabilidade, não esperamos nem apostamos em evitar tais desastres, mas antecipamos que eles irão ocorrer. Assim, precisamos de um plano para lidar não só com as falhas previsíveis, mas também para alguma quantidade de rupturas indiferenciadas aleatórias.
Em suma, sempre soubemos que a adesão às melhores práticas é importante, e foi bom ver que essa máxima provou ser verdadeira.
Google Music-Março de 2012: Detecção de eliminação de fugas
A segunda falha que vamos examinar implica desafios na logística que são únicos à escala de datastore a ser recuperada: onde se armazenam mais de 5.000 fitas, e como se lê de forma eficiente (ou mesmo de forma viável) essa quantidade de dados de mídias offline num período de tempo razoável?
Terça-feira, 6 de Março de 2012, meio da tarde
Descobrindo o problema
Um usuário do Google Music relata que faixas anteriormente não problemáticas estão sendo ignoradas. A equipe responsável pela interface com os usuários do Google Music notifica os engenheiros do Google Music. O problema é investigado como um possível problema de streaming de mídia.
Em 7 de Março, o engenheiro investigador descobre que falta uma referência aos metadados da faixa não reproduzível que deveria apontar para os dados de áudio reais. Ele fica surpreso. A solução óbvia é localizar os dados de áudio e repor a referência aos dados. Contudo, a engenharia do Google orgulha-se de uma cultura de correção de problemas na raiz, então o engenheiro se aprofunda.
Quando encontra a causa do lapso de integridade dos dados, quase tem um ataque cardíaco: a referência de áudio foi removida por um pipeline de eliminação de dados de proteção da privacidade. Esta parte do Google Music foi projetada para apagar um número muito grande de faixas de áudio em tempo recorde.
Avaliar os danos
A política de privacidade do Google protege os dados pessoais de um usuário. Tal como aplicada especificamente ao Google Music, a nossa política de privacidade significa que os ficheiros de música e metadados relevantes são removidos dentro de um prazo razoável depois de os usuários os apagarem. À medida que a popularidade do Google Music aumentava, a quantidade de dados crescia rapidamente, de modo que a implementação da eliminação original precisava ser redesenhada em 2012 para ser mais eficiente. No dia 6 de Fevereiro, o pipeline de eliminação de dados atualizado desfrutou da sua primeira execução, para remover metadados relevantes. Nada parecia errado na época, então um segundo estágio do pipeline também foi autorizado a remover os dados de áudio associados.
Poderia o pior pesadelo do engenheiro ser verdade? Ele soou imediatamente o alarme, elevando a prioridade do caso de apoio à classificação mais urgente da Google e reportando o problema à gestão de engenharia e à Engenharia de confiabilidade do site. Uma pequena equipe de desenvolvedores do Google Music e SREs se reuniu para resolver o problema, e o pipeline ofensivo foi temporariamente desativado para conter a maré de baixas de usuários externos.
A seguir, seria impensável verificar manualmente os metadados de milhões a biliões de ficheiros organizados em múltiplos datacenters. Por isso, a equipe fez um trabalho apressado de MapReduce para avaliar os danos e esperou desesperadamente que o trabalho fosse concluído. Congelaram quando os seus resultados chegaram a 8 de Março: o pipeline de exclusão de dados refatorado havia removido aproximadamente 600.000 referências de áudio que não deveriam ter sido removidas, afetando arquivos de áudio para 21.000 usuários. Como o pipeline de diagnóstico apressado fez algumas simplificações, a verdadeira extensão dos danos poderia ser pior.
Já tinha passado mais de um mês desde a primeira vez que o pipeline de eliminação de dados de buggy funcionou, e essa primeira execução removeu centenas de milhares de faixas de áudio que não deveriam ter sido removidas. Havia alguma esperança de recuperar os dados? Se as faixas não fossem recuperadas, ou não fossem recuperadas suficientemente depressa, o Google teria que enfrentar a música de seus usuários. Como não notamos essa falha?
Resolvendo a questão
Identificação paralela de bugs e esforços de recuperação
O primeiro passo para resolver a questão foi identificar o bug real, e determinar como e porquê o bug aconteceu. Desde que a causa raiz não fosse identificada e corrigida, quaisquer esforços de recuperação seriam em vão. Estaríamos sob pressão para reativar o pipeline para respeitar as solicitações de usuários que excluíram faixas de áudio, mas isso prejudicaria usuários inocentes que continuariam a perder músicas compradas em lojas, ou pior, seus próprios arquivos de áudio cuidadosamente gravados. A única forma de escapar do Catch-22131 era resolver o problema pela raiz, e corrigi-lo rapidamente.
No entanto, não havia tempo a perder antes de montar o esforço de recuperação. As faixas de áudio propriamente ditas foram armazenadas em cassete, mas ao contrário do nosso estudo de caso do Gmail, as fitas de backup codificadas para o Google Music foram transportadas para locais de armazenamento fora do local, porque essa opção oferecia mais espaço para backups volumosos de dados de áudio dos usuários. Para restaurar rapidamente a experiência dos usuários afetados, a equipe decidiu resolver os problemas da causa raiz enquanto recuperava as fitas de backup fora do local (uma opção de restauração bastante demorada) em paralelo.
Os engenheiros dividiram-se em dois grupos. Os SREs mais experientes trabalharam no esforço de recuperação, enquanto os programadores analisaram o código de eliminação de dados e tentaram corrigir o bug de perda de dados na sua raiz. Devido ao conhecimento incompleto do problema de raiz, a recuperação teria de ser encenada em várias passagens. O primeiro lote de quase meio milhão de pistas de áudio foi identificado, e a equipe que manteve o sistema de backup de fita foi notificada do esforço de recuperação de emergência às 16h34. Horário do Pacífico em 8 de março.
A equipe de recuperação teve um fator a seu favor: este esforço de recuperação ocorreu apenas semanas após o exercício anual de testes de recuperação de desastres da empresa (ver [Kri12]). A equipe de recuperação já conhecia as capacidades e limitações dos seus subsistemas que tinham sido objeto de testes DiRT e começou a limpar o pó de uma nova ferramenta que tinham testado durante um exercício DiRT. Utilizando a nova ferramenta, a equipe de recuperação combinada deu início ao esforço meticuloso de mapear centenas de milhares de ficheiros de áudio para backups registrados no sistema de backup de fitas, e depois mapear os ficheiros a partir de backups para fitas reais.
Desta forma, a equipe determinou que o esforço inicial de recuperação envolveria a recolha de mais de 5.000 fitas de backup por caminhão. Posteriormente, os técnicos do datacenter teriam de liberar espaço para as fitas nas bibliotecas de cassetes. Um processo longo e complexo de registrar as fitas e extrair os dados das fitas se seguiria, envolvendo soluções alternativas e mitigações no caso de fitas ruins, unidades ruins e interações inesperadas do sistema
Infelizmente, apenas 436.223 das cerca de 600.000 faixas de áudio perdidas foram encontradas nos backups das fitas, o que significou que cerca de 161.000 outras faixas de áudio foram consumidas antes de poderem ser copiadas. A equipe de recuperação decidiu descobrir como recuperar as 161.000 faixas em falta após terem iniciado o processo de recuperação das faixas com backups em cassete.
Entretanto, a equipe da causa raiz tinha perseguido e abandonado um engano: inicialmente pensaram que um serviço de armazenamento do qual o Google Music dependia tinha fornecido dados de buggy que enganavam os pipelines de eliminação de dados para remover os dados de áudio errados. Após uma investigação mais aprofundada, essa teoria revelou-se falsa. A equipe da causa principal arranhou as suas cabeças e continuou a sua busca do buggy evasivo.
Primeira onda de recuperação
Depois de a equipe de recuperação ter identificado as fitas de backup, a primeira onda de recuperação começou em 8 de março. Solicitar 1,5 petabytes de dados distribuídos entre milhares de fitas do armazenamento externo era uma questão, mas extrair os dados das fitas era outra. A pilha de software de backup de fitas personalizadas não foi projetada para lidar com uma única operação de restauração de tamanho tão grande, pelo que a recuperação inicial foi dividida em 5.475 trabalhos de restauração. Levaria um operador humano digitando um comando de restauração por minuto mais de três dias para solicitar tantas restaurações, e qualquer operador humano sem dúvida cometeria muitos erros. Bastava solicitar a restauração a partir do sistema de backup de fita magnética para que o SRE desenvolvesse uma solução programática.132
À meia-noite do dia 9 de Março, a Music SRE terminou o pedido de todas as 5.475 restaurações. O sistema de backup de cassetes começou a fazer a sua magia. Quatro horas mais tarde, ele expeliu uma lista de 5.337 fitas de backup a serem recuperadas de locais fora do local. Em mais oito horas, as fitas chegaram a um datacenter numa série de entregas de caminhões.
Enquanto os caminhões estavam a caminho, os técnicos do datacenter levaram várias bibliotecas de fitas para manutenção e removeram milhares de fitas para dar lugar à operação de recuperação massiva de dados. Depois os técnicos começaram a carregar cuidadosamente as fitas à mão, à medida que milhares de fitas chegavam durante as primeiras horas da manhã. Em exercícios anteriores de DiRT, este processo manual provou ser centenas de vezes mais rápido para restaurações massivas do que os métodos baseados em robôs fornecidos pelos vendedores das bibliotecas de fitas. No espaço de três horas, as bibliotecas faziam backupdas cassetes e executavam milhares de trabalhos de restauração em armazenamento distribuído por computador.
Apesar da experiência da equipe em DiRT, a recuperação massiva de 1,5 petabyte levou mais tempo do que os dois dias estimados. Na manhã de 10 de Março, apenas 74% dos 436.223 ficheiros de áudio tinham sido transferidos com sucesso de 3.475 fitas de backup recuperadas para armazenamento distribuído de sistemas de ficheiros num cluster computacional próximo. As outras 1.862 fitas de backup tinham sido omitidas do processo de recolha de fitas por um fornecedor. Além disso, o processo de recuperação foi interrompido por 17 fitas ruins. Antecipando uma falha devido a fitas ruins, uma codificação redundante foi usada para gravar os arquivos de backup. Entregas adicionais de caminhões foram iniciadas para recolher as fitas de redundância, juntamente com as outras 1.862 fitas que foram omitidas pelo primeiro recall externo.
Na manhã de 11 de Março, mais de 99,95% da operação de restauração tinha sido concluída, e a recolha de fitas de redundância adicionais para os ficheiros restantes estava em curso. Embora os dados estivessem em segurança nos sistemas de ficheiros distribuídos, eram necessárias etapas adicionais de recuperação de dados, a fim de os tornar acessíveis aos usuários. A Equipe de Música do Google começou a exercer estas etapas finais do processo de recuperação de dados em paralelo numa pequena amostra de ficheiros de áudio recuperados, para se certificar de que o processo ainda funcionava como esperado.
Nesse momento, os pagers de produção do Google Music soaram devido a uma falha de produção não relacionada mas crítica – uma falha que envolveu totalmente a equipe do Google Music durante dois dias. O esforço de recuperação de dados foi retomado em 13 de Março, quando todas as 436.223 faixas de áudio foram mais uma vez tornadas acessíveis aos seus usuários. Em apenas 7 dias, 1,5 petabytes de dados de áudio tinham sido reintegrados aos usuários com a ajuda de backups de cassetes fora do local; 5 dos 7 dias incluíam o esforço real de recuperação de dados.
Segunda onda de recuperação
Com a primeira onda do processo de recuperação atrás deles, a equipe deslocou o seu foco para os outros 161.000 ficheiros de áudio ausentes que tinham sido apagados pelo bug antes de terem sido armazenados. A maioria destes ficheiros foram comprados em lojas e faixas promocionais, e as cópias originais da loja não foram afetadas pelo bug. Tais faixas foram rapidamente repostas para que os usuários afetados pudessem desfrutar novamente da sua música.
No entanto, uma pequena parte dos 161.000 ficheiros de áudio tinha sido carregada pelos próprios usuários. A Equipe de Música da Google solicitou aos seus servidores que os clientes da Google Music dos usuários afetados voltassem a carregar ficheiros datados de 14 de Março em diante. Este processo durou mais de uma semana. Assim, concluiu-se o esforço completo de recuperação do incidente.
Abordar a causa raiz
Eventualmente, a Equipe de Música do Google identificou a falha na sua pipeline de eliminação de dados refaturados. Para compreender esta falha, é necessário primeiro um contexto sobre como os sistemas de processamento de dados offline evoluem em grande escala.
Para um serviço grande e complexo que compreende vários subsistemas e serviços de armazenamento, mesmo uma tarefa tão simples como a remoção de dados apagados precisa ser executada por fases, cada uma envolvendo diferentes datastores.
Para que o processamento de dados termine rapidamente, o processamento é paralelizado para correr em dezenas de milhares de máquinas que exercem uma grande carga em vários subsistemas. Esta distribuição pode atrasar o serviço para os usuários, ou causar a queda do serviço sob a carga pesada.
Para evitar estes cenários indesejáveis, os engenheiros de computação em nuvem fazem frequentemente uma cópia de curta duração dos dados em armazenamento secundário, onde o processamento de dados é então executado. A menos que a idade relativa das cópias secundárias dos dados seja cuidadosamente coordenada, esta prática introduz condições de corrida.
Por exemplo, duas fases de um pipeline podem ser concebidas para funcionar em estrita sucessão, com três horas de intervalo, de modo a que a segunda fase possa fazer uma suposição simplificada sobre a correção das suas entradas. Sem esta suposição simplificadora, a lógica da segunda fase pode ser difícil de paralelizar. Mas as fases podem demorar mais tempo para completar à medida que o volume de dados cresce. Eventualmente, as hipóteses de concepção original podem já não se manter para certos dados necessários para a segunda fase.
A princípio, essa condição de corrida pode ocorrer para uma pequena fração dos dados. Mas à medida que o volume de dados aumenta, uma fração cada vez maior dos dados corre o risco de desencadear uma condição de corrida. Tal cenário é probabilístico – o pipeline funciona corretamente para a grande maioria dos dados e durante a maior parte do tempo. Quando essas condições de corrida ocorrem em um pipeline de exclusão de dados, os dados errados podem ser excluídos de forma não determinística.
O pipeline de exclusão de dados do Google Music foi projetado com coordenação e grandes margens de erro. Mas quando os estágios upstream do pipeline começaram a exigir mais tempo à medida que o serviço crescia, otimizações de desempenho foram implementadas para que o Google Music pudesse continuar atendendo aos requisitos de privacidade. Como resultado, a probabilidade de uma condição de corrida de eliminação de dados inadvertida neste pipeline começou a aumentar. Quando o pipeline foi refaturado, esta probabilidade voltou a aumentar significativamente, até um ponto em que as condições da corrida ocorreram com mais regularidade.
Na sequência do esforço de recuperação, o Google Music redesenhou seu pipeline de eliminação de dados para eliminar este tipo de condição de corrida. Além disso, melhoramos a monitorização da produção e os sistemas de alerta para detectar bugs de eliminação semelhantes em grande escala, com o objetivo de detectar e corrigir tais problemas antes dos usuários notarem quaisquer problemas.
Princípios gerais da SRE aplicados à integridade dos dados
Os princípios gerais da SRE podem ser aplicados às especificidades da integridade dos dados e da computação em nuvem, tal como descrito nesta seção.
Mente de principiante
Os serviços complexos em grande escala têm bugs inerentes que não podem ser totalmente tateados. Nunca pense que compreende o suficiente de um sistema complexo para dizer que não falhará de uma certa forma. Confie mas verifique, e aplique a defesa em profundidade. (Nota: “A mente do principiante” não sugere que se ponha um novo contratado à frente desse pipeline de eliminação de dados!)
Confiar mas verificar
Qualquer API de que dependa não funcionará perfeitamente durante todo o tempo. É um dado adquirido que, independentemente da sua qualidade de engenharia ou rigor de testes, o API terá defeitos. Verifique a correção dos elementos mais críticos dos seus dados utilizando validadores de dados fora da banda, mesmo que a semântica API sugira que não precisa o fazer. Algoritmos perfeitos podem não ter implementações perfeitas.
A esperança não é uma estratégia
Os componentes do sistema que não são exercitados continuamente falham quando mais precisa deles. Provar que a recuperação de dados funciona com exercício regular, ou a recuperação de dados não funcionará. Os humanos não têm disciplina para exercitar continuamente os componentes do sistema, por isso a automatização é sua amiga. No entanto, quando se empenha em tais esforços de automatização com engenheiros que têm prioridades concorrentes, pode acabar por ficar com paragens temporárias.
Defesa em profundidade
Mesmo o sistema mais à prova de bala é suscetível a bugs e erros do operador. Para que os problemas de integridade dos dados possam ser corrigidos, os serviços devem detectar rapidamente tais problemas. Todas as estratégias acabam por falhar em ambientes em mudança. As melhores estratégias de integridade de dados são estratégias multicamadas que se entrecruzam umas com as outras e abordam uma vasta gama de cenários em conjunto a um custo razoável.
Revisitar e reexaminar
O fato de que os seus dados “estavam seguros ontem” não o vai ajudar amanhã, nem mesmo hoje. Os sistemas e infra-estruturas mudam, e tem de provar que os seus pressupostos e processos continuam a ser relevantes face ao progresso. Considere o seguinte.
O serviço de Shakespeare recebeu um pouco de imprensa positiva, e sua base de usuários está aumentando constantemente. Não foi dada qualquer atenção real à integridade dos dados à medida que o serviço estava sendo construído. É claro que não queremos servir bits ruins, mas se o índice Bigtable for perdido, podemos recriá-lo facilmente a partir dos textos originais de Shakespeare e de um MapReduce. Fazer isso levaria muito pouco tempo, então nunca fizemos backups do índice.
Agora uma nova funcionalidade permite aos usuários fazer anotações de texto. De repente, o nosso conjunto de dados já não pode ser facilmente recriado, enquanto os dados dos usuários são cada vez mais valiosos para os nossos usuários. Portanto, precisamos rever as nossas opções de replicação – não estamos apenas replicando para latência e largura de banda, mas também para a integridade dos dados. Por conseguinte, precisamos criar e testar um procedimento de salvaguarda e restauração. Este procedimento é também testado periodicamente por um exercício DiRT para assegurar que podemos restaurar as anotações dos usuários a partir de backups dentro do tempo definido pelo SLO.
Conclusão
A disponibilidade de dados deve ser uma das principais preocupações de qualquer sistema centrado em dados. Em vez de se concentrar nos meios até ao fim, o Google SRE considera útil pedir emprestada uma página do desenvolvimento orientado por testes, provando que nossos sistemas podem manter a disponibilidade de dados com um tempo de inatividade máximo previsto. Os meios e mecanismos que utilizamos para atingir este objetivo final são males necessários. Ao manter os nossos olhos no objetivo, evitamos cair na armadilha em que “A operação foi um sucesso, mas o sistema morreu”.
Reconhecer que não só tudo pode correr mal, mas que tudo irá correr mal é um passo significativo para a preparação de qualquer emergência real. Uma matriz de todas as combinações possíveis de desastres com planos para abordar cada um destes desastres permite-lhe dormir profundamente durante pelo menos uma noite; manter os seus planos de recuperação atuais e exercitados permite-lhe dormir as outras 364 noites do ano.
À medida que se recupera melhor de qualquer quebra em tempo N razoável, encontrará formas de reduzir esse tempo através de uma detecção de perdas mais rápida e mais fina, com o objetivo de se aproximar de N = 0. Poderá então passar do planejamento de recuperação para o planejamento de prevenção, com o objetivo de alcançar o Santo Graal de todos os dados, o tempo todo. Alcance esse objetivo, e você poderá dormir na praia naquelas merecidas férias.