Escrito por Dan Dennison
Editado por Tim Harvey
Este capítulo se concentra nos desafios da vida real de gerenciar pipelines de processamento de dados de profundidade e complexidade. Considera a frequência contínua entre pipelines periódicos que são executados com pouca frequência até pipelines contínuos que nunca param de funcionar, e discute as descontinuidades que podem produzir problemas operacionais significativos. É apresentada uma nova visão do modelo líder-seguidor como uma alternativa mais confiável e melhor escalonada ao pipeline periódico para o processamento de Big Data.
Origem do padrão de design do Pipeline
A abordagem clássica para o processamento de dados é escrever um programa que leia os dados, os transforme de alguma maneira desejada e gere novos dados. Tipicamente, o programa é programado para ser executado sob o controle de um programa de programação periódica, como o cron. Este padrão de design é chamado de data pipeline. Os data pipelines remontam a co-rotinas [Con63], os ficheiros de comunicação DTSS [Bul80], o UNIX pipe [McI86], e depois, os pipelines ETL, mas tais pipelines ganharam maior atenção com o surgimento de “Big Data”, ou “Datasets que são tão grandes e tão complexos que os aplicativos tradicionais de processamento de dados são inadequados”.
Efeito Inicial de Big Data sobre o Padrão Simples de Pipeline
Os programas que realizam transformações periódicas ou contínuas em Big Data são geralmente chamados de “pipelines simples e de uma fase”.
Dada a escala e complexidade de processamento inerente ao Big Data, os programas são tipicamente organizados numa série encadeada, com a saída de um programa se tornando a entrada para o próximo. Pode haver razões variadas para este arranjo, mas é tipicamente concebido para facilitar o raciocínio sobre o sistema e não normalmente orientado para a eficiência operacional. Os programas organizados desta forma são chamados pipelines multifásicos porque cada programa da cadeia atua como uma fase discreta de processamento de dados.
O número de programas encadeados em série é uma medida conhecida como a profundidade de um Pipeline. Assim, um pipeline raso pode ter apenas um programa com uma medição de profundidade de pipeline correspondente de um, enquanto um pipeline profundo pode ter uma profundidade de pipeline em dezenas ou centenas de programas.
Desafios com o Padrão de Pipeline Periódico
Os pipelines periódicos geralmente são estáveis quando há trabalhadores suficientes para o volume de dados e a demanda de execução está dentro da capacidade computacional. Além disso, instabilidades como gargalos de processamento são evitadas quando o número de trabalhos encadeados e a taxa de transferência relativa entre os trabalhos permanecem uniformes.
Os pipelines periódicos são úteis e práticos, e os executamos regularmente no Google. Eles são escritos com estruturas como MapReduce [Dea04] e Flume [Cha10], entre outros.
No entanto, a experiência coletiva da SRE tem sido que o modelo de pipeline periódico é frágil. Descobrimos que quando um pipeline periódico é instalado pela primeira vez com o dimensionamento do trabalhador, a periodicidade, a técnica de agrupamento, e outros parâmetros cuidadosamente ajustados, o desempenho é inicialmente confiável. No entanto, o crescimento orgânico e a mudança inevitavelmente começam a estressar o sistema, e surgem problemas. Exemplos de tais problemas incluem trabalhos que excedem o seu prazo de execução, esgotamento de recursos, e blocos de processamento suspensos que implicam uma carga operacional correspondente.
Problemas causados por uma distribuição desigual do trabalho
O principal avanço do Big Data é a aplicação generalizada de algoritmos “embaraçosamente paralelos” [Mol86] para cortar uma grande carga de trabalho em pedaços pequenos o suficiente para caber em máquinas individuais. Por vezes, os pedaços requerem uma quantidade desigual de recursos em relação uns aos outros, e raramente é óbvio inicialmente porque é que determinados pedaços requerem quantidades diferentes de recursos. Por exemplo, em uma carga de trabalho particionada por cliente, os blocos de dados de alguns clientes podem ser muito maiores do que outros. Como o cliente é o ponto de indivisibilidade, o tempo de execução de ponta a ponta é assim limitado ao tempo de execução do maior cliente.
O problema do “bloco suspenso” pode ocorrer quando os recursos são atribuídos devido a diferenças entre as máquinas num cluster ou superalocação para um trabalho. Este problema surge devido à dificuldade de algumas operações em tempo real em fluxos tais como a classificação de dados “steaming”. O padrão de código de usuário típico é esperar que a computação total seja concluída antes de avançar para o próximo estágio do pipeline, geralmente porque a classificação pode estar envolvida, o que exige que todos os dados continuem. Isso pode atrasar significativamente o tempo de conclusão do pipeline, porque a conclusão é bloqueada no pior dos casos, tal como ditado pela metodologia de processamento de dados em uso.
Se este problema for detectado por engenheiros ou por infraestruturas de monitorização de clusters, a resposta pode piorar a situação. Por exemplo, a resposta “sensata” ou “padrão” a um “bloco suspenso” é encerrar imediatamente o trabalho e permitir que ele reinicie, porque o bloqueio pode muito bem ser o resultado de fatores não determinísticos. No entanto, como as implementações de pipeline por design geralmente não incluem checkpoints, o trabalho em todos os blocos é reiniciado desde o início, desperdiçando tempo, ciclos de CPU e esforço humano investido no ciclo anterior.
Desvantagens de Pipelines Periódicos em Ambientes Distribuídos
Os pipelines periódicos de Big Data são amplamente usados no Google e, portanto, a solução de gerenciamento de cluster do Google inclui um mecanismo de agendamento alternativo para esses pipelines. Esse mecanismo é necessário porque, diferentemente dos pipelines em execução contínua, os pipelines periódicos geralmente são executados como trabalhos em lote de prioridade mais baixa. Uma designação de prioridade mais baixa funciona bem nesse caso porque o trabalho em lote não é sensível à latência da mesma forma que os serviços da Web voltados para a Internet. Além disso, a fim de controlar o custo maximizando a carga de trabalho das máquinas, Borg (sistema de gestão de clusters do Google) atribui trabalho em lote às máquinas disponíveis. Esta prioridade pode resultar numa latência de inicialização degradada, de modo que os trabalhos de pipeline podem potencialmente sofrer atrasos de inicialização em aberto.
Os trabalhos invocados através deste mecanismo têm uma série de limitações naturais, resultando em vários comportamentos distintos. Por exemplo, os trabalhos programados nas lacunas deixadas pelos trabalhos de serviços web voltados para o usuário podem ser afetados em termos de disponibilidade de recursos de baixa latência, preços e estabilidade do acesso aos recursos. O custo de execução é inversamente proporcional ao atraso de inicialização solicitado, e diretamente proporcional aos recursos consumidos. Embora a programação de lotes possa funcionar sem problemas na prática, o uso excessivo do agendador de lotes (Capítulo 24) coloca os trabalhos em risco de preempção, quando a carga do cluster é alta porque outros usuários estão sem recursos em lote. Tendo em conta as compensações de risco, a execução bem-sucedida de um pipeline periódico bem ajustado é um equilíbrio delicado entre o alto custo dos recursos e o risco de preempções.
Atrasos de até algumas horas podem muito bem ser aceitáveis para pipelines que são executados diariamente. Contudo, à medida que a frequência de execução programada aumenta, o tempo mínimo entre execuções pode rapidamente atingir o ponto de atraso médio mínimo, colocando um limite inferior na latência que um pipeline periódico pode esperar atingir. A redução do intervalo de execução do trabalho abaixo deste limite inferior eficaz resulta simplesmente num comportamento indesejável em vez de aumentar o progresso. O modo de falha específico depende da política de programação de lotes em uso. Por exemplo, cada nova execução pode acumular-se no agendador de cluster porque a execução anterior não está completa. Pior ainda, a execução atual e quase terminada poderia ser interrompida quando a próxima execução estivesse agendada para começar, parando completamente todo o progresso em nome de execuções crescentes.
Note onde a linha de intervalo de inatividade em declive intersecta o atraso de programação na Figura 25-1. Neste cenário, a redução do intervalo de execução muito abaixo dos 40 minutos para este trabalho de ~20 minutos resulta em execuções potencialmente sobrepostas com consequências indesejadas.
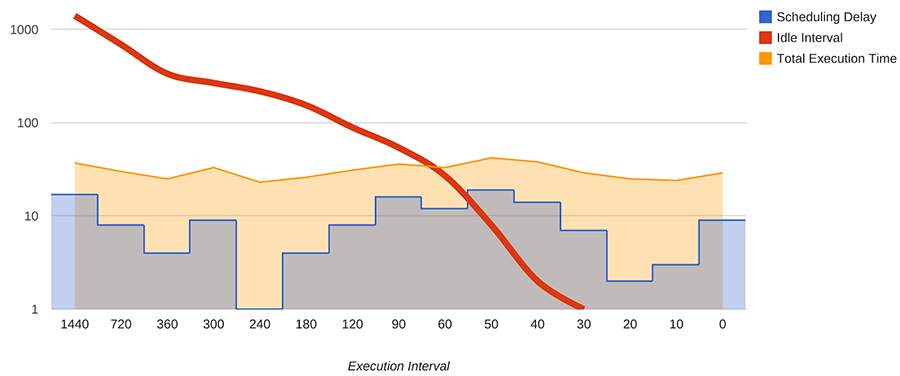
Figure 25-1. Periodic pipeline execution interval versus idle time (log scale)
A solução para este problema é assegurar uma capacidade de servidor suficiente para um funcionamento adequado. No entanto, a aquisição de recursos num ambiente partilhado e distribuído está sujeita à oferta e à procura. Como esperado, as equipes de desenvolvimento tendem a ser relutantes em passar pelos processos de aquisição de recursos quando os recursos devem ser contribuídos para um pool comum e partilhados. Para resolver este problema, tem de ser feita uma distinção entre recursos de programação de lotes versus recursos prioritários de produção para racionalizar os custos de aquisição de recursos.
Problemas de monitoramento em Pipelines periódicos
Para pipelines com duração de execução suficiente, ter informações em tempo real sobre as métricas de desempenho de tempo de execução pode ser tão importante, se não mais importante, do que conhecer as métricas gerais. Isto porque os dados em tempo real são importantes para fornecer suporte operacional, incluindo resposta a emergências. Na prática, o modelo de monitoramento padrão envolve a coleta de métricas durante a execução do trabalho, e a comunicação de métricas apenas após a conclusão do mesmo. Se o trabalho falhar durante a execução, não são fornecidas estatísticas.
Os pipelines contínuos não compartilham esses problemas porque suas tarefas estão em execução constante e sua telemetria é projetada rotineiramente para que as métricas em tempo real estejam disponíveis. Os pipelines periódicos não devem ter problemas de monitoramento inerentes, mas observamos uma forte associação.
Problemas “Thundering Herd”
Somando-se aos desafios de execução e monitorização está o problema do “thundering herd” endêmico em sistemas distribuídos, também discutido em Agendamento periódico distribuído com Cron. Dado um pipeline periódico suficientemente grande, para cada ciclo, potencialmente milhares de trabalhadores iniciam imediatamente o trabalho. Se houver demasiados trabalhadores ou se os trabalhadores forem mal configurados ou invocados por uma lógica de repetição defeituosa, os servidores em que funcionam serão sobrecarregados, assim como os serviços de cluster partilhados subjacentes, e qualquer infraestrutura de rede que estava sendo utilizada será também sobrecarregada.
Se esta situação piorar ainda mais, se a lógica de repetição não for implementada, podem surgir problemas de correção quando o trabalho é abandonado em caso de falha, e o trabalho não será novamente repetido. Se a lógica de repetição estiver presente, mas for simples ou mal implementada, a repetição em caso de falha pode agravar o problema.
A intervenção humana também pode contribuir para esse cenário. Engenheiros com experiência limitada no gerenciamento de pipelines tendem a amplificar esse problema adicionando mais trabalhadores ao pipeline quando o trabalho não é concluído dentro de um período de tempo desejado.
Independentemente da origem do problema do “thundering herd”, nada é mais difícil na infraestrutura do cluster e nos SREs responsáveis pelos vários serviços de um cluster do que um trabalho de pipeline de 10.000 trabalhadores com erros.
Padrão de Carga Moiré
Por vezes, o problema do Thundering herd pode não ser óbvio para detectar isoladamente. Um problema relacionado que chamamos “padrão de carga Moiré” ocorre quando dois ou mais pipelines são executados simultaneamente e suas sequências de execução ocasionalmente se sobrepõem, fazendo com que eles consumam simultaneamente um recurso compartilhado comum. Este problema pode ocorrer mesmo em pipelines contínuos, embora seja menos comum quando a carga chega de forma mais uniforme.
Os padrões de carga moiré são mais aparentes em gráficos de uso de pipeline de recursos compartilhados. Por exemplo, a Figura 25-2 identifica a utilização de recursos de três pipelines periódicos. Na Figura 25-3, que é uma versão empilhada dos dados do gráfico anterior, o pico de impacto para se estar de sobreaviso ocorre quando a carga agregada se aproxima de 1,2M.
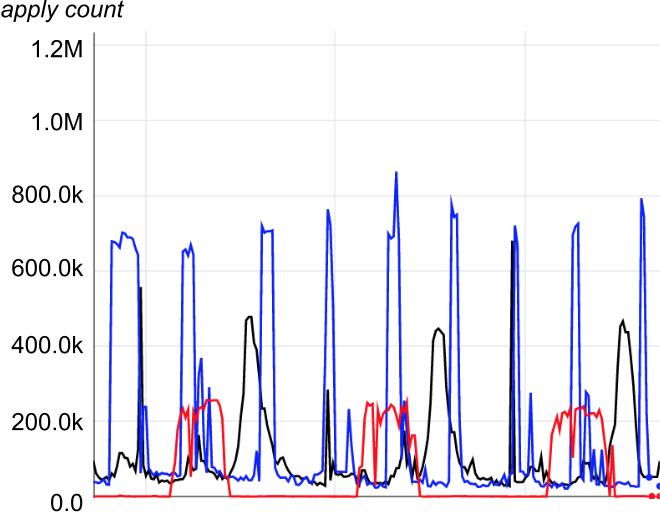
Figure 25-2. Moiré load pattern in separate infrastructure
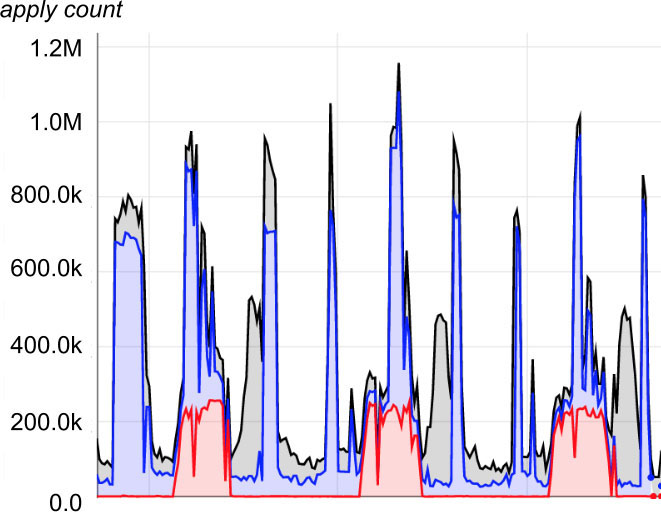
Figure 25-3. Moiré load pattern in shared infrastructure
Introdução ao Google Workflow
Quando um pipeline de lotes inerentemente único é sobrecarregado por exigências comerciais de resultados continuamente atualizados, a equipe de desenvolvimento do pipeline considera geralmente ou a refatoração do design original para satisfazer as exigências atuais, ou a mudança para um modelo de pipeline contínuo. Infelizmente, as exigências comerciais ocorrem geralmente no momento menos conveniente para refatorar o sistema de pipeline num sistema de processamento contínuo online. Os clientes mais recentes e maiores que são confrontados com questões de escala forçada, tipicamente também querem incluir novas características, e esperam que estes requisitos adiram a prazos imutáveis. Ao antecipar este desafio, é importante apurar vários detalhes no início da concepção de um sistema que envolva uma proposta de pipeline de dados. Certifique-se de definir o escopo da trajetória de crescimento esperada, demanda por modificações de design, recursos adicionais esperados e requisitos de latência esperados da empresa.
Face a estas necessidades, a Google desenvolveu em 2003 um sistema denominado “Workflow” que torna o processamento contínuo disponível em escala. O Workflow utiliza o padrão de concepção de sistemas distribuídos por líderes (Workers) e o padrão de concepção de prevalência do sistema. Esta combinação permite pipeline de dados transacionais em larga escala, assegurando a correção com a semântica exata.
Workflow como padrão Model-View-Controller
Devido à forma como a prevalência do sistema funciona, pode ser útil pensar no Workflow como o equivalente dos sistemas distribuídos do padrão model-view-controller conhecido do desenvolvimento da interface do usuário. Como mostra a Figura 25-4, este padrão de design divide um determinado aplicativo de software em três partes interligadas para separar as representações internas de informação das formas como a informação é apresentada ou aceita pelo usuário.
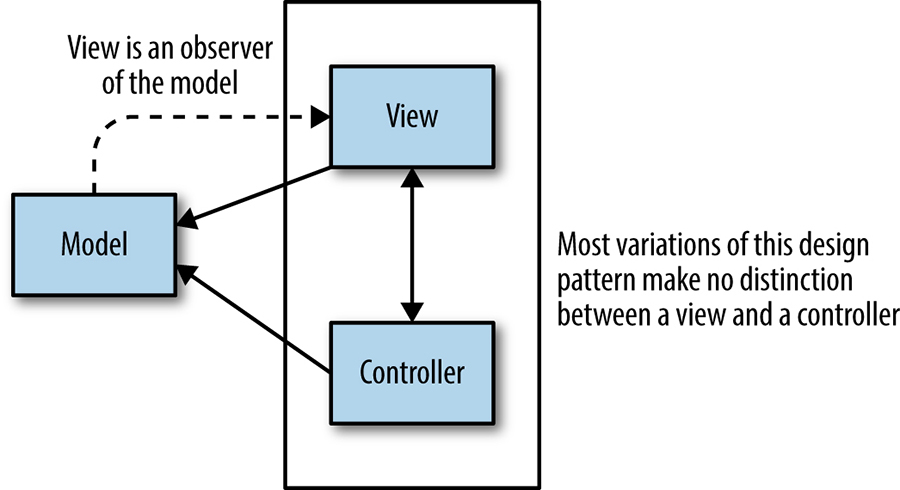
Figura 25-4. O padrão do model-view-controller utilizado no desenho da interface do utilizador
Adaptando este padrão para o Workflow, O model é realizado num servidor chamado “Task Master”. O Task Master utiliza o padrão de prevalência do sistema para manter todos os estados de trabalho na memória para uma rápida disponibilidade enquanto faz o diário sincronizado das mutações para disco persistente. O View é os trabalhadores que continuamente atualizam o estado do sistema transacionalmente com o master de acordo com a sua perspectiva como um subcomponente do pipeline. Embora todos os dados do pipeline possam ser armazenados no Task Master, o melhor desempenho é geralmente alcançado quando apenas as indicações para trabalhar são armazenadas no Task Master, e os dados reais de entrada e saída são armazenados num sistema de ficheiros comum ou noutro tipo de armazenamento. Apoiando esta analogia, os Workers ficam completamente sem estado e podem ser descartados a qualquer momento. Um controller pode opcionalmente ser acrescentado como um terceiro componente do sistema para apoiar eficazmente uma série de atividades auxiliares do sistema que afetam o pipeline, tais como a escala do tempo de execução do pipeline, snapshotting, controle do estado do ciclo de trabalho, estado do pipeline de retorno, ou mesmo a realização de interdição global para a continuidade do negócio. A figura 25-5 ilustra o padrão de design.
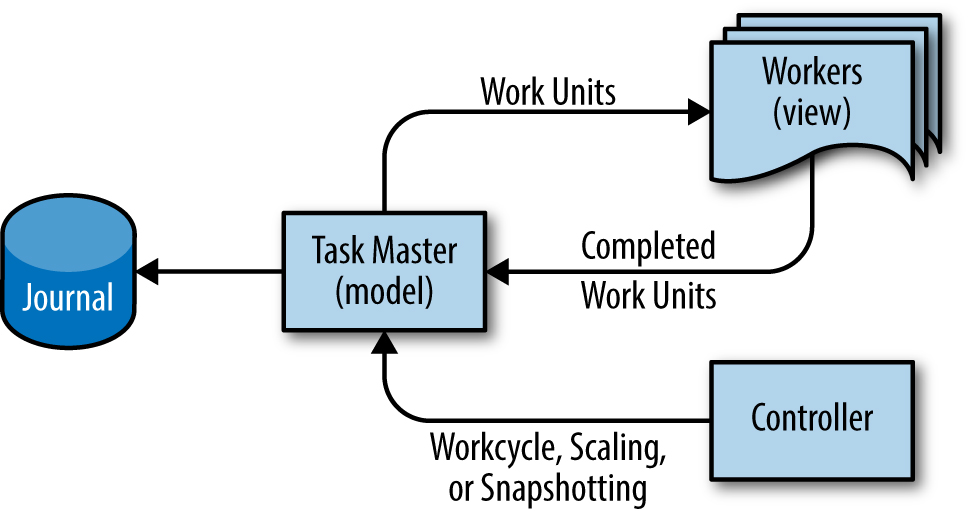
Figura 25-5. O padrão de design do model-view-controller adaptado para o Google Workflow
Etapas de Execução no Workflow
Podemos aumentar a profundidade do pipeline para qualquer nível dentro do Workflow subdividindo o processamento em grupos de tarefas realizadas no Task Master. Cada grupo de tarefas realiza o trabalho correspondente a uma fase de pipeline que pode realizar operações arbitrárias sobre alguns dados. É relativamente simples efetuar o mapeamento, embaralhamento, classificação, divisão, fusão, ou qualquer outra operação em qualquer fase.
Uma fase tem normalmente algum tipo de trabalhador associado a ela. Pode haver múltiplas instâncias simultâneas de um determinado tipo de trabalhador, e os trabalhadores podem ser auto-agendados no sentido em que podem procurar diferentes tipos de trabalho e escolher o tipo a executar.
O trabalhador consome unidades de trabalho de uma fase anterior e produz unidades de produção. A produção pode ser um ponto final ou uma entrada para alguma outra fase de processamento. Dentro do sistema, é fácil garantir que todo o trabalho seja executado, ou pelo menos refletido em estado permanente, exatamente uma vez.
Garantias de correcção do Workflow
Não é prático armazenar todos os detalhes do estado do pipeline dentro do Task Master, porque o Task Master é limitado pelo tamanho da RAM. No entanto, persiste uma dupla garantia de correção, porque o Master detém uma coleção de indicações de dados com nomes exclusivos, e cada unidade de trabalho tem um contrato de arrendamento exclusivo. Os trabalhadores adquirem trabalho com um contrato de arrendamento e só podem comprometer o trabalho de tarefas para as quais possuem atualmente um contrato de arrendamento válido.
Para evitar a situação em que um trabalhador órfão possa continuar trabalhando numa unidade de trabalho, destruindo assim o trabalho do trabalhador atual, cada ficheiro de saída aberto por um trabalhador tem um nome único. Desta forma, mesmo os trabalhadores órfãos podem continuar a escrever independentemente do Master até tentarem comprometer-se. Ao tentarem comprometer-se, não o poderão fazer porque outro trabalhador detém o arrendamento dessa unidade de trabalho. Além disso, os trabalhadores órfãos não podem destruir o trabalho produzido por um trabalhador válido, porque o esquema de nome de ficheiro único assegura que cada trabalhador esteja escrevendo em um ficheiro distinto. Desta forma, a dupla garantia de correção mantém-se: os ficheiros de saída são sempre únicos, e o estado do pipeline é sempre correto em virtude das tarefas com contratos de arrendamento.
Como se uma dupla garantia de correção não fosse suficiente, o Workflow também faz versões de todas as tarefas. Se a tarefa for atualizada ou o arrendamento da tarefa for alterado, cada operação produzirá uma nova tarefa exclusiva substituindo a anterior, com um novo ID atribuído à tarefa. Uma vez que toda a configuração de pipeline no Workflow é armazenada no interior do Task Master na mesma forma que as próprias unidades de trabalho, para comprometer o trabalho, um trabalhador deve possuir um arrendamento ativo e referenciar o número ID da tarefa da configuração que utilizou para produzir o seu resultado. Se a configuração foi alterada enquanto a unidade de trabalho estava em execução, todos os trabalhadores desse tipo serão incapazes de se comprometerem, apesar de possuírem os contratos de arrendamento atuais. Assim, todo o trabalho realizado após uma mudança de configuração é consistente com a nova configuração, ao custo de trabalho sendo jogado fora por trabalhadores infelizes o suficiente para manter os antigos arrendamentos.
Estas medidas fornecem uma garantia tripla de correção: configuração, propriedade do arrendamento, e exclusividade do nome do ficheiro. No entanto, mesmo isto não é suficiente para todos os casos.
Por exemplo, e se o endereço da rede do Task Master mudasse, e um Task Master diferente o substituísse no mesmo endereço? E se uma corrupção da memória alterasse o endereço IP ou o número da porta, resultando num outro Task Master do outro lado? Mais comum ainda, e se alguém (des)configurou a sua Task Master inserindo um balanceador de carga na frente de um conjunto de Task Masters independentes?
O workflow incorpora um token de servidor, um identificador único para esta Task Master em particular, nos metadados de cada tarefa para evitar que uma Task Master desonesta ou incorretamente configurada corrompa o pipeline. Tanto o cliente como o servidor verificam o token em cada operação, evitando uma configuração incorreta muito sutil na qual todas as operações são executadas sem problemas até que ocorra uma colisão de identificador de tarefa.
Em resumo, as quatro garantias de correção dos Workflow são:
- A saída do trabalhador através de tarefas de configuração cria barreiras sobre as quais se pode basear o trabalho.
- Todo o trabalho comprometido requer um contrato de arrendamento atualmente válido detido pelo trabalhador.
- Os ficheiros de saída são nomeados de forma única pelos trabalhadores.
- O cliente e o servidor validam o próprio Task Master verificando um token de servidor em cada operação
Nesta altura, poderá ocorrer-lhe que seria mais simples renunciar ao Task Master especializado e utilizar Spanner ou outro banco de dados. No entanto, o Workflow é especial porque cada tarefa é única e imutável. Estas propriedades gêmeas impedem a ocorrência de muitos problemas potencialmente sutis com distribuição de trabalho em larga escala.
Por exemplo, o arrendamento obtido pelo trabalhador é parte da própria tarefa, exigindo uma tarefa totalmente nova mesmo para alterações de arrendamento. Se um banco de dados for utilizado diretamente e os seus logs de transação funcionarem como um “diário”, cada leitura deve fazer parte de uma transação a longo prazo. Esta configuração é certamente possível, mas terrivelmente ineficiente.
Assegurar a continuidade dos negócios
Os pipelines de Big Data precisam continuar o processamento apesar de falhas de todos os tipos, incluindo cortes de fibra, eventos meteorológicos, e falhas na rede elétrica em cascata. Estes tipos de falhas podem desativar datacenters inteiros. Além disso, os pipelines que não empregam a prevalência do sistema para obter fortes garantias sobre a conclusão do trabalho são frequentemente desativados e entram num estado indefinido. Esta lacuna de arquitetura torna a estratégia de continuidade de negócio frágil, e implica uma dispendiosa duplicação em massa de esforços para restaurar os pipelines e os dados.
O Workflow resolve este problema de forma conclusiva para pipelines de processamento contínuo. Para obter consistência global, o Task Master armazena diários em Spanner, utilizando-o como um sistema de ficheiros globalmente disponível, globalmente consistente, mas de baixo rendimento. Para determinar qual Task Master pode escrever, cada Task Master utiliza o serviço de bloqueio distribuído chamado Chubby para eleger o escritor, e o resultado é persistido no Spanner. Finalmente, os clientes procuram a Task Master atual utilizando serviços internos de nomenclatura.
Uma vez que o Spanner não permite um sistema de ficheiros de alto rendimento, os Workflows distribuídos globalmente empregam dois ou mais Workflows locais que funcionam em clusters distintos, além de uma noção de tarefas de referência armazenadas no Workflow global. Como as unidades de trabalho (tarefas) são consumidas através de um pipeline, tarefas de referência equivalentes são inseridas no Workflow global pelo binário rotulado “fase 1” na Figura 25-6. À medida que as tarefas terminam, as tarefas de referência são removidas transacionalmente do Workflow global, conforme ilustrado na “fase n” da Figura 25-6. Se as tarefas não puderem ser removidas do Workflow global, o Workflow local será bloqueado até o Workflow global ficar novamente disponível, assegurando a correção transacional.
Para automatizar o failover, um binário auxiliar rotulado “fase 1” na Figura 25-6 é executado dentro de cada Workflow local. O Workflow local é inalterado, como descrito pela caixa “fazer trabalho” no diagrama. Este binário auxiliar atua como “controller” no sentido MVC, e é responsável pela criação de tarefas de referência, bem como pela atualização de uma tarefa especial de batimento cardíaco dentro do Workflow global. Se a tarefa de batimento cardíaco não for atualizada dentro do período de tempo limite, o binário auxiliar remoto do Workflow apreende o trabalho em curso, tal como documentado pelas tarefas de referência, e o pipeline continua, sem qualquer impedimento por parte do ambiente que possa fazer ao trabalho.
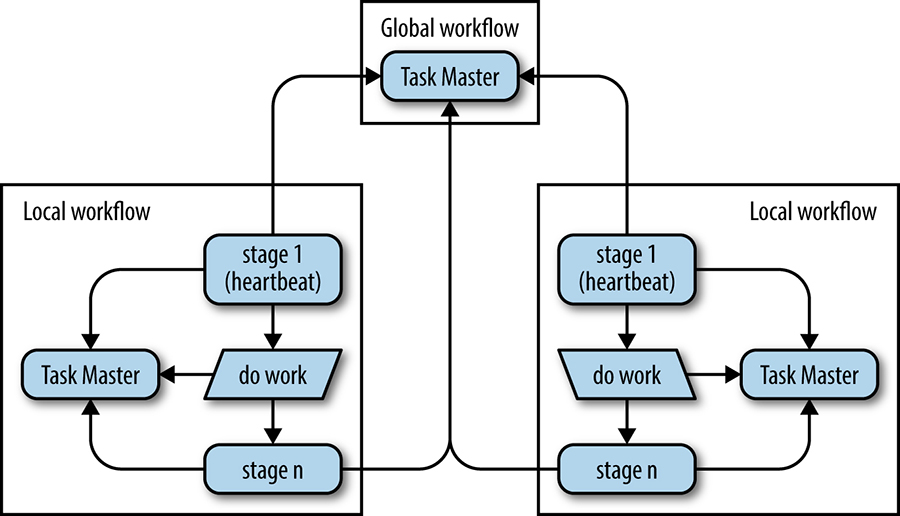
Figura 25-6. Um exemplo de dados distribuídos e fluxo de processo utilizando de Workflow pipelines
Resumo e Observações Finais
Os pipelines periódicos são valiosos. No entanto, se um problema de processamento de dados for contínuo ou se crescer organicamente para se tornar contínuo, não utilize um pipeline periódico. Em vez disso, utilize uma tecnologia com características semelhantes às do Workflow.
Descobrimos que o processamento contínuo de dados com fortes garantias, tal como fornecido pelo Workflow, executa e dimensiona bem a infraestrutura de clusters distribuídos, produz rotineiramente resultados em que os usuários podem confiar, e é um sistema estável e confiável para a equipe de Engenharia de Confiabilidade do Site gerenciar e manter.