Escrito por Niall Murphy com Alex Rodriguez, Carl Crous, Dario Freni, Dylan Curley, Lorenzo Blanco, e Todd Underwood
Editado por Betsy Beyer
A posição organizacional do SRE no Google é interessante, e tem efeitos na forma como comunicamos e colaboramos.
Para começar, há uma enorme diversidade no que o SRE faz, e como o fazemos. Temos equipes de infraestruturas, equipes de serviços, e equipes de produtos horizontais. Temos relacionamentos com equipes de desenvolvimento de produto que vão desde equipes que são muitas vezes do nosso tamanho, a equipes aproximadamente do mesmo tamanho que as suas contrapartes, e situações em que somos a equipe de desenvolvimento de produto. As equipes SRE são constituídas por pessoas com competências de engenharia de sistemas ou arquitetura, competências de engenharia de software, competências de gestão de projetos, instintos de liderança, antecedentes em todos os tipos de indústrias (ver Capítulo 33), e assim por diante. Não temos apenas um modelo, e encontramos uma variedade de configurações que funcionam; esta flexibilidade adapta-se à nossa natureza pragmática em última análise.
É também verdade que o SRE não é uma organização de comando e controle. Geralmente, devemos fidelidade a pelo menos dois mestres: para equipes de serviço ou infraestruturas SRE, trabalhamos em estreita colaboração com as equipes de desenvolvimento de produtos correspondentes que trabalham nesses serviços ou nessas infraestruturas; trabalhamos também, obviamente, no contexto do SRE em geral. A relação de serviço é muito forte, uma vez que somos responsabilizados pelo desempenho desses sistemas, mas apesar dessa relação, as nossas atuais linhas de informação são através do SRE como um todo. Hoje, passamos mais tempo apoiando os nossos serviços individuais do que no trabalho de produção cruzada, mas a nossa cultura e os nossos valores partilhados produzem abordagens fortemente homogêneas aos problemas. Isso ocorre por design.
Os dois fatos anteriores conduziram a organização do SRE em determinadas direções quando se trata de duas dimensões cruciais da forma como as nossas equipes operam – comunicação e colaboração. O fluxo de dados seria uma metáfora de computação adequada para as nossas comunicações: tal como os dados devem fluir em torno da produção, os dados também têm que fluir em torno de uma equipe SRE – dados sobre os projetos, o estado dos serviços, a produção, e o estado dos indivíduos. Para a máxima eficácia de uma equipe, os dados devem fluir de forma confiável de uma parte interessada para outra. Uma maneira de pensar neste fluxo é pensar na interface que uma equipe SRE tem de apresentar a outras equipes, como por exemplo um API. Assim como um API, um bom design é crucial para uma operação eficaz e, se o API estiver errado, pode ser doloroso corrigi-lo mais tarde.
O API como metáfora do contrato é também relevante para a colaboração, tanto entre as equipes SRE, como entre o SRE e as equipes de desenvolvimento de produtos – todos precisam progredir em um ambiente de mudança incessante. Nessa medida, a nossa colaboração assemelha-se bastante à colaboração em qualquer outra empresa em rápida evolução. A diferença é a mistura de competências de engenharia de software, conhecimentos de engenharia de sistemas, e a sabedoria da experiência de produção que o SRE traz para essa colaboração. Os melhores designs e as melhores implementações resultam das preocupações conjuntas da produção e do produto a ser atendido numa atmosfera de respeito mútuo. Esta é a promessa do SRE: uma organização encarregada da confiabilidade, com as mesmas competências que as equipes de desenvolvimento do produto, melhorará as coisas de forma mensurável. A nossa experiência sugere que simplesmente ter alguém responsável pela confiabilidade, sem ter também o conjunto completo de competências, não é suficiente.
Comunicações: reuniões de produção
Embora abunde literatura sobre a realização de reuniões eficazes, é difícil encontrar alguém que tenha a sorte de ter apenas reuniões úteis e eficazes. Isto é igualmente verdade para o SRE.
Contudo, há um tipo de reunião que temos que é mais útil do que a média, chamada reunião de produção. As reuniões de produção são um tipo especial de reunião em que uma equipe de SRE articula cuidadosamente para si mesma – e para os seus convidados – o estado do(s) serviço(s) sob sua responsabilidade, de modo a aumentar a conscientização geral entre todos os que se preocupam, e a melhorar o funcionamento do(s) serviço(s). Em geral, estas reuniões são orientadas para o serviço; não são diretamente sobre a atualização do estado dos indivíduos. O objetivo é que todos saiam da reunião com uma ideia do que está acontecendo – a mesma ideia. O outro grande objetivo das reuniões de produção é o de melhorar os nossos serviços, trazendo a sabedoria da produção para os nossos serviços. Isto significa que falamos em pormenor sobre o desempenho operacional do serviço, e relacionamos esse desempenho operacional com o design, configuração, ou implementação, e fazemos recomendações sobre a forma de resolver os problemas. Conectar o desempenho do serviço com as decisões de design em uma reunião regular é um loop de feedback imensamente poderoso.
Nossas reuniões de produção costumam acontecer semanalmente; dada a antipatia do SRE para com reuniões inúteis, esta frequência parece ser quase certa: tempo para permitir a acumulação de material relevante suficiente para que a reunião valha a pena, embora não seja tão frequente que as pessoas encontrem desculpas para não comparecer. Normalmente duram entre 30 e 60 minutos. Menos e você provavelmente está cortando algo desnecessariamente curto, ou provavelmente deveria estar aumentando seu portfólio de serviços. Mais e você provavelmente está ficando atolado nos detalhes, ou você tem muito o que falar e deve dividir a equipe ou o conjunto de serviços.
Assim como qualquer outra reunião, a reunião de produção deve ter um presidente. Muitas equipes de SRE alternam a presidência entre vários membros da equipe, o que tem a vantagem de fazer com que todos sintam que têm uma participação no serviço e alguma propriedade teórica das questões. É verdade que nem todos têm níveis iguais de capacidade de presidência, mas o valor da propriedade do grupo é tão grande que vale a pena a troca de uma subotimização temporária. Além disso, esta é uma oportunidade para incutir capacidades de presidência, que são muito úteis no tipo de situações de coordenação de incidentes com que o SRE normalmente se depara.
Nos casos em que duas equipes SRE se reúnem por vídeo, e uma das equipes é muito maior do que a outra, temos notado uma dinâmica interessante em jogo. Recomendamos que coloque a sua cadeira no lado mais pequeno da chamada, por padrão. O lado maior naturalmente tende a se acalmar e alguns dos efeitos ruins de tamanhos de equipes desequilibrados (agravados pelos atrasos inerentes à videoconferência) irão melhorar. Não temos ideia se esta técnica tem alguma base científica, mas tende a funcionar.
Agenda
Há muitas maneiras de realizar uma reunião de produção, atestando a diversidade do que o SRE cuida e como o fazemos. Nessa medida, não é apropriado ser prescritivo sobre como conduzir uma dessas reuniões. No entanto, uma agenda padrão (ver Exemplo de Atas de Reunião de Produção para um exemplo) pode parecer algo como o que se segue:
Próximas mudanças de produção
As reuniões de acompanhamento de mudanças são bem conhecidas em todo o setor, e de fato, reuniões inteiras têm sido frequentemente dedicadas a interromper a mudança. No entanto, em nosso ambiente de produção, geralmente adotamos como padrão a ativação da mudança, o que requer o rastreamento do conjunto útil de propriedades dessa mudança: hora de início, duração, efeito esperado e assim por diante. Esta é a visibilidade do horizonte de curto prazo.
Métricas
Uma das principais formas de conduzir uma discussão orientada para os serviços é falando sobre as métricas centrais dos sistemas em questão; ver Capítulo 4 . Mesmo que os sistemas não tenham falhado dramaticamente naquela semana, é muito comum estar em uma posição em que você está olhando para um aumento gradual (ou acentuado!) de carga ao longo do ano. Manter-se a par de como os seus números de latência, números de utilização de CPU, etc., mudam ao longo do tempo é incrivelmente valioso para desenvolver um sentimento para o envelope de desempenho de um sistema.
Algumas equipes acompanham a utilização e eficiência dos recursos, o que é também um indicador útil de mudanças mais lentas, talvez mais insidiosas do sistema.
Interrupções
Este item aborda problemas de tamanho aproximadamente post-mortem, e é uma oportunidade indispensável para a aprendizagem. Uma boa análise post-mortem, tal como discutido no Capítulo 15, deve sempre estabelecer inspiração.
Eventos de notificação de alertas
Estas são alertas do seu sistema de monitoramento, relacionadas com problemas que podem ser merecedores de postmortem, mas que muitas vezes não o são. Em qualquer caso, enquanto a parte de Interrupções olha para a imagem maior de uma interrupção, esta seção olha para a visão tática: a lista de alertas, quem foi acionado, o que aconteceu nessa altura, e assim por diante. Há duas questões implícitas para esta seção: deveria esse alerta ter notificado da forma como o fez, e deveria ter notificado mesmo? Se a resposta à última pergunta for não, remova esses alertas inutilizáveis.
Eventos sem notificação de alertas
Este intervalo contém três pontos:
- Um problema que provavelmente deveria ter alertado, mas não o foi. Nestes casos, é provável que se deva corrigir o monitoramento para que tais eventos acionem um plantonista. Muitas vezes, você encontra o problema enquanto tenta corrigir outra coisa ou está relacionado a uma métrica que você está rastreando, mas para a qual você não recebeu um alerta.
- Um problema que não é alertado mas que requer atenção, tal como a corrupção de dados de baixo impacto ou lentidão em alguma dimensão do sistema não voltada para o usuário. O rastreamento do trabalho operacional reativo também é apropriado aqui.
- Um problema que não é alertado e não requer atenção. Estes alertas devem ser removidos, porque criam ruído extra que distrai os engenheiros de problemas que merecem atenção.
Itens de ação prévia
As discussões detalhadas precedentes conduzem frequentemente a ações que o SRE precisa tomar para corrigir isto, monitorizar aquilo, desenvolver um subsistema para fazer o outro. Acompanhe estas melhorias tal como seriam seguidas em qualquer outra reunião: atribua itens de ação às pessoas e acompanhe o seu progresso. É uma boa ideia ter um ponto de agenda explícito que atue como um ponto de captação, pelo menos. Uma entrega consistente é também um formidável construtor de credibilidade e confiança. Não importa como tal entrega é feita, apenas que seja feita.
Frequência
A participação é obrigatória para todos os membros da equipe do SRE em questão. Isto é particularmente verdade se a sua equipe estiver espalhada por vários países e/ou fusos horários, porque esta é a sua principal oportunidade de interagir como um grupo.
Os principais interessados devem também estar presentes nesta reunião. Quaisquer equipes de desenvolvimento de produtos parceiras que possa ter devem também estar presentes. Algumas equipes do SRE fragmentam sua reunião para que os assuntos somente do SRE sejam mantidos na primeira metade; essa prática é boa, desde que todos, como foi dito anteriormente, saiam com a mesma ideia do que se passa. De tempos em tempos poderão aparecer representantes de outras equipes SRE, particularmente se houver algum assunto de maior envergadura a discutir, mas em geral, a equipe SRE em questão mais outras equipes importantes devem comparecer. Se a sua relação for tal que não possa convidar os seus parceiros de desenvolvimento de produtos, terá de corrigir essa relação: talvez o primeiro passo seja convidar um representante dessa equipe, ou encontrar um intermediário de confiança para representar a comunicação ou modelar interações saudáveis. Há muitas razões pelas quais as equipes não se dão bem, e uma riqueza de escritos sobre como resolver esse problema: esta informação é também aplicável às equipes SRE, mas é importante que o objetivo final de ter um ciclo de feedback das operações seja cumprido, ou que uma grande parte do valor de ter uma equipe SRE é perdida.
Ocasionalmente, haverá demasiadas equipes ou participantes ainda ocupados para convidar. Há várias técnicas que pode utilizar para lidar com essas situações:
- Os serviços menos ativos podem ser atendidos por um único representante da equipe de desenvolvimento de produto, ou ter apenas o compromisso da equipe de desenvolvimento de produto de ler e comentar as atas da agenda.
- Se a equipe de desenvolvimento de produção for bastante numerosa, nomeie um subconjunto de representantes.
- Os participantes ainda ocupados podem fornecer feedback e/ou orientação prévia a indivíduos, ou utilizar a técnica de agenda previamente preenchida (descrita a seguir).
A maioria das estratégias da reunião que discutimos são de senso comum, com um toque orientado para o serviço. Uma maneira única para tornar as reuniões mais eficientes e mais inclusivas é utilizar os recursos colaborativos em tempo real do Google Docs. Muitas equipes de SRE têm esse documento, com um endereço bem conhecido que qualquer pessoa na engenharia pode acessar. Ter um documento assim possibilita duas ótimas práticas:
- Preencher previamente a agenda com ideias, comentários e informação “de baixo para cima”.
- Preparar a agenda em paralelo e com antecedência é realmente eficiente.
Use plenamente as características de colaboração de múltiplas pessoas permitidas pelo produto. Não há nada como ver um presidente da reunião escrever uma frase, depois ver outra pessoa fornecer um link para o material de origem entre colchetes depois de terminar de digitar e depois ver outra pessoa arrumando a ortografia e a gramática na frase original. Tal colaboração faz com que as coisas sejam feitas mais rapidamente, e faz com que mais pessoas se sintam donas de uma fatia do que a equipe faz.
Colaboração dentro do SRE
Obviamente, a Google é uma organização multinacional. Devido à resposta de emergência e ao componente de rotação de alertas do nosso papel, temos muito boas razões comerciais para sermos uma organização distribuída, separada por pelo menos alguns fusos horários. O impacto prático desta distribuição é que temos definições muito fluidas para “equipe” em comparação, por exemplo, com a equipe média de desenvolvimento de produtos. Temos equipes locais, a equipe no site, a equipe transcontinental, equipes virtuais de vários tamanhos e coerência, e tudo mais. Isto cria uma mistura alegremente caótica de responsabilidades, competências e oportunidades. Muito da mesma dinâmica poderia ser esperada em relação a qualquer empresa suficientemente grande (embora possam ser particularmente intensas para as empresas de tecnologia). Dado que a maioria das colaborações locais não enfrenta nenhum obstáculo específico, o caso interessante em termos de colaboração é entre equipes, entre sites, através de uma equipa virtual, e similares.
Este padrão de distribuição também informa como as equipes SRE tendem a ser organizadas. Como a nossa razão d’être (razão de ser) é agregar valor através do domínio técnico, e o domínio técnico tende a ser difícil, tentamos portanto encontrar uma forma de ter domínio sobre algum subconjunto relacionado de sistemas ou infraestruturas, a fim de diminuir a carga cognitiva. A especialização é uma forma de atingir este objetivo; ou seja, a equipe X trabalha apenas no produto Y. A especialização é boa, porque leva a maiores probabilidades de melhorar o domínio técnico, mas também é má, porque leva à siloização e ao desconhecimento do quadro mais amplo. Tentamos ter uma carta de equipe clara para definir o que uma equipe irá – e mais importante, não irá – apoiar, mas nem sempre conseguimos.
Composição da equipe
Temos uma vasta gama de conjuntos de competências em SRE, desde a engenharia de sistemas à engenharia de software, passando pela organização e gestão. A única coisa que podemos dizer sobre colaboração é que as suas hipóteses de colaboração bem sucedida – e na verdade quase tudo o mais – são melhoradas ao ter mais diversidade na sua equipe. Há muitas provas que sugerem que equipes diversas são simplesmente equipes melhores. Gerir uma equipe diversificada implica uma atenção particular à comunicação, aos preconceitos cognitivos, etc., que não podemos cobrir em detalhes aqui.
Formalmente, as equipes SRE têm os papéis de “líder técnico” (TL), “gestor” (SRM), e “gestor de projeto” (também conhecido como PM, TPM, PgM). Algumas pessoas funcionam melhor quando essas funções têm responsabilidades bem definidas: o grande benefício de poderem tomar decisões dentro do escopo de forma rápida e segura. Outras operam melhor num ambiente mais fluido, com responsabilidades variáveis em função de uma negociação dinâmica. Em geral, quanto mais fluida é a equipe, mais desenvolvida é em termos das capacidades dos indivíduos, e mais capaz é a equipe de se adaptar a novas situações – mas ao custo de ter de se comunicar cada vez mais frequentemente, porque menos antecedentes podem ser assumidos.
Independentemente da forma como estes papéis são definidos, a um nível básico, o líder técnico é responsável pela direção técnica da equipe, e pode conduzir de várias formas – desde comentar cuidadosamente o código de todos, realizar apresentações trimestrais de direção, até à construção de consensos na equipe. No Google, as TLs podem fazer quase todo o trabalho de um gestor, porque os nossos gestores são altamente técnicos, mas o gestor tem duas responsabilidades especiais que uma TL não tem: a função de gestão do desempenho, e ser um catchall geral para tudo o que não é tratado por outra pessoa. As grandes TL, SRM e TPMs têm um conjunto completo de competências e podem alegremente dedicar-se para organizar um projeto, comentando um documento de design, ou escrevendo código, conforme necessário.
Técnicas para trabalhar de forma eficaz
Existem várias formas de fazer engenharia eficaz no SRE.
Em geral, os projetos de singleton falham, a menos que a pessoa seja particularmente dotada ou que o problema seja simples. Para realizar qualquer coisa significativa, são necessárias praticamente várias pessoas. Por conseguinte, também é necessária uma boa capacidade de colaboração. Mais uma vez, foi escrito muito material sobre este tópico, e grande parte desta literatura é aplicável ao SRE.
Em geral, um bom trabalho de SRE exige excelentes capacidades de comunicação quando se está trabalhando fora dos limites da sua equipe puramente local. Para colaborações fora do edifício, trabalhar efetivamente através de fusos horários implica ou uma grande comunicação escrita, ou muitas viagens para fornecer a experiência presencial que é adiável mas, em última análise, necessária para uma relação de alta qualidade. Mesmo que você seja um grande escritor, com o tempo você se torna apenas um endereço de e-mail até que você reapareça em carne e osso novamente.
Estudo de Caso de Colaboração na SRE: Viceroy
Um exemplo de colaboração bem-sucedida entre SREs é um projeto chamado Viceroy, que é uma estrutura e serviço de painel de monitoramento. A atual arquitetura organizacional do SRE pode acabar com equipes que produzem múltiplas cópias ligeiramente diferentes do mesmo trabalho; por várias razões, as estruturas de painéis de monitoramento foram um terreno particularmente fértil para a duplicação de trabalho.
Os incentivos que levaram ao sério problema de lixo de muitas estruturas de monitoramento abandonadas e latentes eram bem simples: cada equipe era recompensada por desenvolver a sua própria solução, trabalhar fora dos limites da equipe era difícil, e a infraestrutura que tendia a ser fornecida a nível do SRE era tipicamente mais próxima de um conjunto de ferramentas do que de um produto. Este ambiente encorajou os engenheiros individuais a utilizarem o kit de ferramentas para fazer outro acidente em vez de reparar o problema para o maior número de pessoas possível (um esforço que, portanto, levaria muito mais tempo).
A vinda do Viceroy
O viceroy era diferente. Começou em 2012, quando várias equipes estavam considerando como migrar para o Monarch, o novo sistema de monitoramento do Google. O SRE é profundamente conservador no que diz respeito aos sistemas de monitoramento, pelo que o Monarch demorou, ironicamente, mais tempo a obter tração dentro do SRE do que dentro das equipes não-SRE. Mas ninguém podia argumentar que o nosso sistema de monitoramento antigo, Borgmon (ver Capítulo 10), não tinha margem para melhorias. Por exemplo, os nossos consoles eram complicados porque utilizavam um sistema de templates HTML personalizado, com um sistema especial, cheio de casos funky edge, e difícil de testar. Nessa altura, Monarch tinha amadurecido o suficiente para ser aceito em princípio como substituto do sistema antigo e estava sendo adotado por cada vez mais equipes através do Google, mas ainda tínhamos problemas com os consoles.
Aqueles de nós que tentaram usar o Monarch para os nossos serviços depressa descobriram que ele ficou aquém do suporte do console por duas razões principais:
- Os consoles eram fáceis de montar para um pequeno serviço, mas não se adaptavam bem a serviços com consoles complexos.
- Também não suportaram o sistema legado de monitoramento, tornando a transição para o Monarch muito difícil.
Como não existia nenhuma alternativa viável para implantar o Monarch dessa maneira na época, foram lançados vários projetos específicos de equipes. Como havia pouco em termos de soluções de desenvolvimento coordenadas ou mesmo rastreamento entre grupos na época (um problema que desde então foi resolvido), acabamos por duplicar esforços mais uma vez. Múltiplas equipes de Spanner, Ads Frontend, e uma variedade de outros serviços aceleraram os seus próprios esforços (um exemplo notável foi chamado Consoles++) ao longo de 12-18 meses, e acabou por prevalecer a sanidade quando engenheiros de todas essas equipes acordaram e descobriram os respectivos esforços uns dos outros. Decidiram fazer o mais sensato e unir forças a fim de criar uma solução geral para todos os SRE. Assim, o projeto Viceroy nasceu em meados de 2012.
No início de 2013, o Viceroy tinha começado a despertar o interesse de equipes que ainda não tinham saído do sistema legado, mas que queriam colocar o pé na água. Obviamente, as equipes com maiores projetos de monitoramento existentes tinham menos incentivos para mudar para o novo sistema: era difícil para estas equipes racionalizar o baixo custo de manutenção da sua solução existente que basicamente funcionava bem, para algo relativamente novo e não provado que exigiria muito esforço para fazer funcionar. A enorme diversidade de requisitos aumentou a relutância destas equipes, embora todos os projetos de console de monitoramento partilhassem dois requisitos principais, nomeadamente:
- Suportar painéis de instrumentos complexos com curadoria
- Apoiar tanto o Monarch como o sistema legado de monitoramento.
Cada projeto tinha também o seu próprio conjunto de requisitos técnicos, que dependiam da preferência ou experiência do autor. Por exemplo:
- Múltiplas fontes de dados fora dos sistemas centrais de monitoramento
- Definição de consoles usando configuração versus layout HTML explícito
- Sem Javascript versus adoção total de Javascript com AJAX
- Uso exclusivo de conteúdo estático, para que os consoles pudessem ser armazenados em cache no browser
Embora alguns destes requisitos fossem mais rígidos do que outros, de um modo geral, dificultavam os esforços de fusão. De fato, embora a equipe Consoles++ estivesse interessada em ver como o seu projeto se comparava ao Viceroy, o seu exame inicial no primeiro semestre de 2013 determinou que as diferenças fundamentais entre os dois projetos eram suficientemente significativas para impedir a integração. A maior dificuldade foi que o Viceroy por design não utilizava muito JavaScript, enquanto o Consoles++ era escrito principalmente em JavaScript. Havia, contudo, um vislumbre de esperança, na medida em que os dois sistemas tinham uma série de semelhanças subjacentes:
- Utilizaram sintaxes semelhantes para a renderização de modelos HTML.
- Partilharam uma série de objetivos a longo prazo, que nenhuma das duas equipes tinha ainda começado a abordar. Por exemplo, ambos os sistemas queriam armazenar em cache os dados de monitoramento e dar suporte a um pipeline offline para produzir periodicamente dados que o console pudesse usar, mas era demasiado caro em termos computacionais para produzir sob demanda.
Acabamos estacionando a discussão do console unificado por um tempo. No entanto, no final de 2013, tanto o Consoles++ como o Viceroy haviam se desenvolvido significativamente. As suas diferenças técnicas tinham diminuído, porque o Viceroy tinha começado a utilizar o JavaScript para apresentar os seus gráficos de monitoramento. As duas equipes reuniram-se e descobriram que a integração era muito mais fácil, agora que a integração se resumia a servir os dados dos Consoles++ a partir do servidor do Viceroy. Os primeiros protótipos integrados foram concluídos no início de 2014, e provaram que os sistemas podiam funcionar bem em conjunto. Ambas as equipes se sentiram à vontade para se empenharem num esforço conjunto nessa altura, e porque o Viceroy já tinha estabelecido a sua marca como uma solução de monitoramento comum, o projeto combinado manteve o nome Viceroy. O desenvolvimento da funcionalidade total levou alguns trimestres, mas no final de 2014, o sistema combinado estava completo.
A união de forças colheu enormes benefícios:
- O Viceroy recebeu uma série de fontes de dados e os clientes JavaScript para acessá-los.
- A compilação JavaScript foi reescrita para suportar módulos separados que podem ser incluídos de forma seletiva. Isto é essencial para dimensionar o sistema para qualquer número de equipes com o seu próprio código JavaScript.
- Os Consoles++ se beneficiaram das muitas melhorias que estão sendo feitas ativamente ao Viceroy, tais como a adição de sua cache e do seu pipeline de dados em segundo plano.
- No geral, a velocidade de desenvolvimento de uma solução foi muito maior do que a soma de toda a velocidade de desenvolvimento dos projetos duplicados.
Em última análise, a visão comum do futuro foi o fator-chave para combinar os projetos. Ambas as equipes encontraram valor na expansão da sua equipe de desenvolvimento e se beneficiaram das contribuições uma da outra. O impulso foi tal que, no final de 2014, o Viceroy foi oficialmente declarado a solução de monitoramento geral para todos os SRE. Talvez caracteristicamente para o Google, esta declaração não exigia que as equipes adotassem o Viceroy: em vez disso, recomendava que as equipes utilizassem o Viceroy, em vez de escreverem outro console de monitoramento.
Os desafios
Embora, em última análise, tenha sido um sucesso, o Viceroy não foi isento de dificuldades, e muitas delas surgiram devido à natureza entre sites do projeto.
Uma vez estabelecida a equipe estendida do Viceroy, a coordenação inicial entre os membros da equipe remota revelou-se difícil. Quando se conhecem pessoas pela primeira vez, as sugestões sutis na escrita e na fala podem ser mal interpretadas, porque os estilos de comunicação variam substancialmente de pessoa para pessoa. No início do projeto, os membros da equipe que não estavam localizados em Mountain View também perderam as discussões improvisadas sobre os refrigeradores de água que frequentemente aconteciam pouco antes e depois das reuniões (embora a comunicação tenha melhorado consideravelmente desde então).
Embora a equipe principal do Viceroy permaneceu bastante consistente, a equipe estendida de colaboradores foi bastante dinâmica. Os colaboradores tiveram outras responsabilidades que mudaram ao longo do tempo, e por isso muitos puderam dedicar entre um e três meses ao projeto. Assim, o grupo de colaboradores do desenvolvedor, que era inerentemente maior do que a equipe principal do Viceroy, caracterizou-se por uma quantidade significativa de rotatividade.
A adição de novas pessoas ao projeto exigiu treinar cada colaborador sobre o design geral e a estrutura do sistema, o que levou algum tempo. Por outro lado, quando um SRE contribuía para a funcionalidade principal do Viceroy e mais tarde regressava à sua própria equipe, era um perito local no sistema. Essa divulgação imprevista dos peritos locais do Viceroy levou a uma maior utilização e adoção.
À medida que as pessoas entravam e saíam da equipe, descobrimos que as contribuições casuais eram úteis e caras. O custo principal era a diluição da propriedade: uma vez que os recursos eram entregues e a pessoa saía, os recursos ficavam sem suporte com o tempo e geralmente eram descartados.
Além disso, o escopo do projeto Viceroy cresceu ao longo do tempo. Tinha objetivos ambiciosos no lançamento, mas o escopo inicial era limitado. No entanto, à medida que o escopo crescia, lutamos para entregar as características principais a tempo, e tivemos de melhorar a gestão do projeto e definir uma direção mais clara para assegurar que o projeto se mantivesse no bom caminho.
Finalmente, a equipe do Viceroy achou difícil possuir completamente um componente que tivesse contribuições significativas (determinantes) de sites distribuídos. Mesmo com a melhor vontade do mundo, as pessoas geralmente não seguem o caminho de menor resistência e discutem questões ou tomam decisões localmente sem envolver os proprietários remotos, o que pode conduzir a conflitos.
Recomendações
Só se deve desenvolver projetos entre sites quando é necessário, mas muitas vezes há boas razões para o fazer. O custo de trabalhar entre sites é a maior latência para as ações e maior necessidade de comunicação; o benefício é – se obtiver a mecânica correta – um rendimento muito superior. O projeto de um único site também pode ser prejudicado por alguém fora desse site que saiba o que você está fazendo, por isso há custos para ambas as abordagens.
Colaboradores motivados são valiosos, mas nem todas as contribuições são igualmente valiosas. Certifique-se de que os colaboradores do projeto estejam realmente comprometidos e não estejam apenas se unindo a algum objetivo nebuloso de autorrealização (querendo ganhar um entalhe no seu cinto anexando o seu nome a um projeto brilhante; querendo codificar num novo projeto excitante sem se comprometerem a manter esse projeto). Colaboradores com um objetivo específico a atingir estarão geralmente mais motivados e manterão melhor as suas contribuições.
À medida que os projetos se desenvolvem, eles geralmente crescem, e nem sempre se encontra na feliz posição de ter pessoas na sua equipe local para contribuir para o projeto. Portanto, pense cuidadosamente sobre a estrutura do projeto. Os líderes do projeto são importantes: proporcionam uma visão a longo prazo para o projeto e asseguram que todo o trabalho se alinha com essa visão e é corretamente priorizado. Também precisam ter uma forma acordada de tomar decisões, e devem otimizar especificamente para tomarem mais decisões localmente se houver um elevado nível de acordo e confiança.
A estratégia padrão de “dividir e conquistar” aplica-se a projetos entre sites; reduz-se os custos de comunicação principalmente dividindo o projeto no maior número possível de componentes de dimensão razoável, e tentando assegurar que cada componente possa ser atribuído a um pequeno grupo, de preferência dentro de um site. Divida esses componentes entre as subequipes do projeto e estabeleça entregas e prazos claros. (Tente não deixar que a lei de Conway distorça a forma natural do software muito profundamente).
Um objetivo para uma equipe de projeto funciona melhor quando está orientada para fornecer alguma funcionalidade ou resolver algum problema. Esta abordagem assegura que os indivíduos que trabalham num componente saibam o que se espera deles, e que o seu trabalho só será concluído quando esse componente estiver totalmente integrado e utilizado no âmbito do projeto principal.
Obviamente, as melhores práticas habituais de engenharia aplicam-se a projetos de colaboração: cada componente deve ter documentos de design e revisões com a equipe. Desta forma, é dada a todos na equipe a oportunidade de se manterem a par das mudanças, além da oportunidade de influenciar e melhorar os projetos. Anotar as coisas é uma das principais técnicas que você tem para compensar a distância física e/ou lógica – use-a.
As normas são importantes. As diretrizes de estilo de codificação são um bom começo, mas são geralmente bastante táticas e, portanto, apenas um ponto de partida para o estabelecimento de normas da equipe. Sempre que há um debate em torno da escolha a fazer sobre um assunto, discuta-o totalmente com a equipe, mas com um limite de tempo rigoroso. Depois, escolha uma solução, documente-a, e siga em frente. Se não se chegar a acordo, é preciso escolher um árbitro que todos respeitem, e, mais uma vez, apenas avançar. Com o tempo, construirá uma coleção destas melhores práticas, o que ajudará as novas pessoas a se atualizarem.
Em última análise, não há substituto para a interação presencial, embora alguma parte da interação presencial possa ser adiada por uma boa utilização do VC e uma boa comunicação escrita. Se puder, peça aos líderes do projeto para se encontrarem pessoalmente com o resto da equipe. Se o tempo e o orçamento permitirem, organize uma reunião de equipe para que todos os membros da equipe possam interagir pessoalmente. Uma reunião também proporciona uma grande oportunidade para discutir os projetos e objetivos. Para situações em que a neutralidade é importante, é vantajoso realizar reuniões de equipes num local neutro, para que nenhum local individual tenha a “vantagem de casa”.
Finalmente, utilize o estilo de gestão do projeto que se adequa ao projeto no seu estado atual. Mesmo os projetos com objetivos ambiciosos começarão pequenos, então a sobrecarga deve ser correspondentemente baixa. À medida que o projeto cresce, é apropriado adaptar e mudar a forma como o projeto é gerenciado. Dado o crescimento suficiente, o gerenciamento completo do projeto será necessário.
Colaboração Fora do SRE
Como sugerimos, e O Modelo de Envolvimento Evolutivo do SRE discute, a colaboração entre a organização de desenvolvimento do produto e o SRE está realmente no seu melhor quando ocorre no início da fase de design, idealmente antes de qualquer linha de código ser confirmada. Os SREs estão em melhor posição para fazer recomendações sobre arquitetura e comportamento de software que podem ser bastante difíceis (se não impossíveis) de adaptar. Ter essa voz presente na sala quando um novo sistema está sendo projetado é melhor para todos. Em termos gerais, usamos o processo de Objetivos e Resultados Chave (OKR) [Kla12] para acompanhar esse trabalho. Para algumas equipes de serviço, tal colaboração é a base do que fazem – rastrear novos designs, fazer recomendações, ajudar a implementá-los, e acompanhar a sua execução até à produção.
Estudo de caso: Migração do DFP para F1
Os grandes projetos de migração dos serviços existentes são bastante comuns no Google. Exemplos típicos incluem a portabilidade de componentes de serviços para uma nova tecnologia ou a atualização de componentes para suportar um novo formato de dados. Com a recente introdução de tecnologias de bases de dados que podem ser escaladas a um nível global como a Spanner e a F1, a Google levou a cabo uma série de projetos de migração em larga escala envolvendo bases de dados. Um desses projetos foi a migração da base de dados principal da DoubleClick para Publishers (DFP) de MySQL para F1. Em particular, alguns dos autores deste capítulo foram responsáveis por uma parte do sistema de serviço (mostrado na Figura 31-1) que extrai e processa continuamente os dados da base de dados, a fim de gerar um conjunto de arquivos indexados que são depois carregados e servidos em todo o mundo. Este sistema foi distribuído por vários datacenters e utilizou cerca de 1.000 CPUs e 8 TB de RAM para indexar 100 TB de dados todos os dias.
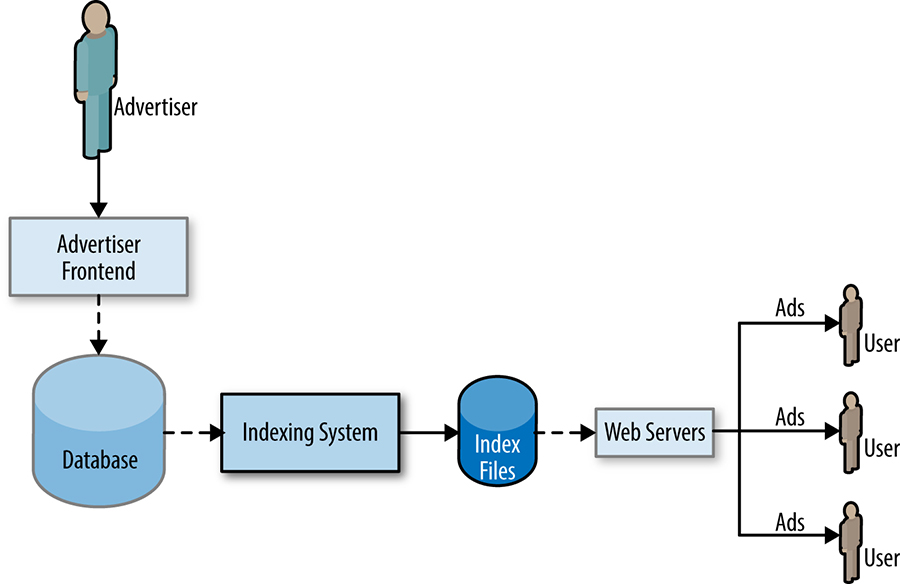
Figura 31-1. Um sistema genérico de veiculação de anúncios
A migração não foi trivial: além de migrar para uma nova tecnologia, o esquema de base de dados foi significativamente refatorado e simplificado graças à capacidade de F1 de armazenar e indexar dados do protocolo de buffer nas colunas da tabela. O objetivo era migrar o sistema de processamento para que pudesse produzir um resultado perfeitamente idêntico ao sistema existente. Isto permitiu-nos deixar o sistema de serviço intocado e realizar, do ponto de vista do usuário, uma migração sem problemas. Como restrição adicional, o produto exigia que completássemos uma migração ao vivo sem qualquer interrupção do serviço para os nossos usuários a qualquer momento. Para o conseguir, a equipe de desenvolvimento do produto e a equipe SRE começaram a trabalhar em estreita colaboração, desde o início, para desenvolver o novo serviço de indexação.
Como seus principais desenvolvedores, as equipes de desenvolvimento de produto estão tipicamente mais familiarizadas com a Lógica Comercial (BL) do software, e estão também em contato mais próximo com os Gestores de Produto e com o componente “necessidade comercial” real dos produtos. Por outro lado, as equipes SRE têm normalmente mais conhecimentos sobre os componentes de infraestrutura do software (por exemplo, bibliotecas para conversar com sistemas de armazenamento distribuídos ou bases de dados), porque os SREs reutilizam frequentemente os mesmos blocos de construção em serviços diferentes, aprendendo as muitas advertências e nuances que permitem que o software funcione de forma escalável e confiável ao longo do tempo.
Desde o início do projeto de migração, o desenvolvimento do produto e o SRE sabiam que teriam de colaborar ainda mais estreitamente, realizando reuniões semanais para sincronizar o progresso do projeto. Neste caso particular, as mudanças de BL estavam parcialmente dependentes de mudanças de infraestrutura. Por esta razão, o projeto começou com o design da nova infraestrutura; os SREs, que tinham um vasto conhecimento sobre o domínio de extração e processamento de dados em escala, conduziram o projeto das mudanças de infraestrutura. Isso envolveu projetar como extrair as várias tabelas de F1, como filtrar e unir os dados, como extrair apenas os dados que foram alterados (em oposição a todo o banco de dados), como sustentar a perda de algumas das máquinas sem afetar o serviço, como garantir que o uso de recursos cresça linearmente com a quantidade de dados extraídos, o planejamento de capacidade e muitos outros aspectos semelhantes. A nova infraestrutura proposta era semelhante a outros serviços que já extraíam e processavam dados da F1. Assim, pudemos ter certeza da solidez da solução e reutilizar partes do monitoramento e das ferramentas.
Antes de prosseguir com o desenvolvimento desta nova infraestrutura, dois SREs produziram um documento de projeto detalhado. Depois, tanto a equipe de desenvolvimento do produto como a equipe SRE revisaram minuciosamente o documento, afinando a solução para lidar com alguns casos extremos e, eventualmente, concordaram com um plano de design. Tal plano identificou claramente o tipo de alterações que a nova infraestrutura traria à BL. Por exemplo, projetamos a nova infraestrutura para extrair apenas dados alterados, em vez de extrair repetidamente todo o banco de dados; a BL teve que levar em conta essa nova abordagem. Desde o início, definimos as novas interfaces entre a infraestrutura e BL, e ao fazê-lo, permitimos que a equipe de desenvolvimento do produto trabalhasse independentemente nas alterações BL. Da mesma forma, a equipe de desenvolvimento do produto manteve o SRE informado sobre as alterações BL. Onde eles interagiram (por exemplo, mudanças de BL dependentes de infraestrutura), essa estrutura de coordenação nos permitiu saber que as mudanças estavam acontecendo e tratá-las de forma rápida e correta.
Em fases posteriores do projeto, os SREs começaram a implementar o novo serviço num ambiente de teste que se assemelhava ao ambiente de produção final do projeto. Esta etapa foi essencial para medir o comportamento esperado do serviço – em particular, o desempenho e a utilização de recursos – enquanto o desenvolvimento do BL ainda estava em curso. A equipe de desenvolvimento do produto utilizou este ambiente de teste para efetuar a validação do novo serviço: o índice dos anúncios produzidos pelo serviço antigo (em produção) tinha que corresponder perfeitamente ao índice produzido pelo novo serviço (em execução no ambiente de teste). Como se suspeitava, o processo de validação evidenciou discrepâncias entre o antigo e o novo serviço (devido a alguns casos extremos no novo formato de dados), que a equipe de desenvolvimento do produto conseguiu resolver iterativamente: para cada anúncio, depuravam a causa da diferença e corrigiam o BL que produzia o mau resultado. Entretanto, a equipe do SRE começou a preparar o ambiente de produção: alocando os recursos necessários em um datacenter diferente, configurando processos e regras de monitoramento e treinando os engenheiros designados para o atendimento. A equipe SRE também criou um processo de lançamento básico que incluiu validação, uma tarefa normalmente concluída pela equipe de desenvolvimento do produto ou pelos Engenheiros de Lançamento mas, neste caso específico, foi concluída pelos SREs para acelerar a migração.
Quando o serviço estava pronto, os SREs prepararam um plano de lançamento em colaboração com a equipe de desenvolvimento do produto e lançaram o novo serviço. O lançamento foi muito bem sucedido e ocorreu sem problemas, sem nenhum impacto visível para o usuário.
Conclusão
Dada a natureza globalmente distribuída das equipes SRE, a comunicação eficaz tem sido sempre uma grande prioridade no SRE. Este capítulo discutiu as ferramentas e técnicas que as equipes SRE utilizam para manter relações eficazes entre as suas equipes e com as suas várias equipes parceiras.
A colaboração entre as equipes SRE tem os seus desafios, mas pode ser potencialmente uma grande recompensa, incluindo abordagens comuns a plataformas de resolução de problemas, permitindo-nos concentrar na resolução de problemas mais difíceis.
Fonte: Google SRE Book