Escrito por Steven Thurgood e David Ferguson com Alex Hidalgo e Betsy Beyer
Os objetivos de nível de serviço (SLOs) especificam um nível desejado para a confiabilidade do seu serviço. Como os SLOs são essenciais para tomar decisões baseadas em dados sobre confiabilidade, eles estão no centro das práticas SRE. Em muitos aspectos, este é o capítulo mais importante deste livro.
Quando estiver equipado com algumas diretrizes, criar SLOs iniciais e um processo para os refinar pode ser simples. O capítulo 4 do nosso primeiro livro introduziu o tema dos SLOs e SLIs (indicadores de nível de serviço), e deu alguns conselhos sobre como usá-los.
Depois de discutir a motivação por detrás dos SLOs e orçamentos de erro, este capítulo fornece uma receita passo a passo para começar a pensar em SLOs, e também alguns conselhos sobre a forma de iterar a partir daí. Abordaremos então como utilizar os SLOs para tomar decisões empresariais eficazes, e explorar alguns tópicos avançados. Por fim, daremos alguns exemplos de SLOs para diferentes tipos de serviços e algumas indicações sobre como criar SLOs mais sofisticados em situações específicas.
Por que os SREs precisam de SLOs
Os engenheiros são um recurso escasso, mesmo nas maiores organizações. O tempo de engenharia deve ser investido nas características mais importantes dos serviços mais importantes. É difícil encontrar o equilíbrio certo entre investir em funcionalidades que irão conquistar novos clientes ou reter os atuais, versus investir na confiabilidade e escalabilidade que irá manter esses clientes satisfeitos. No Google, aprendemos que um SLO bem pensado e adotado é a chave para tomar decisões baseadas em dados sobre o custo de oportunidade do trabalho de confiabilidade, e para determinar como dar a devida prioridade a esse trabalho.
As principais responsabilidades dos SREs não são meramente automatizar “todas as coisas” e manter o pager. As suas tarefas e projetos diários são conduzidos por SLOs: garantir que os SLOs sejam defendidos no curto prazo e que possam ser mantidos no médio e longo prazo. Pode-se até afirmar que, sem SLOs, não há necessidade de SREs.
Os SLOs são uma ferramenta para ajudar a determinar qual trabalho de engenharia deve ser priorizado. Por exemplo, considere as compensações de engenharia para dois projetos de confiabilidade: automatizar rollbacks e migrar para um armazenamento de dados replicado. Ao calcular o impacto estimado em nosso orçamento de erros, podemos determinar qual projeto é mais benéfico para nossos usuários. Ver a seção Tomada de Decisões Utilizando SLOs e Orçamentos de Erros para mais detalhes sobre isto, e “Gerenciar o Risco” em Engenharia de Confiabilidade do Site.
Começando
Como ponto de partida para estabelecer um conjunto básico de SLOs, vamos supor que seu serviço seja algum tipo de código que foi compilado e lançado e está sendo executado em uma infraestrutura de rede que os usuários acessam pela web. O nível de maturidade do seu sistema pode ser um dos seguintes:
- Um desenvolvimento greenfield, sem nada implantado atualmente
- Um sistema em produção com algum monitoramento para notificá-lo quando as coisas dão errado, mas sem objetivos formais, sem conceito de erro de orçamento e uma meta implícita de 100% de tempo de atividade
- Uma implantação em funcionamento com um SLO abaixo de 100%, mas sem um entendimento comum sobre a sua importância ou sobre como aproveitá-lo para fazer escolhas de melhoria contínua – em outras palavras, um SLO ineficaz
Para adotar uma abordagem baseada em orçamento de erro para a Engenharia de Confiabilidade do Site, você precisa atingir um estado em que o seguinte seja verdadeiro:
- Existem SLOs que todas as partes interessadas da organização aprovaram como adequados para o produto.
- As pessoas responsáveis por assegurar que o serviço cumpra o seu SLO concordaram que é possível cumprir este SLO em circunstâncias normais.
- A organização se comprometeu a utilizar o orçamento de erro para a tomada de decisões e priorização. Este compromisso é formalizado numa política de orçamento de erro.
- Existe um processo para refinar o SLO.
Caso contrário, não poderá adotar uma abordagem de confiabilidade baseada em erros orçamentais. A conformidade com o SLO será simplesmente outro KPI (indicador-chave de desempenho) ou métrica de relatório, em vez de uma ferramenta de tomada de decisão.
Objetivos de Confiabilidade e Orçamentos de Erro
O primeiro passo na formulação de SLOs apropriados é falar sobre o que um SLO deve ser, e o que deve cobrir.
Um SLO estabelece um nível alvo de confiabilidade para os clientes do serviço. Acima deste limiar, quase todos os usuários devem estar satisfeitos com o seu serviço (assumindo que estão de outra forma satisfeitos com a utilidade do serviço). Abaixo deste limiar, é provável que os usuários comecem a queixar-se ou deixem de utilizar o serviço. Em última análise, a felicidade do usuário é o que importa – usuários satisfeitos utilizam o serviço, geram receitas para a sua organização, colocam baixas exigências às suas equipes de apoio ao cliente, e recomendam o serviço aos seus amigos. Mantemos os nossos serviços confiáveis para manter os nossos clientes satisfeitos.
A felicidade do cliente é um conceito bastante difuso; não o podemos medir com precisão. Muitas vezes temos muito pouca visibilidade sobre ele, por isso, como começamos? O que usamos para o nosso primeiro SLO?
A nossa experiência tem mostrado que 100% de confiabilidade é o alvo errado:
- Se o seu SLO está alinhado com a satisfação do cliente, 100% não é um objetivo razoável. Mesmo com componentes redundantes, verificação de integridade automatizada e failover rápido, existe uma probabilidade não nula de um ou mais componentes falharem simultaneamente, resultando numa disponibilidade inferior a 100%.
- Mesmo que pudesse alcançar 100% de confiabilidade dentro do seu sistema, os seus clientes não experimentariam 100% de confiabilidade. A cadeia de sistemas entre você e os seus clientes é frequentemente longa e complexa, e qualquer um destes componentes pode falhar. Isto também significa que à medida que se vai de 99% para 99,9% para 99,99% de confiabilidade, cada nove a mais tem um custo acrescido, mas a utilidade marginal para os seus clientes aproxima-se constantemente de zero.
- Se conseguir criar uma experiência que seja 100% confiável para os seus clientes, e quiser manter esse nível de confiabilidade, nunca poderá atualizar ou melhorar o seu serviço. A fonte número um de interrupções é a mudança: a implementação de novos recursos, a aplicação de patches de segurança, a implantação de novo hardware e a expansão para atender à demanda do cliente afetarão essa meta de 100%. Mais cedo ou mais tarde, o seu serviço irá estagnar e os seus clientes irão para outro lugar, o que não é ótimo para o resultado final de ninguém.
- Um SLO de 100% significa que só se tem tempo para ser reativo. Não pode literalmente fazer outra coisa que não seja reagir a < 100% de disponibilidade, o que é garantido. Confiabilidade de 100% não é uma cultura de engenharia SLO – é uma equipe de operações SLO.
Uma vez que tenha um alvo SLO abaixo de 100%, ele precisa ser propriedade de alguém na organização que esteja habilitado a fazer trocas entre velocidade e confiabilidade das características. Numa organização pequena, este pode ser o CTO; em organizações maiores, este é normalmente o proprietário do produto (ou gestor do produto).
O que medir: Usando SLIs
Uma vez que você concorda que 100% é o número errado, como você determina o número certo? E o que você está medindo, afinal? Aqui, entram em jogo indicadores de nível de serviço: um SLI é um indicador do nível de serviço que está fornecendo.
Embora muitos números possam funcionar como um SLI, recomendamos geralmente tratar o SLI como a relação de dois números: o número de eventos bons dividido pelo número total de eventos. Por exemplo:
- Número de solicitações HTTP bem sucedidas / total de solicitações HTTP (taxa de sucesso)
- Número de chamadas gRPC que completaram com sucesso em < 100 ms / total de solicitações gRPC
- Número de resultados de pesquisa que utilizaram todo o corpus / número total de resultados de pesquisa, incluindo os que se degradaram graciosamente
- Número de solicitações de “contagem de verificação de stock” de pesquisas de produtos que utilizaram dados de stock mais recentes do que 10 minutos / número total de solicitações de verificação de stock
- Número de “bons minutos de usuário” de acordo com alguma lista estendida de critérios para essa métrica / número total de minutos de usuário
Os SLIs desta forma têm algumas propriedades particularmente úteis. O SLI varia entre 0% e 100%, onde 0% significa que nada funciona, e 100% significa que nada está quebrado. Consideramos esta escala intuitiva, e este estilo se presta facilmente ao conceito de orçamento de erro: o SLO é uma porcentagem alvo e o orçamento de erro é 100% menos o SLO. Por exemplo, se tiver uma taxa de sucesso SLO de 99,9%, então um serviço que receba 3 milhões de solicitações durante um período de quatro semanas teve um orçamento de 3.000 (0,1%) erros durante esse período. Se uma única interrupção for responsável por 1.500 erros, esse erro custa 50% do orçamento do erro.
Além disso, fazer com que todos os seus SLIs sigam um estilo consistente permite que você aproveite melhor as ferramentas: pode escrever lógica de alerta, ferramentas de análise SLO, cálculo do orçamento de erros, e relatórios para esperar os mesmos inputs: numerador, denominador, e limiar. A simplificação aqui é um bónus.
Ao tentar formular SLIs pela primeira vez, poderá achar útil dividir ainda mais SLIs em especificação SLI e implementação de SLI:
Especificação SLI
A avaliação do resultado do serviço que você considera importante para os usuários, independentemente da forma como é medido.
Por exemplo: Proporção de solicitações de página inicial que foram carregadas em < 100 ms
Implementação de SLI
A especificação SLI é uma forma de medi-la.
Por exemplo:
- Proporção de solicitações da página inicial que foram carregadas em < 100 ms, conforme medido na Coluna de latência do log do servidor. Essa medição perderá solicitações que não chegam ao back-end.
- Proporção de solicitações de página inicial carregadas em < 100 ms, conforme medido por sondas que executam JavaScript em um navegador executado em uma máquina virtual. Essa medição detectará erros quando as solicitações não chegarem à nossa rede, mas poderá deixar passar problemas que afetam apenas um subconjunto de usuários.
- Proporção de solicitações da página inicial que foram carregadas em < 100 ms, conforme medido pela instrumentação no JavaScript na própria página inicial, e relatados a um serviço de gravação de telemetria dedicado. Essa medição capturará com mais precisão a experiência do usuário, embora agora precisemos modificar o código para capturar essas informações e construir a infraestrutura para registrá-las – uma especificação que tem seus próprios requisitos de confiabilidade.
Como pode ver, uma única especificação SLI pode ter múltiplas implementações SLI, cada uma com o seu próprio conjunto de prós e contras em termos de qualidade (com que precisão captam a experiência de um cliente), cobertura (com que precisão captam a experiência de todos os clientes), e custo.
A sua primeira tentativa de um SLI e SLO não precisa ser correta; o objetivo mais importante é colocar algo no lugar e medido, e estabelecer um ciclo de feedback para que possa melhorar. (Aprofundamos este tópico em Melhoria contínua de metas de SLO.)
Em nosso primeiro livro, desaconselhamos a escolha de um SLO com base no desempenho atual, pois isso pode comprometer você com SLOs desnecessariamente rígidos. Embora esse conselho seja verdadeiro, o seu desempenho atual pode ser um bom ponto de partida se não tiver qualquer outra informação, e se tiver um bom processo de iteração no local (que iremos abordar mais tarde). No entanto, não deixe que o desempenho atual o limite à medida que você refina seu SLO: seus clientes também esperam que seu serviço funcione em seu SLO, portanto, se seu serviço retornar solicitações bem-sucedidas 99,999% do tempo em menos de 10 ms, qualquer regressão significativa a partir dessa linha de base pode torná-los infelizes.
Para criar seu primeiro conjunto de SLOs, você precisa decidir sobre algumas especificações de SLI importantes para o seu serviço. Disponibilidade e latência de SLOs são bastante comuns; Os SLOs de atualização, durabilidade, correção, qualidade e cobertura também têm seu lugar (falaremos mais sobre eles mais tarde).
Se tiver dificuldade em descobrir com que tipo de SLIs começar, é útil começar de forma simples:
- Escolha uma aplicação para a qual deseja definir SLOs. Se o seu produto incluir muitas aplicações, poderá adicioná-las mais tarde.
- Decidir claramente quem são os “usuários” nesta situação. Estas são as pessoas cuja felicidade está otimizando.
- Considere as formas comuns de interação dos seus usuários com o seu sistema – tarefas comuns e atividades críticas.
- Desenhe um diagrama de arquitetura de alto nível do seu sistema; mostre os componentes-chave, o fluxo de solicitação, o fluxo de dados, e as dependências críticas. Agrupe estes componentes em categorias listadas na seção seguinte (pode haver alguma sobreposição e ambiguidade; use a sua intuição e não deixe que o perfeito seja o inimigo do bom).
Deve pensar cuidadosamente sobre o que seleciona como SLIs, mas também não deve complicar demais as coisas. Especialmente se você está apenas começando sua jornada SLI, escolha um aspecto do seu sistema que seja relevante, mas fácil de medir – você sempre pode iterar e refinar mais tarde.
Tipos de componentes
A maneira mais fácil de começar a definir SLIs é abstrair o seu sistema em alguns tipos comuns de componentes. Poderá então utilizar a nossa lista de SLIs sugeridos para cada componente para escolher os mais relevantes para o seu serviço:
Orientado por solicitação
O usuário cria algum tipo de evento e espera uma resposta. Por exemplo, pode ser um serviço HTTP onde o usuário interage com um navegador ou uma API para um aplicativo móvel.
Pipeline
Um sistema que recebe registros como entrada, os modifica e coloca a saída em outro lugar. Pode ser um processo simples executado em uma única instância em tempo real ou um processo em lote de vários estágios que leva muitas horas. Exemplos incluem:
Um sistema que lê periodicamente dados de uma base de dados relacional e os grava numa tabela de hash distribuída para servir de forma otimizada
Um serviço de processamento de vídeo que converte vídeo de um formato para outro
Um sistema que lê arquivos de log de várias fontes para gerar relatórios
Um sistema de monitoramento que extrai métricas de servidores remotos e gera séries temporais e alertas
Armazenamento
Um sistema que aceita dados (por exemplo, bytes, registros, arquivos, vídeos) e os disponibiliza para serem recuperados posteriormente.
Um exemplo trabalhado
Considere uma arquitetura simplificada de um jogo para celular, mostrada na Figura 2-1.
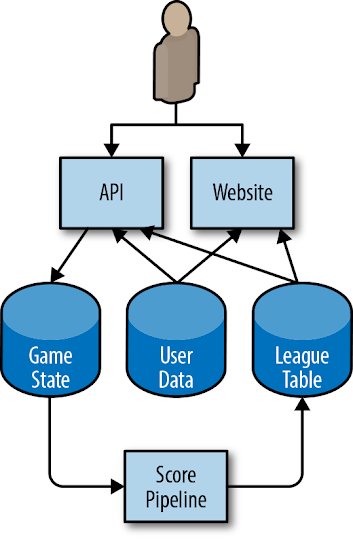
Figura 2-1. Arquitetura para um exemplo de jogo para celular
O aplicativo executado no telefone do usuário interage com uma API HTTP executada na nuvem. A API escreve alterações de estado para um sistema de armazenamento permanente. Um pipeline passa periodicamente por cima destes dados para gerar tabelas classificativas que fornecem pontuações elevadas para hoje, esta semana, e para todo o tempo. Estes dados são escritos numa tabela de dados da liga em separado, e os resultados estão disponíveis através do aplicativo para celular (para pontuações no jogo) e de um website. Os usuários podem carregar avatares personalizados, que são utilizados tanto no jogo através da API como no website de pontuações altas, para a tabela de Dados do Usuário.
Dada esta configuração, podemos começar a pensar em como os usuários interagem com o sistema, e que tipo de SLIs mediriam os vários aspectos da experiência de um usuário.
Alguns destes SLIs podem se sobrepor: um serviço orientado por solicitação pode ter um SLI de correção, um pipeline pode ter um SLI disponível, e os SLIs de durabilidade podem ser vistos como uma variante dos SLIs de correção. Recomendamos a escolha de um pequeno número (cinco ou menos) de tipos de SLI que representam a funcionalidade mais crítica para os seus clientes.
A fim de captar tanto a experiência típica do usuário como a long tail, recomendamos também a utilização de vários graus de SLOs para alguns tipos de SLIs. Por exemplo, se 90% das solicitações dos usuários retornarem dentro de 100 ms, mas os 10% restantes levarem 10 segundos, muitos usuários ficarão insatisfeitos. Um SLO de latência pode capturar esta base de usuários definindo múltiplos limiares: 90% das solicitações são mais rápidas do que 100 ms, e 99% das solicitações são mais rápidas do que 400 ms. Este princípio aplica-se a todos os SLIs com parâmetros que medem a infelicidade do usuário.
A Tabela 2-1 fornece alguns SLIs comuns para diferentes tipos de serviços
Tabela 2-1. Potenciais SLIs para diferentes tipos de componentes
| Tipo de serviço | Tipo de SLI | Descrição |
| Orientado por solicitação | Disponibilidade | A proporção de solicitações que resultaram numa resposta bem sucedida. |
| Orientado por solicitação | Latência | A proporção de solicitações que foram mais rápidas do que algum limiar. |
| Orientado por solicitação | Qualidade | Se o serviço se degradar graciosamente quando sobrecarregado ou quando os backends não estiverem disponíveis, é necessário medir a proporção de respostas que foram atendidas num estado não degradado. Por exemplo, se o armazenamento de dados do usuário não estiver disponível, o jogo ainda poderá ser reproduzido, mas usará imagens genéricas. |
| Pipeline | Atualização | A proporção dos dados que foram atualizados mais recentemente do que algum limiar temporal. Idealmente, essa métrica conta quantas vezes um usuário acessou os dados, para que reflita com mais precisão a experiência do usuário. |
| Pipeline | Correção | A proporção de registros entrando no pipeline que resultaram na saída do valor correto. |
| Pipeline | Cobertura | Para o processamento em lote, a proporção de trabalhos que processaram acima de alguma quantidade alvo de dados. Para processamento de streaming, a proporção de registros de entrada que foram processados com êxito em alguma janela de tempo. |
| Armazenamento | Durabilidade | A proporção de registros escritos que podem ser lidos com sucesso. Ter especial cuidado com os SLIs de durabilidade: os dados que o usuário deseja podem ser apenas uma pequena parte dos dados que são armazenados. Por exemplo, se você tiver 1 bilhão de registros nos 10 anos anteriores, mas o usuário quiser apenas os registros de hoje (que não estão disponíveis), ele ficará insatisfeito, mesmo que quase todos os dados sejam legíveis. |
Passagem da Especificação SLI para a Implementação SLI
Agora que conhecemos as nossas especificações SLI, precisamos começar a pensar em como implementá-las.
Para os seus primeiros SLIs, escolha algo que exija um mínimo de trabalho de engenharia. Se os logs do seu servidor web já estiverem disponíveis, mas a instalação de sondas demoraria semanas e a instrumentação do seu JavaScript levaria meses, utilize os logs.
Você precisa de informações suficientes para medir o SLI: para disponibilidade, você precisa do status de sucesso/falha; para solicitações lentas, você precisa do tempo necessário para atender à solicitação. Pode ser necessário reconfigurar seu servidor web para registrar essas informações. Se você estiver usando um serviço baseado em nuvem, algumas dessas informações já podem estar disponíveis em um painel de monitoramento.
Existem várias opções de implementações SLI para a nossa arquitetura de exemplo, cada uma com os seus próprios prós e contras. As seções seguintes detalham SLIs para os três tipos de componentes do nosso sistema.
Disponibilidade e latência de servidores API e HTTP
Para todas as implementações SLI consideradas, baseamos o sucesso da resposta no código de status HTTP. As respostas 5XX contam contra o SLO, enquanto todas as outras solicitações são consideradas bem-sucedidas. A nossa SLI de disponibilidade é a proporção de solicitações bem-sucedidas, e as nossas SLIs de latência são a proporção de solicitações mais rápidas do que os limites definidos.
Os seus SLIs devem ser específicos e mensuráveis. Para resumir a lista de potenciais candidatos fornecida em O que medir: Usando SLIs, os seus SLIs podem usar uma ou mais das seguintes fontes:
- Registros do servidor de aplicativos
- Monitoramento do balanceador de carga
- Monitoramento de caixa preta
- Instrumentação do lado do cliente
Nosso exemplo usa o monitoramento do balanceador de carga, pois as métricas já estão disponíveis e fornecem SLIs mais próximos da experiência do usuário do que os dos logs do servidor de aplicativos.
Atualização, cobertura e correção do Pipeline
Quando nosso pipeline atualiza a tabela de classificação, ele registra uma marca d’água contendo o carimbo de data e hora de quando os dados foram atualizados. Alguns exemplos de implementações SLI:
- Execute uma consulta periódica na tabela de classificação, contando o número total de novos registros e o número total de registros. Isso tratará cada registro obsoleto como igualmente importante, independentemente de quantos usuários viram os dados.
- Faça com que todos os clientes da tabela de classificação verifiquem a marca d’água quando solicitarem novos dados e incrementem um contador de métrica informando que os dados foram solicitados. Incrementar outro contador se os dados forem mais recentes do que um limite predefinido.
A partir destas duas opções, o nosso exemplo utiliza a implementação do lado do cliente, uma vez que dá SLIs que estão muito mais estreitamente correlacionadas com a experiência do usuário e que são simples de acrescentar.
Para calcular nosso SLI de cobertura, nosso pipeline exporta o número de registros que deveria ter processado e o número de registros que processou com sucesso. Essa métrica pode perder registros que nosso pipeline não conhecia devido a uma configuração incorreta.
Temos algumas abordagens potenciais para medir a correção:
- Injete dados com saídas conhecidas no sistema e conte a proporção de vezes que a saída corresponde às nossas expectativas.
- Use um método para calcular a saída correta com base na entrada que é diferente do nosso pipeline em si (e provavelmente mais caro e, portanto, não adequado para nosso pipeline). Use isso para amostrar pares de entrada/saída e contar a proporção de registros de saída corretos. Esta metodologia assume que a criação de tal sistema é possível e prática.
Nosso exemplo baseia seu SLI de correção em alguns dados selecionados manualmente no banco de dados de estado do jogo, com bons resultados conhecidos que são testados sempre que o pipeline é executado. O nosso SLI é a proporção de entradas corretas para os nossos dados de teste. Para que esse SLI seja representativo da experiência real do usuário, precisamos garantir que nossos dados selecionados manualmente sejam representativos dos dados do mundo real.
Medindo os SLIs
A figura 2-2 mostra como nosso sistema de monitoramento de caixa branca coleta métricas dos vários componentes do aplicativo de exemplo.
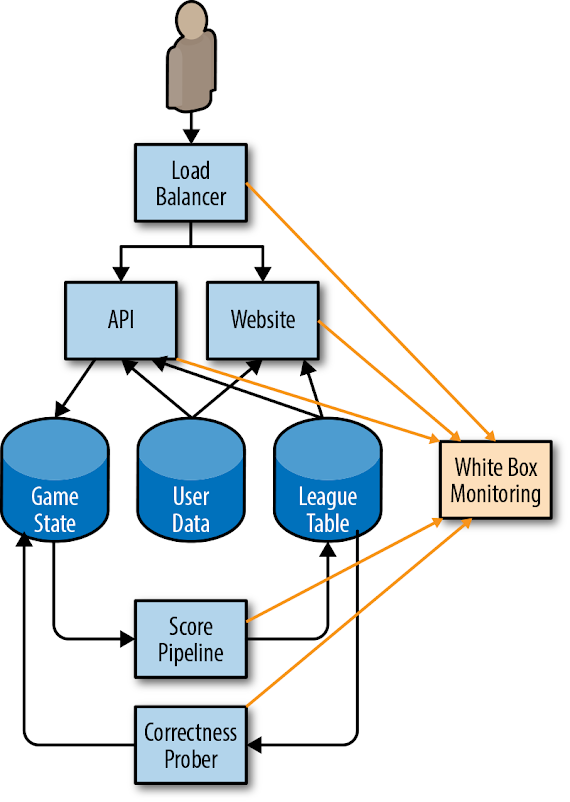
Figura 2-2. Como o nosso sistema de monitoramento coleta as métricas SLI
Vamos dar um exemplo de utilização de métricas do nosso sistema de monitoramento para calcular os nossos SLOs iniciais. Embora o nosso exemplo utilize métricas de disponibilidade e latência, os mesmos princípios aplicam-se a todos os outros SLOs potenciais. Para uma lista completa das métricas que o nosso sistema utiliza, ver Exemplo de Documento SLO. Todos os nossos exemplos utilizam a notação Prometheus.
Métricas de balanceamento de carga
Total de solicitações por backend (“api” ou “web”) e código de resposta:
http_requests_total{host=”api”, status=”500″}
Latência total, como histograma cumulativo; cada bucket conta o número de solicitações que demoraram menos ou igual a esse tempo:
http_request_duration_seconds{host=”api”, le=”0.1″}
http_request_duration_seconds{host=”api”, le=”0.2″}
http_request_duration_seconds{host=”api”, le=”0.4″}
De um modo geral, é melhor contar as solicitações lentas do que aproximá-las com um histograma. Mas, como essa informação não está disponível, utilizamos o histograma fornecido pelo nosso sistema de monitoramento. Outra abordagem seria basear contagens de solicitações lentas explícitas nos vários limites de lentidão na configuração do balanceador de carga (por exemplo, para limiares de 100 ms e 500 ms). Essa estratégia forneceria números mais precisos, mas exigiria mais configuração, o que dificultaria a alteração retroativa dos limites.
http_request_duration_seconds{host=”api”, le=”0.1″}
http_request_duration_seconds{host=”api”, le=”0.5″}
Calculando os SLIs
Utilizando as métricas anteriores, podemos calcular os nossos SLIs atuais durante os sete dias anteriores, conforme mostrado na Tabela 2-2.
Tabela 2-2. Cálculos para SLIs durante os sete dias anteriores
Disponibilidade
sum(rate(http_requests_total{host=”api”, status!~”5..”}[7d]))
/
sum(rate(http_requests_total{host=”api”}[7d])
Latência
histogram_quantile(0.9, rate(http_request_duration_seconds_bucket[7d]))
histogram_quantile(0.99, rate(http_request_duration_seconds_bucket[7d]))
Utilização dos SLIs para calcular os SLOs iniciais
Podemos arredondar para baixo estes SLIs para números gerenciáveis (por exemplo, dois algarismos significativos de disponibilidade, ou até 50 ms5 de latência) para obter os nossos SLOs iniciais.
Por exemplo, ao longo de quatro semanas, as métricas API mostram:
- Total de solicitações: 3,663,253
- Total de solicitações bem-sucedidas: 3,557,865 (97.123%)
- Latência do percentil 90: 432 ms
- Latência do percentil 99: 891 ms
Repetimos este processo para os outros SLIs, e criamos um SLO proposto para o API, mostrado na Tabela 2-3.
Tabela 2-3. SLOs propostos para o API
| Tipo SLO | Objetivo |
| Disponibilidade | 97% |
| Latência | 90% das solicitações < 450 ms |
| Latência | 99% das solicitações < 900 ms |
Exemplo de documento SLO fornece um exemplo completo de um documento SLO. Este documento inclui implementações SLI, que omitimos aqui para ser breve
Com base nesta proposta de SLI, podemos calcular o nosso orçamento de erro durante essas quatro semanas, conforme mostrado na Tabela 2-4.
Tabela 2-4. Orçamento de erro durante quatro semanas
| SLO | Falhas permitidas |
| 97% de disponibilidade | 109,897 |
| 90% das solicitações mais rápidas do que 450 ms | 366,325 |
| 99% das solicitações mais rápidas do que 900 ms | 36,632 |
Escolhendo uma janela de tempo apropriada
Os SLOs podem ser definidos ao longo de vários intervalos de tempo, e podem usar ou uma janela contínua ou uma janela alinhada com um calendário (por exemplo, um mês). Há vários fatores que é preciso levar em conta ao escolher a janela.
As janelas contínuas estão mais alinhadas com a experiência do usuário: se você tiver uma grande interrupção no último dia de um mês, seu usuário não a esquecerá de repente no primeiro dia do mês seguinte. Recomendamos definir este período como um número integral de semanas, para que contenha sempre o mesmo número de fins-de-semana. Por exemplo, se utilizar uma janela de 30 dias, alguns períodos podem incluir quatro fins-de-semana, enquanto outros incluem cinco fins-de-semana. Se o tráfego de fim-de-semana diferir significativamente do tráfego do dia da semana, os seus SLIs podem variar por razões desinteressantes.
As janelas de calendário estão mais estreitamente alinhadas com o planejamento empresarial e o trabalho do projeto. Por exemplo, poderá avaliar os seus SLOs todos os trimestres para determinar onde concentrar o número de funcionários do projeto do trimestre seguinte. As janelas de calendário também introduzem algum elemento de incerteza: no meio do trimestre, é impossível saber quantas solicitações você receberá no restante do trimestre. Portanto, as decisões tomadas no meio do trimestre devem especular sobre quanto orçamento de erro você gastará no restante do trimestre.
Janelas de tempo mais curtas permitem-lhe tomar decisões mais rapidamente: se o seu SLO falhou na semana anterior, então pequenas correções de curso – priorizando bugs relevantes, por exemplo – podem ajudar a evitar violações de SLO nas próximas semanas.
Períodos de tempo mais longos são melhores para decisões mais estratégicas: por exemplo, se pudesse escolher apenas um de três grandes projetos, seria melhor mudar para uma base de dados distribuída de alta disponibilidade, automatizar o seu procedimento de rollout e rollback, ou implantar uma pilha duplicada em outra zona? Você precisa de mais de uma semana de dados para avaliar grandes projetos de vários trimestres; a quantidade de dados necessária é aproximadamente proporcional à quantidade de trabalho de engenharia proposto para corrigi-la.
Encontrámos uma janela contínua de quatro semanas para ser um bom intervalo de uso geral. Complementamos este intervalo de tempo com resumos semanais para priorização de tarefas e relatórios trimestrais resumidos para planejamento de projetos.
Se a fonte de dados permitir, pode então utilizar esta proposta de SLO para calcular o seu desempenho SLO real ao longo desse intervalo: se definir o seu SLO inicial com base em medições reais, por projeto, cumpriu o seu SLO. Mas também podemos recolher informações interessantes sobre a distribuição. Houve alguns dias durante as últimas quatro semanas em que o nosso serviço não atendeu ao SLO? Será que esses dias se correlacionam com incidentes reais? Houve (ou deveria haver) alguma ação tomada nesses dias em resposta a incidentes?
Se não tiver logs, métricas, ou qualquer outra fonte de desempenho histórico, é necessário configurar uma fonte de dados. Por exemplo, como uma solução de baixa fidelidade para serviços HTTP, pode configurar um serviço de monitoramento remoto que efetua algum tipo de verificação periódica do estado de integridade do serviço (um ping ou um HTTP GET) e reporta o número de solicitações bem-sucedidas. Uma série de serviços online pode facilmente implementar esta solução.
Obtendo o Acordo das Partes Interessadas
Para que um SLO proposto seja útil e eficaz, terá de conseguir que todos os interessados concordem com ele:
- Os gerentes de produto precisam concordar que esse limite é bom o suficiente para os usuários – o desempenho abaixo desse valor é inaceitavelmente baixo e vale a pena gastar tempo de engenharia para corrigi-lo.
- Os criadores do produto têm de concordar que, se o orçamento de erro tiver sido esgotado, tomarão algumas medidas para reduzir o risco para os usuários até o serviço estar de volta ao orçamento (como discutido em Estabelecer uma Política de Orçamento de Erro).
- A equipe responsável pelo ambiente de produção, encarregada de defender este SLO, concordou que ele é defensável sem esforço hercúleo, labuta excessiva e esgotamento – tudo isto é prejudicial para a saúde a longo prazo da equipe e do serviço.
Uma vez que todos esses pontos são acordados, a parte difícil está feita. Você iniciou sua jornada de SLO, e os passos restantes implicam iterações a partir deste ponto de partida.
Para defender o seu SLO, terá de estabelecer monitoramento e alerta (ver Alerta sobre SLOs) para que os engenheiros recebam notificações oportunas de ameaças ao erro de orçamento antes que essas ameaças se tornem déficits.
Estabelecendo uma política de erro de orçamento
Assim que tiver um SLO, pode utilizar o SLO para obter um orçamento de erro. Para utilizar este orçamento de erro, é necessária uma política que defina o que fazer quando o seu serviço ficar sem orçamento.
Obter a política de orçamento de erro aprovada por todos os principais interessados – o gestor do produto, a equipe de desenvolvimento, e os SREs – é um bom teste para saber se os SLOs são adequados ao fim a que se destinam:
- Se os SREs sentirem que o SLO não é defensável sem muito trabalho, eles podem argumentar para relaxar alguns dos objetivos.
- Se a equipe de desenvolvimento e o gerente de produto sentirem que o aumento de recursos que terão que dedicar para corrigir a confiabilidade fará com que a velocidade de lançamento de recursos caia abaixo dos níveis aceitáveis, eles também podem argumentar por objetivos de relaxamento. Lembre-se que a redução dos SLOs também reduz o número de situações às quais os SREs responderão; o gestor de produto precisa compreender esta troca.
- Se o gerente de produto achar que o SLO resultará em uma experiência ruim para um número significativo de usuários antes que a política de erro de orçamento solicite que alguém resolva um problema, os SLOs provavelmente não são rígidos o suficiente.
Se as três partes não concordarem em aplicar a política orçamental de erro, é necessário iterar sobre os SLIs e SLOs até que todas as partes interessadas estejam satisfeitas. Decida como avançar e o que precisa para tomar a decisão: mais dados, mais recursos, ou uma alteração no SLI ou SLO?
Quando falamos em aplicar um orçamento de erro, queremos dizer que, uma vez esgotado o seu orçamento de erro (ou quando está prestes a esgotá-lo), deve fazer algo para restaurar a estabilidade do seu sistema.
Para tomar decisões de execução do orçamento de erro, é necessário começar com uma política escrita. Esta política deve abranger as ações específicas que devem ser tomadas quando um serviço tiver consumido todo o seu orçamento de erro durante um determinado período de tempo, e especificar quem as tomará. Os proprietários e ações comuns podem incluir:
- A equipe de desenvolvimento dá prioridade máxima aos bugs relacionados com questões de confiabilidade durante as últimas quatro semanas.
- A equipe de desenvolvimento concentra-se exclusivamente em questões de confiabilidade até o sistema estar dentro do SLO. Esta responsabilidade vem com a aprovação de alto nível para adiar solicitações e mandatos de recursos externos.
- Para reduzir o risco de mais interrupções, um congelamento da produção interrompe certas alterações ao sistema até que haja orçamento de erro suficiente para retomar as alterações.
Por vezes um serviço consome a totalidade do seu orçamento de erro, mas nem todas as partes interessadas concordam que a promulgação da política orçamental de erro é apropriada. Se isto acontecer, é necessário voltar à fase de aprovação da política orçamental de erros.
Documentando o SLO e a política orçamental de erros
Um SLO devidamente definido deve ser documentado num local de destaque onde outras equipes e partes interessadas possam analisá-lo. Esta documentação deve incluir a seguinte informação:
- Os autores do SLO, os revisores (que verificaram a sua exatidão técnica), e os aprovadores (que tomaram a decisão comercial sobre se é o SLO correto).
- A data em que foi aprovado e a data em que deve ser revisto em seguida.
- Uma breve descrição do serviço para dar ao leitor um contexto.
- Os detalhes do SLO: os objetivos e as implementações do SLI.
- Os detalhes de como o orçamento do erro é calculado e consumido.
- A fundamentação por detrás dos números, e se estes foram derivados de dados experimentais ou observacionais. Mesmo que os SLOs sejam totalmente ad hoc, este fato deve ser documentado para que os futuros engenheiros que leiam o documento não tomem más decisões com base em dados ad hoc.
A frequência com que se analisa um documento SLO depende da maturidade da sua cultura SLO. Ao começar, deve provavelmente rever o SLO frequentemente – talvez todos os meses. Uma vez que a adequação do SLO se torne mais estabelecida, é provável que possa reduzir as revisões para que ocorram trimestralmente ou até com menos frequência.
A política orçamental de erros deve também ser documentada, e deve incluir as seguintes informações:
- Os autores, revisores e aprovadores das políticas
- A data em que foi aprovado e a data em que deve ser revisto em seguida
- Uma breve descrição do serviço para dar ao leitor o contexto
- As ações a serem tomadas em resposta ao esgotamento do orçamento
- Um caminho claro de escalonamento a seguir se houver desacordo no cálculo ou se as ações acordadas são apropriadas nas circunstâncias
- Dependendo do nível de experiência e perícia do público em matéria de orçamento de erro, pode ser benéfico incluir uma visão geral dos orçamentos de erro.
Ver Apêndice A para um exemplo de um documento SLO e uma política orçamental de erro.
Dashboards e relatórios
Além dos documentos publicados sobre SLO e políticas de orçamento de erros, é útil ter relatórios e dashboards que forneçam snapshots em tempo real da conformidade SLO dos seus serviços, para comunicar com outras equipes e para detectar áreas problemáticas.
O relatório da Figura 2-3 mostra a conformidade global de vários serviços: se cumpriram todos os seus SLOs trimestrais do ano anterior (os números entre parênteses indicam o número de objetivos que foram cumpridos, e o número total de objetivos), e se os seus SLIs tinham tendência para cima ou para baixo em relação ao trimestre anterior e ao mesmo trimestre do ano passado.
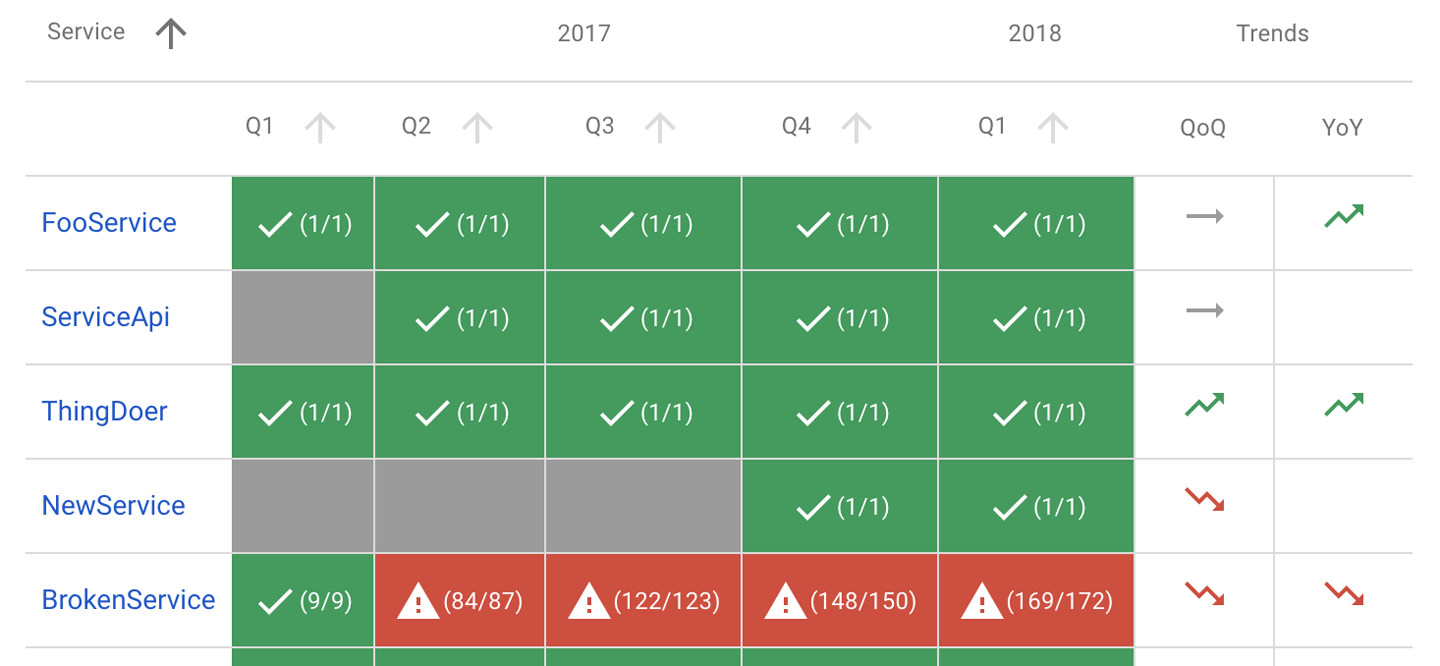
Figura 2-3. Relatório de conformidade SLO
Também é útil ter dashboards que mostrem as tendências SLI. Estes dashboards indicam se você está consumindo o orçamento em uma taxa maior do que o normal ou se há padrões ou tendências que você precisa conhecer.
O dashboard na Figura 2-4 mostra o erro de orçamento para um único trimestre, no meio desse trimestre. Aqui vemos que um único evento consumiu cerca de 15% do orçamento de erros ao longo de dois dias.
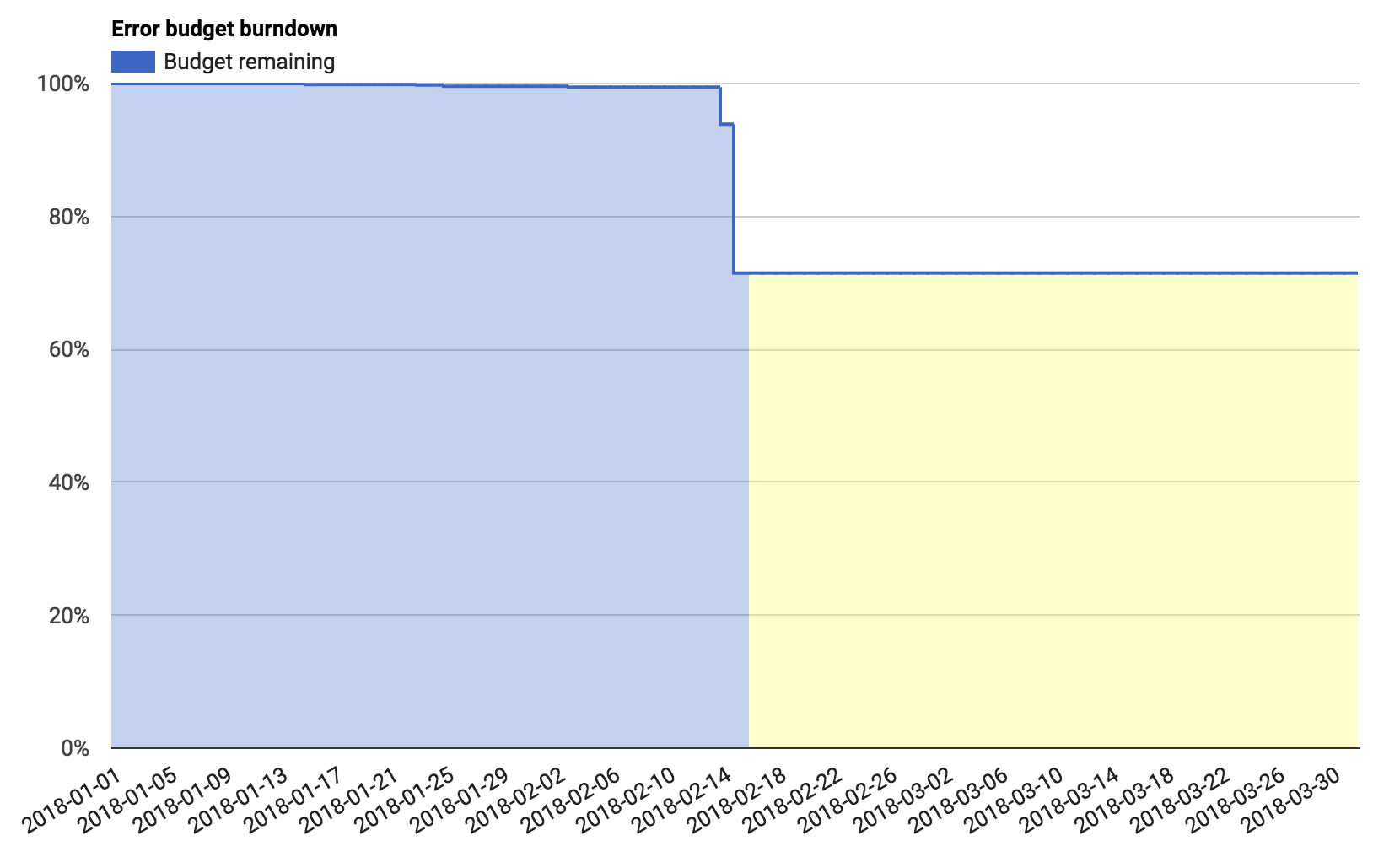
Figura 2-4. Dashboard do orçamento de erros
Os orçamentos de erro podem ser úteis para quantificar estes eventos – por exemplo, “esta interrupção consumiu 30% do meu orçamento de erro trimestral”, ou “estes são os três principais incidentes deste trimestre, ordenados pela quantidade de orçamento de erro que consumiram”.
Melhoria Contínua dos Alvos SLO
Cada serviço pode se beneficiar de uma melhoria contínua. Este é um dos objetivos centrais do serviço no ITIL, por exemplo.
Antes de melhorar suas metas de SLO, você precisa de uma fonte de informações sobre a satisfação do usuário com seu serviço. Há uma enorme variedade de opções:
- Pode contar as interrupções que foram descobertas manualmente, mensagens em fóruns públicos, tickets de suporte, e chamadas para o serviço ao cliente.
- Pode tentar medir o sentimento do usuário nas redes sociais.
- Pode adicionar código ao seu sistema para periodicamente testar a felicidade do usuário.
- Pode realizar pesquisas e amostras presenciais aos usuários.
As possibilidades são infinitas, e o método ótimo depende do seu serviço. Recomendamos que comece com uma medida que seja barata de coletar e iterar a partir desse ponto de partida. Pedir ao seu gestor de produto para incluir a confiabilidade nas discussões existentes com os clientes sobre preços e funcionalidade é um excelente ponto de partida.
Melhorando a qualidade do seu SLO
Conte as suas interrupções detectadas manualmente. Se tiver tickets de suporte, conte-os também. Observe os períodos em que você teve uma interrupção ou incidente conhecido. Verifique se estes períodos estão correlacionados com quedas abruptas no orçamento de erros. Da mesma forma, observe os períodos em que os seus SLIs indicam um problema, ou em que o seu serviço saiu do SLO. Estes períodos de tempo estão correlacionados com interrupções conhecidas ou um aumento dos tickets de suporte? Se estiver familiarizado com a análise estatística, o coeficiente de correlação de classificação do Spearman pode ser uma forma útil de quantificar esta relação.
A Figura 2-5 mostra um gráfico do número de tickets de suporte levantados por dia versus a perda de medida no nosso orçamento de erro nesse dia. Embora nem todos os tickets estejam relacionados com questões de confiabilidade, existe uma correlação entre os tickets e a perda orçamental de erro. Vemos dois outliers: um dia com apenas 5 tickets, em que perdemos 10% do nosso orçamento de erro, e um dia com 40 tickets, em que não perdemos nenhum orçamento de erro. Ambos justificam uma investigação mais aprofundada.
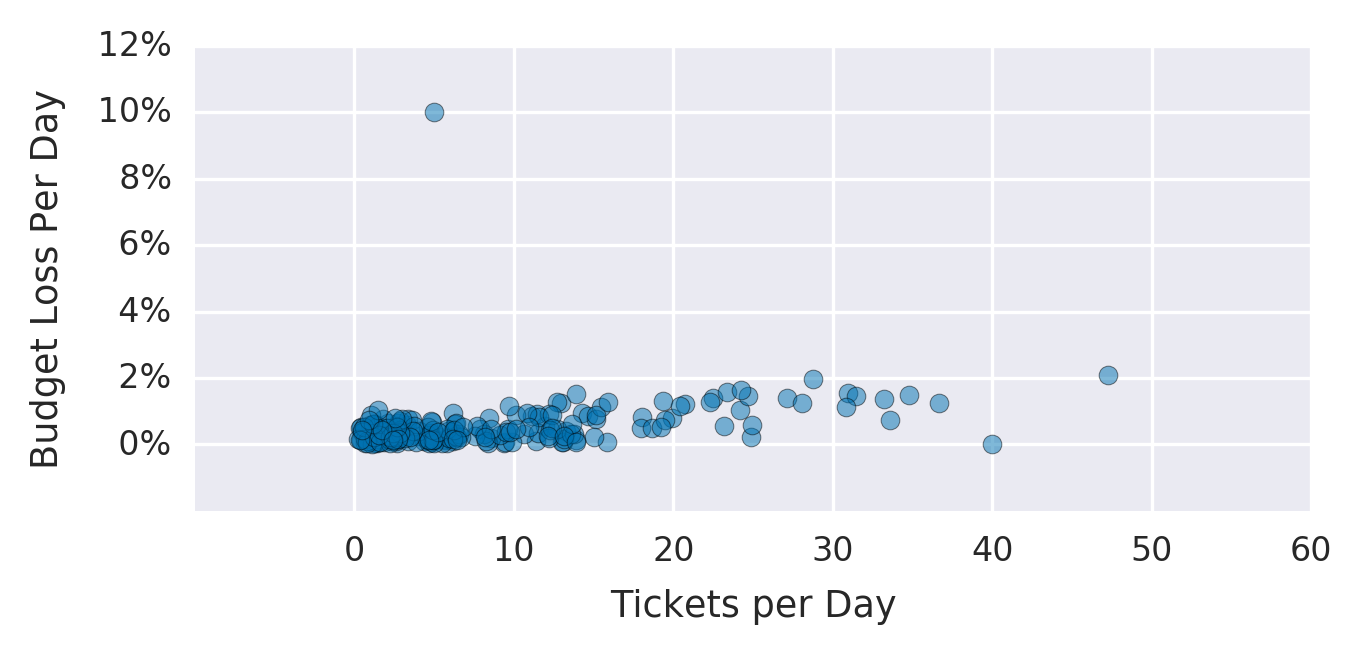
Figura 2-5. Gráfico que mostra o número de tickets de suporte por dia versus a perda orçamental nesse dia
Se algumas das suas interrupções e picos de tickets não forem capturados em qualquer SLI ou SLO, ou se tiver quedas de SLI e falhas de SLO que não mapeiem para questões relacionadas com o usuário, este é um sinal forte de que o seu SLO não tem cobertura. Esta situação é totalmente normal e deve ser esperada. Os seus SLIs e SLOs devem mudar ao longo do tempo à medida que as realidades sobre o serviço que representam mudam. Não tenha medo de os examinar e refinar ao longo do tempo!
Há vários cursos de ação que pode tomar se o seu SLO não tiver cobertura:
Altere o seu SLO
Se os seus SLIs indicarem um problema, mas os seus SLOs não solicitaram que ninguém notificasse ou respondesse, talvez seja necessário restringir seu SLO.
- Se o incidente nessa data foi grande o suficiente para precisar ser resolvido, observe os valores de SLI durante os períodos de interesse. Calcule qual SLO resultaria em uma notificação nessas datas. Aplique esse SLO aos seus SLIs históricos, e veja que outros eventos este ajustamento teria capturado. É inútil melhorar o recall do seu sistema se você diminuir a precisão de tal forma que a equipe deve responder constantemente a eventos sem importância.
- Da mesma forma, para dias falso-positivos, considere relaxar o SLO.
Se a alteração do SLO em qualquer direção resultar em muitos falsos positivos ou falsos negativos, então também é necessário melhorar a implementação do SLI.
Altere a sua implementação do SLI
Há duas maneiras de alterar a sua implementação do SLI: aproximar a medição do usuário para melhorar a qualidade da métrica ou melhorar a cobertura para capturar uma porcentagem maior de interações do usuário. Por exemplo:
- Em vez de medir o sucesso/latência no servidor, meça-o no balanceador de carga ou no cliente.
- Em vez de medir a disponibilidade com uma simples solicitação HTTP GET, use um manipulador de verificação de integridade que exerce mais funcionalidade do sistema, ou um teste que executa todo o JavaScript do lado do cliente.
Instituir um SLO aspiracional
Às vezes, você determina que precisa de um SLO mais rígido para deixar seus usuários satisfeitos, mas melhorar seu produto para atender a esse SLO levará algum tempo. Se você implementar o SLO mais restrito, ficará permanentemente fora do SLO e estará sujeito à sua política de erro de orçamento. Nesta situação, pode fazer do SLO refinado um SLO ambicioso medido e rastreado ao lado do seu SLO atual, mas explicitamente chamado na sua política de orçamento de erro como não exigindo ação. Desta forma, pode acompanhar o seu progresso no sentido de satisfazer o SLO aspiracional, mas não estará num estado de emergência perpétuo.
Iterar
Há muitas maneiras diferentes de iterar, e suas sessões de revisão identificarão muitas melhorias em potencial. Escolha a opção com maior probabilidade de dar o maior retorno sobre o investimento. Especialmente durante as primeiras iterações, erre do lado do mais rápido e mais barato; isso reduz a incerteza em suas métricas e ajuda a determinar se você precisa de métricas mais caras. Itere quantas vezes precisar.
Tomada de decisões utilizando SLOs e orçamentos de erros
Uma vez que tenha SLOs, pode começar a utilizá-los para a tomada de decisões.
As decisões óbvias começam com o que fazer quando você não está cumprindo seu SLO – ou seja, quando você esgotou seu orçamento de erro. Como já foi discutido, a linha de ação apropriada quando esgotar o seu orçamento de erro deve ser coberta pela política de orçamento de erro. As políticas comuns incluem interromper os lançamentos de recursos até que o serviço esteja novamente dentro do SLO ou dedicar parte ou todo o tempo de engenharia para trabalhar em bugs relacionados à confiabilidade.
Em circunstâncias extremas, uma equipe pode declarar uma emergência com aprovação de alto nível para despriorizar todas as demandas externas (solicitações de outras equipes, por exemplo) até o serviço cumprir os critérios de saída – normalmente que o serviço esteja dentro do SLO e que tenha tomado medidas para diminuir as hipóteses de uma subsequente falha do SLO. Estas medidas podem incluir a melhoria do monitoramento, a melhoria dos testes, a remoção de dependências perigosas, ou a rearquitetura do sistema para remover tipos de falhas conhecidas.
Você pode determinar a escala do incidente de acordo com a proporção do orçamento de erro que consumiu, e utilizar estes dados para identificar os incidentes mais críticos que merecem uma investigação mais aprofundada.
Por exemplo, imagine que o lançamento de uma nova versão API causa 100% NullPointerExceptions até que o sistema possa ser revertido quatro horas mais tarde. A inspeção dos logs brutos do servidor indica que o problema causou 14.066 erros. Utilizando os números do nosso SLO 97% anterior, e o nosso orçamento de 109.897 erros, este único evento utilizou 13% do nosso orçamento de erros.
Ou talvez o servidor em que a nossa base de dados de estado individualizada é armazenada falhe, e a restauração a partir de backups demora 20 horas. Estimamos (com base no tráfego histórico ao longo desse período) que esta falha nos causou 72.000 erros, ou 65% do nosso orçamento de erros.
Imagine que a nossa empresa de exemplo teve apenas uma falha no servidor em cinco anos, mas normalmente experimenta dois ou três lançamentos ruins que requerem rollbacks por ano. Podemos estimar que, em média, as más versões custam o dobro do orçamento de erros do que as falhas na base de dados. Os números provam que a resolução do problema de lançamento proporciona muito mais benefícios do que investir recursos na investigação da falha do servidor.
Se o serviço estiver funcionando sem falhas e necessitar de pouca supervisão, talvez seja hora de migrar o serviço para um nível de suporte menos prático. Você pode continuar a fornecer gerenciamento de resposta a incidentes e supervisão de alto nível, mas não precisa mais estar tão intimamente envolvido com o produto no dia-a-dia. Portanto, você pode concentrar seus esforços em outros sistemas que precisam de mais suporte do SRE.
A tabela 2-5 fornece sugestões de ações com base em três dimensões-chave:
- Desempenho contra SLO
- A quantidade de labuta necessária para operar o serviço
- O nível de satisfação do cliente com o serviço
Tabela 2-5. Matriz de decisão SLO
| SLO | Trabalhos | Satisfação do cliente | Ação |
| Conhecido | Baixo | Alto | Escolher (a) relaxar os processos de liberação e implementação e aumentar a velocidade, ou (b) recuar no engajamento e concentrar o tempo de engenharia em serviços que necessitam de maior confiabilidade. |
| Conhecido | Baixo | Baixo | Restringir o SLO. |
| Conhecido | Alto | Alto | Se o alerta estiver gerando falsos positivos, reduza a sensibilidade. Caso contrário, afrouxe temporariamente os SLOs (ou descarregue o trabalho) e conserte o produto e/ou melhore a mitigação de falhas automatizada. |
| Conhecido | Alto | Baixo | Restringir o SLO. |
| Falhado | Baixo | Alto | Relaxar o SLO. |
| Falhado | Baixo | Baixo | Aumentar a sensibilidade dos alertas. |
| Falhado | Alto | Alto | Relaxar o SLO. |
| Falhado | Alto | Baixo | Descarregue o trabalho e conserte o produto e/ou melhore a mitigação automatizada de falhas. |
Tópicos avançados
Assim que tiver uma cultura saudável e madura de SLO e erro orçamental, pode continuar a melhorar e aperfeiçoar a forma como mede e discute a confiabilidade dos seus serviços.
Modelagem de jornadas do usuário
Embora todas as técnicas discutidas neste capítulo sejam benéficas para a sua organização, em última análise, os SLOs devem centrar-se na melhoria da experiência do cliente. Por conseguinte, deverá escrever SLOs em termos de ações centradas no usuário.
Você pode usar jornadas críticas do usuário para ajudar a capturar a experiência de seus clientes. Uma jornada crítica do usuário é uma sequência de tarefas que é uma parte essencial da experiência de um determinado usuário e um aspecto essencial do serviço. Exemplo, para uma experiência de compra online, as jornadas críticas do usuário podem incluir:
- Procura de um produto
- Adicionar um produto a um carrinho de compras
- Conclusão de uma compra
Estas tarefas quase de certeza não irão mapear bem os seus SLIs existentes; cada tarefa requer múltiplas etapas complexas que podem falhar em qualquer ponto, e inferir o sucesso (ou fracasso) destas ações a partir dos logs pode ser extremamente difícil. (Por exemplo, como se determina se o usuário falhou na terceira etapa, ou se simplesmente se distraiu com vídeos de gato em outra guia?) No entanto, precisamos identificar o que importa para o usuário antes de começarmos a garantir que esse aspecto do serviço é confiável.
Uma vez identificados os eventos centrados no usuário, é possível resolver o problema da sua medição. Poderá medi-los juntando eventos de log distintos, utilizando sondagem JavaScript avançada, utilizando instrumentação do lado do cliente, ou utilizando algum outro processo. Uma vez que se possa medir um evento, este torna-se apenas mais um SLI, que se pode seguir juntamente com os seus SLIs e SLOs existentes. As jornadas críticas do usuário podem melhorar seu recall sem afetar sua precisão.
Importância da Interação de Classificação
Nem todas as solicitações são consideradas iguais. A solicitação HTTP de um aplicativo para dispositivos móveis que verifica as notificações da conta (em que as notificações são geradas por um pipeline diário) é importante para o usuário, mas não é tão importante quanto uma solicitação relacionada ao faturamento do anunciante.
Precisamos de uma forma de distinguir certas classes de solicitações de outras. Pode utilizar o bucket para fazer isso – isto é, adicionar mais etiquetas aos seus SLIs, e depois aplicar SLOs diferentes a essas etiquetas diferentes. A tabela 2-6 mostra um exemplo.
Tabela 2-6. Bucket por nível
| Níveis de clientes | Disponibilidade SLO |
| Premium | 99.99% |
| Grátis | 99.9% |
Você pode dividir as solicitações pela capacidade de resposta esperada, conforme mostrado na tabela 2-7
Tabela 2-7. Bucket por capacidade de resposta esperada
| Responsividade | Latência SLO |
| Interativo (ou seja, solicitações que bloqueiam o carregamento de páginas) | 90% das solicitações completas em 100 ms |
| CSV download | 90% dos downloads começam dentro de 5 s |
Se tiver os dados disponíveis para aplicar o seu SLO a cada cliente independentemente, pode acompanhar o número de clientes que estão no SLO em qualquer momento. Observe que esse número pode ser altamente variável – os clientes que enviam um número muito baixo de solicitações terão 100% de disponibilidade (porque tiveram a sorte de não apresentar falhas) ou disponibilidade muito baixa (porque a única falha que experimentaram foi uma porcentagem significativa dos seus pedidos). Os clientes individuais podem não cumprir o seu SLO por razões desinteressantes, mas no conjunto, os problemas de rastreio que afetam um grande número de clientes podem ser um sinal útil.
Modelação de dependências
Os grandes sistemas têm muitos componentes. Um único sistema pode ter uma camada de apresentação, uma camada de aplicação, uma camada de lógica empresarial, e uma camada de persistência de dados. Cada uma destas camadas pode consistir em muitos serviços ou microsserviços.
Enquanto a sua principal preocupação é implementar um SLO centrado no usuário que cubra toda a pilha, os SLOs podem também ser uma forma útil de coordenar e implementar requisitos de confiabilidade entre os diferentes componentes da pilha.
Por exemplo, se um único componente é uma dependência crítica para uma interação de valor particularmente elevado, a sua garantia de confiabilidade deve ser pelo menos tão elevada como a garantia de confiabilidade da ação dependente. A equipe que gere esse componente específico precisa possuir e gerir o SLO do seu serviço da mesma forma que o SLO do produto global.
Se um determinado componente tiver limitações de confiabilidade inerentes, o SLO pode comunicar essa limitação. Se a jornada do usuário que depende dela precisar de um nível mais alto de disponibilidade do que aquele componente pode fornecer razoavelmente, você precisará projetar em torno dessa condição. Você pode usar um componente diferente ou adicionar defesas suficientes (armazenamento em cache, processamento off-line, degradação graciosa, etc.) para lidar com falhas nesse componente.
Pode ser tentador tentar resolver esses problemas com a matemática. Se tem um serviço que oferece 99,9% de disponibilidade numa única zona, e precisa de 99,95% de disponibilidade, a simples implementação do serviço em duas zonas deve resolver esse requisito. A probabilidade de ambos os serviços sofrerem uma interrupção ao mesmo tempo é tão baixa que duas zonas devem fornecer 99,9999% de disponibilidade. Contudo, este raciocínio pressupõe que ambos os serviços são totalmente independentes, o que quase nunca é o caso. As duas instâncias da sua aplicação terão dependências comuns, domínios de falhas comuns, destino partilhado, e planos de controle globais – tudo isso pode causar uma interrupção em ambos os sistemas, não importa o quão cuidadosamente seja projetado e gerenciado. A menos que cada uma destas dependências e padrões de falhas seja cuidadosamente enumerada e contabilizada, quaisquer cálculos deste tipo serão enganadores.
Há duas escolas de pensamento sobre como uma política orçamental de erro deve abordar um SLO falhado quando a falha é causada por uma dependência que é tratada por outra equipe:
- Sua equipe não deve interromper os lançamentos ou dedicar mais tempo à confiabilidade, pois seu sistema não causou o problema.
- Deve decretar um congelamento de alterações a fim de minimizar as hipóteses de futuras interrupções, independentemente da causa dessa interrupção.
A segunda abordagem irá tornar os seus usuários mais felizes. Tem alguma flexibilidade na forma como aplica este princípio. Dependendo da natureza da interrupção e da dependência, as alterações de congelamento podem não ser práticas. Decida o que é mais apropriado para o seu serviço e as suas dependências, e registre essa decisão para a posteridade no seu orçamento de erros documentados. Para um exemplo de como isto pode funcionar na prática, ver o exemplo de política de orçamento de erro em Exemplo de política de orçamento de erro.
Experimentando o relaxamento dos seus SLOs
Você poderá querer experimentar a confiabilidade da sua aplicação e medir quais as alterações na confiabilidade (por exemplo, adicionar latência aos tempos de carregamento de páginas) que têm um impacto adverso mensurável no comportamento do usuário (por exemplo, percentagem de usuários que concluem uma compra). Recomendamos a realização deste tipo de análise apenas se estiver confiante de que tem um orçamento de erro para gastar. Há muitas interações sutis entre latência, disponibilidade, clientes, domínios de negócio e concorrência (ou falta dela). Fazer a escolha de baixar deliberadamente a experiência percebida do cliente é um Rubicão a ser atravessado de forma extremamente atenciosa, se for o caso.
Embora este exercício possa parecer assustador (ninguém quer perder vendas!), o conhecimento que se pode ganhar ao realizar tais experiências permitirá que você melhore seu serviço de maneiras que podem levar a um desempenho ainda melhor (e vendas mais altas!) no futuro. Esse processo pode permitir que você identifique matematicamente uma relação entre uma métrica de negócios chave (por exemplo, vendas) e uma métrica técnica mensurável (por exemplo, latência). Se o fizer, ganhou um dado muito valioso que pode utilizar para tomar decisões de engenharia importantes para o seu serviço no futuro.
Este exercício não deve ser uma atividade pontual. À medida que o seu serviço evolui, o mesmo acontecerá com as expectativas dos seus clientes. Assegure-se de rever regularmente a validade contínua da relação.
Esse tipo de análise também é arriscado porque você pode interpretar mal os dados obtidos. Por exemplo, se atrasar artificialmente as suas páginas em 50 ms e notar que não ocorre nenhuma perda correspondente nas conversões, poderá concluir que o seu SLO de latência é demasiado rigoroso. No entanto, os seus usuários podem estar infelizes, mas simplesmente sem uma alternativa ao seu serviço neste momento. Assim que aparecer um concorrente, os seus usuários irão embora. Certifique-se de que está medindo os indicadores corretos e tome as devidas precauções.
Conclusão
Todos os tópicos abordados neste livro podem ser ligados a SLOs. Agora que leu este capítulo, esperamos que concorde que mesmo os SLOs parcialmente formalizados (que declaram claramente as suas promessas aos usuários) oferecem um quadro para discutir o comportamento do sistema com maior clareza, e podem ajudar a identificar remédios acionáveis quando os serviços não corresponderem às expectativas
Para resumir:
- Os SLOs são a ferramenta pela qual você mede a confiabilidade do seu serviço.
- Os orçamentos de erro são uma ferramenta para equilibrar a confiabilidade com outros trabalhos de engenharia, e uma ótima forma de decidir quais os projetos que terão mais impacto.
- Deve começar hoje a utilizar SLOs e orçamentos de erro.
Para um exemplo de documento SLO e um exemplo de política orçamental de erro, ver Apêndices Exemplo de documento SLO e Exemplo de política orçamental de erro.