Escrito por Steven Thurgood
Com Jess Frame, Anthony Lenton,
Carmela Quinito, Anton Tolchanov, e Nejc Trdin
Este capítulo explica como transformar os seus SLOs em alertas acionáveis sobre eventos significativos. Tanto o nosso primeiro livro do SRE como este livro falam sobre a implementação de SLOs. Acreditamos que ter bons SLOs que medem a confiabilidade da sua plataforma, conforme experimentada por seus clientes, fornece a indicação da mais alta qualidade para quando um engenheiro de plantão deve responder. Aqui damos orientações específicas sobre como transformar esses SLOs em regras de alerta para que possa responder a problemas antes de consumir muito do seu orçamento de erros.
Os nossos exemplos apresentam uma série de implementações cada vez mais complexas para métricas e lógicas de alerta; discutimos a utilidade e as deficiências de cada uma delas. Embora nossos exemplos usem um serviço simples orientado a solicitações e a sintaxe do Prometheus, você pode aplicar essa abordagem em qualquer framework de alertas.
Considerações de Alerta
Para gerar alertas a partir de indicadores de nível de serviço (SLIs) e de um orçamento de erro, você precisa de uma maneira de combinar esses dois elementos em uma regra específica. O seu objetivo é ser notificado para um evento significativo: um evento que consome uma grande fração do orçamento de erro.
Considere os seguintes atributos ao avaliar uma estratégia de alerta:
Precisão
A proporção de eventos detectados que foram significativos. A precisão é de 100% se cada alerta corresponder a um evento significativo. Observe que o alerta pode se tornar particularmente sensível a eventos não significativos durante períodos de baixo tráfego (discutido em Serviços de Baixo Tráfego e Alerta de Orçamento de Erros).
Recall
A proporção de eventos significativos detectados. O recall é de 100% se cada evento significativo resultar em um alerta.
Tempo de detecção
Quanto tempo leva para enviar notificações em várias condições. Longos tempos de detecção podem ter um impacto negativo no orçamento de erros.
Tempo de reset
Quanto tempo os alertas disparam depois de um problema estar resolvido. Longos tempos de reset podem causar confusão ou ignorar problemas.
Modos de Alertar sobre Eventos Significativos
A construção de regras de alerta para os seus SLOs pode se tornar bastante complexa. Aqui apresentamos seis formas de configurar o alerta sobre eventos significativos, de modo a aumentar a fidelidade, para chegar a uma opção que oferece um bom controle sobre os quatro parâmetros de precisão, recall, tempo de detecção, e tempo de reset simultaneamente. Cada uma das seguintes abordagens trata de um problema diferente, e algumas acabam por resolver múltiplos problemas ao mesmo tempo. As três primeiras tentativas não viáveis trabalham para as três últimas estratégias de alerta viáveis, sendo a abordagem 6 a opção mais viável e mais altamente recomendada. O primeiro método é simples de implementar, mas inadequado, enquanto que o método ótimo fornece uma solução completa para defender um SLO tanto a longo como a curto prazo.
Para efeitos desta discussão, “orçamentos de erro” e “taxas de erro” aplicam-se a todos os SLIs, e não apenas àqueles com “erro” no seu nome. Na seção O que medir: Utilizando SLIs, recomendamos o uso de SLIs que capturam a proporção de eventos bons em relação ao total de eventos. O orçamento de erro fornece o número de eventos ruins permitidos e a taxa de erro é a proporção de eventos ruins em relação ao total de eventos.
1: Taxa de erro alvo ≥ Limiar SLO
Para a solução mais trivial, você pode escolher uma pequena janela de tempo (por exemplo, 10 minutos) e alertar se a taxa de erro sobre essa janela exceder o SLO.
Por exemplo, se o SLO for 99,9% durante 30 dias, alerte se a taxa de erro durante os 10 minutos anteriores for ≥ 0,1%:
– alert: HighErrorRate
expr: job:slo_errors_per_request:ratio_rate10m{job=”myjob”} >= 0.001
Nota
Esta média de 10 minutos é calculada no Prometheus com uma regra de registro:
record: job:slo_errors_per_request:ratio_rate10m
expr:
sum(rate(slo_errors[10m])) by (job)
/
sum(rate(slo_requests[10m])) by (job)
Se não exportar slo_errors e slo_requests do seu trabalho, pode criar a série temporal renomeando uma métrica:
record: slo_errors
expr: http_errors
Alertar quando a taxa de erro recente é igual à do SLO significa que o sistema detecta um gasto orçamental de:
tamanho da janela de alerta
_______________________
Período do relatório
A figura 5-1 mostra a relação entre tempo de detecção e a taxa de erro para um serviço de exemplo com uma janela de alerta de 10 minutos e um SLO de 99,9%.
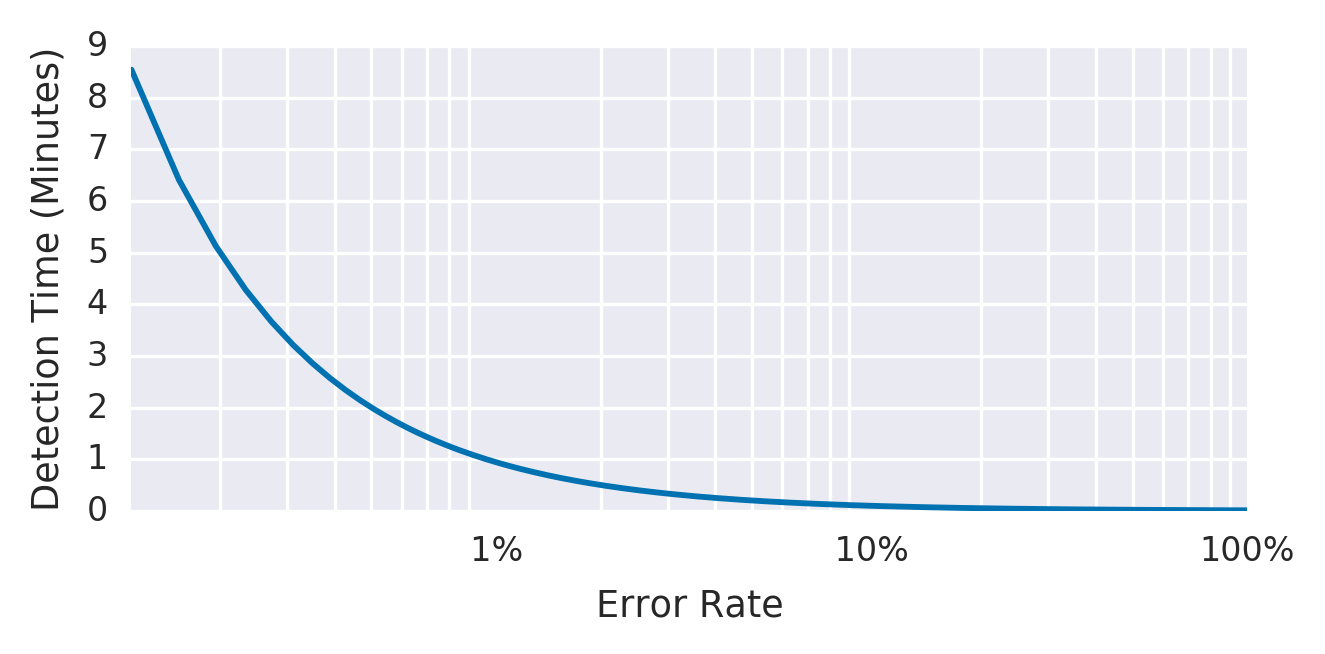
Figura 5-1. Tempo de detecção para um serviço de exemplo com uma janela de alerta de 10 minutos e um SLO de 99,9%.
A tabela 5-1 mostra os benefícios e desvantagens de alertar quando a taxa de erro imediato é muito elevada
Tabela 5-1.Prós e contras de alertar quando a taxa de erro imediato é muito elevada
| Prós | Contras |
| O tempo de detecção é bom: 0,6 segundos para uma interrupção total.
Este alerta dispara sobre qualquer evento que ameace o SLO, exibindo um bom recall. |
A precisão é baixa: O alerta dispara sobre muitos eventos que não ameaçam o SLO. Uma taxa de erro de 0,1% durante 10 minutos alertaria, enquanto consome apenas 0,02% do orçamento mensal de erros.
Levando este exemplo ao extremo, poderia receber até 144 alertas por dia todos os dias, não agir sobre quaisquer alertas, e ainda assim cumprir o SLO. |
2: Janela de Alerta Aumentada
Podemos partir do exemplo anterior, alterando o tamanho da janela de alerta para melhorar a precisão. Ao aumentar o tamanho da janela, você gasta um valor de orçamento maior antes de acionar um alerta.
Para manter a taxa de alertas gerenciável, você decide ser notificado apenas se um evento consumir 5% do orçamento de erro de 30 dias – uma janela de 36 horas:
– alert: HighErrorRate
expr: job:slo_errors_per_request:ratio_rate36h{job=”myjob”} > 0.001
Agora, o tempo de detecção é:
1-SLO
______
Taxa de erro X tamanho da janela de alerta
A tabela 5-2 mostra os benefícios e desvantagens de alertar quando a taxa de erro é muito alta em uma janela de tempo maior.
Tabela 5-2.Prós e contras de alertar quando a taxa de erro é muito alta em uma janela de tempo maior
| Pros | Contras |
| O tempo de detecção ainda é bom: 2 minutos e 10 segundos para uma interrupção completa.
Melhor precisão do que o exemplo anterior: ao assegurar que a taxa de erro é mantida por mais tempo, um alerta representará provavelmente uma ameaça significativa para o orçamento do erro. |
Tempo de reset muito ruim: No caso de 100% de interrupção, um alerta disparará pouco depois de 2 minutos, e continuará a disparar durante as próximas 36 horas.
O cálculo das taxas em janelas mais longas pode ser caro em termos de memória ou operações de E/S, devido ao grande número de pontos de dados. |
A figura 5-2 mostra que, embora a taxa de erro em um período de 36 horas tenha caído para um nível insignificante, a taxa média de erro de 36 horas permanece acima do limite.
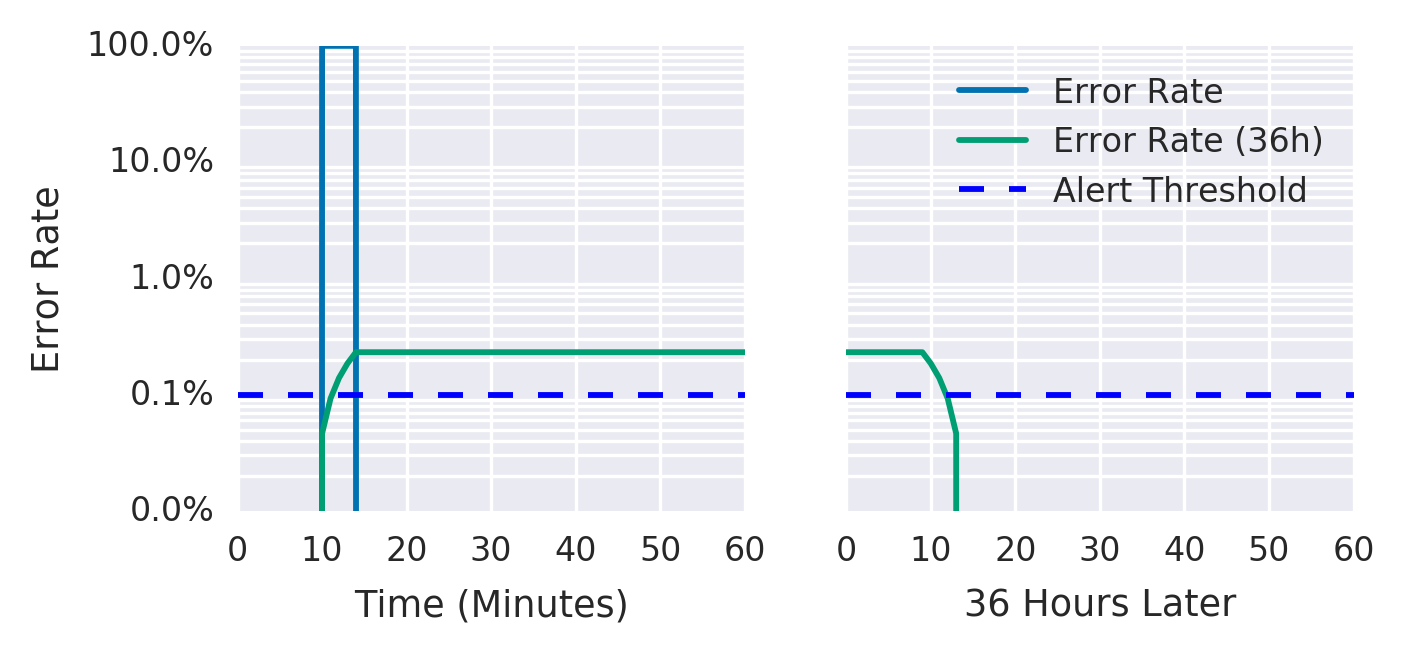
Figura 5-2. Taxa de erro ao longo de um período de 36 horas
3: Duração do Alerta de Incremento
A maioria dos sistemas de monitoramento permite acrescentar um parâmetro de duração aos critérios de alerta, para que o alerta não dispare a menos que o valor se mantenha acima do limiar durante algum tempo. Você pode ficar tentado a usar esse parâmetro como uma maneira relativamente barata de adicionar janelas mais longas:
– alert: HighErrorRate
expr: job:slo_errors_per_request:ratio_rate1m{job=”myjob”} > 0.001
for: 1h
A tabela 5-3 mostra os benefícios e desvantagens da utilização de um parâmetro de duração para alertas.
A tabela 5-3.Prós e contras da utilização de um parâmetro de duração para alertas
| Pros | Contras |
| Os alertas podem ser mais precisos. Exigir uma taxa de erro sustentada antes do disparo significa que os alertas têm maior probabilidade de corresponder a um evento significativo. | Recall insatisfatório e tempo de detecção insatisfatório: como a duração não varia de acordo com a gravidade do incidente, uma interrupção de 100% alerta após uma hora, o mesmo tempo de detecção de uma interrupção de 0,2%. A interrupção de 100% consumiria 140% do orçamento de 30 dias naquela hora.
Se a métrica retornar momentaneamente a um nível dentro do SLO, o cronômetro de duração será resetado. Um SLI que oscila entre SLO falho e SLO aprovado pode nunca alertar. |
Pelas razões enumeradas na Tabela 5-3, não recomendamos a utilização de durações como parte dos seus critérios de alerta baseados em SLO.
A Figura 5-3 mostra a taxa de erro média durante uma janela de 5 minutos de um serviço com uma duração de 10 minutos antes do disparo do alerta. Uma série de picos de erro de 100% com duração de 5 minutos a cada 10 minutos nunca aciona um alerta, apesar de consumir 35% do orçamento de erro.
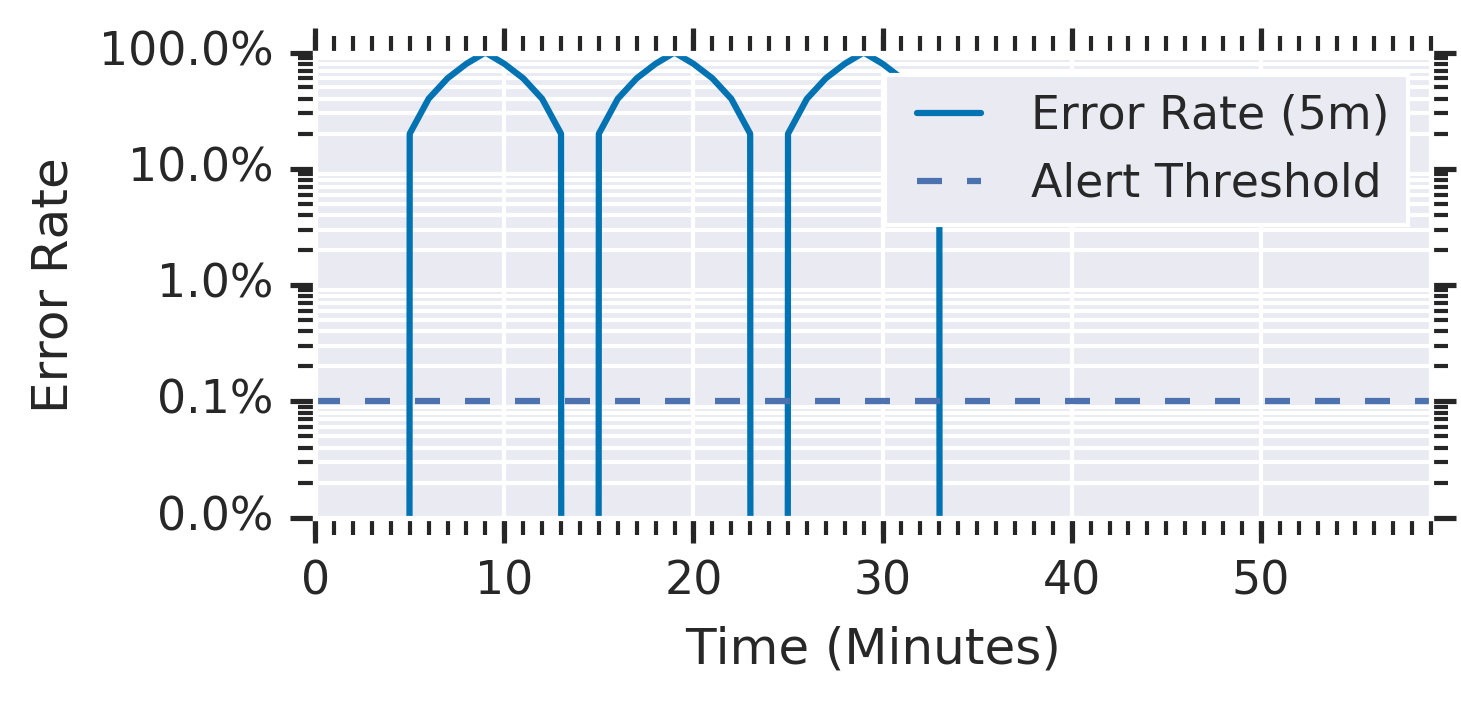
Figura 5-3. Um serviço com picos de erro de 100% a cada 10 minutos
Cada pico consumiu quase 12% do orçamento de 30 dias, mas o alerta nunca foi acionado.
4: Alerta sobre a taxa de queima
Para melhorar a solução anterior, você deseja criar um alerta com bom tempo de detecção e alta precisão. Para este fim, você pode introduzir uma taxa de queima para reduzir o tamanho da janela, mantendo constante o gasto do orçamento de alerta.
A taxa de queima é a rapidez, com que, em relação ao SLO, o serviço consome o orçamento de erro. A figura 5-4 mostra a relação entre as taxas de queima e os orçamentos de erro.
O serviço de exemplo utiliza uma taxa de queima de 1, o que significa que consome o orçamento de erro a uma taxa que deixa você com exatamente 0 orçamento no final da janela de tempo do SLO (ver Capítulo 4 no nosso primeiro livro). Com um SLO de 99,9% em uma janela de tempo de 30 dias, uma taxa de erro constante de 0,1% usa exatamente todo o orçamento de erro: uma taxa de queima de 1.
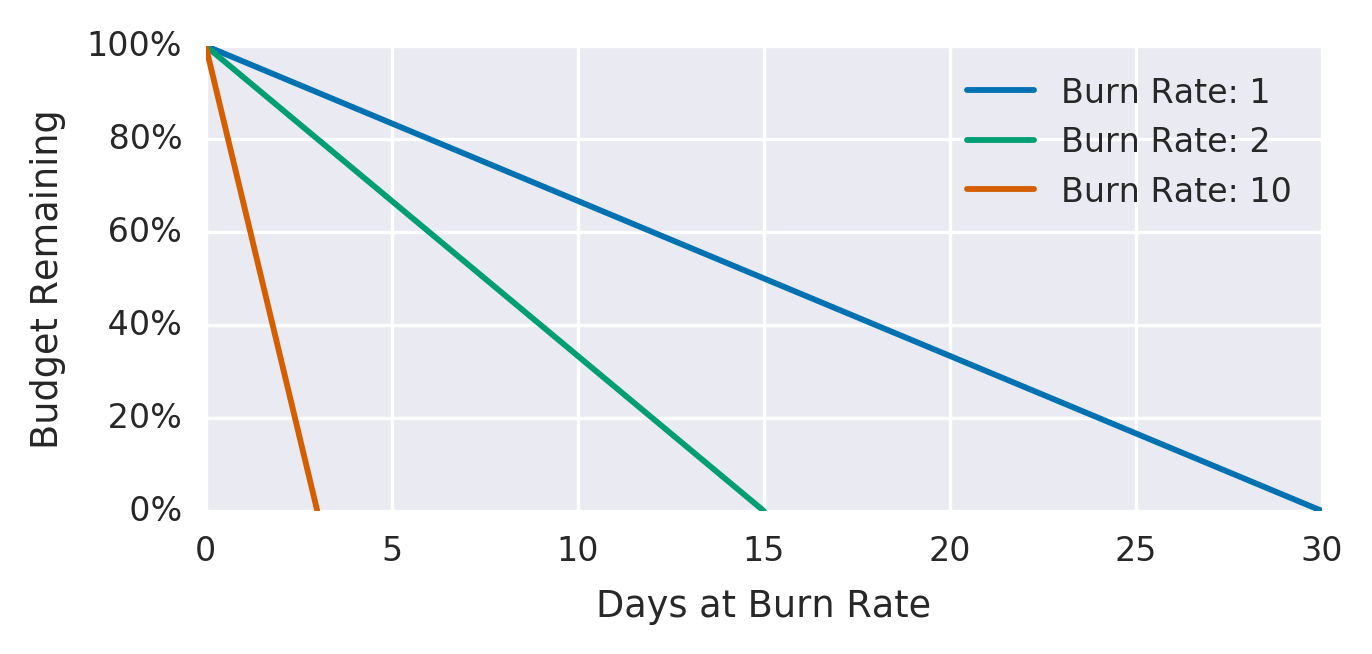
Figura 5-4. Orçamentos de erro em relação às taxas de queima
A tabela 5-4 mostra as taxas de queima, as suas correspondentes taxas de erro, e o tempo que leva para esgotar o orçamento SLO.
Tabela 5-4.Taxas de queima e tempo para completar o esgotamento do orçamento
| Taxa de queima | Taxa de erro para um SLO de 99,9% | Tempo até à queima |
| 1 | 0.1% | 30 dias |
| 2 | 0.2% | 15 dias |
| 10 | 1% | 3 dias |
| 1,000 | 100% | 43 minutos |
Ao manter a janela de alerta fixa em uma hora e decidir que um orçamento de 5% de orçamento de erro é significativo o suficiente para notificar alguém, você pode derivar a taxa de queima a ser usada para o alerta.
Para alertas baseados na taxa de queima, o tempo necessário para um alerta disparar é:
1-SLO
________
Taxa de erro X tamanho da janela de alerta X taxa de queima
O orçamento de erro consumido até ao momento em que o alerta dispara:
Taxa de queima X Tamanho das janelas de alerta
_______________________________
Período
Cinco por cento de um orçamento de erro de 30 dias gasto por mais de uma hora requer uma taxa de queima de 36. A regra do alerta torna-se agora:
– alert: HighErrorRate
expr: job:slo_errors_per_request:ratio_rate1h{job=”myjob”} > 36 * 0.001
A tabela 5-5 mostra os benefícios e limitações do alerta com base na taxa de queima.
Tabela 5-5.Prós e contras do alerta com base na taxa de queima
| Pros | Contras |
| Boa precisão: Esta estratégia escolhe uma parte significativa do gasto de orçamento de erro sobre o qual se deve alertar.
Menor janela de tempo, o que é mais barato de calcular. Bom tempo de detecção. Melhor tempo de reset: 58 minutos. |
Baixo recall: Uma taxa de queima de 35x nunca alerta, mas consome todo o orçamento de erro de 30 dias em 20,5 horas.
Tempo de reset: 58 minutos é ainda muito longo. |
5: Alertas de múltiplas taxas de queima
A sua lógica de alerta pode usar múltiplas taxas de queima e janelas de tempo, e disparar alertas quando as taxas de queima ultrapassarem um limite especificado. Essa opção mantém os benefícios de alertar sobre taxas de queima e garante que você não ignore taxas de erro mais baixas (mas ainda significativas).
É também uma boa ideia estabelecer notificações de tickets para incidentes que normalmente passam despercebidos, mas que podem esgotar o seu orçamento de erro se não forem verificados – por exemplo, um consumo orçamental de 10% em três dias. Esta taxa de erros detecta eventos significativos, mas como a taxa de consumo do orçamento fornece o tempo adequado para abordar o evento, não é necessário chamar alguém.
Recomendamos 2% de consumo de orçamento em uma hora e 5% de consumo de orçamento em seis horas como números iniciais razoáveis para paginação, e 10% de consumo de orçamento em três dias como uma boa base de referência para alertas de ticket. Os números apropriados dependem do serviço e do carregamento da página de linha de base. Para serviços mais ocupados, e dependendo das responsabilidades de plantão nos finais de semana e feriados, poderá querer alertas de tickets para a janela de seis horas.
A tabela 5-6 mostra as taxas de queima correspondentes e as janelas de tempo para as percentagens do orçamento SLO consumido.
Tabela 5-6.janelas de tempo e taxas de queima recomendadas para percentagens do orçamento SLO consumido
| Consumo de orçamento SLO | Período de tempo | Taxa de queima | Notificação |
| 2% | 1 hora | 14.4 | Página |
| 5% | 6 horas | 6 | Página |
| 10% | 3 dias | 1 | Ticket |
A configuração de alerta pode ser algo como:
expr: (
job:slo_errors_per_request:ratio_rate1h{job=”myjob”} > (14.4*0.001)
or
job:slo_errors_per_request:ratio_rate6h{job=”myjob”} > (6*0.001)
)
severity: page
expr: job:slo_errors_per_request:ratio_rate3d{job=”myjob”} > 0.001
severity: ticket
A figura 5-5 mostra o tempo de detecção e o tipo de alerta de acordo com a taxa de erro.
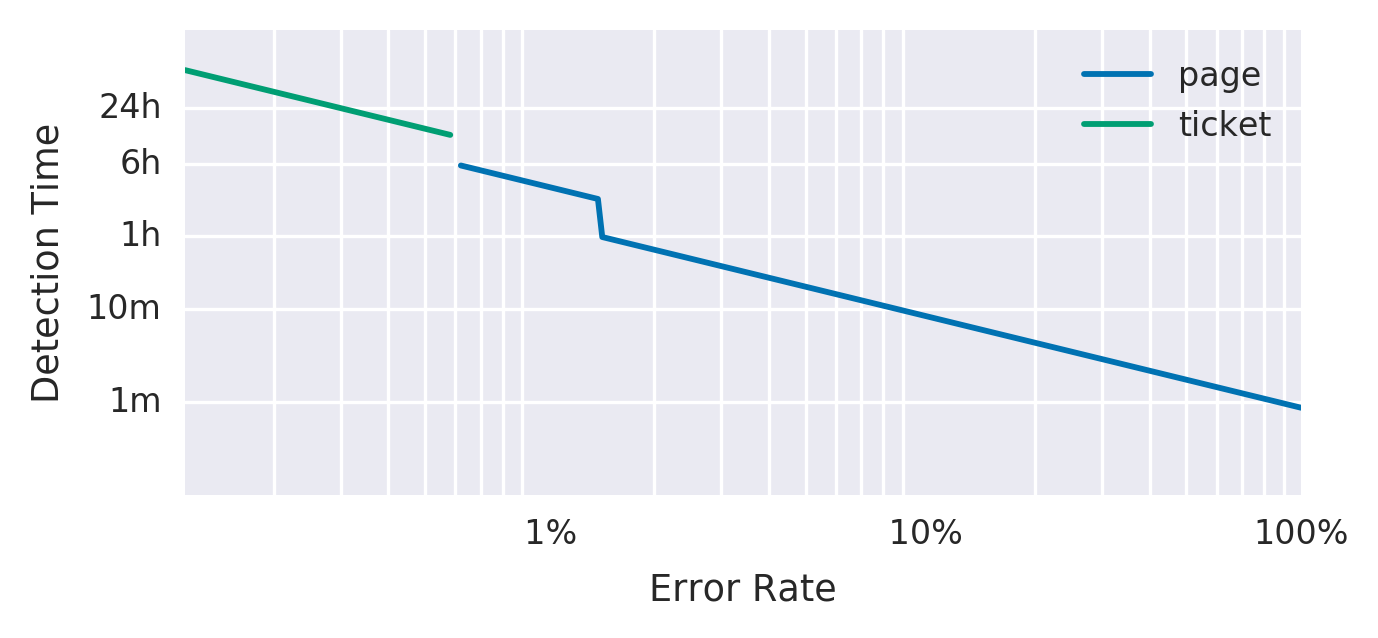
Figura 5-5. Taxa de erro, tempo de detecção, e notificação de alerta
As múltiplas taxas de queimas lhe permitem ajustar o alerta para dar a prioridade adequada com base na rapidez com que tem de responder. Se um problema esgotar o orçamento do erro dentro de horas ou alguns dias, é apropriado enviar uma notificação ativa. Caso contrário, uma notificação baseada em ticket para endereçar o alerta no próximo dia útil é mais apropriada.
A tabela 5-7 lista os benefícios e desvantagens da utilização de múltiplas taxas de queima.
Tabela 5-7.Prós e contras da utilização de múltiplas taxas de queima
| Prós | Contras |
| Capacidade de adaptar a configuração de monitoramento a muitas situações de acordo com a criticidade: alertar rapidamente se a taxa de erro for alta; alertar eventualmente se a taxa de erro for baixa, mas sustentada.
Boa precisão, como em todas as abordagens de alerta de parte do orçamento fixo. Bom recall, por causa da janela de três dias. Capacidade de escolher o tipo de alerta mais apropriado com base na rapidez com que alguém tem de reagir para defender o SLO. |
Mais números, tamanhos de janelas, e limiares para gerenciar e raciocinar.
Um tempo de reset ainda mais longo, como resultado da janela de três dias. Para evitar que múltiplos alertas sejam disparados se todas as condições forem verdadeiras, é necessário implementar a supressão de alertas. Por exemplo: 10% do orçamento gasto em cinco minutos significa também que 5% do orçamento foi gasto em seis horas, e 2% do orçamento foi gasto em uma hora. Este cenário desencadeará três notificações, a menos que o sistema de monitoramento seja suficientemente inteligente para impedir que isso aconteça. |
6: Alertas multijanela, Multi-queima
Podemos melhorar os alertas de multi queima na iteração 5 para nos notificar apenas quando ainda estamos queimando ativamente o orçamento – reduzindo assim o número de falsos positivos. Para tal, precisamos adicionar outro parâmetro: uma janela mais curta para verificar se o orçamento de erro ainda está sendo consumido à medida que desencadeamos o alerta.
Uma boa orientação é fazer da janela curta 1/12 a duração da janela longa, como se mostra na Figura 5-6. O gráfico mostra ambos os limiares de alerta. Depois de experimentar 15% de erros durante 10 minutos, a média da janela curta ultrapassa imediatamente o limiar de alerta, e a média da janela longa ultrapassa o limiar após 5 minutos, altura em que o alerta começa a disparar. A média da janela curta cai abaixo do limiar 5 minutos após os erros pararem, o ponto em que o alerta para de disparar. A média da janela longa cai abaixo do limiar 60 minutos depois de os erros pararem.
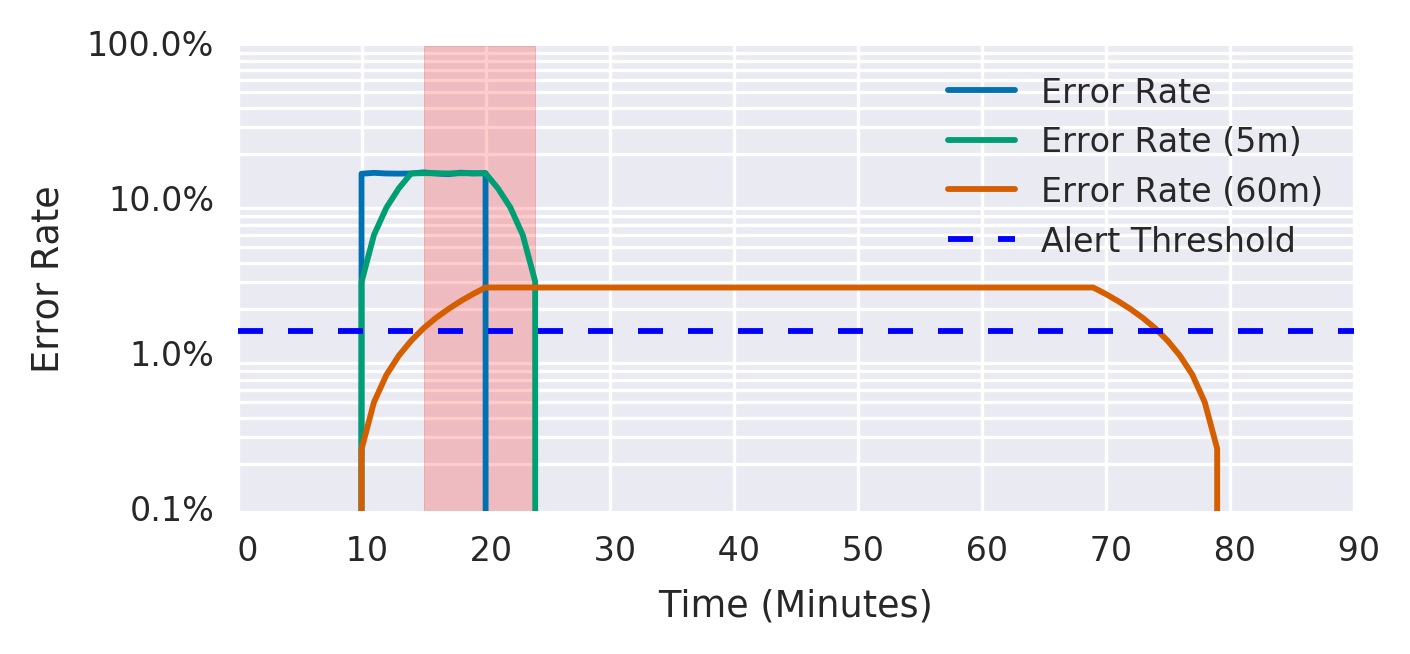
Figura 5-6. Janelas curtas e longas para alertar
Por exemplo, você pode enviar um alerta de nível de página quando exceder a taxa de queima de 14,4x, tanto na hora anterior como nos cinco minutos anteriores. Este alerta só dispara depois de ter consumido 2% do orçamento, mas exibe um melhor tempo de reset ao deixar de ser acionado cinco minutos depois, em vez de uma hora depois:
expr: (
job:slo_errors_per_request:ratio_rate1h{job=”myjob”} > (14.4*0.001)
and
job:slo_errors_per_request:ratio_rate5m{job=”myjob”} > (14.4*0.001)
)
or
(
job:slo_errors_per_request:ratio_rate6h{job=”myjob”} > (6*0.001)
and
job:slo_errors_per_request:ratio_rate30m{job=”myjob”} > (6*0.001)
)
severity: page
expr: (
job:slo_errors_per_request:ratio_rate24h{job=”myjob”} > (3*0.001)
and
job:slo_errors_per_request:ratio_rate2h{job=”myjob”} > (3*0.001)
)
or
(
job:slo_errors_per_request:ratio_rate3d{job=”myjob”} > 0.001
and
job:slo_errors_per_request:ratio_rate6h{job=”myjob”} > 0.001
)
severity: ticket
Recomendamos os parâmetros listados na Tabela 5-8 como ponto de partida para a sua configuração de alerta com base no SLO.
Tabela 5-8.Parâmetros recomendados para uma configuração de alerta SLO de 99,9%
| Severidade | Janela longa | Janela curta | Taxa de queima | Orçamento de erro consumido |
| Página | 1 hora | 5 minutos | 14.4 | 2% |
| Página | 6 horas | 30 minutos | 6 | 5% |
| Ticket | 3 dias | 6 horas | 1 | 10% |
Descobrimos que o alerta baseado em múltiplas taxas de queimas é uma forma poderosa de implementar o alerta baseado em SLO.
A tabela 5-9 mostra os benefícios e limitações da utilização de múltiplas taxas de queimas e tamanhos de janelas.
Tabela 5-9.Prós e contras da utilização de múltiplas taxas de queima e tamanhos de janelas
| Prós | Contras |
| Uma estrutura de alertas flexível que lhe permite controlar o tipo de alerta de acordo com a gravidade do incidente e os requisitos da organização.
Boa precisão, como em todas as abordagens de alerta de parcela de orçamento fixo. Bom recall, por causa da janela de três dias. |
Muitos parâmetros para especificar, o que pode dificultar o gerenciamento das regras de alerta. Para mais informações sobre a gestão de regras de alerta, ver Alerta em escala. |
Serviços de baixo tráfego e alerta de orçamento de erro
A abordagem multijanela, multi-taxa-de-queima só funciona bem quando uma taxa suficientemente elevada de solicitações recebidas fornece um sinal significativo quando surge um problema. Contudo, estas abordagens podem causar problemas aos sistemas que recebem uma baixa taxa de solicitações. Se um sistema tiver um número baixo de usuários ou períodos naturais de baixo tráfego (como noites e fins de semana), poderá ser necessário alterar a sua abordagem.
É mais difícil distinguir automaticamente eventos sem importância em serviços de baixo tráfego. Por exemplo, se um sistema recebe 10 solicitações por hora, então uma única solicitação com falha resulta numa taxa de erro horária de 10%. Para um SLO de 99,9%, essa solicitação constitui uma taxa de queima de 1.000x e seria paginada imediatamente, uma vez que consumiu 13,9% do orçamento de erro de 30 dias. Este cenário permite apenas sete solicitações com falha em 30 dias. Solicitações únicas podem falhar por um grande número de razões efêmeras e desinteressantes que não são necessariamente rentáveis para resolver da mesma forma que grandes interrupções sistemáticas.
A melhor solução depende da natureza do serviço: qual é o impacto de uma única solicitação com falha? Um objetivo de alta disponibilidade pode ser apropriado se as solicitações com falha forem solicitações únicas e de alto valor que não são repetidas. Pode fazer sentido de uma perspectiva empresarial investigar cada solicitação com falha. No entanto, neste caso, o sistema de alerta notifica você sobre um erro tarde demais.
Recomendamos algumas opções importantes para lidar com um serviço de baixo tráfego:
- Gere tráfego artificial para compensar a falta de sinal de usuários reais.
- Combine serviços menores em um serviço maior para fins de monitoramento.
- Modifique o produto para que:
- Sejam necessárias mais solicitações para qualificar um único incidente como uma falha.
- O impacto de uma única falha seja menor.
Geração de Tráfego Artificial
Um sistema pode sintetizar a atividade do usuário para verificar possíveis erros e solicitações de alta latência. Na ausência de usuários reais, seu sistema de monitoramento pode detectar erros e solicitações sintéticas, para que seus engenheiros de plantão possam responder a problemas antes que eles afetem muitos usuários reais.
O tráfego artificial fornece mais sinais para trabalhar, e permite a reutilização da sua lógica de monitoramento existente e dos valores SLO. Você pode até já ter a maioria dos componentes de geração de tráfego necessários, como sondas de caixa preta e testes de integração.
A geração de carga artificial tem alguns aspectos negativos. A maioria dos serviços que merecem apoio SRE são complexos, e têm uma grande superfície de controle do sistema. Idealmente, o sistema deveria ser projetado e construído para monitoramento usando tráfego artificial. Mesmo para um serviço não trivial, só se pode sintetizar uma pequena parte do número total de tipos de solicitação do usuário. Para um serviço stateful, o maior número de estados agrava este problema.
Além disso, se um problema afetar usuários reais mas não afetar o tráfego artificial, as solicitações artificiais bem-sucedidas ocultarão o sinal real do usuário, para que você não seja notificado de que os usuários veem erros.
Combinando serviços
Se vários serviços de baixo tráfego contribuírem para uma função geral, combinar suas solicitações em um único grupo de nível superior pode detectar eventos significativos com mais precisão e com menos falsos positivos. Para que esta abordagem funcione, os serviços devem estar relacionados de alguma forma – pode combinar micro-serviços que fazem parte do mesmo produto, ou vários tipos de solicitação tratados pelo mesmo binário.
Uma desvantagem da combinação de serviços é que uma falha completa de um serviço individual pode não contar como um evento significativo. É possível aumentar a probabilidade de que uma falha afete o grupo como um todo, escolhendo serviços com um domínio de falha compartilhado, tais como uma base de dados backend comum. Ainda é possível utilizar alertas de períodos mais longos que eventualmente detectam essas falhas de 100% para serviços individuais.
Fazer mudanças de serviços e infra-estruturas
O alerta sobre eventos significativos visa fornecer aviso prévio suficiente para mitigar problemas antes que estes esgotem todo o orçamento de erro. Se não for possível ajustar o monitoramento para ser menos sensível a eventos efêmeros, e gerar tráfego sintético for impraticável, considere alterar o serviço para reduzir o impacto do usuário de uma única solicitação com falha. Por exemplo, você pode:
- Modificar o cliente para tentar de novo, com exponencial backoff e jitter.
- Configurar caminhos de fallback que capturem a solicitação para eventual execução, que pode ocorrer no servidor ou no cliente.
Estas mudanças são úteis para sistemas de alto tráfego, mas ainda mais para sistemas de tráfego reduzido: elas permitem mais eventos com falha no orçamento de erros, mais sinais de monitoramento e mais tempo para responder a um incidente antes que ele se torne significativo.
Baixar o SLO ou Aumentar a Janela
Também poderá querer reconsiderar se o impacto de uma única falha no orçamento do erro reflete com precisão seu impacto nos usuários. Se um pequeno número de erros lhe causar a perda do orçamento de erro, você realmente precisa chamar um engenheiro para corrigir o problema imediatamente? Se não, os usuários ficariam igualmente satisfeitos com um SLO mais baixo. Com um SLO mais baixo, um engenheiro é notificado apenas de uma maior interrupção prolongada.
Uma vez negociada a redução do SLO com as partes interessadas do serviço (por exemplo, a redução do SLO de 99,9% para 99%), a implementação da alteração é muito simples: se já tiver sistemas implementados para a elaboração de relatórios, monitoramento e alerta com base num limiar SLO, basta adicionar o novo valor SLO aos sistemas relevantes.
A redução do SLO tem um lado negativo: envolve uma decisão sobre o produto. A alteração do SLO afeta outros aspectos do sistema, tais como as expectativas em torno do comportamento do sistema e quando deve ser decretada a política de orçamento de erro. Estes outros requisitos podem ser mais importantes para o produto do que evitar algum número de alertas de baixo sinal.
De modo semelhante, o aumento da janela de tempo utilizada para a lógica de alerta garante que os alertas que acionam as páginas sejam mais significativos e dignos de atenção.
Na prática, utilizamos alguma combinação dos seguintes métodos para alertar para serviços de baixo tráfego:
- Gerar tráfego falso, quando isso é possível e pode conseguir uma boa cobertur
- Modificar os clientes para que as falhas efêmeras sejam menos suscetíveis de causar danos ao usuário
- Agregar serviços mais pequenos que compartilham algum modo de falha
- Definir limiares SLO proporcionais ao impacto real de uma solicitação com falha
Metas de Disponibilidade Extrema
Serviços com uma meta de disponibilidade extremamente baixa ou extremamente alta podem exigir consideração especial. Por exemplo, considerar um serviço que tenha uma meta de disponibilidade de 90%. A tabela 5-8 diz para a página quando 2% do orçamento de erro numa única hora for consumido. Como uma interrupção de 100% consome apenas 1,4% do orçamento naquela hora, esse alerta nunca poderia ser acionado. Se seus orçamentos de erro forem definidos por longos períodos, talvez seja necessário ajustar seus parâmetros de alerta.
Para serviços com uma meta de disponibilidade extremamente elevada, o tempo até a exaustão para uma interrupção de 100% é extremamente pequeno. Uma interrupção de 100% para um serviço com uma meta de disponibilidade mensal de 99,999% esgotaria seu orçamento em 26 segundos – o que é menor do que o intervalo de coleta de métrica de muitos serviços de monitoramento, sem falar no tempo de ponta a ponta para gerar um alerta e passá-lo através de sistemas de notificação como e-mail e SMS. Mesmo que o alerta vá direto para um sistema de resolução automatizado, o problema pode consumir totalmente o orçamento de erros antes que você possa mitigá-lo.
Receber notificações de que apenas lhe restam 26 segundos de orçamento não é necessariamente uma má estratégia; apenas não é útil para defender o SLO. A única maneira de defender esse nível de confiabilidade é projetar o sistema de modo que a chance de uma interrupção de 100% seja extremamente baixa. Dessa forma, é possível resolver os problemas antes de consumir o orçamento. Por exemplo, se inicialmente implementar essa alteração para apenas 1% dos seus usuários, e queimar o seu orçamento de erro à mesma taxa de 1%, tem agora 43 minutos antes de esgotar o seu orçamento de erro. Ver Capitulo 16 para táticas sobre como projetar tal sistema.
Alerta em Escala
Ao escalar o seu serviço, certifique-se de que a sua estratégia de alerta é igualmente escalável. Poderá ser tentado a especificar parâmetros de alerta personalizados para serviços individuais. Se o seu serviço compreende 100 microserviços (ou equivalente, um único serviço com 100 tipos de solicitação diferentes), este cenário acumula muito rapidamente uma labuta e uma carga cognitiva que não é escalável.
Neste caso, desaconselhamos vivamente a especificação da janela de alerta e parâmetros de taxa de queima independentemente para cada serviço, porque fazê-lo rapidamente se torna avassalador. Uma vez decididos os seus parâmetros de alerta, apliquem-nos a todos os seus serviços.
Uma técnica para gerir um grande número de SLOs é agrupar tipos de solicitação em buckets com requisitos de disponibilidade aproximadamente semelhantes. Por exemplo, para um serviço com SLOs de disponibilidade e latência, pode agrupar os seus tipos de pedido nos seguintes buckets:
CRÍTICO
Para os tipos de solicitação mais importantes, como uma solicitação quando um usuário efetua login no serviço.
HIGH_FAST
Para solicitações com requisitos de alta disponibilidade e baixa latência. Essas solicitações envolvem a funcionalidade interativa principal, como quando um usuário clica em um botão para ver quanto dinheiro seu inventário de publicidade ganhou este mês.
HIGH_SLOW
Para funcionalidades importantes, mas menos sensíveis à latência, tais como quando um usuário clica num botão para gerar um relatório de todas as campanhas publicitárias dos últimos anos, e não espera que os dados retornem instantaneamente.
BAIXO
Para solicitações que devem ter alguma disponibilidade, mas para as quais as interrupções são invisíveis para os usuários, por exemplo, manipuladores de sondagem para notificações de conta que podem falhar por longos períodos sem impacto no usuário.
NO_SLO
Para funcionalidades que são completamente invisíveis para o usuário – por exemplo, lançamentos escuros ou funcionalidades alfa que estão explicitamente fora de qualquer SLO.
Ao agrupar solicitações em vez de colocar objetivos exclusivos de disponibilidade e latência em todos os tipos de solicitação, você pode agrupar solicitações em cinco buckets, como o exemplo da Tabela 5-10 .
Tabela 5-10: Solicitar buckets de classe de acordo com requisitos e limites de disponibilidade semelhantes
| Solicitar classe | Disponibilidade | Latência @ 90% | Latência @ 99% |
| CRÍTICO | 99.99% | 100 ms | 200 ms |
| HIGH_FAST | 99.9% | 100 ms | 200 ms |
| HIGH_SLOW | 99.9% | 1,000 ms | 5,000 ms |
| BAIXO | 99% | Nenhum | Nenhum |
| NO_SLO | Nenhum | Nenhum | Nenhum |
Esses buckets fornecem fidelidade suficiente para proteger a felicidade do usuário, mas envolvem menos trabalho do que um sistema mais complicado e caro de gerenciar que provavelmente mapeia com mais precisão a experiência do usuário.
Conclusão
Se você definir SLOs que sejam significativos, compreendidos e representados em métricas, poderá configurar o alerta para notificar um plantonista apenas quando houver ameaças acionáveis e específicas ao orçamento de erro.
As técnicas para alertar sobre eventos significativos vão desde alertar quando sua taxa de erro ultrapassa o limite do SLO até à utilização de múltiplos níveis de taxa de queima e tamanhos de janelas. Na maioria dos casos, acreditamos que a técnica de alerta de múltiplas janelas e múltiplas taxas de queimas é a abordagem mais apropriada para defender os SLOs da sua aplicação.
Esperamos ter fornecido a você o contexto e as ferramentas necessárias para tomar as decisões de configuração corretas para a sua própria aplicação e organização.
Fonte : Google SRE Work Book