Escrito por David Challoner, Joanna Wijntjes, David Huska,
Matthew Sartwell, Chris Coykendall, Chris Schrier,
John Looney, e Vivek Rau
Com Betsy Beyer, Max Luebbe, Alex Perry, e Murali Suriar
Os SREs do Google gastam muito do seu tempo otimizando, extraindo cada pedacinho do desempenho de um sistema por meio do trabalho de projeto e da colaboração do desenvolvedor. Mas o escopo da otimização não se limita ao cálculo dos recursos: é também importante que os SREs otimizem a forma como gastam o seu tempo. Em primeiro lugar, queremos evitar a execução de tarefas classificadas como toil. Para uma discussão abrangente sobre toil, ver Capítulo 5 em Engenharia da Confiabilidade do Site. Para os propósitos deste capítulo, definiremos toil como o fluxo repetitivo, previsível e constante de tarefas relacionadas com a manutenção de um serviço.
O toil é aparentemente inevitável para qualquer equipe que gerencia um serviço de produção. A manutenção do sistema inevitavelmente exige uma certa quantidade de lançamentos, atualizações, reinicializações, triagem de alertas e assim por diante. Estas atividades podem rapidamente consumir uma equipe se não forem verificadas e não forem contabilizadas. O Google limita o tempo que as equipes SRE gastam em trabalho operacional (incluindo tanto o toil intenso como o toil não intenso) a 50% (para mais informações sobre os motivos, ver Capítulo 5 no nosso primeiro livro). Embora este objetivo possa não ser apropriado para a sua organização, ainda há uma vantagem em colocar um limite superior no toil, já que identificar e quantificar o toil é o primeiro passo para otimizar o tempo da sua equipe.
O que é Toil?
O toil tende a cair sobre um espectro medido pelas seguintes características, que são descritas no nosso primeiro livro. Aqui, damos um exemplo concreto para cada característica do toil:
Manual
Quando o diretório tmp em um servidor web atinge 95% de utilização, a engenheira Anne efetua login no servidor e vasculha o sistema de arquivos em busca de arquivos de log estranhos para serem excluídos.
Repetitivos
Um diretório tmp completo é pouco provável que seja um evento único, portanto, a tarefa de corrigi-lo é repetitiva.
Automatizável
Se a sua equipe tiver documentos de correção com conteúdos como “iniciar sessão em X, executar este comando, verificar a saída, reiniciar Y se vir…”, estas instruções são essencialmente pseudo-códigos para alguém com capacidades de desenvolvimento de software! No exemplo do diretório tmp, a solução foi parcialmente automatizada. Seria ainda melhor automatizar totalmente a detecção e a correção do problema, não exigindo um humano para executar o script. Melhor ainda, submeter um patch para que o software não quebre mais desta forma.
Não tático/reativo
Quando você recebe muitos alertas como “disco cheio” e “servidor inativo”, eles distraem os engenheiros da engenharia de maior valor e potencialmente mascaram outros alertas de maior gravidade. Como resultado, a saúde do serviço sofre.
Falta de valor duradouro
A conclusão de uma tarefa traz frequentemente uma sensação satisfatória de realização, mas esta satisfação repetitiva não é positiva a longo prazo. Por exemplo, fechar aquele ticket gerado pelo alerta garantiu que as consultas do usuário continuassem a fluir e as solicitações HTTP continuassem a servir com códigos de status < 400, o que é bom. No entanto, a resolução do ticket hoje não impedirá a questão no futuro, portanto, o retorno tem uma curta duração.
Cresce pelo menos tão rapidamente como a sua fonte
Muitas classes de trabalho operacional crescem tão rapidamente como (ou mais rapidamente do que) a dimensão da infra-estrutura subjacente. Por exemplo, pode-se esperar que o tempo gasto na execução de reparações de hardware aumente de forma gradual com o tamanho de uma frota de servidores. O trabalho de reparação física pode inevitavelmente escalar com o número de máquinas, mas as tarefas auxiliares (por exemplo, fazer alterações de software/configuração) não têm necessariamente de o fazer.
As fontes de toil podem nem sempre satisfazer todos estes critérios, mas lembrem-se de que o toil do dia-a-dia vem em muitas formas. Para além dos traços anteriores, considere o efeito que um determinado trabalho tem no moral da equipe. As pessoas gostam de fazer uma tarefa e a acham gratificante, ou é o tipo de trabalho que é muitas vezes negligenciado por ser visto como chato ou sem recompensa? O toil pode lentamente diminuir o moral da equipe. O tempo gasto trabalhando no toil geralmente é o tempo que não é gasto pensando criticamente ou expressando criatividade; reduzir o toil é um reconhecimento de que o esforço de um engenheiro é melhor utilizado em áreas onde o julgamento e a expressão humana são possíveis.
Exemplo: Resposta manual ao toil
Escrito por John Looney, gerente de engenharia de produção do Facebook e sempre um SRE de coração
Nem sempre é claro que uma determinada parte do trabalho é toil. Por vezes, uma solução “criativa” – escrever uma solução alternativa – não é a decisão certa. Idealmente, a sua organização deveria recompensar as correções de causa raiz sobre as correções que simplesmente mascaram um problema.
A minha primeira tarefa após ter entrado no Google (Abril de 2005) foi entrar em máquinas avariadas, investigar porque estavam avariadas, depois consertá-las ou enviá-las a um técnico de hardware. Esta tarefa parecia simples até que percebi que havia mais de 20.000 máquinas avariadas num dado momento!
A primeira máquina avariada que investiguei tinha um sistema de arquivos raiz que estava completamente cheio com gigabytes de logs sem sentido de um driver de rede Google-patched. Encontrei mais mil máquinas avariadas com o mesmo problema. Eu compartilhei meu plano para resolver o problema com meu colega de equipe: Eu escreveria um script para ssh em todas as máquinas avariadas e verificaria se o sistema de arquivos raiz estava completamente cheio. Se o sistema de arquivos estivesse cheio, o script truncaria qualquer logs maiores que um megabyte em /var/log e reiniciaria o syslog.
A reação pouco entusiasmada do meu companheiro de equipe ao meu plano me fez parar. Ele assinalou que é melhor corrigir as causas raiz quando possível. A médio e longo prazo, escrever um script que mascarasse a gravidade do problema desperdiçaria tempo (por não corrigir o problema real) e potencialmente causaria mais problemas posteriormente.
A análise demonstrou que cada servidor custaria provavelmente $1 por hora. De acordo com a minha linha de pensamento, o custo não deveria ser a métrica mais importante? Eu não tinha considerado que se corrigisse o sintoma, não haveria incentivo para corrigir a causa raiz: o conjunto de testes de lançamento da equipe do kernel não verificou o volume de logs que essas máquinas produziam.
O engenheiro sênior me direcionou para a fonte do kernel para que eu pudesse encontrar a linha ofensiva de código e registrar um bug contra a equipe do kernel para melhorar seu conjunto de testes. A minha análise objetiva de custo/benefício mostrando que o problema estava custando 1000 dólares por hora ao Google convenceu os desenvolvedores a corrigir o problema com meu patch.
O meu patch foi transformado numa nova versão do kernel nessa noite, e no dia seguinte, eu o coloquei nas máquinas afetadas. A equipe do kernel atualizou o seu conjunto de testes no final da semana seguinte. Em vez do ataque de endorfina a curto prazo de consertar essas máquinas todas as manhãs, agora eu tinha o prazer mais cerebral de saber que havia resolvido o problema corretamente.
Medir o toil
Como você sabe quanto do seu trabalho operacional é toil? E depois de ter decidido tomar medidas para reduzir o toil, como sabe se os seus esforços foram bem sucedidos ou justificados? Muitas equipes SRE respondem a estas perguntas com uma combinação de experiência e intuição. Embora tais tácticas possam produzir resultados, podemos melhorá-las.
A experiência e a intuição não são repetíveis, objetivas ou transferíveis. Os membros da mesma equipe ou organização chegam frequentemente a conclusões diferentes quanto à magnitude do esforço de engenharia perdido e, por conseguinte, dão prioridade aos esforços de remediação de forma diferente. Além disso, os esforços de redução do toil podem abranger trimestres ou mesmo anos (como demonstrado por alguns dos estudos de caso neste capítulo), durante os quais as prioridades da equipe e o pessoal podem mudar. Para manter o foco e justificar o custo a longo prazo, é necessária uma medida objetiva de progresso. Normalmente, as equipes devem escolher um projeto de redução de toil entre vários candidatos. Uma medida objetiva de toil permite que sua equipe avalie a gravidade dos problemas e priorize-os para obter o máximo retorno sobre o investimento em engenharia.
Antes de iniciar projetos de redução de toil, é importante analisar o custo versus o benefício e confirmar que o tempo poupado através da eliminação do toil será (no mínimo) proporcional ao tempo investido no primeiro desenvolvimento e depois na manutenção de uma solução automatizada (Figura 6-1). Os projetos que parecem “não rentáveis” a partir de uma comparação simplista de horas poupadas versus horas investidas podem ainda valer a pena ser empreendidos devido aos muitos benefícios indiretos ou intangíveis da automatização. Os potenciais benefícios poderiam incluir:
- Crescimento do trabalho de projeto de engenharia ao longo do tempo, alguns dos quais irão reduzir ainda mais o toil
- Aumento do moral da equipe e diminuição do desgaste e esgotamento da equipe
- Menos mudança de contexto para interrupções, o que aumenta a produtividade da equipe
- Aumento da clareza e padronização do processo
- Melhoria das competências técnicas e crescimento da carreira dos membros da equipe
- Tempo de treinamento reduzido
- Menos interrupções atribuíveis a erros humanos
- Melhoria da segurança
- Tempos de resposta mais curtos para solicitações de usuários
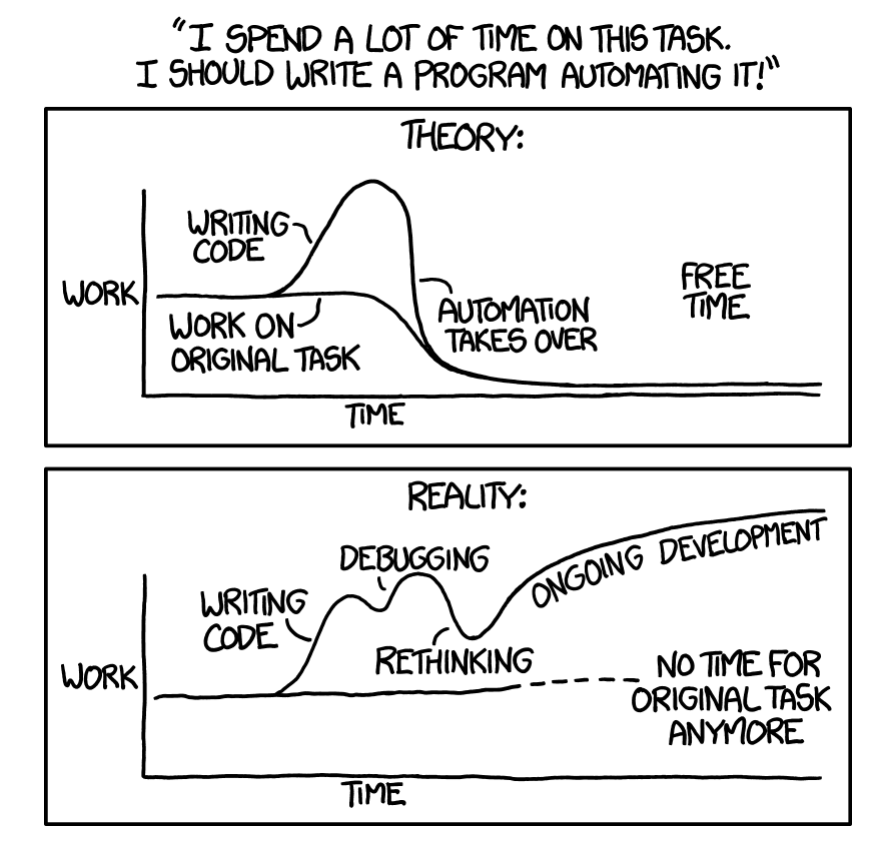
Figura 6-1. Faça uma estimativa do tempo que irá gastar nos esforços de redução do toil, e certifique-se de que os benefícios superam o custo (fonte: xkcd.com/1319/)
Então como é que recomendamos que meça o toil?
- Identifique-o. O capítulo 5 do primeiro livro do SRE oferece orientações para a identificação do toil nas suas operações. As pessoas mais bem posicionadas para identificar o toil dependem da sua organização. Idealmente, elas serão partes interessadas, incluindo as que irão realizar o trabalho real.
- Selecione uma unidade de medida apropriada que expresse a quantidade de esforço humano aplicado a este toil. Os minutos e horas são uma escolha natural, porque são objetivos e universalmente compreendidos. Certifique-se de levar em conta o custo da troca de contexto. Para os esforços que são distribuídos ou fragmentados, um balde de esforço humano bem compreendido pode ser mais apropriado. Alguns exemplos de unidades de medida incluem um patch aplicado, um ticket concluído, uma alteração de produção manual, uma troca de e-mail previsível ou uma operação de hardware. Desde que a unidade seja objetiva, consistente e bem compreendida, pode servir como uma medida de toil.
- Acompanhe continuamente estas medições antes, durante e depois dos esforços de redução do toil. Agilize o processo de medição usando ferramentas ou scripts para que a coleta destas medições não crie toil adicional!
Taxonomia do Toil
O toil, como uma ponte em ruínas ou uma represa vazando, esconde-se no cotidiano banal. As categorias desta seção não são exaustivas, mas representam algumas categorias comuns do toil. Muitas destas categorias parecem ser trabalhos de engenharia “normais”, e são. É útil pensar no toil como um espectro em vez de uma classificação binária.
Processos de Negócios
Esta é provavelmente a fonte mais comum de toil. Talvez a sua equipe gere alguns recursos informáticos – computação, armazenamento, rede, balanceadores de carga, bases de dados, e assim por diante com o hardware que fornece esse recurso. Você lida com a integração de usuários, configurando e protegendo suas máquinas, realizando atualizações de software e adicionando e removendo servidores com capacidade moderada. Trabalha também para minimizar o custo ou desperdício desse recurso. A sua equipe é a interface humana para a máquina, interagindo normalmente com clientes internos que arquivam tickets para as suas necessidades. A sua organização pode até ter múltiplos sistemas de emissão de tickets e sistemas de entrada de trabalho.
O toil de ticket é um pouco insidioso porque os processos de negócio orientados para os tickets geralmente atingem o seu objetivo. Os usuários conseguem o que querem, e porque o toil é tipicamente disperso uniformemente pela equipe, o toil não é barulhento e obviamente exige remediação. Onde quer que exista um processo de trabalho baseado em ticket, há a possibilidade de o toil se acumular calmamente nas proximidades. Mesmo que não esteja explicitamente planejando automatizar um processo, ainda é possível realizar trabalhos de melhoria do processo, tais como simplificação e racionalização – os processos serão mais fáceis de automatizar mais tarde, e mais fáceis de gerenciar nesse meio tempo.
Interrupções de produção
As interrupções são uma classe geral de tarefas de limpeza sensíveis ao tempo que mantêm os sistemas em funcionamento. Por exemplo, pode ser necessário corrigir uma escassez aguda de algum recurso (disco, memória, I/O), liberando manualmente espaço em disco ou reiniciando aplicações que estão perdendo memória. Você pode estar preenchendo solicitações para substituir discos rígidos, “chutando” sistemas que não respondem ou ajustando manualmente a capacidade para atender às cargas atuais ou esperadas. Geralmente, as interrupções desviam a atenção de trabalhos mais importantes.
Condução de Lançamento
Em muitas organizações, as ferramentas de implantação conduzem automaticamente os lançamentos do desenvolvimento à produção. Mesmo com automação, cobertura completa de códigos, revisões de códigos e numerosas formas de testes automatizados, este processo nem sempre corre sem problemas. Dependendo das ferramentas e cadência de lançamento, solicitações de lançamento, rollbacks, patches de emergência e alterações de configuração repetitivas ou manuais, os lançamentos ainda podem gerar toil.
Migrações
Você pode encontrar-se frequentemente migrando de uma tecnologia para outra. Você executa esse trabalho manualmente ou com scripts limitados porque, esperançosamente, você só passará de X para Y uma vez. As migrações ocorrem de várias formas, mas alguns exemplos incluem alterações de armazenamentos de dados, fornecedores de nuvem, sistemas de controle de código-fonte, bibliotecas de aplicações, e ferramentas.
Se abordar uma migração em grande escala manualmente, a migração envolve muito provavelmente toil. Você pode estar inclinado a executar a migração manualmente porque é um esforço único. Embora possa até ser tentado a vê-la como “trabalho de projeto” em vez de “toil”, o trabalho de migração também pode satisfazer muitos dos critérios de toil. Tecnicamente, modificar a ferramenta de backup para uma base de dados para trabalhar com outra é desenvolvimento de software, mas este trabalho é basicamente apenas código de refactoring para substituir uma interface por outra. Este trabalho é repetitivo, e, em grande medida, o valor comercial das ferramentas de backup é o mesmo de antes.
Engenharia de Custos e Planejamento de Capacidade
Se você possui hardware ou usa um provedor de infraestrutura (nuvem), a engenharia de custos e o planejamento de capacidade geralmente envolvem algum toil associado. Por exemplo:
- Garantir uma linha de base econômica ou capacidade de expansão para necessidades futuras em recursos como computação, memória ou IOPS (operações de entrada/saída por segundo). Isto pode traduzir-se em ordens de compra, instâncias reservadas AWS , ou Cloud/Infraestrutura como uma negociação de contrato de serviço.
- Preparação para (e recuperação de) eventos críticos de alto tráfego, como o lançamento de um produto ou feriado.
- Revisão dos níveis/limites de serviço downstream e upstream.
- Otimização da carga de trabalho em relação a diferentes configurações de área ocupada. (Quer comprar uma caixa grande, ou quatro caixas mais pequenas?)
- Otimização de aplicações em relação às especificidades de faturamento de ofertas de serviços de nuvem proprietárias (DynamoDB para AWS ou Cloud Datastore para GCP).
- Ferramentas de refactoring para fazer melhor uso de recursos “spot” ou “preemptivos” mais baratos.
- Lidar com recursos com excesso de subscrição, seja upstream com seu provedor de infraestrutura ou com seus clientes downstream.
Resolução de Problemas para Arquiteturas Opacas
As arquiteturas de microsserviços distribuídos são agora comuns, e à medida que os sistemas se tornam mais distribuídos, surgem novos modos de falha. Uma organização pode não ter os recursos para criar rastreamento distribuído sofisticado, monitoramento de alta fidelidade ou dashboards detalhados. Mesmo que a empresa tenha estas ferramentas, elas podem não funcionar com todos os sistemas. A solução de problemas pode até exigir login em sistemas individuais e escrever consultas de análise de log ad hoc com ferramentas de script.
A resolução de problemas em si não é intrinsecamente má, mas você deve focar sua energia em novos modos de falha – não o mesmo tipo de falha toda semana causada pela arquitetura frágil do sistema. Com cada nova dependência crítica de upstream da disponibilidade P, a disponibilidade diminui em 1 – P devido à chance combinada de falha. Um serviço de quatro 9s que acrescenta nove dependências críticas de 9s é agora um serviço de três 9s.
Estratégias de Gestão de toil
Descobrimos que realizar o gerenciamento de toil é fundamental se você estiver operando um sistema de produção de qualquer escala. Uma vez identificado e quantificado o toil, é necessário um plano para a sua eliminação. Estes esforços podem levar semanas ou trimestres para serem realizados, por isso é importante ter uma estratégia abrangente e sólida.
Eliminar o toil em sua origem é a solução ideal, mas se isso não for possível, você deve lidar com o toil por outros meios. Antes de nos aprofundarmos nas especificidades de dois estudos de caso aprofundados, esta seção fornece algumas estratégias gerais a serem consideradas ao planejar um esforço de redução de toil. Como você observará nas duas histórias, as nuances do toil variam de equipe para equipe (e de empresa para empresa), mas, independentemente da especificidade, algumas táticas comuns são verdadeiras para organizações de qualquer tamanho ou sabor. Cada um dos seguintes padrões é ilustrado de forma concreta em pelo menos um dos estudos de caso subsequentes.
Identificar e medir o toil
Recomendamos que adote uma abordagem baseada em dados para identificar e comparar fontes de toil, tomar decisões objetivas de correção e quantificar o tempo economizado (retorno do investimento) por projetos de redução de toil. Se sua equipe está enfrentando sobrecarga de toil, trate a redução de toil como seu próprio projeto. As equipes de SRE do Google geralmente rastreiam o toil em bugs e classificam o toil de acordo com o custo para corrigi-lo e o tempo economizado ao fazê-lo. Veja a seção Medindo Toil para técnicas e orientação.
Engenheiro Toil Fora do Sistema
A estratégia ideal para lidar com o toil é eliminá-lo na fonte. Antes de investir esforços na gestão do toil gerada pelos seus sistemas e processos existentes, examine se pode reduzir ou eliminar esse toil alterando o sistema.
Uma equipe que executa um sistema em produção tem uma experiência inestimável com o funcionamento desse sistema. Eles conhecem as peculiaridades e partes tediosas que causam a maior quantidade de toil. Uma equipe de SRE deve aplicar este conhecimento trabalhando com equipes de desenvolvimento de produtos para desenvolver software operacionalmente amigável que não só seja menos trabalhoso, mas também mais escalável, seguro e resiliente.
Rejeitar o toil
Uma equipe com trabalho de toil deve tomar decisões orientadas por dados sobre a melhor forma de gastar o seu tempo e esforço de engenharia. Na nossa experiência, embora possa parecer contraproducente, rejeitar uma tarefa intensiva de toil deve ser a primeira opção a ser considerada. Para um determinado conjunto de toil, analise o custo de responder ao toil versus não fazê-lo. Outra tática é atrasar intencionalmente o toil para que as tarefas se acumulem para processamento em lote ou em paralelo. Trabalhar com toil em agregados maiores reduz as interrupções e ajuda-o a identificar padrões de toil, que você pode direcionar para eliminação.
Usar SLOs para reduzir o toil
Conforme discutido em Implementação de SLOs, os serviços devem ter um objetivo de nível de serviço (SLO) documentado. Um SLO bem definido permite que os engenheiros tomem decisões informadas. Por exemplo, você pode ignorar determinadas tarefas operacionais se isso não consumir ou exceder o orçamento de erros do serviço. Um SLO que se concentra na integridade geral do serviço, em vez de dispositivos individuais, é mais flexível e sustentável à medida que o serviço cresce. Consulte Implementação de SLOs para obter orientação sobre como escrever SLOs eficazes.
Comece com Interfaces com Suporte Humano
Se você tiver um problema de negócios particularmente complexo com muitos casos extremos ou tipos de solicitações, considere uma abordagem parcialmente automatizada como uma etapa provisória em direção à automação total. Nesta abordagem, o seu serviço recebe dados estruturados – normalmente através de um API definido – mas os engenheiros ainda podem lidar com algumas das operações resultantes. Mesmo que algum esforço manual permaneça, essa abordagem de “engenheiro por trás dos bastidores” permite que você avance incrementalmente em direção à automação total. Utilize o input do cliente para progredir em direção a uma maneira mais uniforme de coletar esses dados; ao diminuir as solicitações de formato livre, você pode se aproximar do tratamento de todas as solicitações de forma programática. Essa abordagem pode economizar com os clientes (que agora têm indicadores claros das informações de que você precisa) e evitar que você faça engenharia excessiva de uma solução de grande porte antes de mapear e entender completamente o domínio.
Fornecer métodos de autoatendimento
Uma vez definida a sua oferta de serviços através de uma interface datilografada (ver Comece com Interfaces com Suporte Humano), passe a fornecer métodos de autoatendimento aos usuários. Você pode fornecer um formulário web, binário ou script, API, ou até mesmo apenas documentação que informa aos usuários como emitir solicitações de pull para os arquivos de configuração do seu serviço. Por exemplo, em vez de pedir aos engenheiros que arquivem um ticket para fornecer uma nova máquina virtual para o seu trabalho de desenvolvimento, forneça a eles um formulário ou script da Web simples que acione o provisionamento. Permita que o script degrade suavemente para um ticket para solicitações especializadas ou se ocorrer uma falha. As interfaces com suporte humano são um bom começo na guerra contra o toil, mas os proprietários de serviços devem sempre procurar tornar suas ofertas de autoatendimento sempre que possível.
Obter apoio da Gerência e dos Colegas
A curto prazo, os projetos de redução de toil reduzem a equipe disponível para atender a solicitações de recursos, melhorias de desempenho e outras tarefas operacionais. Mas se a redução de toil for bem sucedida, a longo prazo a equipe será mais saudável e feliz, e terá mais tempo para melhorias de engenharia.
É importante que todos na organização concordem que a redução de toil é um objetivo que vale a pena. O apoio dos gestores é crucial na defesa do pessoal contra novas exigências. Use métricas objetivas sobre o toil para defender a resistência.
Promover a Redução do Toil como um Recurso
Para criar casos comerciais fortes para a redução do toil, procure oportunidades de associar a sua estratégia a outras características ou objetivos comerciais desejáveis. Se um objetivo complementar – por exemplo, segurança, escalabilidade, ou confiabilidade – for convincente para os seus clientes, eles estarão mais dispostos a abdicar dos seus atuais sistemas geradores de toil por outros novos e brilhantes que não são toil intenso. Então, reduzir o toil é apenas um bom efeito colateral de ajudar os usuários!
Comece pequeno e depois melhore
Não tente projetar o sistema perfeito que elimina todo o toil. Automatize primeiro alguns itens de alta prioridade, e depois melhore a sua solução utilizando o tempo ganho com a eliminação desse toil, aplicando as lições aprendidas ao longo do caminho. Escolha métricas claras tais como MTTR (Mean Time to Repair) para medir o seu sucesso.
Aumentar a uniformidade
Em escala, um ambiente de produção diversificado torna-se exponencialmente mais difícil de gerenciar. Dispositivos especiais requerem uma gestão contínua demorada e propensa a erros e uma resposta a incidentes. Pode utilizar a abordagem “animais de estimação versus gado” para acrescentar redundância e reforçar a consistência no seu ambiente. A escolha do que considerar gado depende das necessidades e da escala de uma organização. Pode ser razoável avaliar links de rede, switches, máquinas, racks de máquinas ou mesmo clusters inteiros como unidades intercambiáveis.
Mudar dispositivos para uma filosofia de gado pode ter um custo inicial elevado, mas pode reduzir o custo de manutenção, recuperação de desastres, e utilização de recursos a médio e longo prazo. Equipar vários dispositivos com a mesma interface implica que eles tenham configuração consistente, sejam intercambiáveis e exijam menos manutenção. Uma interface consistente (para desviar tráfego, restaurar tráfego, executar um encerramento, etc.) para uma variedade de dispositivos permite uma automatização mais flexível e expansível.
O Google alinha incentivos comerciais para encorajar as equipes de engenharia a unificarem-se no nosso conjunto de ferramentas e tecnologias internas em constante evolução. As equipes são livres para escolher suas próprias abordagens, mas precisam assumir o trabalho gerado por ferramentas sem suporte ou sistemas obsoletos.
Avalie o risco dentro da automação
A automação pode economizar inúmeras horas de trabalho humano, mas em circunstâncias erradas, também pode provocar interrupções. Em geral, o software defensivo é sempre uma boa ideia; quando a automação exerce poderes a nível administrativo, o software defensivo é crucial. Cada ação deve ser avaliada quanto à sua segurança antes da sua execução. Isto inclui alterações que podem reduzir a capacidade de serviço ou redundância. Quando se implementa a automação, recomendamos as seguintes práticas:
- Lide com o input do usuário defensivamente, mesmo que esse input esteja fluindo de sistemas upstream – isto é, ter a certeza de validar o input cuidadosamente no contexto.
- Inclua salvaguardas equivalentes aos tipos de alertas indiretos que um operador humano pode receber. As proteções podem ser tão simples como os tempos de espera de comando, ou podem ser verificações mais sofisticadas das métricas atuais do sistema ou do número de interrupções atuais. Por esse motivo, os sistemas de monitoramento, alerta e instrumentação devem ser consumíveis tanto por máquinas quanto por operadores humanos.
- Esteja ciente de que mesmo as operações de leitura, implementadas ingenuamente, podem aumentar a carga do dispositivo e desencadear interrupções. À medida que a automação aumenta, essas verificações de segurança podem eventualmente dominar a carga de trabalho.
- Minimize o impacto das interrupções causadas por verificações de segurança incompletas da automação. A automação deve ser padronizada para operadores humanos se ocorrer em uma condição insegura.
Automatizar a resposta ao toil
Uma vez identificado um toil como automatizável, vale a pena considerar a melhor forma de espelhar o fluxo de trabalho humano no software. Raramente se pretende transcrever literalmente um fluxo de trabalho humano num fluxo de trabalho de uma máquina. Observe também que a automação não deve eliminar a compreensão humana do que está acontecendo de errado.
Uma vez que o seu processo esteja completamente documentado, tente dividir o trabalho manual em componentes que podem ser implementados separadamente e usados para criar uma biblioteca de software composta que outros projetos de automação possam reutilizar posteriormente. Como o próximo estudo de caso de reparo de datacenter ilustra, a automação geralmente oferece a oportunidade de reavaliar e simplificar os fluxos de trabalho humanos.
Utilizar ferramentas de código aberto e de terceiros
Por vezes, não é necessário fazer todo o trabalho para se reduzir o toil. Muitos esforços como as migrações pontuais podem não justificar a construção de ferramentas próprias, mas provavelmente não é a primeira organização a trilhar este caminho. Procure oportunidades de utilizar ou ampliar bibliotecas de terceiros ou de código aberto para reduzir os custos de desenvolvimento, ou pelo menos para o ajudar na transição para a automatização parcial.
Use o Feedback para melhorar
É importante procurar ativamente o feedback de outras pessoas que interagem com as suas ferramentas, fluxos de trabalho e automação. Os seus usuários farão diferentes suposições sobre as suas ferramentas, dependendo da sua compreensão dos sistemas subjacentes. Quanto menos familiarizados os seus usuários estiverem com estes sistemas, mais importante é procurar ativamente o feedback dos usuários. Aproveite pesquisas, estudos de experiência do usuário (UX) e outros mecanismos para entender como suas ferramentas são usadas e integre esse feedback para produzir uma automação mais eficaz no futuro.
A contribuição humana é apenas uma dimensão do feedback que você deve considerar. Meça também a eficácia das tarefas automatizadas de acordo com métricas como latência, taxa de erro, taxa de retrabalho e tempo humano poupado (em todos os grupos envolvidos no processo). Idealmente, encontre medidas de alto nível que possa comparar antes e depois de qualquer automatização ou esforços de redução de toil.
Sistemas obsoletos
A maioria dos engenheiros com responsabilidades semelhantes às do SRE encontraram pelo menos um sistema obsoleto no seu trabalho. Esses sistemas mais antigos geralmente apresentam problemas com relação à experiência do usuário, segurança, confiabilidade ou escalabilidade. Tendem a funcionar como uma caixa negra mágica na medida em que “geralmente funcionam”, mas poucas pessoas compreendem como funcionam. São assustadores e caros de modificar, e mantê-los em funcionamento requer muitas vezes um bom ritual operacional.
A jornada para longe de um sistema obsoleto geralmente segue esse caminho:
- Prevenção: Há muitos motivos para não enfrentar esse problema de frente: você pode não ter os recursos para substituir este sistema. Você julga o custo e o risco para o seu negócio como não valendo o custo de uma substituição. Pode não haver soluções substancialmente melhores disponíveis comercialmente. Evitar é escolher efetivamente aceitar a dívida técnica e se afastar dos princípios de SRE em direção à administração do sistema.
- Encapsulamento/aumento: você pode trazer SREs a bordo para criar um shell de APIs abstratas, automação, gerenciamento de configuração, monitoramento e teste em torno desses sistemas obsoletos que descarregarão o trabalho das SAs. O sistema obsoleto permanece frágil para mudanças, mas agora você pode pelo menos identificar de forma confiável o mau comportamento e reverter quando apropriado. Esta tática ainda é evitada, mas é um pouco como refinanciar dívidas técnicas com juros altos em dívidas técnicas com juros baixos. É normalmente uma medida provisória para se preparar para uma substituição incremental.
- Substituição/refatoração: A substituição de um sistema antigo pode exigir uma grande dose de determinação, paciência, comunicação, e documentação. É melhor realizado de forma incremental. Uma abordagem é definir uma interface comum que fique na frente e abstraia um sistema obsoleto . Essa estratégia ajuda a migrar usuários de forma lenta e segura para alternativas usando técnicas de engenharia de lançamento, como canarying ou implantações azul-verde. Muitas vezes, a “especificação” de um sistema antigo é realmente definida apenas pelo seu uso histórico, então é útil construir conjuntos de dados de tamanho de produção de entradas e saídas históricas esperadas para criar confiança de que novos sistemas não estão divergindo do comportamento esperado (ou estão divergindo de uma maneira esperada).
- Aposentadoria/propriedade de custódia: Eventualmente, a maioria dos clientes ou funcionalidade é migrada para uma ou mais alternativas. Para alinhar os incentivos comerciais, os estrategistas que não tenham migrado podem assumir a custódia dos remanescentes do sistema obsoleto.
Estudos de casos
Os seguintes estudos de caso ilustram as estratégias de redução do toil que acabam de ser discutidas. Cada história descreve uma área importante da infra-estrutura do Google que atingiu um ponto em que já não podia escalar sublinearmente com o esforço humano; ao longo do tempo, um número crescente de horas de engenharia resultou em menores retornos sobre esse investimento. Muito desse esforço será agora reconhecido como toil. Para cada estudo de caso, detalhamos como os engenheiros identificaram, avaliaram e mitigaram esse toil. Também discutimos os resultados e as lições que aprendemos ao longo do caminho.
No primeiro estudo de caso, a rede do datacenter do Google tinha um problema de dimensionamento: tínhamos um grande número de componentes e links projetados pelo Google para monitorar, mitigar e reparar. Precisávamos de uma estratégia para minimizar a natureza difícil deste toil para os técnicos de datacenter.
O segundo estudo de caso se concentra em uma equipe executando seu próprio hardware especializado “outlier” para dar suporte a processos de negócios de toil intenso que se tornaram profundamente arraigados no Google. Este estudo de caso ilustra os benefícios da reavaliação e substituição de processos de negócio operacionalmente dispendiosos. Demonstra que com um pouco de persistência e perseverança, é possível migrar para alternativas mesmo quando constrangido pela inércia institucional de uma grande organização.
Juntos, esses estudos de caso fornecem um exemplo concreto de cada estratégia de redução de toil abordada anteriormente. Cada estudo de caso começa com uma lista de estratégias relevantes para a redução do toil.
Estudo de Caso 1: Redução do toil no Datacenter com Automação
Nota
Estratégias de redução do toil destacadas no Estudo de Caso 1:
- Engenheiro trabalha fora do sistema
- Comece pequeno e depois melhore
- Aumente a uniformidade
- Utilize SLOs para reduzir o toil
- Avalie o risco dentro da automação
- Use o feedback para melhorar
- Automatize a resposta ao toil
Background
Este estudo de caso ocorre nos datacenters do Google. Semelhante a todos os datacenters, as máquinas do Google são conectadas a switches, que são conectados a roteadores. O tráfego entra e sai destes routers através de links que por sua vez se ligam a outros routers na Internet. À medida que os requisitos do Google para lidar com o tráfego da Internet aumentavam, o número de máquinas necessárias para servir esse tráfego aumentou dramaticamente. Nossos datacenters cresceram em alcance e complexidade à medida que descobrimos como atender a uma grande quantidade de tráfego de forma eficiente e econômica. Esse crescimento mudou a natureza dos reparos manuais do datacenter de ocasionais e interessantes para frequentes e rotineiros — dois sinais de toil.
Quando o Google começou a executar seus próprios datacenters, a topologia de rede de cada datacenter apresentava um pequeno número de dispositivos de rede que gerenciavam o tráfego para um grande número de máquinas. Uma única falha de dispositivo de rede poderia ter um impacto significativo no desempenho da rede, mas uma equipe relativamente pequena de engenheiros poderia lidar com o pequeno número de dispositivos. Nesta fase inicial, os engenheiros depuravam os problemas e deslocavam manualmente o tráfego para longe dos componentes avariados.
Nosso datacenter de última geração tinha muito mais máquinas e introduziu uma rede definida por software (SDN) com uma topologia Clos dobrada, o que aumentou consideravelmente o número de switches. A figura 6-2 mostra a complexidade do fluxo de tráfego para uma pequena rede de switch Clos de datacenter. Este número proporcionalmente maior de dispositivos significava que um maior número de componentes poderia agora falhar. Embora cada falha individual tivesse menos impacto no desempenho da rede do que antes, o enorme volume de problemas começou a sobrecarregar a equipe de engenharia.
Além de introduzir uma carga pesada de novos problemas para depurar, o layout complexo era confuso para os técnicos: quais links exatos precisavam ser verificados? Qual o line card que precisavam substituir? O que era um switch de Estágio 2, versus um switch de Estágio 1 ou switch de Estágio 3? Desligar um switch criaria problemas para os usuários?
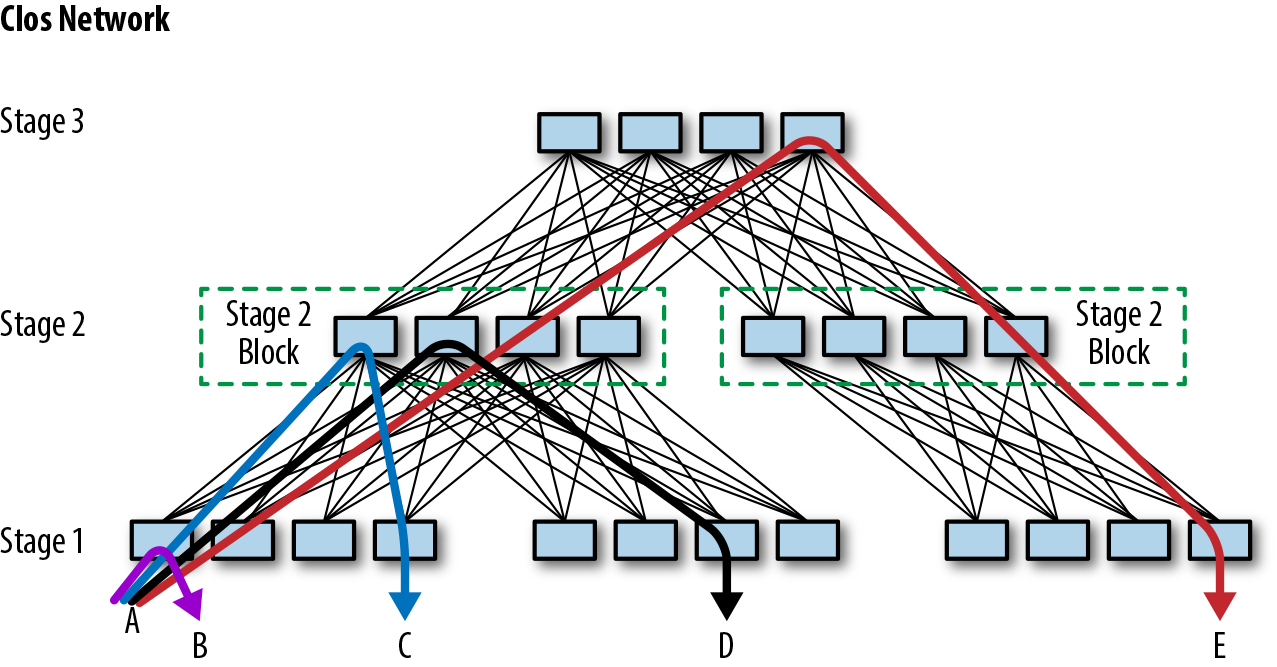
Figura 6-2. Uma pequena rede Clos, que suporta 480 máquinas conectadas abaixo do Estágio 1
A reparação de line card de datacenter com falha era uma lista de pendências de trabalho crescente e óbvia, portanto, direcionamos essa tarefa como nosso primeiro estágio de criação de automação de reparo de rede de datacenter. Este estudo de caso descreve como introduzimos a automação de reparo para nossa primeira geração de line card (denominada Saturno). Discutimos então as melhorias que introduzimos com a próxima geração de line card para materiais Júpiter.
Como se mostra na Figura 6-3, antes do projeto de automação, cada correção no fluxo de trabalho de reparo do line card do datacenter exigia que um engenheiro fizesse o seguinte:
- Verificar se era seguro mover o tráfego do switch afetado.
- Deslocar o tráfego para longe do dispositivo avariado (uma operação de “drenagem”).
- Executar uma reinicialização ou reparo (tal como a substituição de um line card).
- Deslocar o tráfego de volta para o dispositivo (uma operação de “não drenagem”).
Este trabalho invariável e repetitivo de drenar, não drenar e reparar dispositivos é um exemplo clássico de toil. A natureza repetitiva do trabalho introduziu problemas próprios – por exemplo, os engenheiros podem realizar várias tarefas trabalhando em um line card enquanto também depuram problemas mais desafiadores. Como resultado, o engenheiro distraído pode acidentalmente introduzir um switch não configurado de volta à rede.
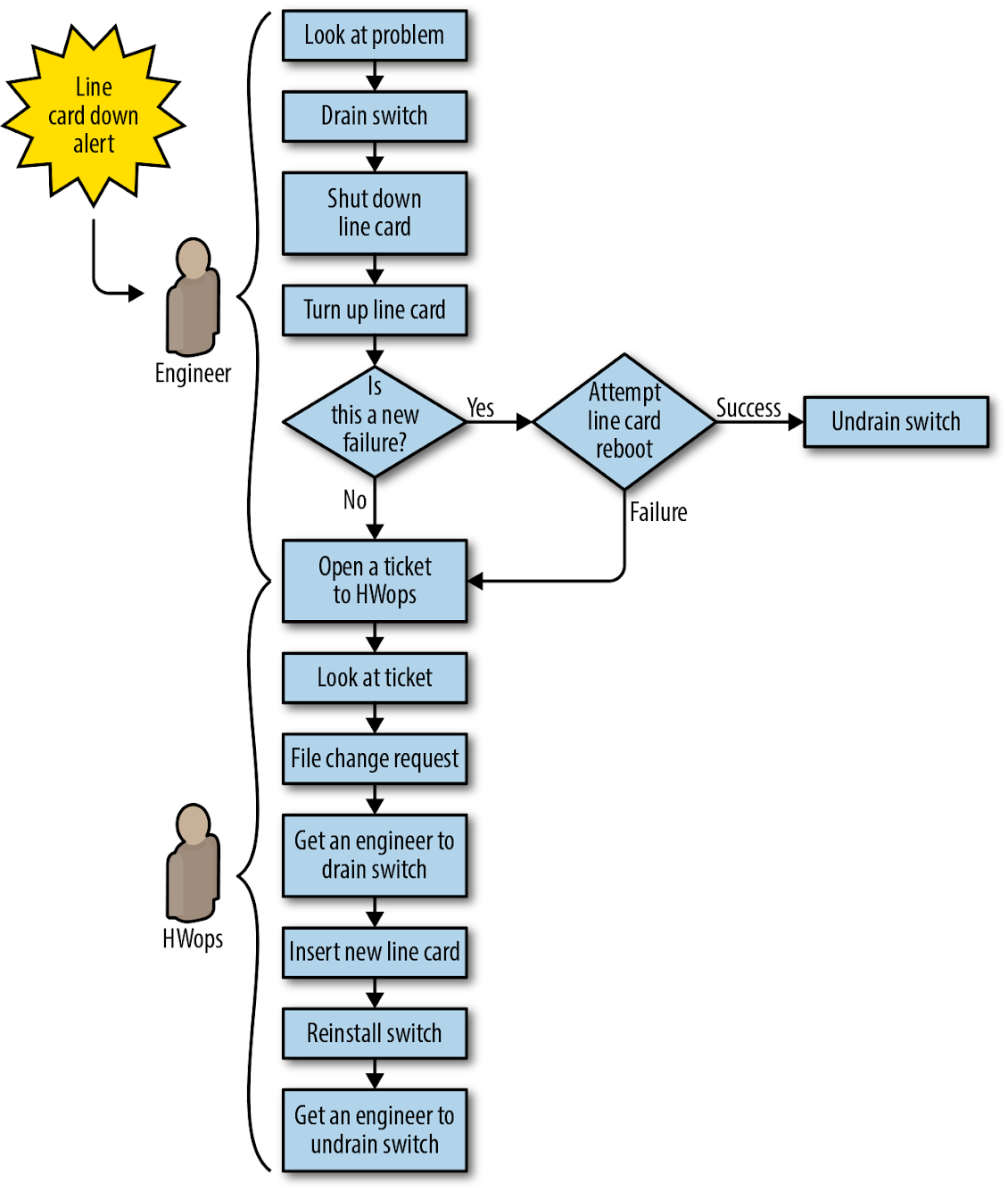
Figura 6-3. Fluxo de trabalho de reparo de line card do datacenter (Saturno) antes da automação: todas as etapas exigem trabalho manual
Declaração de problemas
O espaço do problema de reparos do datacenter tinha as seguintes dimensões:
- Não conseguimos aumentar a equipe com rapidez suficiente para acompanhar o volume de falhas e não conseguimos corrigir os problemas com rapidez suficiente para evitar o impacto negativo na malha.
- A execução das mesmas etapas repetida e frequentemente introduziu muitos erros humanos.
- Nem todas as falhas de line card tiveram o mesmo impacto. Não tínhamos como priorizar falhas mais graves.
- Algumas falhas foram transitórias. Queríamos a opção de reiniciar o line card ou reinstalar o switch como primeira tentativa de reparo. Idealmente, poderíamos capturar programaticamente o problema se ele acontecesse novamente e sinalizar o dispositivo para substituição.
- A nova topologia exigia que avaliássemos manualmente o risco de isolar a capacidade antes que pudéssemos agir. Cada avaliação de risco manual era uma oportunidade para erro humano que poderia resultar em uma interrupção. Engenheiros e técnicos não tinham uma boa maneira de avaliar quantos dispositivos e links seriam afetados pelo reparo planejado.
O que decidimos fazer
Em vez de atribuir cada problema a um engenheiro para avaliação de risco, drenagem, não drenagem e validação, decidimos criar uma estrutura para automação que, quando associada a um técnico no local, quando apropriado, poderia dar suporte a essas operações de forma programática.
Primeiro Esforço de Projeto: Reparação de Line-Card do Saturno
O nosso objetivo de alto nível era construir um sistema que respondesse aos problemas detectados nos dispositivos de rede, em vez de depender de um engenheiro para fazer a triagem e corrigir esses problemas. Em vez de enviar um “line card inativo” de alerta a um engenheiro, escrevemos o software para solicitar uma drenagem (para remover tráfego) e criar um caso para um técnico. O novo sistema tinha algumas características notáveis:
- Aproveitamos as ferramentas existentes sempre que possível. Como se mostra na Figura 6-3, o nosso alerta já podia detectar problemas nos line cards de malha; reaproveitamos esse alerta para acionar um reparo automatizado. O novo fluxo de trabalho também reaproveitou o nosso sistema de emissão de tickets para dar suporte aos reparos de rede.
- Incorporamos a avaliação automática de riscos para evitar o isolamento acidental de dispositivos durante uma drenagem e para acionar mecanismos de segurança sempre que necessário. Isto eliminou uma enorme fonte de erros humanos.
- Adotamos uma política de greve que foi controlada por software: a primeira falha (ou greve) apenas reinicializava o card e reinstalava o software. Uma segunda falha desencadeou a substituição do card e a devolução total ao fornecedor.
Implementação
O novo fluxo de trabalho automatizado (mostrado na Figura 6-4) procedeu da seguinte forma:
- O line card problemático é detectado e um sintoma é adicionado a um componente específico no banco de dados.
- O serviço de reparação detecta o problema e permite reparações no switch. O serviço efetua uma avaliação de risco para confirmar que nenhuma capacidade será isolada pela operação, e depois:
- Drena o tráfego de todo o switch.
- Desliga o line card.
- Se esta for uma primeira falha, reinicializa o card e drena o switch, restaurando o serviço para o switch. Neste ponto, o fluxo de trabalho está concluído. d. Se esta for a segunda falha, o fluxo de trabalho prossegue para a etapa 3.
- O gestor do fluxo de trabalho detecta o novo caso e envia-o para um pool de casos de reparação para que um técnico o reclame.
- O técnico reclama o caso, vê um “stop” vermelho na interface do usuário (indicando que o switch precisa ser drenado antes que os reparos sejam iniciados) e executa o reparo em três etapas: a. Inicia a drenagem do chassi por meio de um botão “Prep component” na interface do usuário do técnico.
- Espera que o “stop” vermelho desapareça, indicando que a drenagem está completa e que o caso é acionável.
- Substitui o card e encerra o caso.
- O sistema de reparação automatizado faz subir novamente o line card. Após uma pausa para dar tempo ao card para inicializar, o gerenciador de fluxo de trabalho aciona uma operação para restaurar o tráfego para o switch e encerrar o caso de reparo.
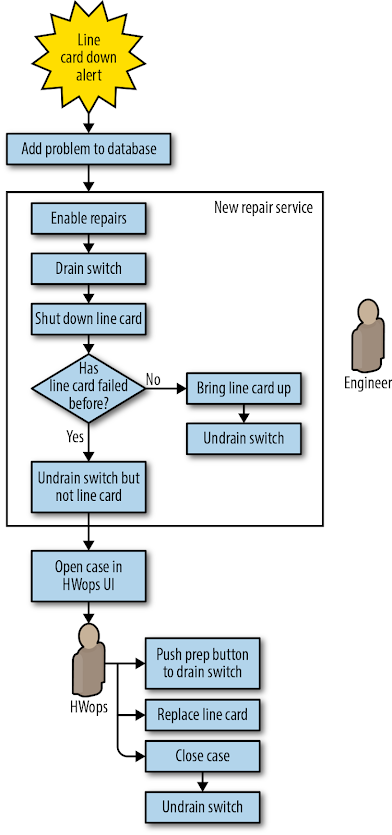
Figura 6-4. Fluxo de trabalho de reparo do line-card Saturno com automação: trabalho manual necessário apenas para apertar um botão e substituir o line-card
O novo sistema liberou a equipe de engenharia de um grande volume de trabalho toil, dando-lhes mais tempo para buscar projetos produtivos em outros lugares: trabalhando em Júpiter, a topologia Clos de próxima geração.
Segundo Esforço de Projeto: Reparo do Line-Card Saturno Versus Reparo do Line-Card Jupiter
Os requisitos de capacidade no datacenter continuaram a dobrar quase a cada 12 meses. Como resultado, nossa malha de datacenter de última geração, Jupiter, era mais de seis vezes maior do que qualquer malha anterior do Google. O volume de problemas era também seis vezes maior. O Jupiter apresentou desafios de dimensionamento para automação de reparos porque milhares de links de fibra e centenas de line cards poderiam falhar em cada camada. Felizmente, o aumento dos potenciais pontos de falha foi acompanhado por uma redundância muito maior, o que significava que podíamos implementar uma automação mais ambiciosa. Como mostrado na Figura 6-5, preservamos parte do fluxo de trabalho geral de Saturno e acrescentamos algumas modificações importantes:
- Depois que um ciclo de drenagem/reinicialização automatizado determinou que queríamos substituir o hardware, enviamos o hardware para um técnico. Contudo, em vez de exigirmos a um técnico que iniciasse a drenagem com o botão “Pressione o botão de preparação para drenar o interruptor”, drenamos automaticamente todo o interruptor quando este falhou.
- Adicionamos automação para instalar e empurrar a configuração que se inicia após a substituição do componente.
- Habilitamos a automação para verificar se o reparo foi bem-sucedido antes de drenar o switch.
- Concentramos a atenção no switch do interruptor sem envolver um técnico, a menos que seja absolutamente necessário.
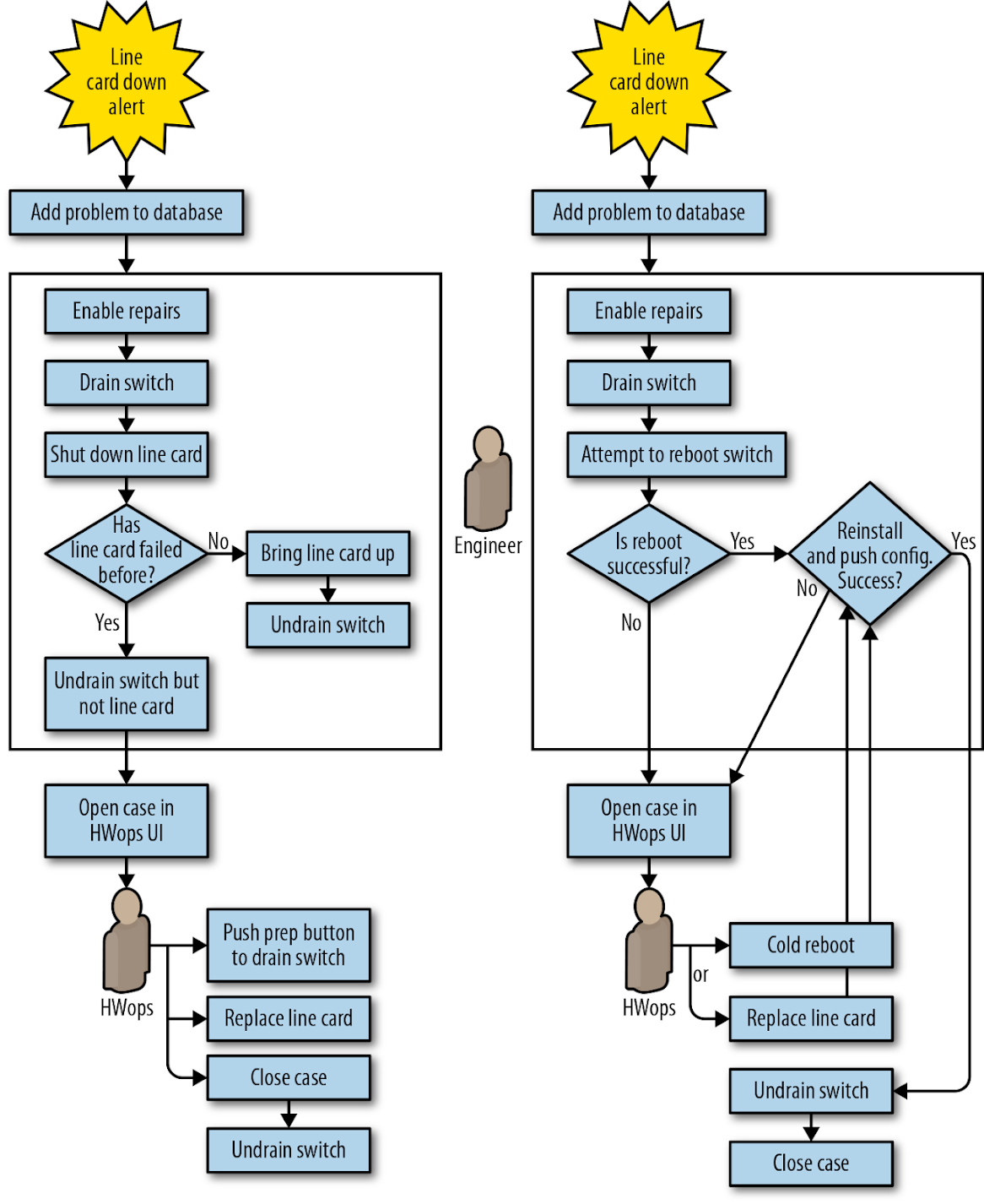
Figura 6-5. Automação de line card de Saturno (esquerda) versus automação de Júpiter (direita)
Implementação
Adotamos um fluxo de trabalho simples e uniforme para cada problema de line card em switches Jupiter: declarar o switch desativado, drená-lo e iniciar um reparo.
A automação realizou o seguinte:
- O problema é detectado e um sintoma é acrescentado à base de dados.
- O serviço de reparo detecta o problema e permite reparos no switch: drenar todo o switch, e adicionar uma razão de drenagem. a. Se esta for a segunda falha no prazo de seis meses, prossiga para o passo 4.
- Caso contrário, prossiga para o passo 3.
- Tente (através de dois métodos distintos) desligar e ligar o switch. a. Se o ciclo de energia for bem sucedido, execute a verificação automatizada e instale e configure o switch. Remova a razão da reparação, limpe o problema do banco de dados e anule a drenagem do switch.
- Se as operações de verificação de sanidade anteriores falharem, enviar o caso a um técnico com uma mensagem de instrução.
- Se esta foi a segunda falha, envie o caso diretamente ao técnico, solicitando novo hardware. Após a mudança de hardware ocorrer, execute a verificação automática e depois instale e configure o switch. Remova o motivo do reparo, limpe o problema do banco de dados e esvazie o switch.
Esta nova gestão do fluxo de trabalho foi uma reescrita completa do sistema de reparação anterior. Mais uma vez, aproveitamos as ferramentas existentes quando possível:
- As operações para configurar novos switches (instalar e verificar) foram as mesmas operações necessárias para verificar se um switch foi substituído.
- A implementação rápida de novas malhas exigia a capacidade de BERT e auditoria de cabos de forma programática. Antes de restaurar o tráfego, reutilizamos esse recurso para executar automaticamente padrões de teste em links que sofreram reparos. Esses testes melhoraram ainda mais o desempenho ao identificar links defeituosos.
A melhoria lógica seguinte foi automatizar a mitigação e o reparo de erros de memória nos line cards do switch Jupiter. Como mostrado na Figura 6-6, antes da automação, esse fluxo de trabalho dependia muito de um engenheiro para determinar se a falha estava relacionada a hardware ou software e, em seguida, drenar e reinicializar o switch ou providenciar um reparo, se apropriado.
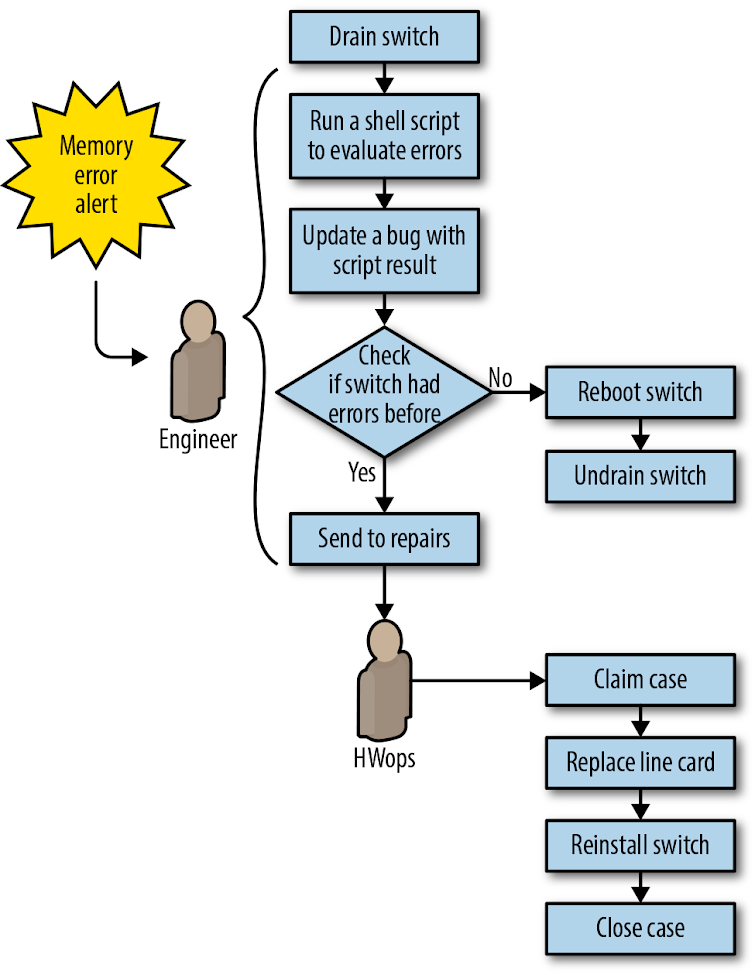
Figura 6-6. Fluxo de trabalho de reparação de erros de memória Júpiter antes da automação
A nossa automatização simplificou o fluxo de trabalho de reparação ao deixar de tentar resolver os erros de memória (ver Às vezes, a automação imperfeita é boa o suficiente para saber por que isso fazia sentido). Em vez disso, tratamos os erros de memória da mesma forma que tratamos os line cards com falha. Para estender a automação aos erros de memória, simplesmente tivemos que adicionar outro sintoma a um arquivo de configuração para que ele atuasse no novo tipo de problema. A figura 6-7 mostra o fluxo de trabalho automatizado para erros de memória.
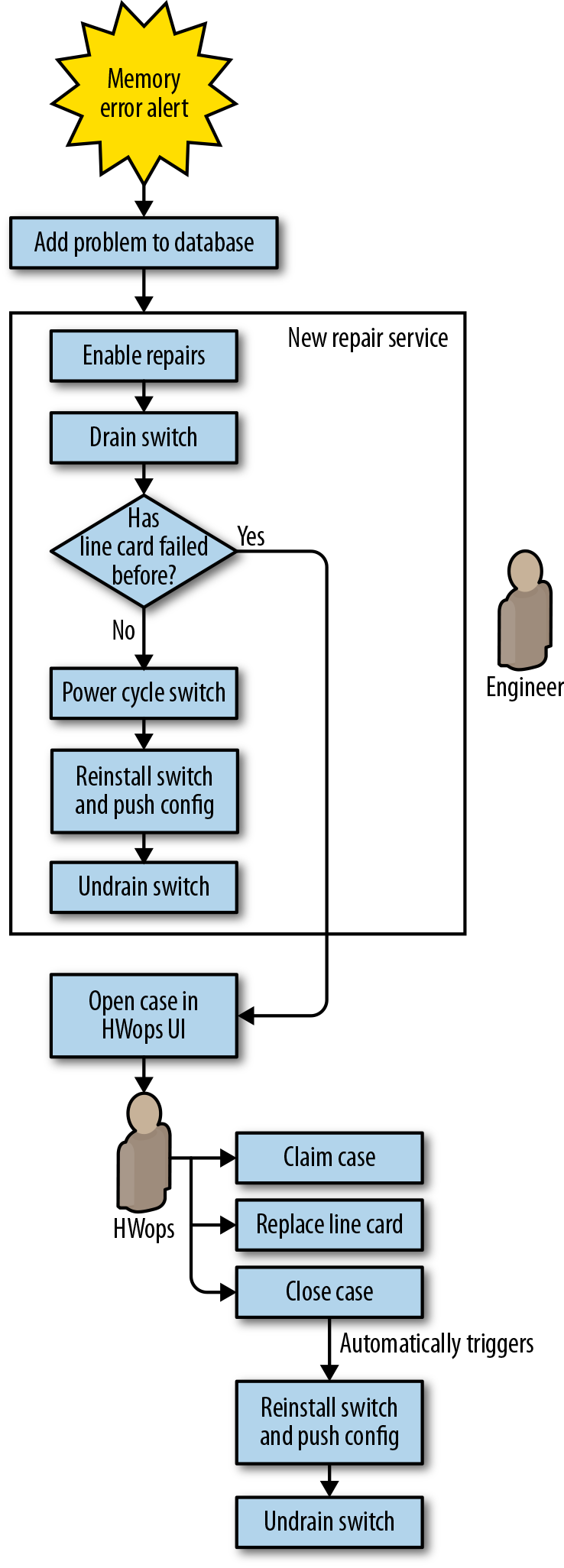
Figura 6-7. Fluxo de trabalho de reparação de erros de memória Júpiter com automação
Lições aprendidas
Durante os vários anos que trabalhamos para automatizar a reparação da rede, aprendemos muitas lições gerais sobre como reduzir eficazmente o toil.
As UIs não devem introduzir sobrecarga ou complexidade
Para line cards baseados em Saturno, a substituição de um line card requer a drenagem de todo o switch. A drenagem de todo o switch no início do processo de reparação significou a perda da capacidade de trabalho de todos os line cards no switch enquanto se aguardava a substituição de peças e de um técnico. Introduzimos um botão na IU chamado “Componente de preparação” que permitiu a um técnico drenar o tráfego de todo o switch mesmo antes de estarem prontos para substituir o card, eliminando assim o tempo de inatividade desnecessário para o restante do switch (ver “Pressione o botão de preparação para drenar o switch” na Figura 6-5).
Esse aspecto da interface do usuário e do fluxo de trabalho de reparo apresentou vários problemas inesperados:
- Depois de pressionar o botão, o técnico não obteve feedback sobre o progresso da drenagem, mas simplesmente teve que esperar a permissão para prosseguir.
- O botão não sincronizava de forma confiável com o estado real do switch. Como resultado, às vezes um switch drenado não era reparado ou um técnico interrompia o tráfego agindo sobre um switch não drenado.
- Os componentes que não tinham automação habilitada retornavam uma mensagem genérica de “engenharia de contato” quando surgia um problema. Os técnicos mais novos não sabiam a melhor maneira de chegar a alguém que pudesse ajudar. Os engenheiros que foram contatados nem sempre estavam imediatamente disponíveis.
Em resposta a relatórios de usuários e problemas com regressões causados pela complexidade do recurso, projetamos fluxos de trabalho futuros para garantir que o switch estivesse seguro e pronto para reparo antes que o técnico chegasse ao switch.
Não confie na perícia humana
Confiamos demais em técnicos de datacenter experientes para identificar erros em nosso sistema (por exemplo, quando o software indicava que era seguro prosseguir com os reparos, mas o switch não era drenado). Esses técnicos também tiveram que executar várias tarefas manualmente, sem serem solicitados pela automação.
A experiência é difícil de replicar. Em um episódio particularmente de alto impacto, um técnico decidiu agilizar a experiência “pressione o botão e aguarde os resultados”, iniciando drenagens simultâneas em cada line card aguardando reparos no datacenter, resultando em congestionamento de rede e perda de pacotes visível ao usuário. Nosso software não previu e impediu essa ação porque não testamos a automação com novos técnicos.
Projete componentes reutilizáveis
Sempre que possível, evite projetos monolíticos. Crie fluxos de trabalho de automação complexos a partir de componentes separáveis, cada um dos quais lida com uma tarefa distinta e bem definida. Poderíamos facilmente reutilizar ou adaptar os principais componentes de nossa automação inicial do Jupiter para cada geração sucessiva de malha, e era mais fácil adicionar novos recursos quando podíamos construir uma automação que já existia. Variações sucessivas em malhas do tipo Júpiter podem alavancar o trabalho feito em iterações anteriores.
Não pense demais no problema
Analisamos em excesso o problema de erro de memória para line cards Jupiter. Em nossas tentativas de diagnóstico preciso, procuramos distinguir erros de software (corrigíveis por reinicializações) de erros de hardware (que exigiam a substituição do card) e também identificar erros que impactavam o tráfego versus erros que não impactavam. Passamos quase três anos (2012-2015) coletando dados sobre mais de 650 problemas de erro de memória discreta antes de perceber que esse exercício provavelmente era um exagero, ou pelo menos não deveria bloquear nosso projeto de automação de reparo.
Uma vez que decidimos agir sobre qualquer erro detectado, foi fácil usar nossa automação de reparo existente para implementar uma política simples de drenagem, reinicialização e reinstalação de switches em resposta a erros de memória. Se o problema ocorresse novamente, concluímos que a falha provavelmente era baseada em hardware e solicitamos a substituição do componente. Reunimos dados ao longo de um trimestre e descobrimos que a maioria dos erros era transitório — a maioria dos switches se recuperava após ser reinicializado e reinstalado. Não precisávamos de dados adicionais para realizar o reparo, portanto, o atraso de três anos na implementação da automação foi desnecessário.
Às vezes, a automação imperfeita é boa o suficiente
Embora a capacidade de verificar links com o BERT antes de drená-los fosse útil, as ferramentas do BERT não suportavam links de gerenciamento de rede. Adicionamos esses links à automação de reparo de link existente com uma verificação que permitia que eles ignorassem a verificação. Ficamos à vontade para ignorar a verificação porque os links não carregavam o tráfego do cliente e poderíamos adicionar essa funcionalidade mais tarde se a verificação fosse importante.
A automatização da reparação não é disparar e esquecer
A automação pode ter uma vida útil muito longa, portanto, planeje a continuidade do projeto à medida que as pessoas saem e se juntam à equipe. Novos engenheiros devem ser treinados em sistemas antigos para que possam corrigir bugs. Devido à escassez de peças para as malhas de Júpiter, as malhas baseadas em Saturno viveram muito depois da data de fim de vida originalmente prevista, exigindo que introduzíssemos algumas melhorias bem tarde na vida útil geral de Saturno.
Uma vez adotada, a automação pode ficar enraizada por muito tempo, com consequências positivas e negativas. Quando possível, projete sua automação para evoluir de maneira flexível. Confiar na automação inflexível torna os sistemas frágeis para mudar. A automação baseada em políticas pode ajudar separando claramente a intenção de um mecanismo de implementação genérico, permitindo que a automação evolua de forma mais transparente.
Construir em profundidade a avaliação e defesa do risco
Depois de construir novas ferramentas para Júpiter que determinaram o risco de uma operação de drenagem antes de executá-la, a complexidade que encontramos nos levou a introduzir uma verificação secundária de defesa em profundidade. A segunda verificação estabeleceu um limite superior para o número de links impactados e outro limite para dispositivos impactados. Se excedermos um dos limites, um bug de rastreamento para solicitar uma investigação mais aprofundada será aberto automaticamente. Ajustamos estes limites ao longo do tempo para reduzir os falsos positivos. Embora considerássemos inicialmente esta medida temporária até a avaliação primária do risco estabilizar, a verificação secundária provou ser útil para identificar taxas de reparação atípicas devido a falhas de energia e bugs de software (por exemplo, ver “Capítulo 7” em Engenharia da Confiabilidade do Site).
Obtenha um orçamento de falhas e suporte ao gerente
A automação de reparo às vezes pode falhar, especialmente quando introduzida pela primeira vez. O apoio da gestão é crucial para preservar o projeto e capacitar a equipe para perseverar. Recomendamos estabelecer um orçamento de erros para automação anti-toil. Você também deve explicar às partes interessadas externas que a automação é essencial, apesar do risco de falhas, e que permite a melhoria contínua em confiabilidade e eficiência.
Pense holisticamente
Em última análise, a complexidade dos cenários a serem automatizados é o verdadeiro obstáculo a ultrapassar. Reexamine o sistema antes de trabalhar para automatizá-lo – você pode simplificar o sistema ou o fluxo de trabalho primeiro?
Preste atenção a todos os aspectos do fluxo de trabalho que você está automatizando, não apenas aos aspectos que criam toil para você pessoalmente. Realize testes com as pessoas diretamente envolvidas no trabalho e busque ativamente seu feedback e assistência. Se cometerem erros, descubra como a sua IU poderia ser mais clara, ou que verificações de segurança adicionais necessita. Certifique-se de que sua automação não crie novos toil – por exemplo, abrindo tickets desnecessários que precisam de atenção humana. Criar problemas para outras equipes aumentará a resistência a futuros empreendimentos de automação.
Estudo de caso 2: Desativação de diretórios pessoais com suporte de arquivo
Nota
Estratégias de redução de toil destacadas no Estudo de Caso 2:
- Considere a desativação de sistemas obsoletos
- Promova a redução do toil como um recurso
- Obtenha apoio da gerência e dos colegas
- Rejeite o toil
- Comece com interfaces apoiadas por humanos
- Forneça métodos de autoatendimento
- Comece pequeno e depois melhore
- Use o feedback para melhorar
Background
Nos primeiros dias do Google, a equipe SRE Corp Data Storage (CDS) fornecia diretórios pessoais para todos os Googlers. Semelhante aos perfis de roaming do Active Directory, comuns na TI corporativa, os Googlers podem usar os mesmos diretórios pessoais em estações de trabalho e plataformas. A equipe do CDS também ofereceu “Team Shares” para colaboração entre equipes em um espaço de armazenamento compartilhado. Fornecemos diretórios pessoais e Team Shares por meio de uma frota de Netapp Storage Appliances sobre NFS/CIFS (ou “arquivadores”). Esse armazenamento era operacionalmente caro, mas oferecia um serviço muito necessário aos Googlers.
Declaração de problemas
Com o passar dos anos, estas soluções de arquivo foram na sua maioria descontinuadas por outras, melhores, soluções de armazenamento: os nossos sistemas de controle de versões (Piper/Git-on-borg), Google Drive, Google Team Drive, Google Cloud Storage, e um sistema de arquivo interno, compartilhado e distribuído globalmente chamado x20. Estas alternativas eram superiores por uma série de razões:
- Os protocolos NFS/CIFS nunca foram projetados para operar em uma WAN, portanto, a experiência do usuário se degrada rapidamente, mesmo com algumas dezenas de milissegundos de latência. Isso criou problemas para trabalhadores remotos ou equipes distribuídas globalmente, pois os dados podiam residir apenas em um local.
- Em comparação com as alternativas, estes aparelhos eram dispendiosos para funcionar e escalar.
- Seria necessário um trabalho significativo para tornar os protocolos NFS/CIFS compatíveis com o modelo de segurança de rede Beyond Corp do Google.
Mais relevantes para este capítulo, os diretórios pessoais e os Team Shares eram toil intensivo. Muitas facetas do provisionamento de armazenamento eram orientadas por tickets. Embora estes fluxos de trabalho fossem, muitas vezes, parcialmente roteirizados, representavam uma quantidade considerável de toil da equipe CDS. Passamos muito tempo criando e configurando compartilhamentos, modificando acessos, solucionando problemas de usuários finais e realizando ativação e desativação para gerenciar a capacidade. O CDS também gerenciou os processos de provisionamento, racking e cabeamento desse hardware especializado, além de sua configuração, atualizações e backups. Devido aos requisitos de latência, muitas vezes precisávamos implantar em escritórios remotos em vez de datacenters do Google, o que às vezes exigia que um membro da equipe percorresse uma distância substancial para gerenciar uma implantação.
O que decidimos fazer
Primeiro, coletamos dados: o CDS criou uma ferramenta chamada Moonwalk para analisar como os funcionários usavam nossos serviços. Coletamos métricas tradicionais de inteligência de negócios, como usuários ativos diários (DAU) e usuários ativos mensais (MAU), e fizemos perguntas como: “Quais famílias de empregos realmente usam seus diretórios pessoais?” e “Dos usuários que usam arquivadores todos os dias, que tipo de arquivos eles mais acessam? O Moonwalk, combinado com pesquisas de usuários, validou que as necessidades de negócios atualmente atendidas pelos arquivadores poderiam ser melhor atendidas por soluções alternativas que tivessem custos e despesas operacionais menores. Outro motivo comercial convincente nos levou a abandonar os arquivadores: se pudéssemos migrar a maioria de nossos casos de uso de arquivadores para o G Suite/GCP, poderíamos usar as lições aprendidas para melhorar esses produtos, permitindo assim que outras grandes empresas migrem para o G Suite/GCP.
Nenhuma alternativa poderia atender a todos os casos de uso de arquivadores atuais. No entanto, dividindo o problema em componentes endereçáveis menores, descobrimos que, em conjunto, um punhado de alternativas poderia cobrir todos os nossos casos de uso. As soluções alternativas eram mais especializadas, mas cada uma oferecia uma experiência de usuário melhor do que uma solução generalizada baseada em arquivador. Por exemplo:
x2012
Foi uma ótima maneira para as equipes compartilharem globalmente artefatos estáticos como os binários
G Suite Team Drive
Funcionou bem para colaboração de documentos de escritório e foi muito mais tolerante à latência do usuário do que o NFS
Sistema de arquivos Colossus do Google
Equipes com permissão para compartilhar grandes arquivos de dados com mais segurança e escalabilidade do que o NFS
Piper/Git-on-Borg
Poderia sincronizar melhor os dotfiles (preferências de ferramentas personalizadas dos engenheiros)
Uma nova ferramenta histórica como serviço
Poderia hospedar o histórico da linha de comando da estação de trabalho cruzada
À medida que catalogamos os casos de uso e encontramos alternativas, o plano de desativação tomou forma.
Design e implementação
Afastar-se dos arquivadores foi um esforço contínuo, iterativo e plurianual que envolveu vários projetos internos:
Moira
Desativação do diretório inicial
Tekmor
Migrar a long tail dos usuários do diretório inicial
Migra
Desativação do Team Share
Azog
Desativar a infraestrutura de compartilhamento/diretório inicial e hardware associado
Este estudo de caso se concentra no primeiro projeto, Moira. Os projetos subsequentes se basearam no que aprendemos e criamos para Moira.
Conforme mostrado na Figura 6-8, Moira consistia em quatro fases.
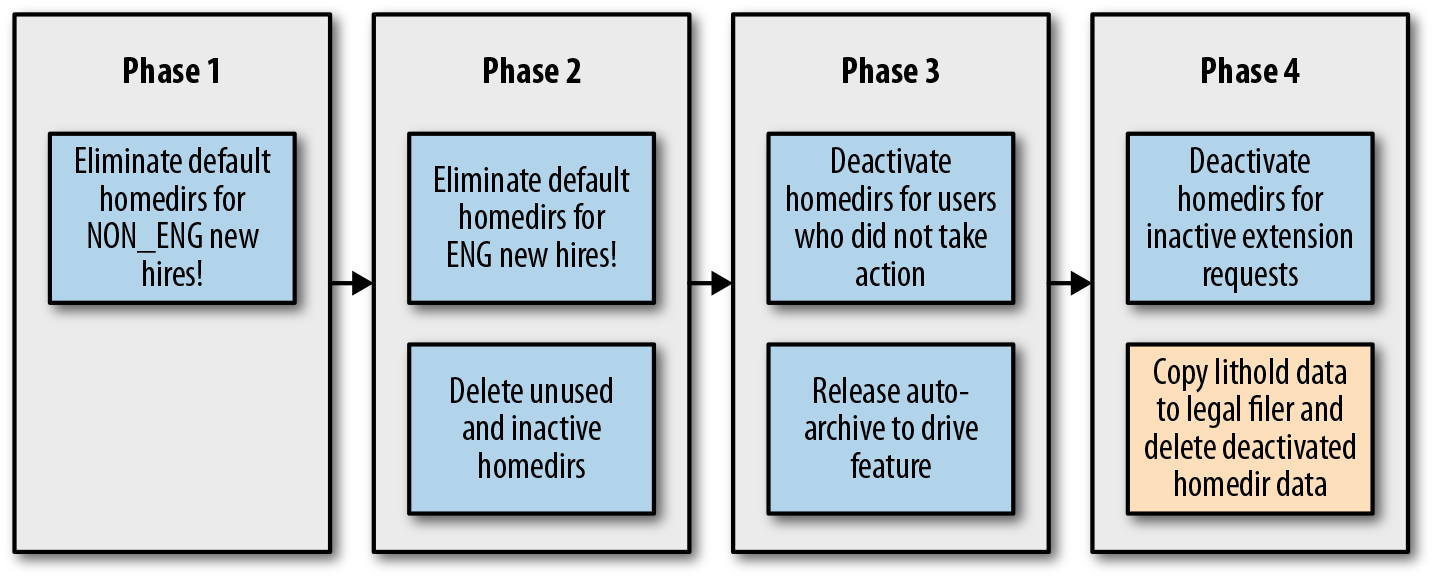
Figura 6-8. As quatro etapas do Projeto Moira
O primeiro passo para descontinuar um sistema obsoleto é parar ou (muitas vezes de forma mais realista) retardar ou desencorajar uma nova adoção. É muito mais doloroso tirar algo dos usuários do que nunca oferecê-lo em primeiro lugar. Os dados do Moonwalk mostraram que os Googlers que não são engenheiros utilizavam o mínimo dos seus diretórios pessoais compartilhados, então nossa fase inicial tinha como alvo esses usuários. À medida que o escopo das fases aumentava, também aumentava nossa confiança nas soluções alternativas de armazenamento e em nossos processos e ferramentas de migração. Cada fase do projeto tinha um documento de design associado que examinava a proposta em dimensões como segurança, escalabilidade, teste e lançamento. Também demos atenção especial à experiência do usuário, expectativas e comunicação. Nosso objetivo era garantir que os usuários afetados por cada fase entendessem os motivos do projeto de desativação e a maneira mais fácil de arquivar ou migrar seus dados.
Componentes-chave
Moonwalk
Embora tivéssemos estatísticas básicas sobre os compartilhamentos de nossos usuários (tamanhos de compartilhamentos, por exemplo), precisávamos entender os fluxos de trabalho de nossos usuários para ajudar a tomar decisões de negócios sobre a suspensão de uso. Montamos um sistema chamado Moonwalk para coletar e relatar essas informações.
O Moonwalk armazenou os dados sobre quem estava acessando quais arquivos e quando no BigQuery, o que nos permitiu criar relatórios e realizar consultas ad hoc para entender melhor nossos usuários. Usando o BigQuery, resumimos os padrões de acesso em 2,5 bilhões de arquivos usando 300 terabytes de espaço em disco. Esses dados pertenciam a 60.000 usuários POSIX em 400 volumes de disco em 124 appliances NAS em 60 locais geográficos ao redor do mundo.
Portal Moira
Nossa grande base de usuários tornou insustentável o gerenciamento do esforço de desativação do diretório inicial com um processo manual baseado em ticket. Precisávamos tornar todo o processo – pesquisando usuários, comunicando os motivos do projeto de desativação e percorrendo o arquivamento de seus dados ou migrando para uma alternativa – o mais simples possível. Os nossos requisitos finais foram:
- Uma página de destino descrevendo o projeto
- Um FAQ atualizado continuamente
- As informações de status e uso associadas ao compartilhamento do usuário atual
- Opções para solicitar, desativar, arquivar, excluir, estender ou reativar um compartilhamento
Nossa lógica de negócios tornou-se bastante complicada porque tivemos que levar em conta vários cenários de usuário. Por exemplo, um usuário pode sair do Google, tirar uma licença temporária ou ter dados sob uma retenção de litígio. A figura 6-9 fornece um diagrama de estado do documento de projeto de amostra que ilustra essa complexidade.
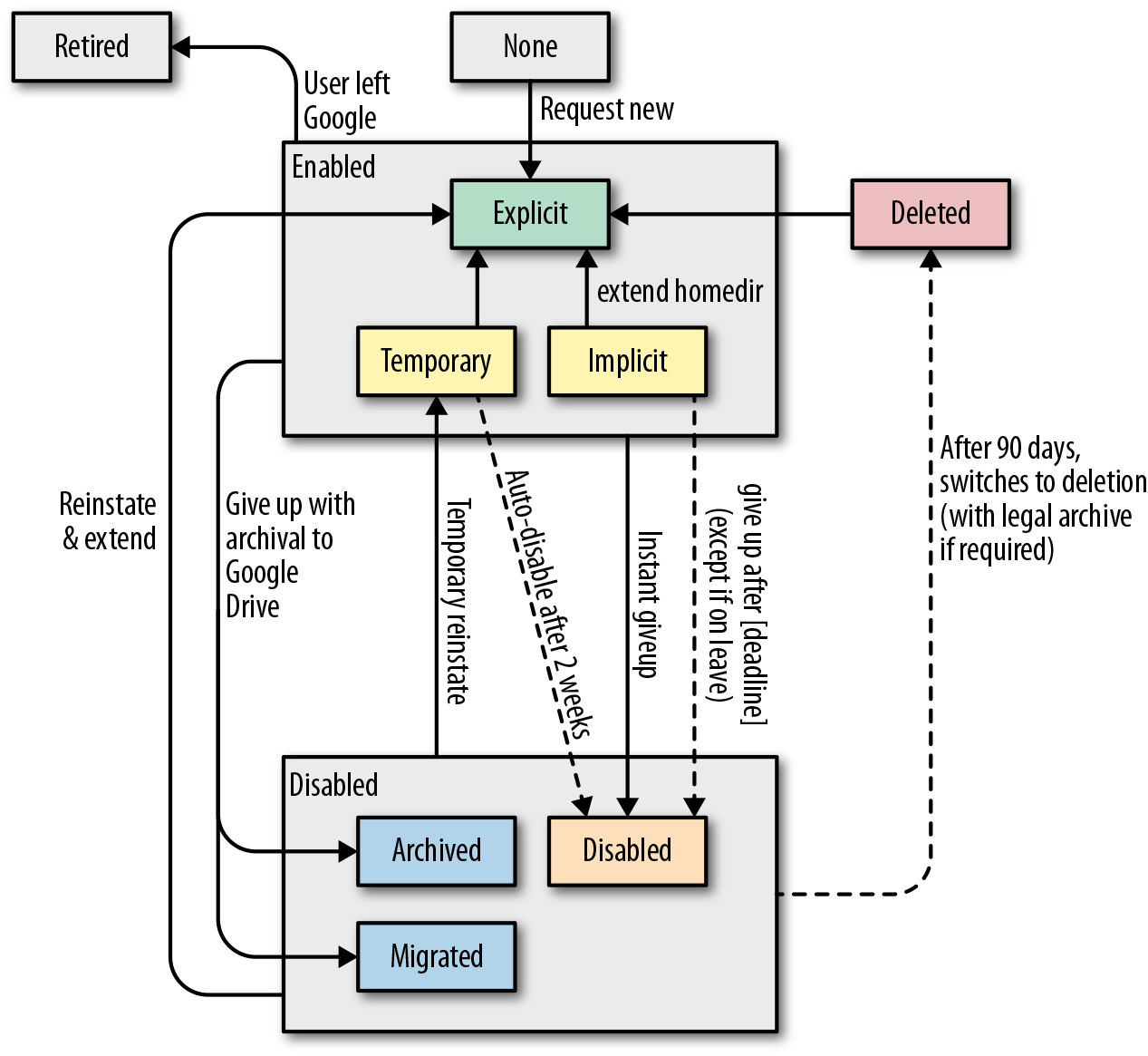
Figura 6-9. Lógica de negócios baseada em cenários de usuário
A tecnologia que alimentava o portal era relativamente simples. Escrito em Python com a estrutura Flask, ele lia e gravava em um Bigtable e usava vários trabalhos em segundo plano e programadores para gerenciar o seu trabalho.
Automação de arquivamento e migração
Precisávamos de muitas ferramentas auxiliares para unir o portal e o gerenciamento de configuração e para consultar e nos comunicar com os usuários. Também precisávamos ter certeza de que identificamos os usuários certos para as comunicações certas. Falsos positivos (relatar erroneamente uma ação necessária) ou falsos negativos (não notificar um usuário de que você estava retirando algo) eram inaceitáveis, e erros aqui significariam trabalho extra na forma de perda de credibilidade e atendimento ao cliente.
Trabalhamos com proprietários de sistemas de armazenamento alternativos para adicionar recursos a seus roteiros. Como resultado, alternativas menos maduras se tornaram mais adequadas para casos de uso de arquivadores à medida que o projeto avançava. Também poderíamos usar e estender ferramentas de outras equipes. Por exemplo, usamos a ferramenta desenvolvida internamente por outra equipe para migrar dados do Google Cloud Storage para o Google Drive como parte da funcionalidade de arquivamento automático do Portal.
O esforço exigiu o desenvolvimento de software substancial ao longo da vida do projeto. Criamos e iteramos em cada componente – o pipeline de relatórios do Moonwalk, o portal e a automação para gerenciar melhor os compartilhamentos de retirada e arquivamento – em resposta aos requisitos da próxima fase e ao feedback do usuário. Aproximámo-nos de um estado completo de funcionalidade apenas na fase três (quase dois anos); e mesmo assim, precisávamos de ferramentas adicionais para lidar com uma “long tail” de cerca de 800 usuários. Essa abordagem baixa e lenta teve benefícios definidos. Permitiu-nos:
- Manter uma equipe enxuta (com média de três membros da equipe CDS)
- Reduzir a interrupção dos fluxos de trabalho do usuário
- Limitar o toil para a Techstop (organização de suporte técnico interno do Google)
- Criar ferramentas conforme necessário para evitar o desperdício de esforços de engenharia
Tal como em todas as decisões de engenharia, houve tradeoffs: o projeto teria vida longa, então a equipe teve que suportar o trabalho operacional relacionado ao arquivador enquanto projetava essas soluções.
O programa foi oficialmente concluído em 2016. Reduzimos os diretórios pessoais de 65.000 para cerca de 50 no momento da redação. (O atual Projeto Azog visa aposentar esses últimos usuários e desativar totalmente o hardware do arquivador.) A experiência de nossos usuários melhorou e o CDS aposentou hardware e processos operacionalmente caros.
Lições aprendidas
Embora nenhuma alternativa pudesse substituir o armazenamento com suporte de arquivador que os Googlers usavam há mais de 14 anos, não precisávamos necessariamente de uma substituição por atacado. Ao mover efetivamente a pilha de uma solução de nível de sistema de arquivos generalizada, mas limitada, para várias soluções específicas de aplicativos, trocamos flexibilidade por melhor escalabilidade, tolerância à latência e segurança. A equipe da Moira teve que antecipar uma variedade de jornadas do usuário e considerar alternativas em vários estágios de maturidade. Tivemos que gerenciar as expectativas em torno dessas alternativas: em conjunto, elas poderiam fornecer uma melhor experiência ao usuário, mas chegar lá não seria indolor. Aprendemos as seguintes lições sobre como reduzir efetivamente o toil ao longo do caminho.
Desafiar suposições e retirar processos de negócios caros
Os requisitos de negócios variam e novas soluções surgem continuamente, por isso vale a pena questionar periodicamente os processos de negócios intensivos de toil. Como discutimos em Estratégias de gerenciamento de toil, rejeitar o toil (decidir não realizar tarefas laboriosas) geralmente é a maneira mais simples de eliminá-la, embora essa abordagem nem sempre seja rápida ou fácil. Reforce seu caso com análises de usuários e justificativas de negócios além da mera redução de toil. A principal justificativa comercial para a desativação de arquivadores se resumia aos benefícios de um modelo de segurança da Beyond Corp. Portanto, embora Moira tenha sido uma ótima maneira de reduzir o toil da equipe do CDS, enfatizar os muitos benefícios de segurança de desativação de arquivadores criou um caso de negócios mais atraente.
Criar interfaces de autoatendimento
Construímos um portal personalizado para Moira (que era relativamente caro), mas geralmente há alternativas mais fáceis. Muitas equipes do Google gerenciam e configuram seus serviços usando o controle de versão e processam solicitações organizacionais na forma de pull requests (chamadas de changelists ou CLs). Essa abordagem requer pouco ou nenhum envolvimento da equipe do serviço, mas nos oferece os benefícios de revisão de código e processos de implantação contínua para validar, testar e implantar alterações internas de configuração de serviço.
Comece com interfaces apoiadas por humanos
Em vários pontos, a equipe da Moira usou uma abordagem de “engenheiro por trás dos bastidores” que casava a automação com o trabalho manual dos engenheiros. Por exemplo, solicitações de compartilhamento abriram bugs de rastreamento, que nossa automação atualizou à medida que processávamos as solicitações.
O sistema também atribuiu bugs aos usuários finais para lembrá-los de endereçar seus compartilhamentos. Os tickets podem servir como uma GUI rápida e superficial para automação: eles mantêm um registro do trabalho, atualizam as partes interessadas e fornecem um mecanismo simples de fallback humano se a automação der errado. No nosso caso, se um usuário precisasse de ajuda com sua migração ou se a automação não pudesse processar sua solicitação, o bug era roteado automaticamente para uma fila que os SREs tratavam manualmente.
Derreter flocos de neve
A automação anseia por conformidade. Os engenheiros da Moira optaram por reequipar nossa automação para lidar especificamente com casos extremos de compartilhamento ou para excluir/modificar compartilhamentos não conformes para atender às expectativas de ferramentas. Isso nos permitiu abordar a automação sem toque para grande parte dos processos de migração.
Nota
Curiosidade: no Google, essa prática de mudar a realidade para se adequar ao código e não o contrário é chamada de “comprar o gnomo”. Esta frase faz referência a uma lenda sobre Froogle, um motor de busca de compras desde os primeiros dias da empresa.
No início da vida de Froogle, um sério bug de qualidade de pesquisa fez com que uma pesquisa por [tênis de corrida] retornasse um gnomo de jardim (usando tênis de corrida) como um resultado de alto nível. Depois de várias tentativas malsucedidas de corrigir o bug, alguém notou que o gnomo não era um item produzido em massa, mas uma única listagem do eBay com a opção Comprar Agora. Eles compraram o gnomo (Figura 6-10).

Figura 6-10. O gnomo de jardim que não desapareceria
Empregar estímulos organizacionais
Procure maneiras de estimular novos usuários a adotar alternativas melhores (e, esperançosamente, menos trabalhosas). Nesse sentido, Moira exigiu escalações para novas solicitações de compartilhamento ou cota e reconheceu usuários que retiraram seus compartilhamentos. Também é importante fornecer uma boa documentação sobre a configuração do serviço, práticas recomendadas e quando usar seu serviço. As equipes do Google costumam empregar codelabs ou livros de receitas que ensinam os usuários a configurar e usar o serviço para casos de uso comuns. Como resultado, a maioria da integração de usuários não requer ajuda da equipe proprietária do serviço.
Conclusão
No mínimo, a quantidade de toil associada à execução de um serviço de produção cresce linearmente com sua complexidade e escala. A automação costuma ser o padrão-ouro da eliminação de toil e pode ser combinada com várias outras táticas. Mesmo quando o toil não vale o esforço da automação total, você pode diminuir as cargas de trabalho de engenharia e operações por meio de estratégias como automação parcial ou mudanças nos processos de negócios.
Os padrões e métodos para eliminar o toil descritos neste capítulo podem ser generalizados para funcionar para uma variedade de outros serviços de produção em larga escala. A eliminação do toil libera o tempo de engenharia para se concentrar nos aspectos mais duradouros dos serviços e permite que as equipes mantenham as tarefas manuais no mínimo à medida que a complexidade e a escala das arquiteturas de serviço modernas continuam a aumentar.
É importante notar que eliminar o toil nem sempre é a melhor solução. Conforme mencionado ao longo deste capítulo, você deve considerar os custos mensuráveis associados à identificação, projeto e implementação de processos ou soluções de automação em torno do toil. Uma vez identificado o toil, é crucial determinar quando a redução do toil faz sentido, usando métricas, análise de retorno sobre o investimento (ROI), avaliação de risco e desenvolvimento iterativo.
O toil geralmente começa pequeno e pode crescer rapidamente para consumir uma equipe inteira. As equipes de SRE devem ser incansáveis na eliminação de toil, porque mesmo que a tarefa pareça assustadora, os benefícios geralmente excedem os custos. Cada um dos projetos que descrevemos exigiu perseverança e dedicação de suas respectivas equipes, que às vezes lutavam contra o ceticismo ou a resistência institucional, e sempre enfrentavam altas prioridades concorrentes. Esperamos que essas histórias encorajem você a identificar seu toil, quantificá-lo e depois trabalhar para eliminá-lo. Mesmo que você não possa investir em um grande projeto hoje, você pode começar com uma pequena prova de conceito que pode ajudar a mudar a disposição de sua equipe em lidar com o toil.
Fonte: Google SRE Book