Capítulo 8: Engenharia de Lançamento
Escrito por Dinah McNutt
Editado por Betsy Beyer e Tim Harvey
A Engenharia de Lançamento é uma disciplina relativamente nova e de rápido crescimento da Engenharia de Software que pode ser descrita de forma concisa como construção e entrega de software. Os engenheiros de lançamento têm uma compreensão sólida (se não especializada) de gerenciamento de código-fonte, compiladores, linguagens de configuração de build, ferramentas de build automatizadas, gerenciadores de pacotes e instaladores. Seu conjunto de habilidades inclui profundo conhecimento de vários domínios: desenvolvimento, gerenciamento de configuração, integração de teste, administração de sistema e suporte ao cliente.
A execução de serviços confiáveis requer processos de liberação confiáveis. Os engenheiros de confiabilidade do site (SREs) precisam saber que os binários e as configurações que eles usam são construídos de forma reproduzível e automatizada para que as versões sejam repetíveis e não sejam “flocos de neve exclusivos”. Mudanças em qualquer aspecto do processo de lançamento devem ser intencionais, ao invés de acidentais. Os SREs se preocupam com esse processo, desde o código-fonte até o deploy.
A engenharia de lançamento é uma função específica do Google. Os engenheiros de lançamento trabalham com engenheiros de software (SWEs) no desenvolvimento de produtos e SREs para definir todas as etapas necessárias para lançar o software – desde como o software é armazenado no repositório de código-fonte, até construir regras para compilação, e como o teste, empacotamento e implantação são conduzidos.
O papel de um engenheiro de lançamento
O Google é uma empresa orientada a dados e a engenharia de lançamento segue o exemplo. Temos ferramentas que informam sobre uma série de métricas, como quanto tempo leva para uma mudança de código passar pelo deploy na produção (em outras palavras, velocidade de lançamento) e estatísticas sobre quais recursos estão sendo usados em arquivos de configuração de build. A maioria dessas ferramentas foi concebida e desenvolvida por engenheiros de lançamento.
Os engenheiros de lançamento definem as melhores práticas para usar nossas ferramentas, a fim de garantir que os projetos sejam lançados usando metodologias consistentes e repetíveis. Nossas melhores práticas cobrem todos os elementos do processo de lançamento. Exemplos incluem compiladores de flag, formatos para tags de identificação de build e as etapas necessárias durante um build. Certificar-se de que nossas ferramentas se comportam corretamente por padrão, e estão adequadamente documentadas, torna mais fácil para as equipes manterem o foco nos recursos e nos usuários, em vez de perder tempo (mal) reinventando a roda quando se trata de lançar software.
O Google tem um grande número de SREs encarregados de fazer o deploy de produtos com segurança e manter os serviços do Google em funcionamento. A fim de garantir que nossos processos de lançamento atendam aos requisitos de negócios, engenheiros de lançamento e SREs trabalham juntos para desenvolver estratégias para alterações canary, iniciando novos lançamentos sem interromper serviços e fazendo o roll back de features que apresentem problemas.
Filosofia
A engenharia de lançamento é guiada por uma filosofia de engenharia e serviço expressa por meio de quatro princípios fundamentais, detalhados nas seções a seguir.
Modelo de autoatendimento
Para trabalhar em escala, as equipes devem ser autossuficientes. A engenharia de lançamento desenvolveu práticas recomendadas e ferramentas que permitem que nossas equipes de desenvolvimento de produto controlem e executem seus próprios processos de lançamento. Embora tenhamos milhares de engenheiros e produtos, podemos alcançar uma alta velocidade de lançamento porque as equipes individuais podem decidir com que frequência e quando lançar novas versões de seus produtos. Os processos de lançamento podem ser automatizados a ponto de exigirem o mínimo de envolvimento dos engenheiros, e muitos projetos são criados e liberados automaticamente usando uma combinação de nosso sistema de build automatizado e nossas ferramentas de deploy. Os lançamentos são verdadeiramente automáticos e requerem o envolvimento do engenheiro apenas se e quando surgirem problemas.
Alta velocidade
O software voltado para o usuário (como muitos componentes da Pesquisa Google) passa pelo rebuilt com frequência, pois nosso objetivo é implementar recursos voltados para o cliente o mais rápido possível. Adotamos a filosofia de que lançamentos frequentes resultam em menos alterações entre as versões. Essa abordagem torna o teste e a solução de problemas mais fáceis. Algumas equipes realizam builds de hora em hora e, em seguida, selecionam a versão para realmente implantar na produção a partir do pool de compilações resultante. A seleção é baseada nos resultados do teste e nos recursos contidos em um determinado build. Outras equipes adotaram um modelo de lançamento “Push on Green” e implantam cada build que passa em todos os testes.
Builds herméticos
As ferramentas de construção devem nos permitir garantir consistência e repetibilidade. Se duas pessoas tentarem construir o mesmo produto com o mesmo número de revisão no repositório de código-fonte, em máquinas diferentes, esperamos resultados idênticos. (O Google usa um repositório monolítico unificado de código-fonte. Vídeo disponível no YouTube aqui). Nossos builds são herméticos, o que significa que são insensíveis às bibliotecas e outros softwares instalados na máquina de construção. Em vez disso, os builds dependem de versões conhecidas de ferramentas de build, como compiladores, e dependências, como bibliotecas. O processo de build é independente e não deve depender de serviços externos ao ambiente de construção.
Reconstruir versões mais antigas quando precisamos corrigir um bug em um software que está sendo executado em produção pode ser um desafio. Nós realizamos essa tarefa reconstruindo na mesma revisão que a construção original e incluindo alterações específicas que foram enviadas após aquele momento. Chamamos essa tática de escolha seletiva. Nossas próprias ferramentas de build são versionadas com base na revisão no repositório de código-fonte para o projeto que está sendo construído. Portanto, um projeto construído no mês passado não usará a versão deste mês do compilador se uma escolha aleatória for necessária, porque essa versão pode conter features incompatíveis ou indesejadas.
Aplicação de políticas e procedimentos
Várias camadas de segurança e controle de acesso determinam quem pode realizar operações específicas ao lançar um projeto. As operações bloqueadas incluem:
- Aprovar alterações no código-fonte – esta operação é gerenciada por meio de arquivos de configuração espalhados por toda a base de código
- Especificação das ações a serem realizadas durante o processo de lançamento
- Criar um novo lançamento
- Aprovar a proposta de integração inicial (que é uma solicitação para realizar um build em um número de revisão específico no repositório de código-fonte) e escolhas subsequentes
- Fazer o deploy de uma nova versão
- Fazer alterações na configuração de build de um projeto
Quase todas as alterações na base de código exigem uma revisão do código, que é uma ação simplificada e integrada ao nosso fluxo de trabalho normal de desenvolvedor. Nosso sistema de lançamento automatizado produz um relatório de todas as alterações contidas em um lançamento, que é arquivado com outros artefatos de construção. Ao permitir que os SREs entendam quais mudanças estão incluídas em uma nova versão de projeto, este relatório pode agilizar a solução de problemas quando há problemas com uma versão.
Build e deploy contínuos
O Google desenvolveu um sistema de lançamento automatizado chamado Rapid. Rapid é um sistema que aproveita uma série de tecnologias do Google para fornecer uma estrutura que entrega versões escaláveis, herméticas e confiáveis. As seções a seguir descrevem o ciclo de vida do software no Google e como ele é gerenciado usando o Rapid e outras ferramentas associadas.
Construção
Blaze é a ferramenta de build preferida do Google (o Blaze foi lançado como Bazel. Existe uma “FAQ Bazel” no site oficial). Ela suporta a construção de binários de uma variedade de linguagens, incluindo nossas linguagens padrão C++, Java, Python, Go e JavaScript. Os engenheiros usam o Blaze para definir os build targets (por exemplo, a saída de um build, como um arquivo JAR) e para especificar as dependências de cada target. Ao criar um build, o Blaze constrói automaticamente os targets de dependência.
Build targets para binários e testes de unidade são definidos nos arquivos de configuração de projeto do Rapid. Flags específicas do projeto, como um identificador de build exclusivo, são passados pelo Rapid para o Blaze. Todos os binários suportam uma flag que exibe a data de build, o número da revisão e o identificador de build, o que nos permite associar facilmente um binário a um registro de como foi construído.
Ramificação
Todo o código é verificado na ramificação principal da árvore do código-fonte (linha principal). No entanto, a maioria dos projetos principais não libera diretamente da linha principal. Em vez disso, ramificamos da linha principal em uma revisão específica e nunca mesclamos as alterações da ramificação de volta na linha principal. As correções de bugs são enviadas para a linha principal e, em seguida, selecionadas no branch para inclusão no lançamento. Essa prática evita a coleta inadvertida de alterações não relacionadas enviadas à linha principal desde a ocorrência do build original. Usando esse método de selecionar e ramificar, sabemos o conteúdo exato de cada versão.
Teste
Um sistema de teste contínuo executa testes de unidade na linha principal do código cada vez que uma alteração é enviada, o que nos permite detectar falhas de build e teste rapidamente. A engenharia de lançamento recomenda que os targets de build de teste contínuo correspondam aos mesmos targets de teste que geram o lançamento do projeto. Também recomendamos a criação de lançamentos no número de revisão (versão) do último build de teste contínuo que concluiu com êxito todos os testes. Essas medidas diminuem a chance de que alterações subsequentes feitas na linha principal causem falhas durante a construção executada no momento do lançamento.
Durante o processo de lançamento, nós reexecutamos os testes de unidade usando o branch de lançamento e criamos uma trilha de auditoria mostrando que todos os testes foram aprovados. Esta etapa é importante porque se um lançamento envolve escolhas certas, o branch de lançamento pode conter uma versão do código que não existe em nenhum lugar da linha principal. Queremos garantir que os testes sejam aprovados no contexto do que realmente está sendo lançado.
Para complementar o sistema de teste contínuo, usamos um ambiente de teste independente que executa testes de nível de sistema em artefatos de build empacotados. Esses testes podem ser iniciados manualmente ou a partir do Rapid.
Empacotamento
O software é distribuído para nossas máquinas de produção por meio do Midas Package Manager (MPM). O MPM monta pacotes com base nas regras do Blaze, que lista os artefatos de build a serem incluídos, junto com seus proprietários e permissões. Os pacotes são nomeados (por exemplo, search/shakespeare/frontend), versionados com um hash exclusivo e assinados para garantir a autenticidade. O MPM oferece suporte à aplicação de rótulos a uma versão específica de um pacote. O Rapid aplica um rótulo contendo o ID do build, o que garante que um pacote possa ser referenciado de forma exclusiva usando o nome do pacote e este rótulo.
Os rótulos podem ser aplicados a um pacote MPM para indicar a localização de um pacote no processo de lançamento (por exemplo, dev, canary ou produção). Se você aplicar um rótulo existente a um novo pacote, o rótulo será automaticamente movido do pacote antigo para o novo. Por exemplo: se um pacote é rotulado como canary, alguém instalando subsequentemente a versão canary desse pacote receberá automaticamente a versão mais recente do pacote com o rótulo canary.
Rapid
A figura abaixo mostra os principais componentes do sistema Rapid. O Rapid é configurado com arquivos chamados blueprints. Os blueprints são escritos em uma linguagem de configuração interna e são usados para definir destinos de construção e teste, regras para deploy e informações administrativas (como project owners). As listas de controle de acesso com base em funções determinam quem pode executar ações específicas em um projeto Rapid.
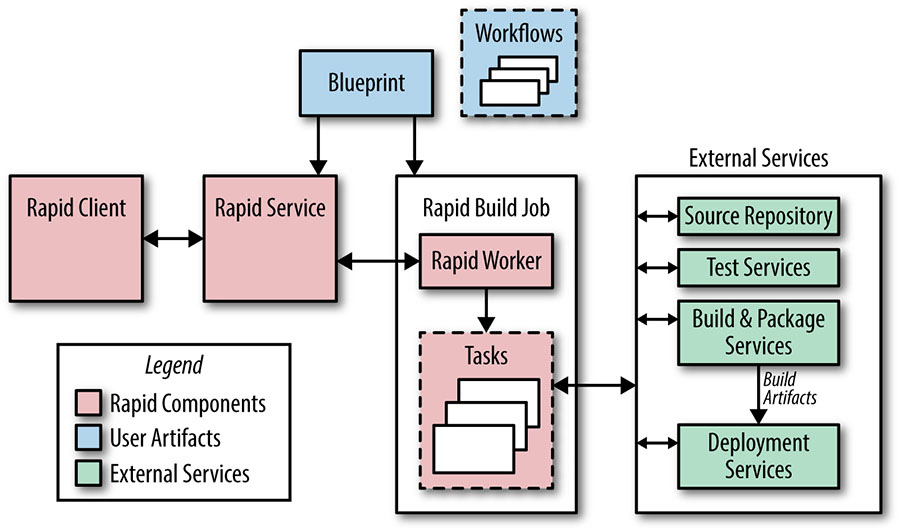
Cada projeto do Rapid possui workflows que definem as ações a serem executadas durante o processo de lançamento. As ações do workflow podem ser executadas em série ou em paralelo, sendo que um workflow pode iniciar outros. O Rapid despacha solicitações de trabalho para tarefas em execução como um trabalho Borg em nossos servidores de produção. Como o Rapid usa nossa infraestrutura de produção, ele pode lidar com milhares de solicitações de lançamento simultaneamente.
Um processo de lançamento típico acontece da seguinte forma:
- O Rapid usa o número de revisão de integração solicitado (geralmente obtido automaticamente do nosso sistema de teste contínuo) para criar um branch de lançamento.
- O Rapid usa o Blaze para compilar todos os binários e executar os testes de unidade, geralmente executando essas duas etapas em paralelo. A compilação e o teste ocorrem em ambientes dedicados a essas tarefas específicas, em vez de ocorrer no Borg onde o workflow Rapid está sendo executado. Essa separação nos permite paralelizar o trabalho facilmente.
- Os artefatos de build ficam então disponíveis para teste do sistema e deploys canary. Um deploy canary típico envolve o início de alguns trabalhos em nosso ambiente de produção após a conclusão dos testes do sistema.
- Os resultados de cada etapa do processo são registrados. É criado um relatório de todas as alterações desde a última versão.
O Rapid nos permite gerenciar nossas ramificações de lançamento e solicitações; solicitações individuais escolhidas aleatoriamente podem ser aprovadas ou rejeitadas para inclusão em um lançamento.
Deploy
O Rapid costuma ser usado para conduzir implantações simples diretamente. Ele atualiza os trabalhos do Borg para usar pacotes MPM recém-construídos com base nas definições de deploy nos arquivos de blueprint e executores de tarefas especializados.
Para deploys mais complexos, usamos o Sisyphus, que é um framework de automação de implantação de uso geral desenvolvido pela equipe SRE. Uma implementação (conhecida como rollout) é uma unidade lógica de trabalho composta por uma ou mais tarefas individuais. O Sisyphus fornece um conjunto de classes Python que podem ser estendidas para oferecer suporte a qualquer processo de deploy. O framework possui um painel que possibilita um controle mais preciso sobre como a implementação é realizada e fornece uma maneira de monitorar o progresso da implementação.
Em uma integração típica, o Rapid cria uma implementação em um trabalho do Sisyphus de longa duração. O Rapid conhece o rótulo de construção associado ao pacote MPM que ele criou e pode especificar esse rótulo de construção ao criar a implementação no Sisyphus. Este então usa o rótulo de build para especificar qual versão dos pacotes MPM deve ser implantada.
Com o Sisyphus, o processo de implementação pode ser tão simples ou complicado quanto necessário. Por exemplo, ele pode atualizar todas as tarefas associadas imediatamente ou pode distribuir um novo binário para clusters sucessivos por um período de várias horas.
Nosso objetivo é adequar o processo de deploy ao perfil de risco de um determinado serviço. Em ambientes de desenvolvimento ou de pré-produção, podemos criar lançamentos de hora em hora e enviar lançamentos automaticamente quando todos os testes forem aprovados. Para grandes serviços voltados para o usuário, podemos começar em um cluster e expandir exponencialmente até que todos os clusters sejam atualizados. Para peças sensíveis de infraestrutura, podemos estender o lançamento por vários dias, intercalando-as em instâncias em diferentes regiões geográficas.
Gerenciamento de configuração
O gerenciamento de configuração é uma área de colaboração particularmente próxima entre engenheiros de lançamento e SREs. Embora o gerenciamento de configuração possa inicialmente parecer um problema aparentemente simples, as alterações na configuração são uma fonte potencial de instabilidade. Como resultado, nossa abordagem para liberar e gerenciar configurações de sistema e serviço evoluiu substancialmente ao longo do tempo. Hoje usamos vários modelos para distribuir arquivos de configuração, conforme descrito nos parágrafos a seguir. Todos os esquemas envolvem o armazenamento de configuração em nosso repositório de código-fonte primário e a aplicação de um requisito de revisão de código estrito.
Use a linha principal para configuração. Este foi o primeiro método usado para configurar serviços no Borg (e os sistemas anteriores ao Borg). Usando esse esquema, os desenvolvedores e SREs modificam os arquivos de configuração na cabeça do branch principal. As alterações são revisadas e aplicadas ao sistema em execução. Como resultado, as versões binárias e as mudanças de configuração são dissociadas. Embora conceitual e procedimentalmente simples, essa técnica geralmente leva a uma distorção entre a versão com check-in dos arquivos de configuração e a versão em execução do arquivo de configuração, porque as tarefas devem ser atualizadas para que as alterações sejam coletadas.
Inclua arquivos de configuração e binários no mesmo pacote MPM. Para projetos com poucos arquivos de configuração ou projetos onde os arquivos (ou um subconjunto de arquivos) mudam a cada ciclo de lançamento, os arquivos de configuração podem ser incluídos no pacote MPM com os binários. Embora essa estratégia limite a flexibilidade ao vincular os arquivos binários e de configuração de maneira rígida, ela simplifica o deploy, porque requer apenas a instalação de um pacote.
Empacote os arquivos de configuração em “pacotes de configuração” MPM. Podemos aplicar o princípio hermético ao gerenciamento de configuração. As configurações binárias tendem a ser fortemente vinculadas a versões específicas de binários, portanto, aproveitamos os sistemas de construção e empacotamento para capturar e liberar arquivos de configuração junto com seus binários. Semelhante ao nosso tratamento de binários, podemos usar o ID de build para reconstruir a configuração em um momento específico.
Por exemplo, uma mudança que implementa um novo recurso pode ser lançada com uma configuração de flag que configura esse recurso. Ao gerar dois pacotes MPM, um para o binário e outro para a configuração, mantemos a capacidade de alterar cada pacote independentemente. Ou seja, se o recurso foi lançado com uma configuração de flag de first_folio, mas percebemos que deveria ser bad_quarto, podemos escolher essa mudança no branch de lançamento, reconstruir o pacote de configuração e fazer o deploy. Essa abordagem tem a vantagem de não exigir uma nova construção binária.
Podemos aproveitar o recurso de rotulagem do MPM para indicar quais versões dos pacotes MPM devem ser instalados juntos. Um rótulo de much_ado pode ser aplicado aos pacotes MPM descritos no parágrafo anterior, o que nos permite buscar ambos os pacotes usando este rótulo. Quando uma nova versão do projeto é construída, o rótulo much_ado será aplicado aos novos pacotes. Como essas marcas são exclusivas no namespace de um pacote MPM, apenas o pacote mais recente com essa tag será usado.
Leia os arquivos de configuração de um armazenamento externo. Alguns projetos têm arquivos de configuração que precisam ser alterados com frequência ou dinamicamente (ou seja, enquanto o binário está em execução). Esses arquivos podem ser armazenados no Chubby, Bigtable ou em nosso sistema de arquivos com base na origem.
Em resumo, os project owners consideram as diferentes opções para distribuir e gerenciar arquivos de configuração e decidirem qual funciona melhor caso a caso.
Conclusões
Embora este capítulo tenha discutido especificamente a abordagem do Google para a engenharia de lançamento e as maneiras pelas quais os engenheiros de lançamento trabalham e colaboram com os SREs, essas práticas também podem ser aplicadas de forma mais ampla.
Não é apenas para Googlers
Quando equipados com as ferramentas certas, automação adequada e políticas bem definidas, os desenvolvedores e SREs não devem se preocupar com o lançamento de software. Os lançamentos podem ser tão indolores quanto simplesmente apertar um botão.
A maioria das empresas lida com o mesmo conjunto de problemas de engenharia de lançamento, independentemente de seu tamanho ou das ferramentas que usam. Então, pense: como você deve lidar com o controle de versão de seus pacotes? Você deve usar um modelo de construção e implantação contínua ou realizar builds periódicos? Com qual frequência deve lançar? Quais políticas de gerenciamento de configuração você deve usar? Quais métricas de lançamento são de interesse?
Os engenheiros de lançamento do Google desenvolveram nossas próprias ferramentas por necessidade, porque ferramentas de código aberto ou fornecidas por fornecedores não funcionam na escala que exigimos. Ferramentas personalizadas nos permitem incluir funcionalidade para oferecer suporte (e até mesmo fazer cumprir) as políticas de processo de lançamento. No entanto, essas políticas devem primeiro ser definidas a fim de adicionar recursos apropriados às nossas ferramentas, e todas as empresas devem se esforçar para definir seus processos de lançamento, quer os processos possam ser automatizados e/ou impostos ou não.
Comece a Engenharia de Lançamento devagar
A Engenharia de Lançamento muito frequentemente foi tida como um pensamento à parte, mas essa maneira de pensar deve mudar à medida que as plataformas e os serviços continuarem a crescer em tamanho e complexidade.
As equipes devem fazer um orçamento para liberar recursos de engenharia no início do ciclo de desenvolvimento do produto. É mais barato implementar boas práticas e processos no início do que ter que reformar seu sistema mais tarde.
É essencial que os desenvolvedores, SREs e engenheiros de lançamento trabalhem juntos. O engenheiro de lançamento precisa entender a intenção de como o código deve ser construído e implantado. Os desenvolvedores não devem construir e “jogar os resultados por cima do muro” para serem manipulados pelos engenheiros de lançamento.
As equipes de projeto individuais decidem quando a engenharia de lançamento se envolve em um projeto. Como a engenharia de lançamento ainda é uma disciplina relativamente jovem, os gerentes nem sempre planejam e orçam a engenharia de lançamento nos estágios iniciais de um projeto. Portanto, ao considerar como incorporar as práticas de engenharia de lançamento, certifique-se de considerar sua função aplicada a todo o ciclo de vida de seu produto ou serviço – especialmente nos estágios iniciais.
Mais informações
Para obter mais informações sobre a engenharia de lançamento, consulte as apresentações a seguir, cada uma com um vídeo disponível online:
- Como a Adoção do Lançamento Contínuo Reduziu a Complexidade da Mudança, USENIX Release Engineering Summit West 2014
- Mantendo a Consistência em um Ambiente Massivamente Paralelo, USENIXConfiguration Management Summit 2013
- Os 10 Mandamentos da Engenharia de Lançamento, 2nd International Workshop on Release Engineering 2014
- Distribuindo Software em um Ambiente Massivamente Paralelo, LISA 2014
Fonte: Google SRE Book