Em um caso ideal, a carga de um determinado serviço é distribuída perfeitamente por todas as suas tarefas de backend e, a qualquer momento, as tarefas de backend menos e mais carregadas consomem exatamente a mesma quantidade de CPU.
Só podemos enviar tráfego para um datacenter até o ponto em que a tarefa mais carregada atinja seu limite de capacidade; isso está representado na figura abaixo para dois cenários no mesmo intervalo de tempo. Durante esse período, o algoritmo de balanceamento de carga entre datacenters deve evitar o envio de tráfego adicional para o datacenter, para não haver o risco de sobrecarregar algumas tarefas.
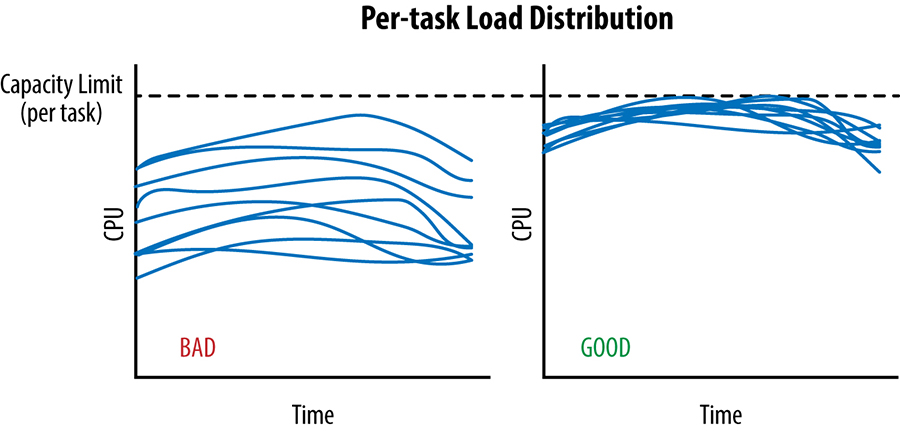
Conforme mostrado no gráfico à esquerda na figura abaixo, uma quantidade significativa de capacidade é desperdiçada: a capacidade ociosa de cada tarefa, exceto a tarefa mais carregada.
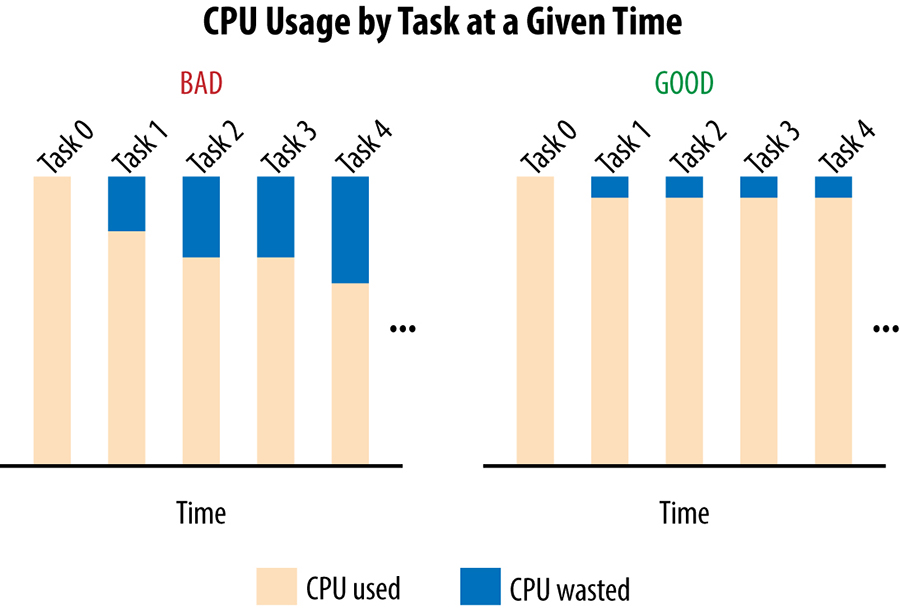
Mais formalmente, sendo CPU[i] a taxa de CPU consumida pela tarefa i em um determinado ponto de tempo, e supondo que a tarefa 0 seja a tarefa mais carregada; então, no caso de uma grande propagação, estamos desperdiçando a soma das diferenças na CPU de qualquer tarefa para CPU[0]: ou seja, a soma sobre todas as tarefas i de (CPU[0] – CPU[i]) será desperdiçada. Neste caso, “desperdiçada” significa reservada, mas não utilizada.
Este exemplo ilustra como práticas ruins de balanceamento de carga no datacenter limitam artificialmente a disponibilidade de recursos: você pode estar reservando 1.000 CPUs para seu serviço em um determinado datacenter, mas não conseguir usar mais do que, digamos, 700 CPUs.
Uma implementação ingênua de um algoritmo de seleção de subconjunto pode fazer com que cada cliente embaralhe aleatoriamente a lista de backends uma vez e preencha seu subconjunto selecionando backends resolvíveis/saudáveis da lista. Embaralhando uma vez e, em seguida, escolhendo backends do início da lista lida com reinicializações e falhas de forma robusta (por exemplo, com relativamente pouca rotatividade) porque explicitamente os limita a consideração. No entanto, descobrimos que essa estratégia funciona muito mal na maioria dos cenários práticos porque distribui a carga de maneira muito desigual.
Durante o trabalho inicial de balanceamento de carga, implementamos subconjuntos aleatórios e calculamos a carga esperada para vários casos. Como exemplo, considere:
- 300 clientes
- 300 backends
- Um tamanho de subconjunto de 30% (cada cliente se conecta a 90 backends)
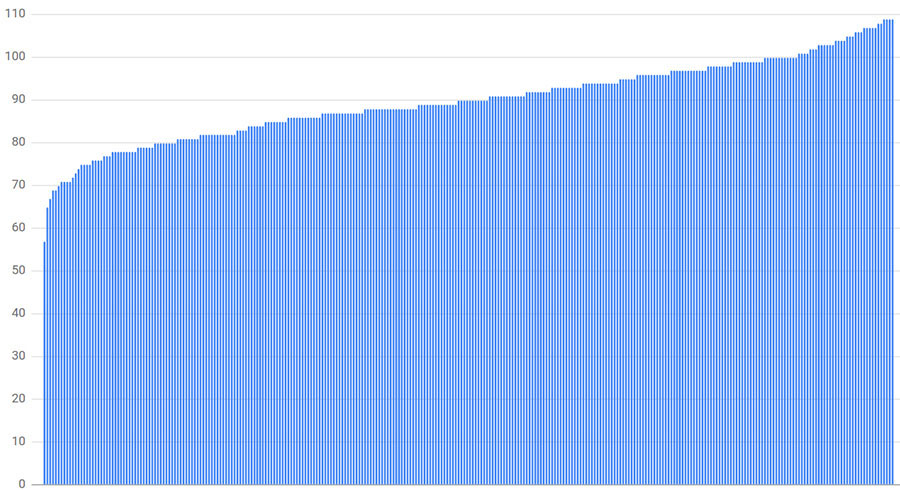
Como mostra a figura abaixo, o backend menos carregado tem apenas 63% da carga média (57 conexões, onde a média é de 90 conexões) e o mais carregado tem 121% (109 conexões). Na maioria dos casos, um tamanho de subconjunto de 30% já é maior do que gostaríamos de usar na prática. A distribuição de carga calculada muda toda vez que executamos a simulação enquanto o padrão geral permanece.
Infelizmente, tamanhos menores de subconjuntos levam a desequilíbrios ainda piores. Por exemplo, a figura abaixo mostra os resultados se o tamanho do subconjunto for reduzido para 10% (30 backends por cliente). Nesse caso, o backend menos carregado recebe 50% da carga média (15 conexões) e o mais carregado recebe 150% (45 conexões).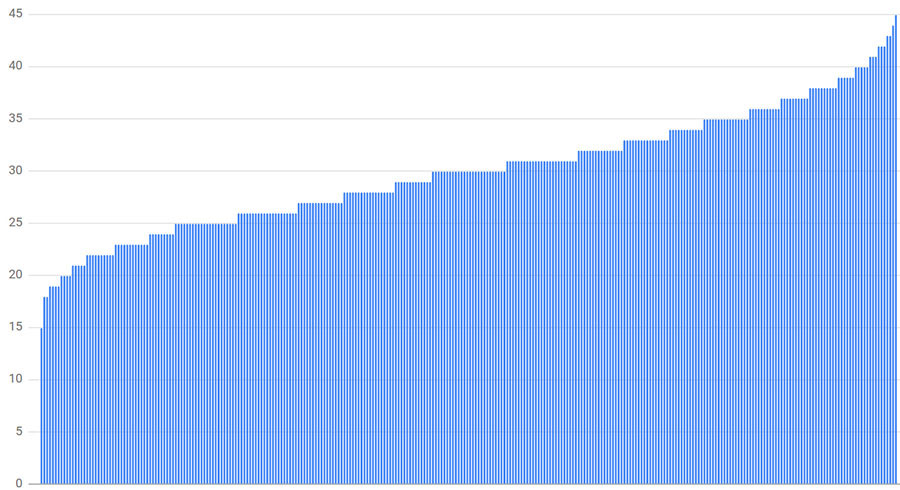
Concluímos que, para que o subconjunto aleatório distribua a carga de maneira relativamente uniforme em todas as tarefas disponíveis, precisaríamos de subconjuntos de tamanhos de até 75%. Um subconjunto tão grande é simplesmente impraticável; a variação no número de clientes que se conectam a uma tarefa é muito grande para considerar um subconjunto aleatório uma boa política de seleção de subconjunto em escala.
A solução do Google para as limitações do subconjunto aleatório é o subconjunto determinístico. O código a seguir implementa esse algoritmo, descrito em detalhes a seguir:
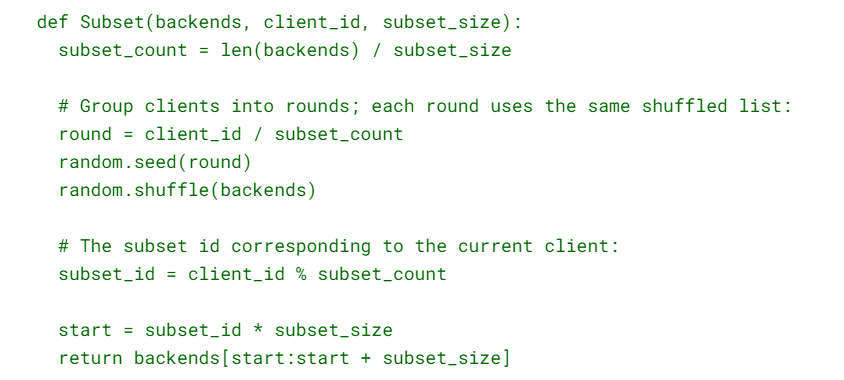
Dividimos as tarefas do cliente em “rodadas”, onde round i consiste em subset_count de tarefas consecutivas do cliente, começando na tarefa subset_count × i, e subset_count é o número de subconjuntos (ou seja, o número de tarefas de backend dividido pelo tamanho do subconjunto desejado). Dentro de cada rodada, cada backend é atribuído a exatamente um cliente (exceto possivelmente a última rodada, que pode não conter clientes suficientes, portanto, alguns backends podem não ser atribuídos).
Por exemplo, se tivermos 12 tarefas de backend [0, 11] e um tamanho de subconjunto desejado de 3, teremos rodadas contendo 4 clientes cada (subset_count = 12/3). Se tivéssemos 10 clientes, o algoritmo anterior poderia produzir os seguintes shuffled_backends:
O ponto-chave a ser observado é que cada rodada atribui apenas um backend em toda a lista a cada cliente (exceto o último, onde ficamos sem clientes). Neste exemplo, cada backend é atribuído a exatamente dois ou três clientes.
A lista deve ser embaralhada; caso contrário, os clientes recebem um grupo de tarefas de backend consecutivas que podem ficar temporariamente indisponíveis (por exemplo, porque o trabalho de backend está sendo atualizado gradualmente, em ordem, da primeira à última tarefa). Rodadas diferentes usam uma semente diferente para embaralhar. Caso contrário, quando um backend falha, a carga que estava recebendo é distribuída apenas entre os backends restantes em seu subconjunto. Se backends adicionais no subconjunto falharem, o efeito se compõe e a situação pode piorar de forma significante e bem rapidamente: se N backends em um subconjunto estiverem inativos, sua carga correspondente será distribuída pelos backends restantes (subset_size – N). Uma abordagem muito melhor é distribuir essa carga por todos os backends restantes usando um embaralhador diferente para cada rodada.
Quando usamos um embaralhamento diferente para cada rodada, os clientes na mesma rodada começarão com a mesma lista embaralhada, mas os clientes nas rodadas terão listas embaralhadas diferentes. A partir daqui, o algoritmo cria definições de subconjunto com base na lista embaralhada de backends e no tamanho de subconjunto desejado. Por exemplo:
Subset[0] = shuffled_backends[0] através de shuffled_backends[2]
Subset[1] = shuffled_backends[3] através de shuffled_backends[5]
Subset[2] = shuffled_backends[6] através de shuffled_backends[8]
Subset[3] = shuffled_backends[9] através de shuffled_backends[11]
onde shuffled_backend é a lista embaralhada criada por cada cliente. Para atribuir um subconjunto a uma tarefa de cliente, basta pegar o subconjunto que corresponde à sua posição dentro de sua rodada (por exemplo, (i % 4) para client[i] com quatro subconjuntos):
client[0], client[4], client[8] usará subset[0]
client[1], client[5], client[9] usará subset[1]
client[2], client[6], client[10] usará subset[2]
client[3], client[7], client[11] usará subset[3]
Como os clientes nas rodadas usarão um valor diferente para shuffled_backends (e, portanto, para subset) e os clientes nas rodadas usarão subconjuntos diferentes, a carga da conexão é distribuída uniformemente. Nos casos em que o número total de backends não é divisível pelo tamanho do subconjunto desejado, permitimos que alguns subconjuntos sejam ligeiramente maiores que outros, mas na maioria dos casos o número de clientes atribuídos a um backend será diferente em no máximo 1.
Como mostra a figura abaixo, a distribuição para o exemplo anterior de 300 clientes cada um se conectando a 10 de 300 backends produz resultados muito bons: cada backend recebe exatamente o mesmo número de conexões.

Uma abordagem alternativa ao Simple Round Robin é fazer com que cada tarefa do cliente acompanhe o número de solicitações ativas que possui para cada tarefa de backend em seu subconjunto e use o Round Robin entre o conjunto de tarefas com um número mínimo de solicitações ativas.
Por exemplo, suponha que um cliente use um subconjunto de tarefas de backend t0 a t9 e atualmente tenha o seguinte número de solicitações ativas em cada backend:
Para uma nova solicitação, o cliente filtraria a lista de possíveis tarefas de backend apenas para aquelas tarefas com o menor número de conexões (t2, t3, t5, t7 e t8) e escolheria um backend dessa lista. Vamos supor que ele escolha t2. A tabela de estado de conexão do cliente agora teria a seguinte aparência:
Supondo que nenhuma das solicitações atuais tenha sido concluída, na próxima solicitação, o pool de candidatos de backend se torna t3, t5, t7 e t8.
Vamos avançar rapidamente até emitirmos quatro novas solicitações. Ainda supondo que nenhuma solicitação seja concluída nesse meio tempo, a tabela de estado de conexão teria a seguinte aparência:

Neste ponto, o conjunto de candidatos de backend são todas as tarefas, exceto t0 e t6. No entanto, se a solicitação em relação à tarefa t4 for concluída, seu estado atual se tornará “0 solicitações ativas” e uma nova solicitação será atribuída a t4.
Essa implementação realmente usa Round Robin, mas é aplicada em todo o conjunto de tarefas com solicitações ativas mínimas. Sem essa filtragem, a política pode não ser capaz de distribuir as solicitações o suficiente para evitar uma situação em que parte das tarefas de backend disponíveis não sejam utilizadas. A ideia por trás da política de menor carga é que as tarefas carregadas tenderão a ter maior latência do que aquelas com capacidade extra, e essa estratégia naturalmente tirará a carga dessas tarefas carregadas.
Dito tudo isso, aprendemos (da maneira mais difícil!) sobre uma armadilha muito perigosa da abordagem Round Robin menos carregado: se uma tarefa não estiver nada íntegra, ela pode começar a apresentar 100% de erros. Dependendo da natureza desses erros, eles podem ter latência muito baixa; muitas vezes é significativamente mais rápido apenas retornar um erro “Não estou íntegro!” do que efetivamente processar uma solicitação. Como resultado, os clientes podem começar a enviar uma quantidade muito grande de tráfego para a tarefa não íntegra, pensando erroneamente que a tarefa está disponível, em vez de fazê-la falhar rapidamente! Dizemos que a tarefa não íntegra está agora “afundando” o tráfego. Felizmente, essa armadilha pode ser resolvida com relativa facilidade modificando a política para contar erros recentes como se fossem solicitações ativas. Dessa forma, se uma tarefa de backend se tornar não íntegra, a política de balanceamento de carga começará a desviar a carga dela da mesma forma que desviaria a carga de uma tarefa sobrecarregada.
O Round Robin menos carregado apresenta duas limitações importantes:
A contagem de solicitações ativas pode não ser um proxy muito bom para a capacidade de um determinado backend
Muitas solicitações passam uma parte significativa de sua vida apenas aguardando uma resposta da rede (ou seja, aguardando respostas a solicitações que iniciam para outros backends) e muito pouco tempo no processamento real. Por exemplo, uma tarefa de backend pode processar duas vezes mais solicitações que outra (por exemplo, porque está sendo executada em uma máquina com uma CPU duas vezes mais rápida que o restante), mas a latência de suas solicitações ainda pode ser aproximadamente a mesma como a latência das requisições na outra tarefa (porque as requisições passam a maior parte de sua vida apenas esperando que a rede responda). Nesse caso, como o bloqueio de I/O geralmente consome zero de CPU, muito pouca RAM e nenhuma largura de banda, ainda gostaríamos de enviar o dobro de solicitações para o backend mais rápido. No entanto, o Round Robin menos carregado considerará ambas as tarefas de backend igualmente carregadas.
A contagem de solicitações ativas em cada cliente não inclui solicitações de outros clientes para os mesmos backends
Ou seja, cada tarefa do cliente tem apenas uma visão muito limitada do estado de suas tarefas de backend: a visão de suas próprias solicitações.
Na prática, descobrimos que grandes serviços usando o Round Robin menos carregado verão sua tarefa de backend mais carregada usando duas vezes mais CPU do que a menos carregada, tendo um desempenho tão ruim quanto o Round Robin.
O Round Robin avançado é uma importante política de balanceamento de carga que melhora o Round Robin simples e intermediário, incorporando informações fornecidas pelo backend no processo de decisão.
O Round Robin avançado é bastante simples em princípio: cada tarefa do cliente mantém uma pontuação de “capacidade” para cada backend em seu subconjunto. As solicitações são distribuídas no modo Round-Robin, mas os clientes pesam as distribuições de solicitações para backends proporcionalmente. Em cada resposta (incluindo respostas a verificações de integridade), os backends incluem as taxas observadas atuais de consultas e erros por segundo, além da utilização (normalmente, uso da CPU). Os clientes ajustam as pontuações de capacidade periodicamente para escolher tarefas de backend com base em seu número atual de solicitações bem-sucedidas tratadas e em qual custo de utilização; solicitações com falha resultam em uma penalidade que afeta decisões futuras.
Na prática, o Round Robin avançado funcionou muito bem e reduziu significativamente a diferença entre as tarefas mais e menos utilizadas. A figura abaixo mostra as taxas de CPU para um subconjunto aleatório de tarefas de backend em torno do momento em que seus clientes alternaram de Round Robin intermediário para avançado. A propagação das tarefas menos carregadas para as tarefas mais carregadas diminuiu drasticamente.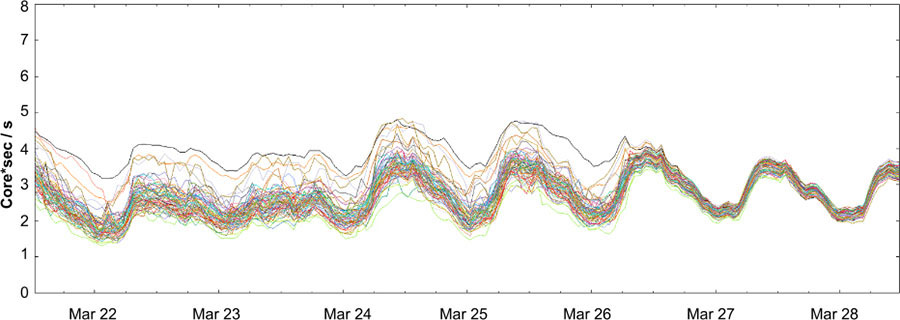
Fonte: Google SRE Book