Escrito por Alejandro Forero Cuervo
Editado por Sarah Chavis
Evitar a sobrecarga é um objetivo das políticas de balanceamento de carga. Mas não importa quão eficiente seja sua política de balanceamento de carga, eventualmente alguma parte do seu sistema ficará sobrecarregada. O tratamento adequado das condições de sobrecarga é fundamental para a execução de um sistema de serviço confiável.
Uma opção para lidar com a sobrecarga é fornecer respostas degradadas: respostas que não são tão precisas ou que contêm menos dados do que as respostas normais, mas que são mais fáceis de calcular. Por exemplo:
- Em vez de pesquisar um corpus inteiro para fornecer os melhores resultados disponíveis para uma query, pesquise apenas uma pequena porcentagem do conjunto de candidatos.
- Confie em uma cópia local dos resultados que podem não estar totalmente atualizados, mas que serão mais baratos de usar do que ir contra o armazenamento canônico.
No entanto, sob sobrecarga extrema, o serviço pode nem mesmo ser capaz de calcular e fornecer respostas degradadas. Neste ponto, pode não ter outra opção imediata a não ser mostrar os erros. Uma maneira de mitigar esse cenário é equilibrar o tráfego entre os datacenters de forma que nenhum datacenter receba mais tráfego do que tem capacidade de processar. Por exemplo, se um datacenter executar 100 tarefas de backend e cada tarefa puder processar até 500 solicitações por segundo, o algoritmo de balanceamento de carga não permitirá que mais de 50.000 consultas por segundo sejam enviadas a esse datacenter. No entanto, mesmo essa restrição pode ser insuficiente para evitar sobrecarga quando você está operando em escala. No final das contas, é melhor construir clientes e back-ends para lidar com restrições de recursos normalmente: redirecionar quando possível, fornecer resultados degradados quando necessário e lidar com erros de recursos de forma transparente quando tudo mais falhar.
A armadilha das “queries por segundo”
Queries diferentes podem ter requisitos de recursos muito diferentes. O custo de uma query pode variar com base em fatores arbitrários, como o código no cliente que a libera (para serviços que têm muitos clientes diferentes) ou até mesmo a hora do dia (por exemplo, usuários domésticos versus usuários de trabalho; ou tráfego interativo do usuário final versus tráfego em lote).
Aprendemos esta lição da maneira mais difícil: modelar a capacidade como “queries por segundo” ou usar recursos estáticos das solicitações que se acredita serem um proxy para os recursos que consomem (por exemplo, “quantas chaves as solicitações estão lendo”) geralmente leva a uma métrica ruim. Mesmo que essas métricas tenham um desempenho adequado em um determinado momento, os índices podem mudar. Às vezes, a mudança é gradual, mas às vezes a mudança é drástica (por exemplo, uma nova versão do software de repente fez com que alguns recursos de algumas solicitações exigissem significativamente menos recursos). Um dado móvel é uma métrica ruim para projetar e implementar o balanceamento de carga.
Uma solução melhor é medir a capacidade diretamente nos recursos disponíveis. Por exemplo, você pode ter um total de 500 núcleos de CPU e 1 TB de memória reservados para um determinado serviço em um determinado data center. Naturalmente, funciona muito melhor usar esses números diretamente para modelar a capacidade de um datacenter. Costumamos falar sobre o custo de uma solicitação para se referir a uma medida normalizada de quanto tempo de CPU foi consumido (em diferentes arquiteturas de CPU, levando em consideração as diferenças de desempenho).
Na maioria dos casos (embora certamente não em todos), descobrimos que simplesmente usar o consumo de CPU como sinal para provisionamento funciona bem, pelos seguintes motivos:
- Em plataformas com garbage collection, a pressão da memória se traduz naturalmente em maior consumo de CPU.
- Em outras plataformas, é possível provisionar os recursos restantes de forma que seja muito improvável que eles se esgotem antes que a CPU se esgote.
Nos casos em que o provisionamento excessivo de recursos que não são da CPU é proibitivamente caro, levamos em conta cada recurso do sistema separadamente ao considerar o consumo de recursos.
Limites por cliente
Um componente para lidar com sobrecarga é decidir o que fazer no caso de sobrecarga global. Em um mundo perfeito, onde as equipes coordenam seus lançamentos cuidadosamente com os proprietários de suas dependências de backend, a sobrecarga global nunca acontece e os serviços de backend sempre têm capacidade suficiente para atender seus clientes. Infelizmente, não vivemos em um mundo perfeito. Aqui, na realidade, a sobrecarga global ocorre com bastante frequência (especialmente para serviços internos que tendem a ter muitos clientes executados por muitas equipes).
Quando ocorre uma sobrecarga global, é vital que o serviço forneça respostas de erro apenas para clientes com comportamento inadequado, enquanto outros clientes não são afetados. Para alcançar esse resultado, os proprietários de serviços provisionam sua capacidade com base no uso negociado com seus clientes e definem cotas por cliente de acordo com esses acordos.
Por exemplo, se um serviço de backend tiver 10.000 CPUs alocadas em todo o mundo (em vários datacenters), seus limites por cliente podem ser parecidos com o seguinte:
- O Gmail pode consumir até 4.000 segundos de CPU por segundo.
- O calendário pode consumir até 4.000 segundos de CPU por segundo.
- O Android pode consumir até 3.000 segundos de CPU por segundo.
- O Google+ pode consumir até 2.000 segundos de CPU por segundo.
- Todos os outros usuários podem consumir até 500 segundos de CPU por segundo.
Observe que esses números podem somar mais de 10.000 CPUs alocadas ao serviço de backend. O proprietário do serviço está confiando no fato de que é improvável que todos os seus clientes atinjam seus limites de recursos simultaneamente.
Agregamos informações de uso global em tempo real de todas as tarefas de backend e usamos esses dados para aumentar os limites efetivos de tarefas de backend individuais. Uma análise mais detalhada do sistema que implementa essa lógica está fora do escopo desta discussão, mas escrevemos um código significativo para implementar isso em nossas tarefas de backend. Uma parte interessante do quebra-cabeça é calcular em tempo real a quantidade de recursos – especificamente CPU – consumidos por cada solicitação individual. Essa computação é particularmente complicada para servidores que não implementam um modelo de thread por solicitação, onde um pool de threads apenas executa diferentes partes de todas as solicitações à medida que elas chegam, usando APIs sem bloqueio.
Limitação do lado do cliente
Quando um cliente está fora da cota, uma tarefa de backend deve rejeitar solicitações rapidamente com a expectativa de que retornar um erro “cliente está fora da cota” consome significativamente menos recursos do que realmente processar a solicitação e fornecer uma resposta correta. No entanto, essa lógica não é válida para todos os serviços. Por exemplo, é quase tão caro rejeitar uma solicitação que requer uma pesquisa simples de RAM (onde a sobrecarga do tratamento do protocolo de solicitação/resposta é significativamente maior do que a sobrecarga de produzir a resposta) quanto aceitar e executar essa solicitação. E mesmo no caso em que a rejeição de solicitações economiza recursos significativos, essas solicitações ainda consomem alguns recursos. Se a quantidade de solicitações rejeitadas for significativa, esses números aumentarão rapidamente. Nesses casos, o backend pode ficar sobrecarregado mesmo que a grande maioria de sua CPU seja gasta apenas rejeitando solicitações!
A limitação do lado do cliente resolve esse problema. (Por exemplo, veja Doorman, que fornece um sistema de limitação do lado do cliente distribuído e cooperativo). Quando um cliente detecta que uma parte significativa de suas solicitações recentes foi rejeitada devido a erros “fora de cota”, ele inicia a autorregulação e limita a quantidade de tráfego de saída que gera. Solicitações acima do limite falham localmente sem chegar à rede.
Implementamos a limitação do lado do cliente por meio de uma técnica que chamamos de limitação adaptativa. Especificamente, cada tarefa do cliente mantém as seguintes informações nos últimos dois minutos de seu histórico:
requests
O número de solicitações tentadas pela camada de aplicativo (no cliente, em cima do sistema de limitação adaptável)
accepts
O número de solicitações aceitas pelo backend
Em condições normais, os dois valores são iguais. À medida que o backend começa a rejeitar o tráfego, o número de accepts se torna menor que o número de requests. Os clientes podem continuar a emitir solicitações para o backend até que as solicitações sejam K vezes maiores que as accepts. Uma vez que esse limite é atingido, o cliente começa a se autorregular e novas solicitações são rejeitadas localmente (ou seja, no cliente) com a probabilidade calculada no tópico abaixo, em “Probabilidade de rejeição de solicitação do cliente”.
Probabilidade de rejeição de solicitação do cliente
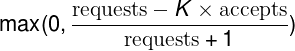
À medida que o próprio cliente começa a rejeitar solicitações, as requests continuarão a exceder as accepts. Embora possa parecer contraintuitivo, dado que as solicitações rejeitadas localmente não são propagadas para o back-end, esse é o comportamento preferencial. À medida que a taxa na qual o aplicativo tenta solicitações ao cliente cresce (em relação à taxa na qual o backend as aceita), queremos aumentar a probabilidade de descartar novas solicitações.
Para serviços em que o custo de processamento de uma solicitação é muito próximo do custo de rejeição dessa solicitação, pode ser inaceitável permitir que cerca de metade dos recursos de backend sejam consumidos por solicitações rejeitadas. Nesse caso, a solução é simples: modifique o multiplicador de aceitações K (por exemplo, por 2) na probabilidade de rejeição do pedido do cliente. Dessa maneira:
- Reduzir o multiplicador fará com que a limitação adaptativa se comporte de forma mais agressiva
- Aumentar o multiplicador fará com que a limitação adaptativa se comporte de forma menos agressiva
Por exemplo, em vez de fazer com que o cliente se autorregule quando requests = 2 * accepts, faça com que ele se autorregule quando requests = 1.1 * accepts. Reduzir o modificador para 1.1 significa que apenas uma solicitação será rejeitada pelo backend para cada 10 solicitações aceitas.
Geralmente preferimos o multiplicador 2x. Ao permitir que mais solicitações cheguem ao backend do que o esperado, desperdiçamos mais recursos no backend, mas também aceleramos a propagação do estado do backend para os clientes. Por exemplo, se o backend decidir parar de rejeitar o tráfego das tarefas do cliente, o atraso até que todas as tarefas do cliente tenham detectado essa alteração no estado será menor.
Descobrimos que a limitação adaptativa funciona bem na prática, levando a taxas estáveis de solicitações em geral. Mesmo em grandes situações de sobrecarga, os backends acabam rejeitando uma solicitação para cada solicitação que realmente processam. Uma grande vantagem dessa abordagem é que a decisão é tomada pela tarefa do cliente com base inteiramente em informações locais e usando uma implementação relativamente simples: não há dependências adicionais ou penalidades de latência.
Uma consideração adicional é que a limitação do lado do cliente pode não funcionar bem com clientes que enviam solicitações apenas esporadicamente para seus backends. Nesse caso, a visão que cada cliente tem do estado do backend é reduzida drasticamente, e abordagens para incrementar essa visibilidade tendem a ser caras.
Criticidade
A criticidade é outra noção que achamos muito útil no contexto de cotas globais e limitação. Uma solicitação feita a um backend é associada a um dos quatro possíveis valores de criticidade, dependendo de quão crítica consideramos essa solicitação:
CRITICAL_PLUS
Reservado para as solicitações mais críticas, aquelas que resultarão em sério impacto visível ao usuário se falharem.
CRITICAL
O valor padrão para solicitações enviadas de trabalhos de produção. Essas solicitações resultarão em impacto visível ao usuário, mas o impacto pode ser menos grave do que os de CRITICAL_PLUS. Espera-se que os serviços forneçam capacidade suficiente para todo o tráfego CRITICAL e CRITICAL_PLUS esperado.
SHEDDABLE_PLUS
Tráfego para a qual a indisponibilidade parcial é esperada. Esse é o padrão para trabalhos em lote, que podem repetir as solicitações minutos ou até horas depois.
SHEDDABLE
Tráfego para o qual se espera indisponibilidade parcial frequente e indisponibilidade total ocasional.
Descobrimos que quatro valores eram suficientemente robustos para modelar quase todos os serviços. Tivemos várias discussões sobre propostas para agregar mais valores, porque isso nos permitiria classificar as solicitações com mais precisão. No entanto, definir valores adicionais exigiria mais recursos para operar vários sistemas com reconhecimento de criticidade.
Fizemos da criticidade uma noção de primeira classe do nosso sistema RPC e trabalhamos duro para integrá-la em muitos de nossos mecanismos de controle para que ela possa ser levada em consideração ao reagir a situações de sobrecarga. Por exemplo:
- Quando um cliente fica sem cota global, uma tarefa de backend só rejeitará solicitações de uma determinada criticidade se já estiver rejeitando todas as solicitações de todas as criticidades mais baixas (na verdade, os limites por cliente que nosso sistema suporta, descritos anteriormente, podem ser definidos por criticidade).
- Quando uma tarefa está sobrecarregada, ela rejeitará solicitações de menor criticidade mais cedo.
- O sistema de limitação adaptável também mantém estatísticas separadas para cada criticidade.
A criticidade de uma solicitação é ortogonal aos seus requisitos de latência e, portanto, à qualidade de serviço (QoS) da rede subjacente usada. Por exemplo, quando um sistema exibe resultados de pesquisa ou sugestões enquanto o usuário está digitando uma query de pesquisa, as solicitações subjacentes são altamente descartáveis (se o sistema estiver sobrecarregado, é aceitável não exibir esses resultados), mas tendem a ter requisitos de latência rigorosos.
Também ampliamos significativamente nosso sistema RPC para propagar a criticidade automaticamente. Se um backend receber a solicitação A e, como parte da execução desta solicitação, emitir a solicitação de saída B e a solicitação C para outros backends, a solicitação B e a solicitação C usarão a mesma criticidade que a solicitação A por padrão.
No passado, muitos sistemas do Google desenvolveram suas próprias noções ad hoc de criticidade que muitas vezes eram incompatíveis entre os serviços. Ao padronizar e propagar a criticidade como parte de nosso sistema RPC, agora podemos definir a criticidade de forma consistente em pontos específicos. Isso significa que podemos ter certeza de que as dependências sobrecarregadas cumprirão a criticidade de alto nível desejada à medida que rejeitam o tráfego, independentemente da profundidade da pilha RPC em que estejam. Nossa prática é, portanto, definir a criticidade o mais próximo possível dos navegadores ou clientes móveis – normalmente nos frontends HTTP que produzem o HTML a ser retornado – e apenas substituir a criticidade em casos específicos onde faça sentido em pontos específicos da pilha.
Sinais de utilização
Nossa implementação de proteção de sobrecarga em nível de tarefa é baseada na noção de utilização. Em muitos casos, a utilização é apenas uma medida da taxa de CPU (ou seja, a taxa de CPU atual dividida pelo total de CPUs reservadas para a tarefa), mas em alguns casos também levamos em consideração medidas como a parte da memória reservada que está sendo usada atualmente. À medida que a utilização se aproxima dos limites configurados, começamos a rejeitar solicitações com base em sua criticidade (limites mais altos para criticidades mais altas).
Os sinais de utilização que usamos são baseados no estado local da tarefa (já que o objetivo dos sinais é proteger a tarefa) e temos implementações para vários sinais. O sinal mais útil geralmente é baseado na “carga” no processo, que é determinada usando um sistema que chamamos de média de carga do executor (executor load average).
Para encontrar a média de carga do executor, contamos o número de threads ativas no processo. Nesse caso, “ativo” refere-se a threads que estão atualmente em execução ou prontas para serem executadas e aguardando um processador livre. Suavizamos esse valor com decaimento exponencial e começamos a rejeitar solicitações à medida que o número de threads ativas cresce além do número de processadores disponíveis para a tarefa. Isso significa que uma solicitação de entrada que tem um fan-out muito grande (ou seja, um que agenda um número muito grande de operações de curta duração) fará com que a carga aumente muito brevemente, mas a suavização engolirá esse pico. No entanto, se as operações não forem de curta duração (ou seja, a carga aumentar e permanecer alta por um período significativo de tempo), a tarefa começará a rejeitar solicitações.
Embora a média de carga do executor tenha provado ser um sinal muito útil, nosso sistema pode conectar qualquer sinal de utilização que um determinado backend possa precisar. Por exemplo, podemos usar a pressão de memória — que indica se o uso de memória em uma tarefa de backend cresceu além dos parâmetros operacionais normais — como outro possível sinal de utilização. O sistema também pode ser configurado para combinar vários sinais e rejeitar requisições que ultrapassem os limites de utilização combinados (ou individuais).
Lidando com erros de sobrecarga
Além de lidar com a carga normalmente, pensamos bastante em como os clientes devem reagir quando receberem uma resposta de erro relacionada à carga. No caso de erros de sobrecarga, distinguimos duas situações possíveis:
Um grande subconjunto de tarefas de backend no datacenter está sobrecarregado.
Se o sistema de balanceamento de carga entre datacenters estiver funcionando perfeitamente (ou seja, ele pode propagar o estado e reagir instantaneamente às mudanças no tráfego), essa condição não ocorrerá.
Um pequeno subconjunto de tarefas de backend no datacenter está sobrecarregado.
Essa situação geralmente é causada por imperfeições no balanceamento de carga dentro do datacenter. Por exemplo, uma tarefa pode ter recebido muito recentemente uma requisição muito cara. Nesse caso, é muito provável que o datacenter tenha capacidade restante em outras tarefas para lidar com a requisição.
Se um grande subconjunto de tarefas de backend no datacenter estiver sobrecarregado, as requisições não devem ser repetidas e os erros devem aparecer até o caller (“chamador”) – por exemplo, retornar um erro ao usuário final. É muito mais comum que apenas uma pequena parte das tarefas fique sobrecarregada e, nesse caso, a resposta preferencial é tentar novamente a solicitação imediatamente. Em geral, nosso sistema de balanceamento de carga entre datacenters tenta direcionar o tráfego dos clientes para os datacenters de backend disponíveis mais próximos. Em alguns casos, o datacenter mais próximo está longe (por exemplo, um cliente pode ter seu backend disponível mais próximo em um continente diferente), mas geralmente conseguimos situar os clientes perto de seus backends. Dessa forma, a latência adicional de tentar novamente uma solicitação – apenas algumas viagens de ida e volta da rede – tende a ser insignificante.
Do ponto de vista de nossas políticas de balanceamento de carga, novas tentativas de solicitações são indistinguíveis de novas solicitações. Ou seja, não usamos nenhuma lógica explícita para garantir que uma nova tentativa vá para uma tarefa de backend diferente; contamos apenas com a probabilidade provável de que a nova tentativa chegue a uma tarefa de backend diferente simplesmente em virtude do número de backends participantes no subconjunto. Garantir que todas as tentativas realmente sigam para uma tarefa diferente incorreria em mais complexidade em nossas APIs do que vale a pena.
Mesmo que um backend esteja apenas levemente sobrecarregado, uma solicitação de cliente geralmente é melhor atendida se o backend rejeitar novas tentativas e novas requisições de maneira igual e rápida. Essas requisições podem ser repetidas imediatamente em uma tarefa de backend diferente que pode ter recursos extras. A consequência de tratar tentativas e novas solicitações de forma idêntica no backend é que repetir solicitações em diferentes tarefas se torna uma forma orgânica de balanceamento de carga: isso redireciona a carga para tarefas que podem ser mais adequadas para essas solicitações.
Decidindo tentar novamente
Quando um cliente recebe uma resposta de erro “tarefa sobrecarregada” (“task overloaded”), ele precisa decidir se tenta novamente a solicitação. Temos alguns mecanismos implementados para evitar novas tentativas quando uma parte significativa das tarefas em um cluster estiver sobrecarregada.
Primeiro, implementamos um orçamento de repetição por requisição de até três tentativas. Se uma solicitação já falhou três vezes, deixamos a falha borbulhar no caller. A lógica é que, se uma solicitação já foi recebida em tarefas sobrecarregadas três vezes, é relativamente improvável que tentar novamente ajude porque todo o datacenter provavelmente está sobrecarregado.
Em segundo lugar, implementamos um orçamento de repetição por cliente. Cada cliente acompanha a proporção de solicitações que correspondem a novas tentativas. Uma solicitação só será repetida enquanto essa proporção estiver abaixo de 10%. A lógica é que, se apenas um pequeno subconjunto de tarefas estiver sobrecarregado, haverá relativamente pouca necessidade de tentar novamente.
Como exemplo concreto (do pior cenário), vamos supor que um datacenter está aceitando uma pequena quantidade de requisições e rejeitando uma grande parte das solicitações. Sendo X a taxa total de requisições tentadas contra o datacenter de acordo com a lógica do lado do cliente. Devido ao número de tentativas que ocorrerão, o número de requisições aumentará significativamente, para um pouco abaixo de 3X. Embora tenhamos efetivamente limitado o crescimento causado por novas tentativas, um aumento de três vezes nas requisições é significativo, especialmente se o custo de rejeitar versus processar uma requisição for considerável. No entanto, colocar camadas no orçamento de repetição por cliente (uma taxa de repetição de 10%) reduz o crescimento para apenas 1.1x no caso geral – uma melhoria significativa.
Uma terceira abordagem faz com que os clientes incluam um contador de quantas vezes a solicitação já foi tentada nos metadados da requisição. Por exemplo, o contador começa em 0 na primeira tentativa e é incrementado a cada nova tentativa até atingir 2, quando o orçamento por requisição faz com que ele pare de ser repetido. Os backends mantêm histogramas desses valores no histórico recente. Quando um backend precisa rejeitar uma requisição, ele consulta esses histogramas para determinar a probabilidade de que outras tarefas de backend também estejam sobrecarregadas. Se esses histogramas revelarem uma quantidade significativa de tentativas (indicando que outras tarefas de backend provavelmente também estão sobrecarregadas), eles retornarão uma resposta de erro “sobrecarregado; não tente novamente” (overloaded; don’t retry) em vez do erro padrão “tarefa sobrecarregada” (task overloaded) que aciona novas tentativas.
A figura abaixo mostra o número de tentativas em cada solicitação recebida por uma determinada tarefa de backend em várias situações de exemplo, em uma sliding window (correspondendo a 1.000 requisições iniciais, sem contar as tentativas). Para simplificar, o orçamento de repetição por cliente é ignorado (ou seja, esses números pressupõem que o único limite para novas tentativas é o orçamento de repetição de três tentativas por requisição) e a subconfiguração pode alterar um pouco esses números.
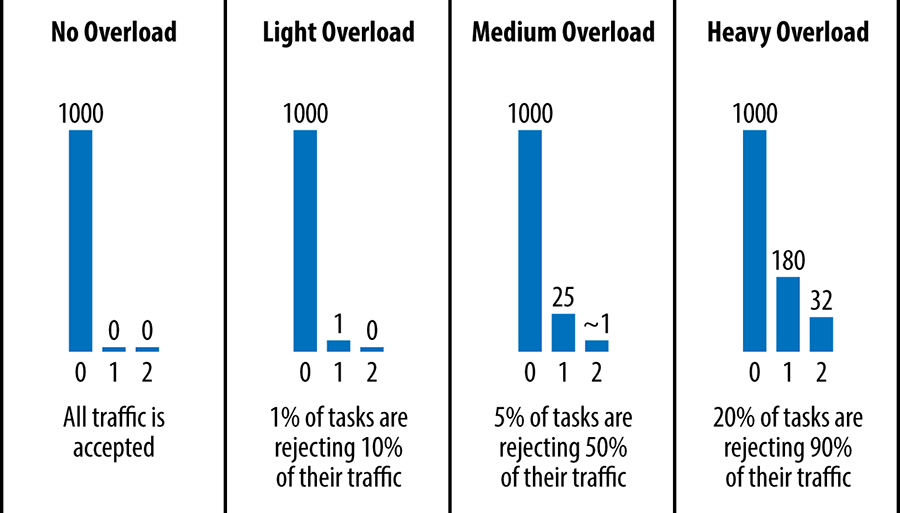
[Figura] – Legenda: Histogramas de tentativas em várias condições
Nossos serviços maiores tendem a ser pilhas profundas de sistemas, que por sua vez podem ter dependências entre si. Nessa arquitetura, as solicitações devem ser repetidas apenas na camada imediatamente acima da camada que as estiver rejeitando. Quando decidimos que uma determinada solicitação não pode ser atendida e não deve ser repetida, usamos um erro “sobrecarregado; não tente novamente” (overloaded; don’t retry) e, assim, evitamos uma explosão de novas tentativas combinatórias.
Considere o exemplo da figura abaixo (na prática, nossas pilhas costumam ser significativamente mais complexas). Imagine que o DB Frontend esteja sobrecarregado e rejeite uma requisição. Nesse caso:
- O backend B tentará novamente a solicitação de acordo com as diretrizes anteriores.
- No entanto, uma vez que o Backend B determina que a solicitação para o DB Frontend não pode ser atendida (por exemplo, porque a solicitação já foi tentada e rejeitada três vezes), o Backend B deve retornar ao Backend A com um “overloaded; don’ t retry” ou com uma resposta degradada (assumindo que pode produzir alguma resposta moderadamente útil mesmo quando sua solicitação ao DB Frontend falhar).
- O backend A tem exatamente as mesmas opções para a solicitação que recebeu do frontend e procede de acordo.
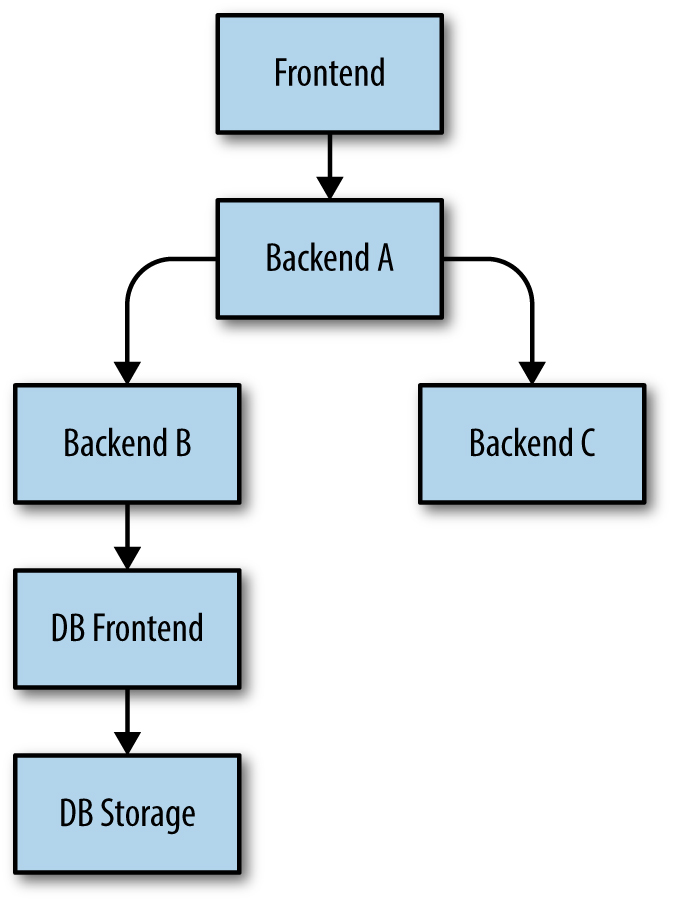
[Figura] – Legenda: Uma pilha de dependências
O ponto chave é que uma requisição com falha do DB Frontend só deve ser tentada novamente pelo Backend B, a camada imediatamente acima dele. Se várias camadas tentassem novamente, teríamos uma explosão combinatória.
Carregar a partir das conexões
A carga associada às conexões é um último fator que merece destaque. Às vezes, levamos em consideração apenas a carga nos back-ends que é causada diretamente pelas solicitações que eles recebem (que é um dos problemas com abordagens que modelam a carga com base em queries por segundo). No entanto, isso ignora os custos de CPU e memória de manter um grande conjunto de conexões ou o custo de uma taxa rápida de rotatividade de conexões. Esses problemas são insignificantes em sistemas pequenos, mas rapidamente se tornam problemáticos ao executar sistemas RPC de grande escala.
Conforme mencionado anteriormente, nosso protocolo RPC exige que clientes inativos realizem verificações periódicas de integridade. Depois que uma conexão estiver ociosa por um período configurável, o cliente descarta sua conexão TCP e alterna para UDP para verificação de integridade. Infelizmente, esse comportamento é problemático quando você tem um número muito grande de tarefas de cliente que emitem uma taxa muito baixa de solicitações: a verificação de integridade das conexões pode exigir mais recursos do que realmente atender às requisições. Abordagens como ajustar cuidadosamente os parâmetros de conexão (por exemplo, diminuir significativamente a frequência das verificações de integridade) ou até mesmo criar e destruir as conexões dinamicamente podem melhorar significativamente essa situação.
O tratamento de explosões de novas solicitações de conexão é um segundo (mas relacionado) problema. Vimos explosões desse tipo acontecerem no caso de trabalhos em lotes muito grandes, que criam um número muito grande de tarefas de cliente em funcionamento de uma só vez. A necessidade de negociar e manter um número excessivo de novas conexões simultaneamente pode sobrecarregar facilmente um grupo de backends. Em nossa experiência, existem algumas estratégias que podem ajudar a mitigar essa carga:
– Exponha a carga ao algoritmo de balanceamento de carga entre datacenters (por exemplo, balanceamento de carga base na utilização do cluster, em vez de apenas no número de solicitações). Nesse caso, a carga das solicitações é efetivamente rebalanceada para outros datacenters que têm capacidade ociosa.
– Obrigue que os trabalhos de cliente em lote usem um conjunto separado de tarefas de proxy de backend em lote que não fazem nada além de encaminhar solicitações para os backends subjacentes e entregar suas respostas aos clientes de maneira controlada. Portanto, em vez de “cliente em lote → backend”, você tem “cliente em lote → proxy em lote → backend”. Nesse caso, quando o trabalho muito grande é iniciado, apenas o trabalho de proxy em lote sofre, protegendo os backends reais (e clientes de prioridade mais alta). Efetivamente, o proxy de lote atua como uma espécie de fusível. Outra vantagem de usar o proxy é que ele normalmente reduz o número de conexões em relação ao backend, o que pode melhorar o balanceamento de carga em relação ao backend (por exemplo, as tarefas de proxy podem usar subconjuntos maiores e provavelmente ter uma visão melhor do estado do backend tarefas).
Conclusões
Este capítulo e o Capítulo 20 discutiram como várias técnicas (subconjunto determinístico, Round Robin ponderado, limitação do lado do cliente, cotas de clientes etc.) podem ajudar a distribuir a carga pelas tarefas em um datacenter de maneira relativamente uniforme. No entanto, esses mecanismos dependem da propagação do estado em um sistema distribuído. Embora eles tenham um desempenho razoavelmente bom no caso geral, a aplicação no mundo real resultou em um pequeno número de situações em que eles funcionam de maneira imperfeita.
Como resultado, consideramos crítico garantir que as tarefas individuais sejam protegidas contra sobrecarga. Para simplificar: uma tarefa de backend provisionada para atender a uma determinada taxa de tráfego deve continuar a atender o tráfego a essa taxa sem nenhum impacto significativo na latência, independentemente de quanto tráfego em excesso seja lançado na tarefa. Como corolário, a tarefa de backend não deve cair e falhar sobre a carga. Essas declarações devem ser verdadeiras até uma determinada taxa de tráfego – algo acima de 2x ou até 10x do que a tarefa está provisionada para processar. Aceitamos que pode haver um certo ponto em que um sistema começa a entrar em colapso, e aumentar o limite em que esse colapso ocorre torna-se relativamente difícil de alcançar.
A chave é levar a sério essas condições de degradação. Quando essas condições de degradação são ignoradas, muitos sistemas apresentarão um comportamento terrível. E à medida que o trabalho se acumula e as tarefas acabam ficando sem memória e travam (ou acabam queimando quase toda a CPU na memória), a latência sofre à medida que o tráfego é descartado e as tarefas competem por recursos. Deixada desmarcada, a falha em um subconjunto de um sistema (como uma tarefa de backend individual) pode desencadear a falha de outros componentes do sistema, potencialmente causando a falha de todo o sistema (ou um subconjunto considerável). O impacto desse tipo de falha em cascata pode ser tão grave que é fundamental para qualquer sistema que opere em escala se proteger contra isso; consulte o Capítulo 22.
É um erro comum supor que um backend sobrecarregado deve ser desativado e parar de aceitar todo o tráfego. No entanto, essa suposição na verdade vai contra o objetivo de balanceamento de carga robusto. Na verdade, queremos que o backend continue aceitando o máximo de tráfego possível, mas apenas aceite essa carga à medida que a capacidade for liberada. Um backend bem comportado, suportado por políticas robustas de balanceamento de carga, deve aceitar apenas as solicitações que puder processar, e rejeitar o restante normalmente.
Embora tenhamos uma vasta gama de ferramentas para implementar um bom balanceamento de carga e proteções contra sobrecarga, não existe uma bala mágica: o balanceamento de carga geralmente requer uma compreensão profunda de um sistema e da semântica de suas solicitações. As técnicas descritas neste capítulo evoluíram de acordo com as necessidades de muitos sistemas do Google e provavelmente continuarão a evoluir à medida que a natureza de nossos sistemas continuar a mudar.
Fonte: Google SRE Book