Escrito por Jess Frame, Anthony Lenton, Steven Thurgood,
Anton Tolchanov, e Nejc Trdin
Com Carmela Quinito
O monitoramento pode incluir muitos tipos de dados, incluindo métrica, log de texto, log de eventos estruturados, rastreamento distribuído, e introspecção de eventos. Embora todas estas abordagens sejam úteis por si só, este capítulo aborda principalmente a métrica e o log estruturado. Na nossa experiência, estas duas fontes de dados são as mais adequadas para as necessidades fundamentais de monitoramento do SRE.
No nível mais básico, o monitoramento permite que você obtenha visibilidade em um sistema, que é um requisito básico para avaliar a integridade do serviço e diagnosticar seu serviço quando as coisas dão errado. O capítulo 6 do primeiro livro do SRE fornece algumas definições básicas de monitoramento e explica que os SREs monitoram os seus sistemas para:
- Alertar sobre as condições que requerem atenção.
- Investigar e diagnosticar esses problemas.
- Mostrar, visualmente, informação sobre o sistema.
- Obter informações das tendências de utilização de recursos ou integridade dos serviços para planejamento a longo prazo.
- Comparar o comportamento do sistema antes e depois de uma mudança, ou entre dois grupos em um experimento.
A importância relativa destes casos de utilização pode levá-lo a fazer tradeoffs ao selecionar ou construir um sistema de monitoramento.
Este capítulo fala sobre como o Google gerencia os sistemas de monitoramento e fornece algumas diretrizes para dúvidas que podem surgir ao escolher e executar um sistema de monitoramento.
Características desejáveis de uma estratégia de monitoramento
Ao escolher um sistema de monitoramento, é importante compreender e dar prioridade às características que são importantes para você. Se você estiver avaliando diferentes sistemas de monitoramento, os atributos nesta seção podem ajudar a orientar sua reflexão sobre qual(is) solução(ões) melhor atende(m) às suas necessidades. Se já tem uma estratégia de monitoramento, poderá considerar a utilização de algumas capacidades adicionais da sua solução atual. Dependendo de suas necessidades, um sistema de monitoramento pode atender a todos os seus casos de uso, ou poderá querer utilizar uma combinação de sistemas.
Velocidade
Diferentes organizações terão necessidades diferentes quando se trata de atualização de dados e velocidade de recuperação de dados.
Os dados devem estar disponíveis quando você precisar deles: a atualização afeta o tempo que seu sistema de monitoramento levará para avisar você quando algo der errado. Além disso, a lentidão dos dados pode levá-lo a agir acidentalmente em dados incorretos. Por exemplo, durante a resposta a incidentes, se o tempo entre a causa (executar uma ação) e o efeito (ver essa ação refletida em seu monitoramento) for muito longo, você pode presumir que uma alteração não teve efeito ou deduzir uma falsa correlação entre causa e efeito. Dados com mais de quatro a cinco minutos de atraso podem ter um impacto significativo na rapidez com que se pode responder a um incidente.
Se você estiver selecionando um sistema de monitoramento com base nesses critérios, precisará descobrir seus requisitos de velocidade com antecedência. A velocidade de recuperação de dados é principalmente um problema quando você está consultando grandes quantidades de dados. Pode levar algum tempo para um gráfico carregar se tiver que registrar muitos dados de muitos sistemas monitorados. Para acelerar os seus gráficos mais lentos, é útil se o sistema de monitoramento puder criar e armazenar novas séries temporais baseadas em dados recebidos; depois pode pré-computar respostas para consultas comuns.
Cálculos
O suporte para cálculos pode abranger uma variedade de casos de uso, em uma série de complexidades. No mínimo, é provável que queira que o seu sistema retenha dados durante um período de tempo de vários meses. Sem uma visão a longo prazo dos seus dados, não poderá analisar tendências a longo prazo como o crescimento do sistema. Em termos de granularidade, dados resumidos (ou seja, dados agregados que você não pode detalhar) são suficientes para facilitar o planejamento do crescimento. A manutenção de todas as métricas individuais detalhadas pode ajudar a responder a perguntas como, “Este comportamento incomum já aconteceu antes?”. No entanto, os dados podem ser caros para armazenar ou impraticáveis para recuperar.
As métricas que você retém sobre eventos ou consumo de recursos devem, idealmente, ser contadores de incremento monotônico. Utilizando contadores, seu sistema de monitoramento pode calcular funções em janela ao longo do tempo, por exemplo, para relatar a taxa de solicitações por segundo desse contador. A computação destas taxas numa janela mais longa (até um mês) permite-lhe implementar os blocos de construção para alertas baseados em queimas de SLO (ver Capítulo 5 ).
Finalmente, o suporte para uma gama mais completa de funções estatísticas pode ser útil porque operações triviais podem mascarar o mau comportamento. Um sistema de monitoramento que suporta percentis de computação (ou seja, 50º, 95º, 99º percentis) ao registrar a latência permitirá que você veja se 50%, 5% ou 1% de suas solicitações são muito lentas, enquanto a média aritmética só pode dizer— sem detalhes — que o tempo de solicitação é mais lento. Em alternativa, se o seu sistema não suportar diretamente percentis de computação, você pode conseguir isto:
- Obter um valor médio somando os segundos gastos em requisições e dividindo pelo número de requisições
- Registrar todas as solicitações e computar os valores percentuais por meio da verificação ou amostragem das entradas de log
Você pode querer registrar seus dados brutos de métrica em um sistema separado para análise offline, por exemplo, para usar em relatórios semanais ou mensais ou para realizar cálculos mais complexos que são muito difíceis de computar em seu sistema de monitoramento.
Interfaces
Um sistema robusto de monitoramento deve permitir que você exiba dados de séries temporais de forma concisa em gráficos, e também a estruturação de dados em tabelas ou numa gama de estilos de gráficos. Os seus dashboards serão interfaces primárias para exibir o monitoramento, por isso é importante que escolha os formatos que mais claramente exibam os dados de seu interesse. Algumas opções incluem heatmaps, histogramas, e gráficos de escala logarítmica.
É provável que tenha que oferecer diferentes visões dos mesmos dados com base no público; a gestão de alto nível pode querer ver informações bastante diferentes das dos SREs. Seja específico quanto à criação de dashboards que façam sentido para as pessoas que consomem o conteúdo. Para cada conjunto de dashboards, a exibição consistente dos mesmos tipos de dados é valiosa para a comunicação.
Talvez seja necessário representar graficamente informações em diferentes agregações de uma métrica, como tipo de máquina, versão do servidor ou tipo de solicitação, em tempo real. É uma boa ideia que a sua equipe se sinta confortável com a realização de detalhamentos ad hoc nos seus dados. Ao dividir os seus dados de acordo com uma variedade de métricas, você pode procurar correlações e padrões nos dados quando precisar deles.
Alertas
É útil poder classificar os alertas: múltiplas categorias de alertas permitem respostas proporcionais. A capacidade de definir diferentes níveis de gravidade para diferentes alertas também é útil: você pode arquivar um ticket para investigar uma baixa taxa de erros que dura mais de uma hora, enquanto uma taxa de erro de 100% é uma emergência que merece resposta imediata.
A funcionalidade de supressão de alertas permite evitar ruídos desnecessários que distraem os engenheiros de plantão. Por exemplo:,
- Quando todos os nós estão apresentando a mesma alta taxa de erros, você pode alertar apenas uma vez para a taxa de erro global em vez de enviar um alerta individual para cada nó.
- Quando uma das suas dependências de serviço tem um alerta de disparo (por exemplo, um backend lento), você não precisa alertar para a taxa de erro do seu serviço.
Também é necessário poder assegurar que os alertas deixem de ser suprimidos quando o evento tiver terminado.
O nível de controle que você precisa sobre seu sistema determinará se você usa um serviço de monitoramento de terceiros ou implementa e executa seu próprio sistema de monitoramento. A Google desenvolveu o seu próprio sistema de monitoramento internamente, mas há muitos sistemas de monitoramento de código aberto e comerciais disponíveis.
Fontes de dados de monitoramento
A sua escolha do(s) sistema(s) de monitoramento será informada pelas fontes específicas de dados de monitoramento que irá utilizar. Esta seção discute duas fontes comuns de dados de monitoramento: logs e métricas. Existem outras fontes de monitoramento valiosas que não abordaremos aqui, como rastreamento distribuído e introspecção em tempo de execução.
As métricas são medições numéricas que representam atributos e eventos, normalmente colhidos através de muitos pontos de dados em intervalos regulares de tempo. Os logs são um registro de eventos append-only. A discussão deste capítulo se concentra em logs estruturados que permitem ferramentas avançadas de consulta e agregação em oposição a logs de texto simples.
Os sistemas baseados em logs do Google processam grandes volumes de dados altamente granulares. Há algum atraso inerente entre quando um evento ocorre e quando é visível nos logs. Para análises que não são sensíveis ao tempo, estes logs podem ser processados com um sistema em lote, interrogados com consultas ad hoc, e visualizados com dashboards. Um exemplo deste fluxo de trabalho seria utilizar o Cloud Dataflow para processar logs, o BigQuery para consultas ad hoc, e Data Studio para os dashboards.
Em contrapartida, o nosso sistema de monitoramento baseado em métricas, que coleta um grande número de métricas de cada serviço no Google, fornece muito menos informação granular, mas em tempo quase real. Estas características são bastante típicas de outros sistemas de monitoramento baseados em logs e métricas, embora existam exceções, tais como sistemas de logs em tempo real ou métricas de alta cardinalidade.
Os nossos alertas e dashboards utilizam tipicamente métricas. A natureza em tempo real do nosso sistema de monitoramento baseado em métricas significa que os engenheiros podem ser notificados de problemas muito rapidamente. Tendemos a utilizar os logs para encontrar a causa raiz de um problema, uma vez que a informação de que necessitamos não está muitas vezes disponível como métrica.
Quando a elaboração de relatórios não é sensível ao tempo, muitas vezes geramos relatórios detalhados utilizando sistemas de processamento de logs, porque os logs produzirão quase sempre dados mais precisos do que a métrica.
Se estiver alertando com base em métricas, pode ser tentador adicionar mais alertas com base em logs – por exemplo, se precisar ser notificado quando ocorrer mesmo um único evento excepcional. Ainda recomendamos alertas baseados em métricas em tais casos: pode incrementar uma contra-medição quando um determinado evento acontece, e configurar um alerta com base no valor dessa métrica. Esta estratégia mantém toda a configuração de alerta num único local, facilitando a sua gestão (ver Gerir o seu Sistema de Monitoramento).
Exemplos
Os seguintes exemplos do mundo real ilustram como raciocinar através do processo de escolha entre sistemas de monitoramento.
Mover a informação dos logs para a métrica
Problema. O código de status HTTP é um sinal importante para os clientes do App Engine depurarem os seus erros. Esta informação estava disponível em logs, mas não em métricas. O dashboard de métricas podia fornecer apenas uma taxa global de todos os erros, e não incluía qualquer informação sobre o código exato do erro ou a causa do erro. Como resultado, o fluxo de trabalho para depurar um problema envolveu:
- Olhar para o gráfico de erro global para encontrar o momento em que ocorreu um erro.
- Ler arquivos de log para procurar linhas contendo um erro.
- Tentar correlacionar erros no arquivo de log com o gráfico.
As ferramentas de log não davam uma noção de escala, tornando difícil saber se um erro visto numa linha de log estava ocorrendo frequentemente. Os logs também continham muitas outras linhas irrelevantes, o que tornava difícil encontrar a causa raiz.
Solução proposta. A equipe de desenvolvimento do App Engine escolheu exportar o código de status HTTP como rótulo na métrica (por exemplo, requests_total{status=404} versus requests_total{status=500}). Como o número de diferentes códigos de status HTTP é relativamente limitado, isto não aumentou o volume de dados métricos para um tamanho impraticável, mas tornou os dados mais pertinentes disponíveis para gráficos e alertas.
Resultado. Este novo rótulo significava que a equipe poderia atualizar os gráficos para mostrar linhas separadas para diferentes categorias e tipos de erros. Os clientes podiam agora rapidamente formar conjecturas sobre possíveis problemas com base nos códigos de erro expostos. Poderíamos agora também definir diferentes limiares de alerta para erros de clientes e servidores, fazendo com que os alertas disparassem com maior precisão.
Melhorar tanto os logs como as métricas
Problema. Uma equipe de Anúncios SRE manteve ~50 serviços, que foram escritos em várias linguagens e estruturas diferentes. A equipe utilizou os logs como fonte canônica da verdade para a conformidade com o SLO. Para calcular o orçamento de erros, cada serviço utilizou um script de processamento de logs com muitos casos especiais específicos do serviço. Aqui está um script de exemplo para processar uma entrada de log para um único serviço:
Se o código de status HTTP estava no intervalo (500, 599)
AND o campo ‘SERVER ERROR’ do log é preenchido
AND o cookie DEBUG não foi definido como parte da solicitação
AND o URL não continha ‘/reports’
AND o campo ‘exception’ não continha ‘com.google.ads.PasswordException’
THEN incremente o contador de erros em 1
Estes scripts eram difíceis de manter e também utilizavam dados que não estavam disponíveis para o sistema de monitoramento baseado em métricas. Uma vez que a métrica conduzia os alertas, por vezes os alertas não correspondiam a erros orientado para o usuário. Cada alerta exigia uma etapa de triagem explícita para determinar se estava orientado para o usuário, o que tornava o tempo de resposta mais lento.
Solução proposta. A equipe criou uma biblioteca que se ligou à lógica das linguagens de estrutura de cada aplicação. A biblioteca decidiu se o erro estava afetando os usuários no momento da solicitação. A instrumentação escreveu esta decisão em logs e a exportou como uma métrica ao mesmo tempo, melhorando a consistência. Se a métrica mostrasse que o serviço havia retornado um erro, os logs conteriam o erro exato, juntamente com dados relacionados à solicitação para ajudar a reproduzir e depurar o problema. Da mesma forma, qualquer erro com impacto no SLO que se manifestasse nos logs também alterava as métricas do SLI, sobre as quais a equipe poderia alertar.
Resultado. Ao introduzir uma superfície de controle uniforme em múltiplos serviços, a equipe reutilizou ferramentas e lógica de alerta em vez de implementar múltiplas soluções personalizadas. Todos os serviços se beneficiaram da remoção do complicado código de processamento de logs específico do serviço, o que resultou numa maior escalabilidade. Uma vez que os alertas estavam diretamente ligados aos SLOs, eram mais claramente acionáveis, de modo que a taxa de falsos positivos diminuiu significativamente.
Manter logs como a fonte de dados
Problema. Enquanto investigava questões de produção, uma equipe do SRE geralmente examinava as IDs de entidade afetadas para determinar o impacto do usuário e a causa raiz. Tal como no exemplo anterior do App Engine, esta investigação exigia dados que só estavam disponíveis em logs. A equipe tinha que realizar consultas pontuais aos logs para o efeito enquanto respondia a incidentes. Esta etapa acrescentou tempo para a recuperação de incidentes: alguns minutos para montar corretamente a consulta, mais o tempo para consultar os logs.
Solução proposta. A equipe debateu inicialmente se uma métrica deveria substituir as suas ferramentas de log. Ao contrário do exemplo do App Engine, o ID da entidade poderia assumir milhões de valores diferentes, portanto, não seria prático como rótulo de métrica.
Em última análise, a equipe decidiu escrever um script para realizar as consultas de log pontuais de que necessitavam, e documentou qual o script a executar nos e-mails de alerta. Poderiam então copiar o comando diretamente para um terminal, se necessário.
Resultado. A equipe já não tinha a carga cognitiva de gerir a consulta de log pontual correta. Consequentemente, podiam obter os resultados de que necessitavam mais rapidamente (embora não tão rapidamente como uma abordagem baseada em métricas). Também tinham um plano de backup: podiam executar o script automaticamente assim que um alerta fosse disparado, e utilizar um pequeno servidor para consultar os logs em intervalos regulares para recuperar dados seminovos constantemente.
Gerenciando seu sistema de monitoramento
O seu sistema de monitoramento é tão importante como qualquer outro serviço que gere. Como tal, deve ser tratado com o nível adequado de cuidado e atenção.
Trate a sua configuração como código
Tratar a configuração do sistema como código e armazená-la no sistema de controle de revisão são práticas comuns que proporcionam alguns benefícios óbvios: histórico de alterações, ligações de alterações específicas ao seu sistema de rastreamento de tarefas, rollbacks e verificações de linting mais fáceis, e procedimentos de revisão de códigos aplicados.
Recomendamos fortemente que trate também a configuração de monitoramento como código (para mais informações sobre configuração, ver Capítulo 14). Um sistema de monitoramento que suporta configuração baseada em intenção é preferível aos sistemas que apenas fornecem UIs da web ou APIs ao estilo CRUD. Esta abordagem de configuração é padrão para muitos binários de código aberto que apenas lêem um arquivo de configuração. Algumas soluções de terceiros, como a grafanalib, permitem esta abordagem para componentes que são tradicionalmente configurados com uma UI.
Incentivar a Consistência
Grandes empresas com múltiplas equipes de engenharia que utilizam o monitoramento precisam encontrar um bom equilíbrio: uma abordagem centralizada proporciona consistência, mas por outro lado, equipes individuais podem querer ter controle total sobre o design de sua configuração.
A solução certa depende da sua organização. A abordagem do Google evoluiu ao longo do tempo em direção à convergência em uma única estrutura executada centralmente como um serviço. Esta solução funciona bem para nós, por algumas razões. Uma estrutura única permite que os engenheiros acelerem mais rapidamente quando trocam de equipe, e facilita a colaboração durante a depuração. Também temos um serviço de dashboards centralizado, onde os dashboards de cada equipe são detectáveis e acessíveis. Se compreender facilmente o dashboard de outra equipe, pode depurar tanto os seus problemas como os deles mais rapidamente.
Se possível, torne a cobertura básica de monitoramento sem esforço. Se todos os seus serviços exportarem um conjunto consistente de métricas básicas, você poderá coletar automaticamente essas métricas em toda a sua organização e fornecer um conjunto consistente de dashboards. Esta abordagem significa que qualquer novo componente que lançar automaticamente tem monitoramento básico. Muitas equipes em toda a sua empresa – mesmo que não sejam equipes de engenharia – podem utilizar estes dados de monitoramento.
Prefira Acoplamento Solto
As necessidades das empresas mudam, e o seu sistema de produção terá um aspecto diferente daqui a um ano. Da mesma forma, o seu sistema de monitoramento precisa evoluir ao longo do tempo, à medida que os serviços monitorados evoluem por meio de diferentes padrões de falha.
Recomendamos que mantenha os componentes do seu sistema de monitoramento acoplados de forma solta. Deverá ter interfaces estáveis para configurar cada componente e passar os dados de monitoramento. Os componentes separados devem ser responsáveis por coletar, armazenar, alertar e visualizar seu monitoramento. Interfaces estáveis facilitam a troca de um determinado componente por uma melhor alternativa.
A divisão da funcionalidade em componentes individuais está se tornando popular no mundo do código aberto. Há uma década, sistemas de monitoramento como o Zabbix combinavam todas as funções em um único componente. O design moderno geralmente envolve a separação de coleta e avaliação de regras (com uma solução como o servidor Prometheus), armazenamento de séries temporais de longo prazo (InfluxDB), agregação de alertas (Alertmanager), e dashboarding (Grafana).
No momento da redação deste artigo, existem pelo menos dois padrões abertos populares para instrumentar seu software e expor métricas:
statsd
O daemon de agregação métrica inicialmente escrito por Etsy e agora portado para uma maioria de linguagens de programação.
Prometheus
Uma solução de monitoramento de código aberto com um modelo de dados flexível, suporte para rótulos de métricas, e funcionalidade robusta de histograma. Outros sistemas estão adotando o formato Prometheus, e está sendo padronizado como OpenMetrics.
Um sistema de dashboard separado que pode utilizar múltiplas fontes de dados fornece uma visão geral central e unificada do seu serviço. O Google viu recentemente este benefício na prática: o nosso sistema de monitoramento antigo (Borgmon3) combinou dashboards na mesma configuração das regras de alerta. Ao migrar para um novo sistema (Monarch), decidimos mudar o dashboard para um serviço separado (Viceroy). Como o Viceroy não era um componente do Borgmon ou do Monarch, o Monarch tinha menos requisitos funcionais. Uma vez que os usuários podiam utilizar o Viceroy para exibir gráficos baseados em dados de ambos os sistemas de monitoramento, podiam migrar gradualmente do Borgmon para o Monarch.
Métricas com Finalidade
Alertar sobre SLOs aborda como monitorar e alertar usando métricas de SLI quando o orçamento de erro de um sistema está sob ameaça. As métricas SLI são as primeiras métricas que se pretende verificar quando os alertas baseados em SLO disparam. Estas métricas devem aparecer com destaque no dashboard do seu serviço, idealmente em sua página de destino.
Ao investigar a causa de uma violação de SLO, muito provavelmente não obterá informação suficiente dos dashboards de SLO. Estes dashboards mostram que você está violando o SLO, mas não necessariamente o motivo. Que outros dados devem exibir os dashboards de monitoramento?
Consideramos as seguintes diretrizes úteis na implementação de métricas. Estas métricas devem fornecer um monitoramento razoável que lhe permita investigar questões de produção e também fornecer uma vasta gama de informações sobre o seu serviço.
Alterações Pretendidas
Ao diagnosticar um alerta baseado em SLO, você precisa ser capaz de passar de métricas de alerta que notificam sobre problemas que afetam o usuário para métricas que informam o que está causando esses problemas. As mudanças recentes no seu serviço podem estar com falhas. Adicione monitoramento que informa sobre quaisquer alterações na produção. Para determinar o gatilho, recomendamos o seguinte:
- Monitorar a versão do binário.
- Monitorar os sinalizadores de linha de comando, especialmente quando você usa esses sinalizadores para ativar e desativar as características do serviço.
- Se os dados de configuração forem enviados para seu serviço dinamicamente, monitore a versão dessa configuração dinâmica.
Se alguma dessas partes do sistema não tiver versão, você poderá monitorar o carimbo de data/hora em que foi compilado ou empacotado pela última vez.
Quando se tenta correlacionar uma interrupção com uma implementação, é muito mais fácil ver um gráfico/dashboard vinculado ao seu alerta do que vasculhar os logs do sistema CI/CD (integração contínua/entrega contínua) após o fato.
Dependências
Mesmo que o seu serviço não tenha mudado, qualquer uma das suas dependências pode mudar ou ter problemas, por isso deve também monitorar as respostas provenientes de dependências diretas.
É razoável exportar o tamanho da solicitação e da resposta em bytes, latência, e códigos de resposta para cada dependência. Ao escolher a métrica para o gráfico, tenha em mente os quatro sinais de ouro. É possível utilizar rótulos adicionais nas métricas para as decompor por código de resposta, nome do método RPC (chamada de procedimento remoto), e nome do trabalho de mesmo nível.
Idealmente, pode instrumentar a biblioteca cliente RPC de nível inferior para exportar estas métricas uma vez, em vez de solicitar a cada biblioteca cliente RPC que as exporte. Instrumentar a biblioteca cliente fornece mais consistência e permite monitorar novas dependências gratuitamente.
Às vezes, você encontrará dependências que oferecem uma API muito restrita, onde todas as funcionalidades estão disponíveis por meio de um único RPC chamado Get, Query ou algo igualmente inútil, e o comando real é especificado como argumentos para esse RPC. Um único ponto de instrumentação na biblioteca do cliente fica aquém deste tipo de dependência: irá observar uma alta variação na latência e alguma percentagem de erros que podem ou não indicar que alguma parte desta API opaca está falhando completamente. Se essa dependência for crítica, você tem algumas opções para monitorá-la bem:
- Exportar métricas separadas para adaptar à dependência, para que as métricas possam descompactar as solicitações recebidas para obter o sinal real.
- Pedir aos proprietários de dependência que efetuem uma reescrita para exportar uma API mais ampla que suporte uma funcionalidade separada dividida em serviços e métodos RPC separados.
Saturação
Tenha como objetivo monitorar e rastrear o uso de todos os recursos dos quais o serviço depende. Alguns recursos têm limites rígidos que você não pode exceder, como cota de RAM, disco ou CPU alocada à sua aplicação. Outros recursos — como descritores de arquivos abertos, threads ativos em qualquer pool de threads, tempos de espera em filas ou o volume de logs gravados — podem não ter um limite rígido claro, mas ainda exigem gerenciamento.
Dependendo da linguagem de programação em uso, você deve monitorar recursos adicionais:
- Em Java: O tamanho da pilha e do meta-espaço, e métricas mais específicas, dependendo do tipo de coleta de lixo que você está usando
- Em Go: O número de goroutinos
As próprias linguagens fornecem suporte variado para rastrear esses recursos.
Além de alertar sobre eventos significativos, conforme descrito em Alerta em SLOs, você também pode precisar configurar alertas que sejam acionados quando você se aproximar do esgotamento de recursos específicos, como:
- Quando o recurso tem um limite rígido
- Quando ultrapassar um limiar de utilização causa degradação do desempenho
Deverá ter métricas de monitoramento para rastrear todos os recursos – mesmo os recursos que o serviço gerencia bem. Estas métricas são vitais no planejamento da capacidade e dos recursos.
Status do tráfego servido
É uma boa ideia adicionar métricas ou rótulos de métricas que permitam que os dashboards decomponham o tráfego servido por código de status (a menos que as métricas que o seu serviço utiliza para fins de SLI já incluam esta informação). Aqui estão algumas recomendações:
- Para tráfego HTTP, monitore todos os códigos de resposta, mesmo que não forneçam sinal suficiente para alertar, pois alguns podem ser acionados por comportamento incorreto do cliente.
- Se aplicar limites de taxa ou de cota a seus usuários, monitore os agregados de quantas solicitações foram negadas devido à falta de cota.
Os gráficos destes dados podem ajudá-lo a identificar quando o volume de erros muda visivelmente durante uma mudança de produção.
Implementação de Métricas Intencionais
Cada métrica exposta deve servir a um propósito. Resista à tentação de exportar um punhado de métricas apenas porque são fáceis de gerar. Em vez disso, pense em como estas métricas serão utilizadas. O design da métrica, ou a sua falta, tem implicações.
Idealmente, os valores de métrica usados para alertar mudam drasticamente apenas quando o sistema entra em um estado problemático, e não mudam quando um sistema está funcionando normalmente. Por outro lado, as métricas para a depuração não têm estes requisitos – elas têm como objetivo fornecer informações sobre o que está acontecendo quando os alertas são acionados. Uma boa métrica de depuração apontará para algum aspecto do sistema que está potencialmente causando problemas. Quando escrever um post-mortem, pense em que métricas adicionais lhe teriam permitido diagnosticar o problema mais rapidamente.
Lógica de Alerta de Teste
Em um mundo ideal, o código de monitoramento e alerta deveria estar sujeito aos mesmos padrões de teste que o desenvolvimento de código. Enquanto os desenvolvedores do Prometheus estão discutindo o desenvolvimento de testes de unidade para monitoramento, atualmente não existe um sistema amplamente adotado que lhe permita fazer isso.
No Google, testamos nosso monitoramento e alertas usando uma linguagem específica de domínio que nos permite criar séries temporais sintéticas. Em seguida, escrevemos asserções com base nos valores em uma série temporal derivada ou no status de disparo e na presença de rótulos de alertas específicos.
Monitorar e alertar é frequentemente um processo em várias fases, o que exige, portanto, múltiplas famílias de testes de unidade. Embora esta área permaneça largamente subdesenvolvida, caso se pretenda implementar testes de monitoramento em algum momento, recomendamos uma abordagem em três camadas, como mostrado na Figura 4-1.
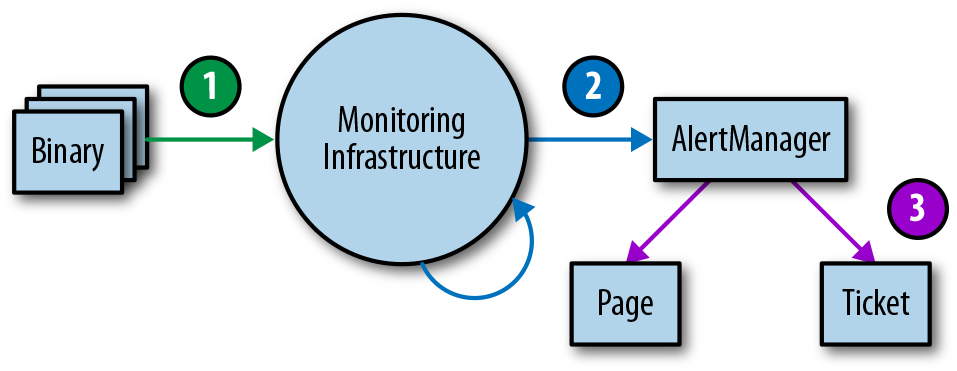
Figura 4-1. Monitoramento das camadas do ambiente de teste
- Relatórios binários: Verificar se as variáveis de métrica exportadas mudam de valor sob certas condições, como esperado.
- Configurações de monitoramento: Assegurar que a avaliação das regras produz os resultados esperados, e que as condições específicas produzem os alertas esperados.
- Configurações de alerta: Testar se os alertas gerados são roteados para um destino predeterminado, com base nos valores do rótulo de alerta.
Se não puder testar seu monitoramento através de meios sintéticos, ou se houver uma fase do seu monitoramento que simplesmente não pode testar, considere a criação de um sistema em funcionamento que exporte métricas bem conhecidas, como o número de solicitações e erros. Pode utilizar este sistema para validar séries temporais derivadas e alertas. É muito provável que as suas regras de alerta não disparem durante meses ou anos depois de as configurar, e você precisa ter certeza de que, quando a métrica ultrapassar um determinado limite, os engenheiros corretos serão alertados com notificações que fazem sentido.
Conclusão
Como a função do SRE é responsável pela confiabilidade dos sistemas em produção, os SREs geralmente precisam estar intimamente familiarizados com o sistema de monitoramento de um serviço e seus recursos. Sem este conhecimento, os SREs podem não saber onde procurar, como identificar comportamentos anormais, ou como encontrar a informação de que necessitam durante uma emergência.
Esperamos que, ao apontar as características do sistema de monitoramento que consideramos úteis e por quê, possamos ajudá-lo a avaliar o quão bem a sua estratégia de monitoramento se adapta às suas necessidades, explorar algumas características adicionais que poderá ser capaz de aproveitar, e considerar mudanças que poderá querer fazer. Provavelmente achará útil combinar alguma fonte de métrica e log na sua estratégia de monitoramento; a combinação exata de que necessita é altamente dependente do contexto. Certifique-se de coletar métricas que atendem a um propósito específico. Esse objetivo pode ser permitir um melhor planejamento da capacidade, ajudar na depuração, ou notificá-lo diretamente sobre problemas.
Uma vez que o monitoramento esteja implementado, ele precisa ser visível e útil. Para este fim, recomendamos também que teste a sua configuração de monitoramento. Um bom sistema de monitoramento paga dividendos. Vale a pena o investimento para pensar bastante nas soluções que melhor respondem às suas necessidades, e para iterar até que o faça corretamente.