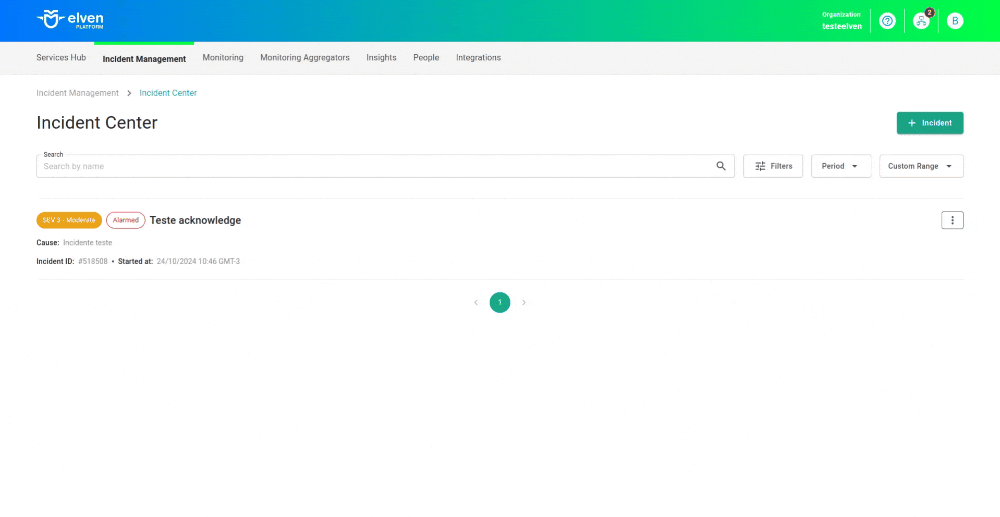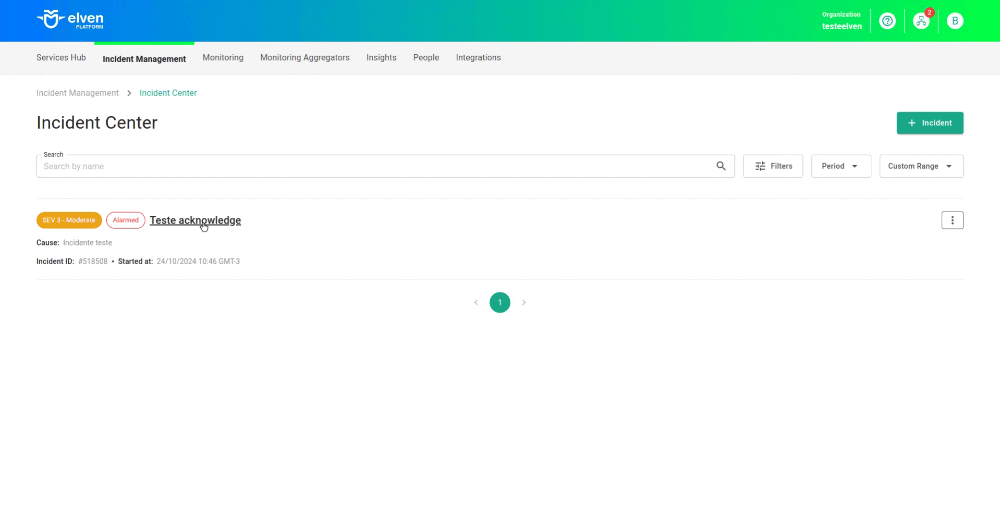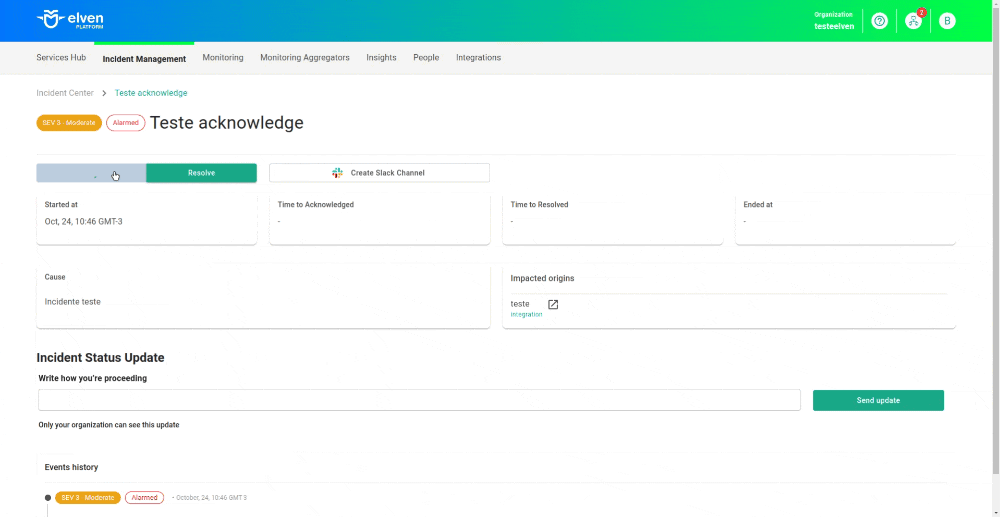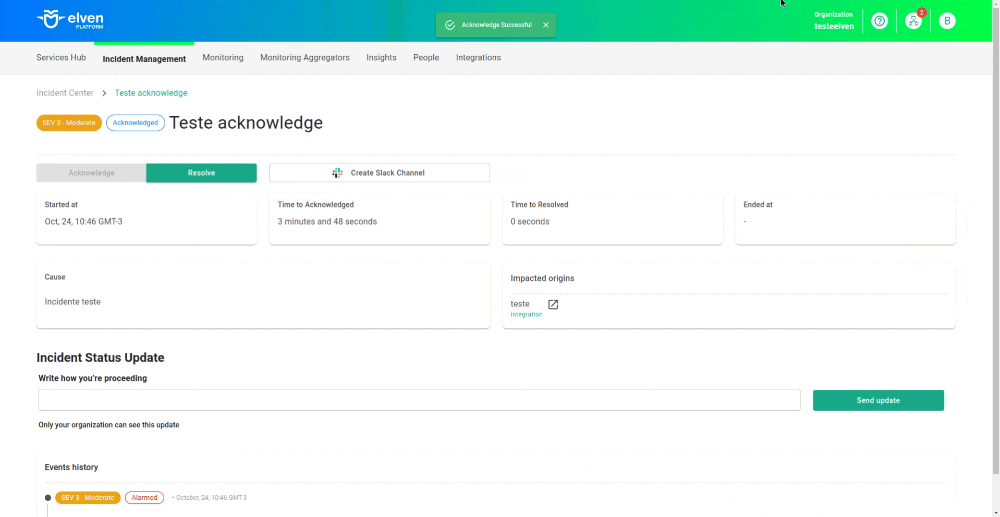
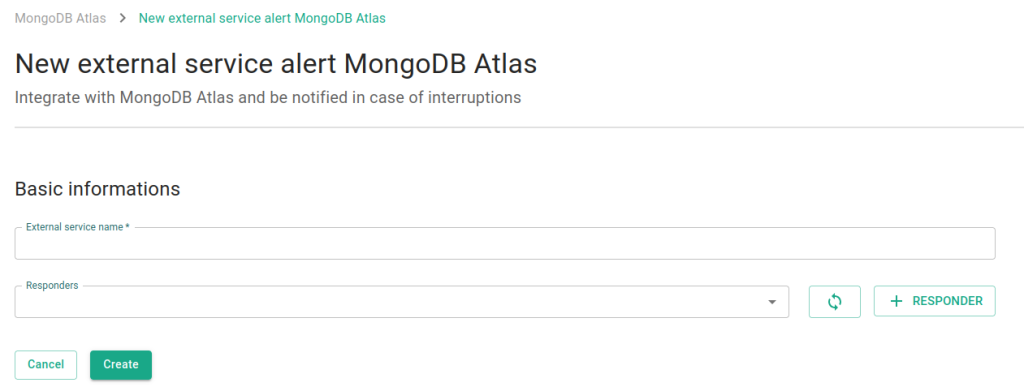
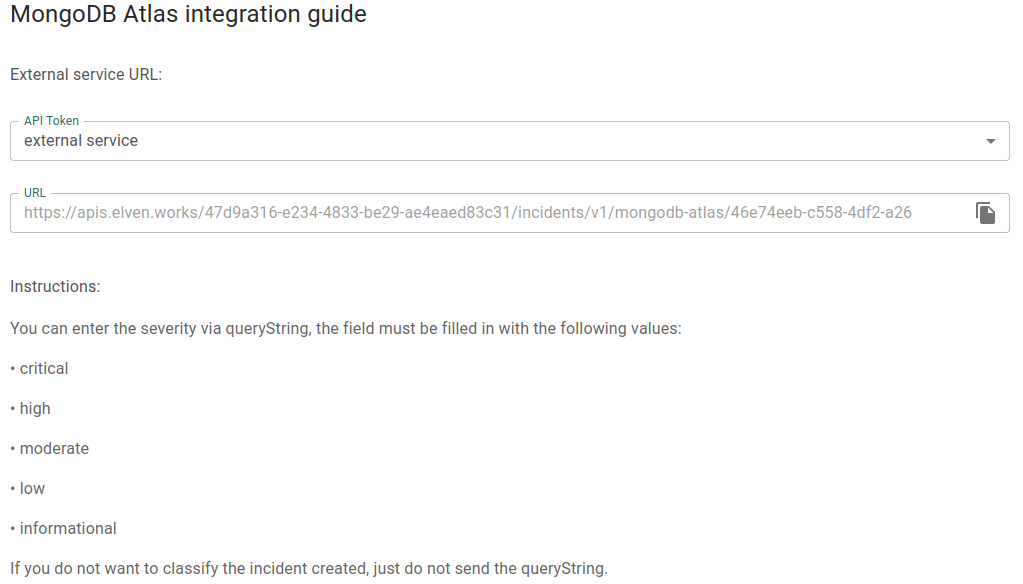
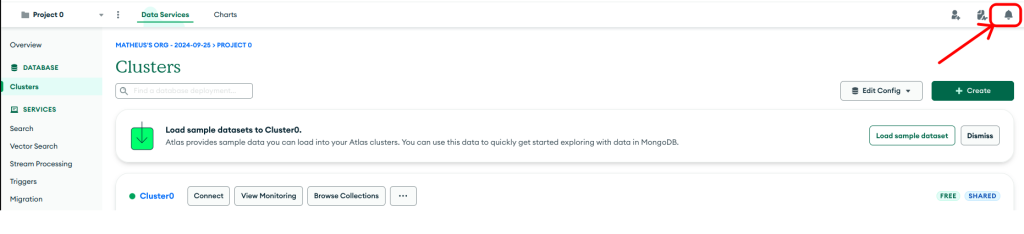
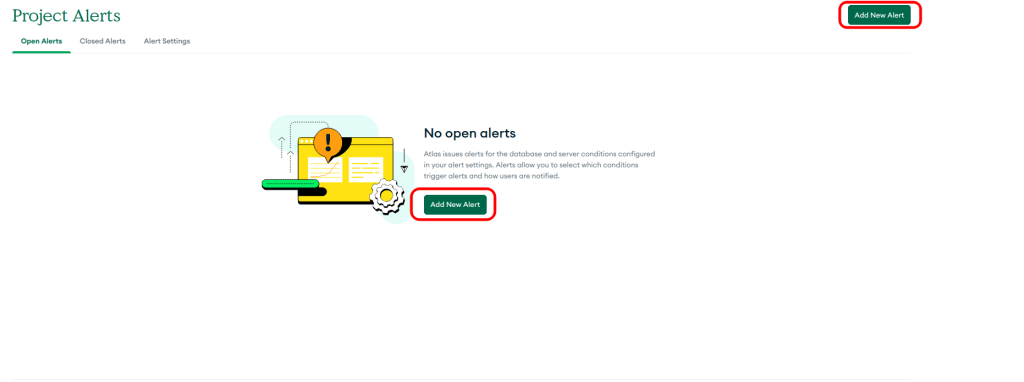
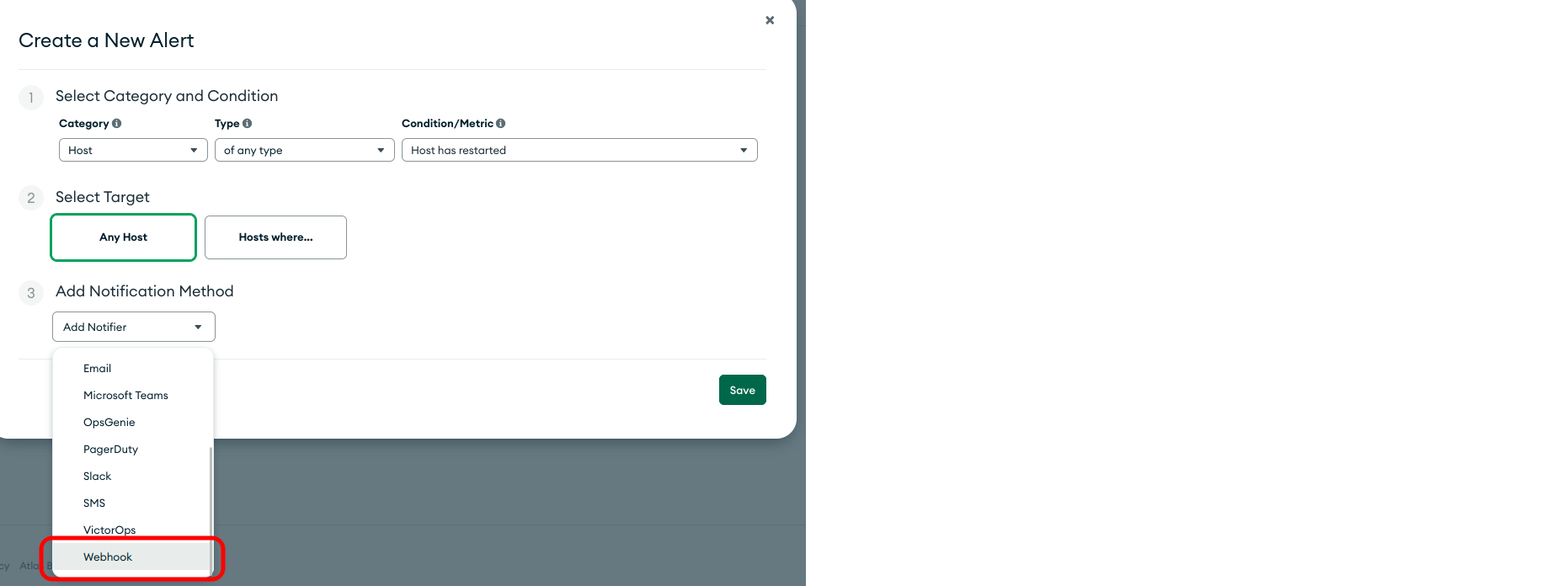
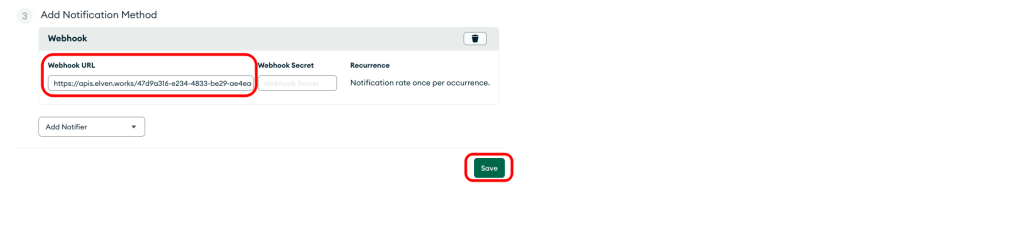
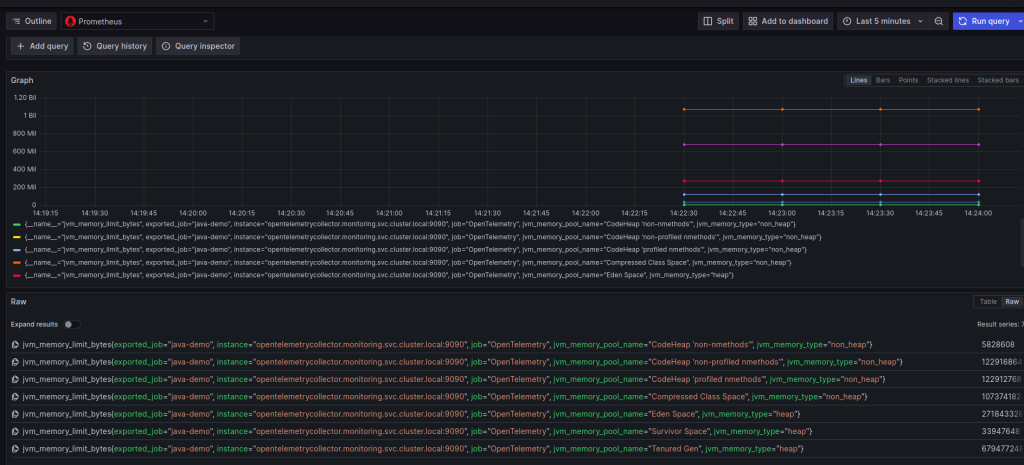
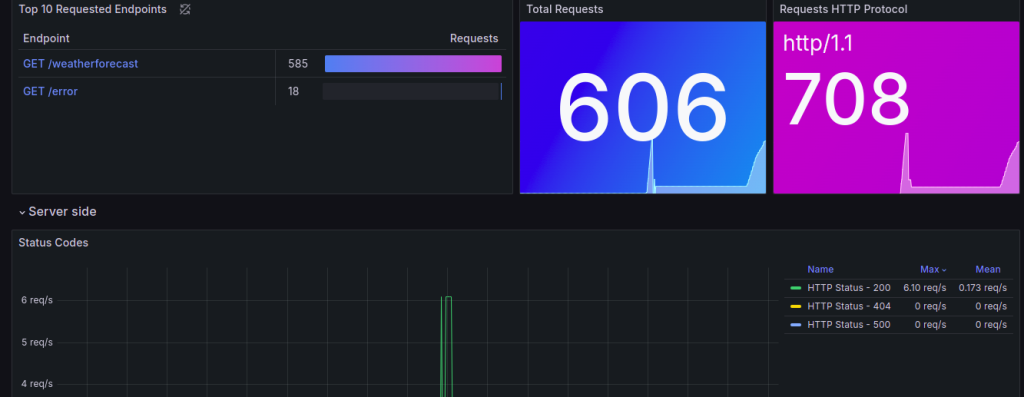
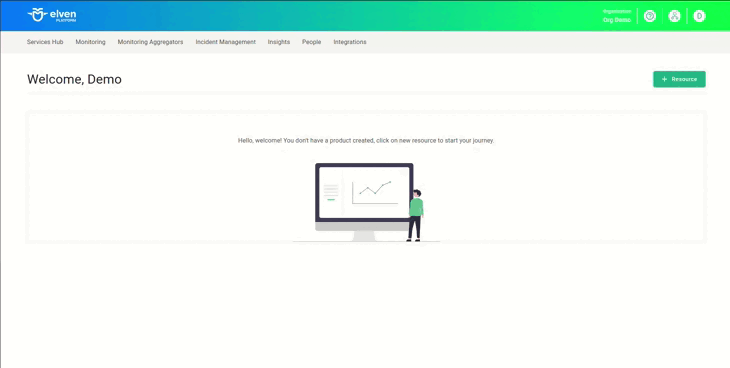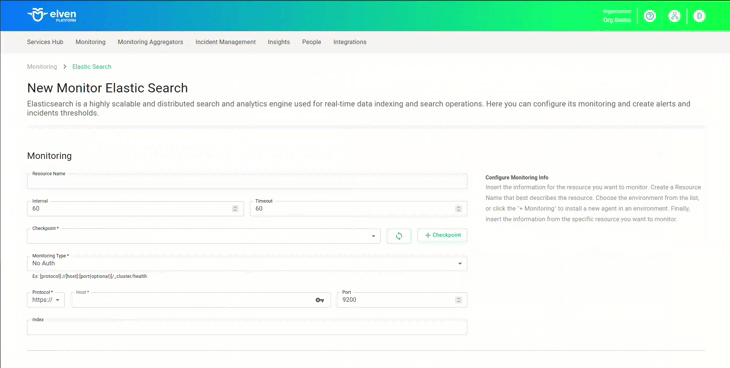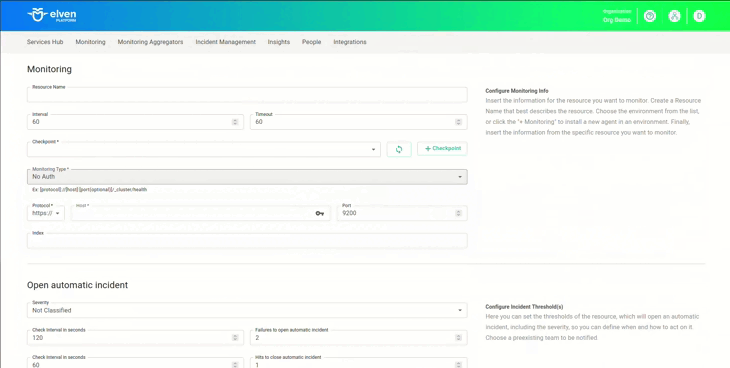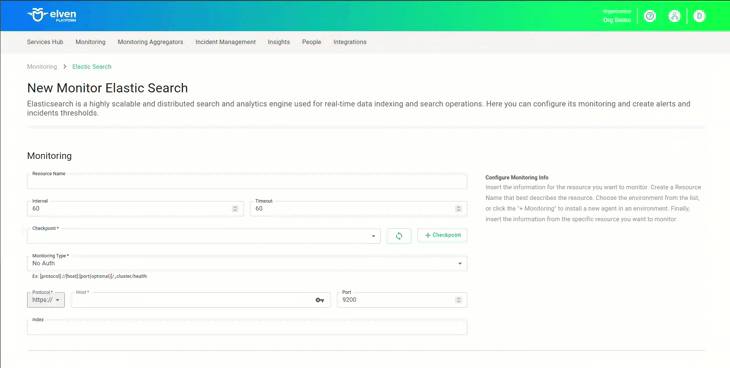
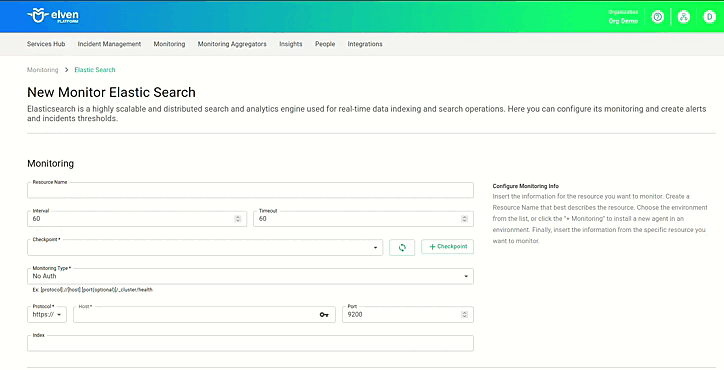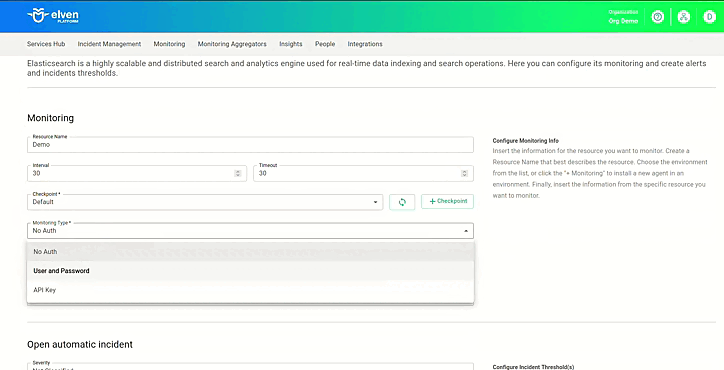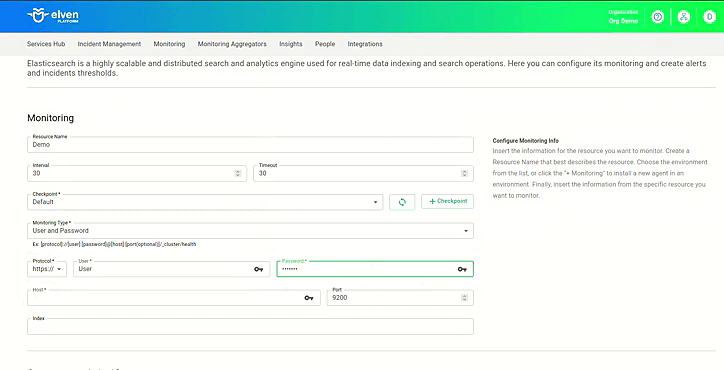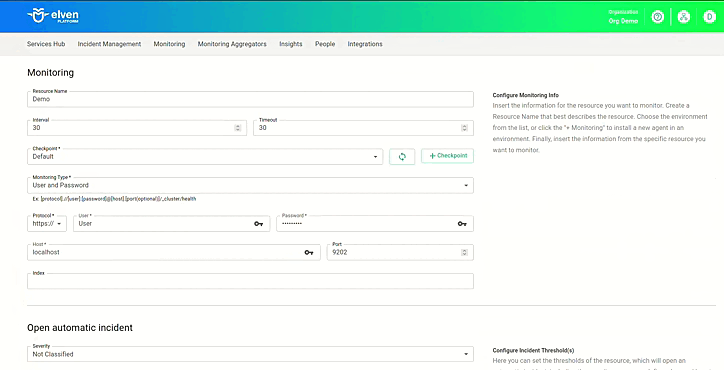
Adicionar anotações a implantações existentes
O passo final é optar por seus serviços para instrumentação automática. Isso é feito atualizando seus serviços spec.template.metadata.annotations para incluir uma anotação específica do idioma:
.NET: instrumentation.opentelemetry.io/inject-dotnet: “true”
Go: instrumentation.opentelemetry.io/inject-go: “true”
Java: instrumentation.opentelemetry.io/inject-java: “true”
Node.js: instrumentation.opentelemetry.io/inject-nodejs: “true”
Python: instrumentation.opentelemetry.io/inject-python: “true”
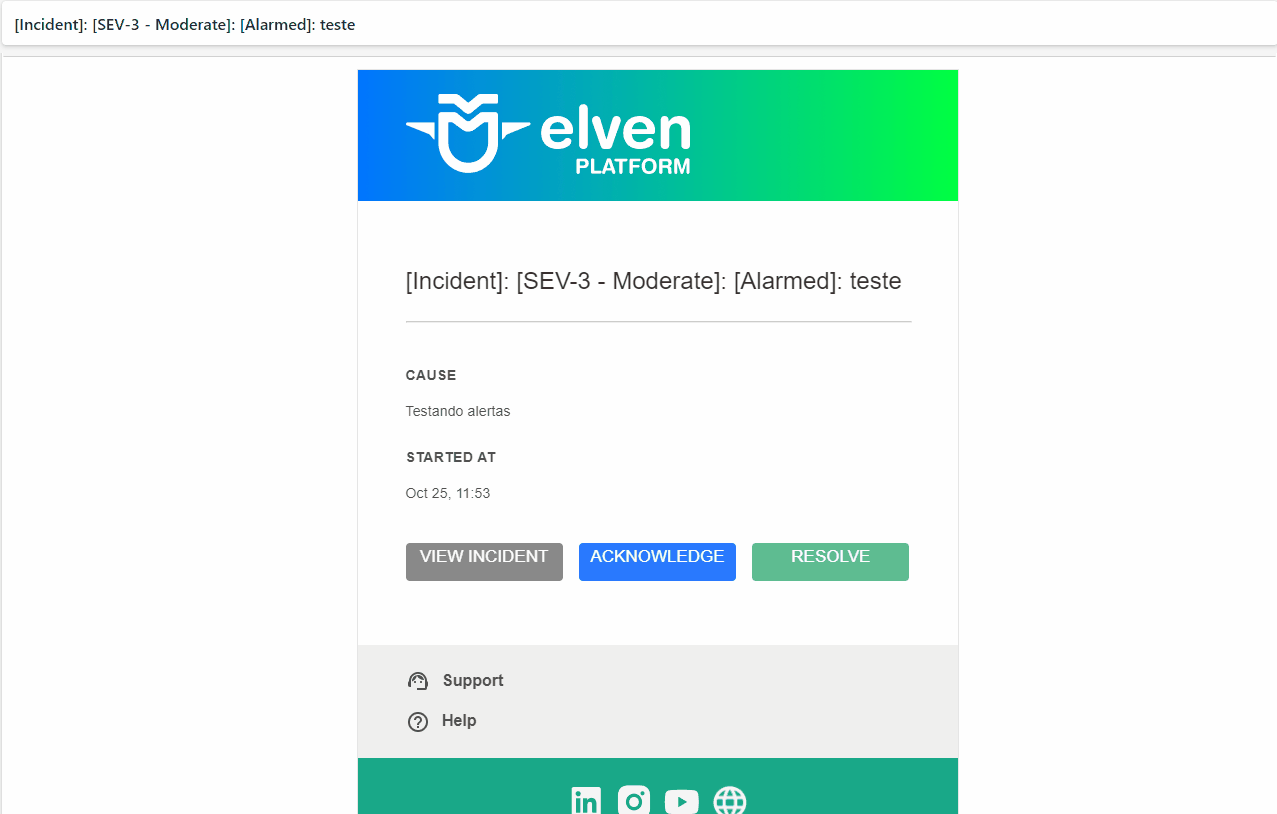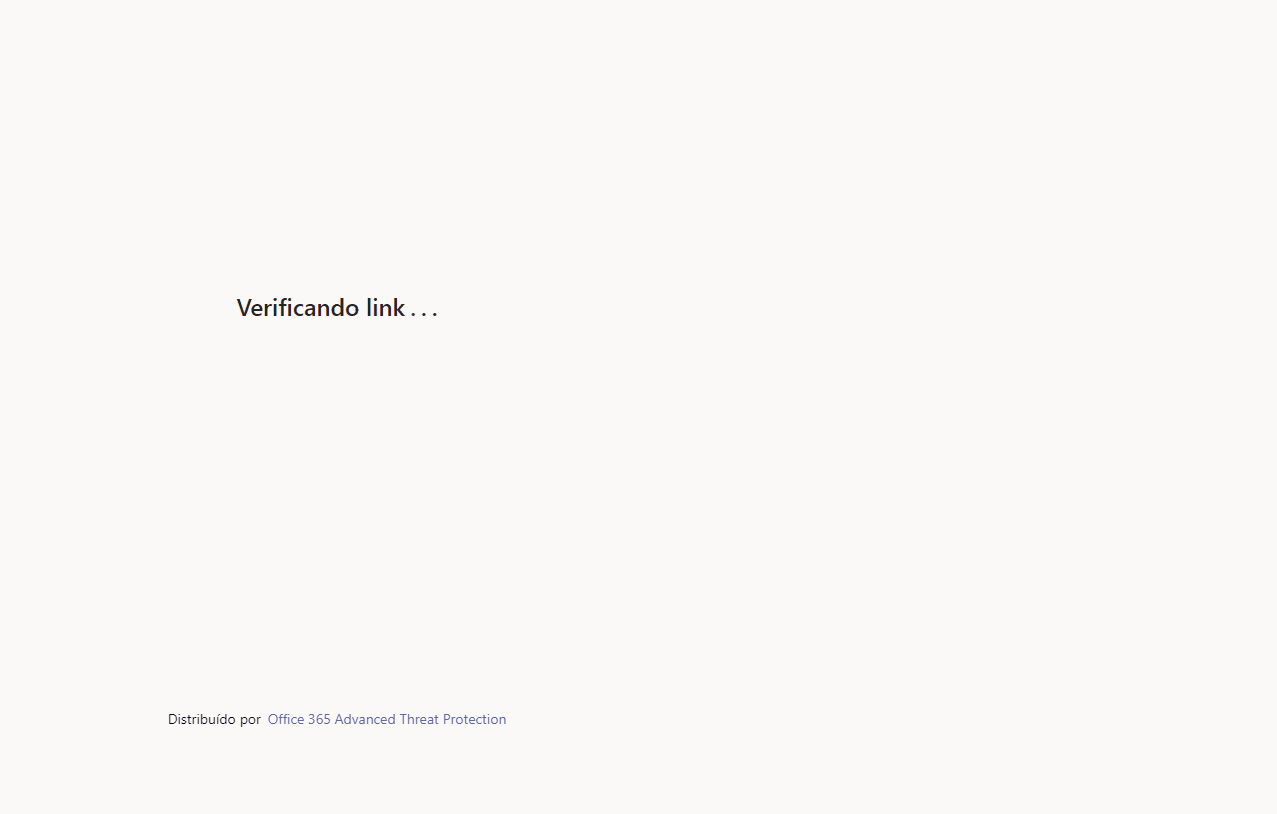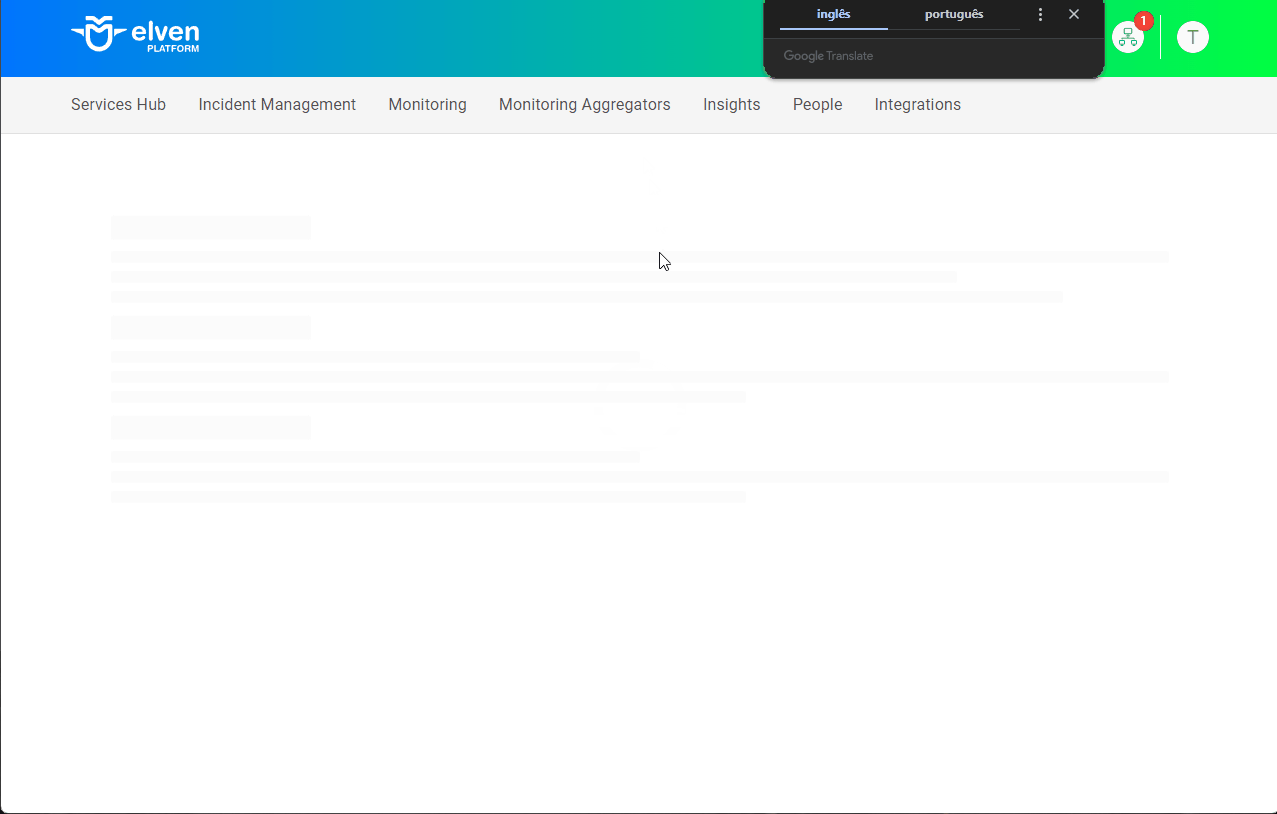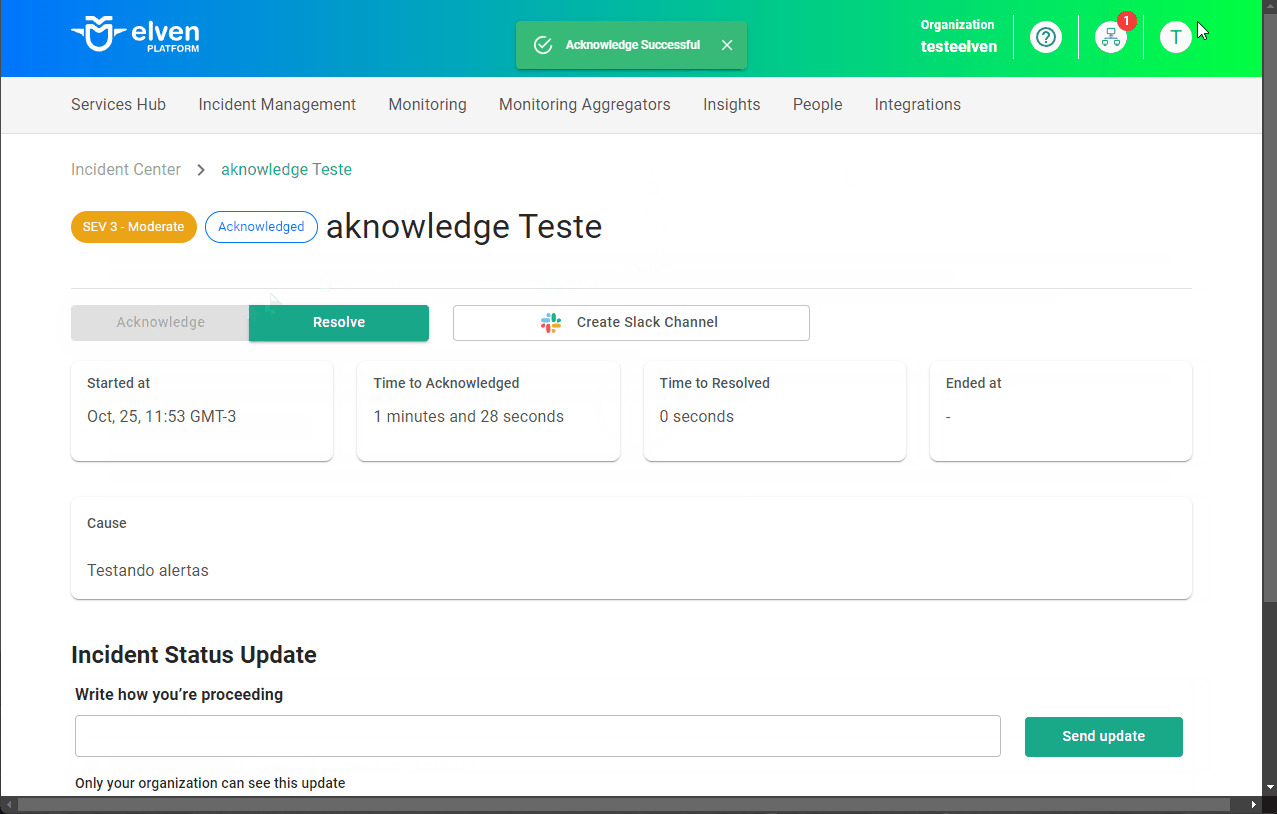
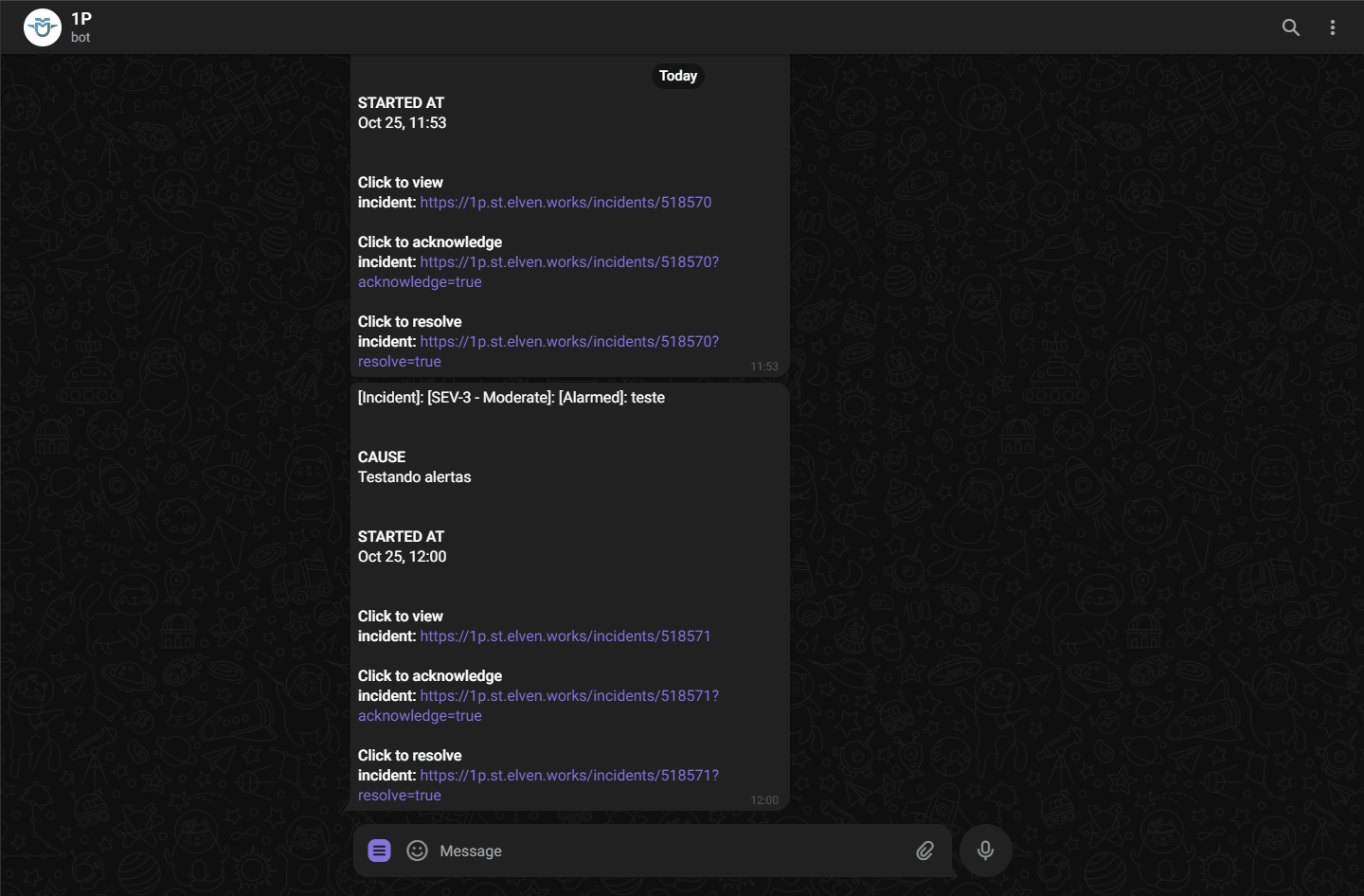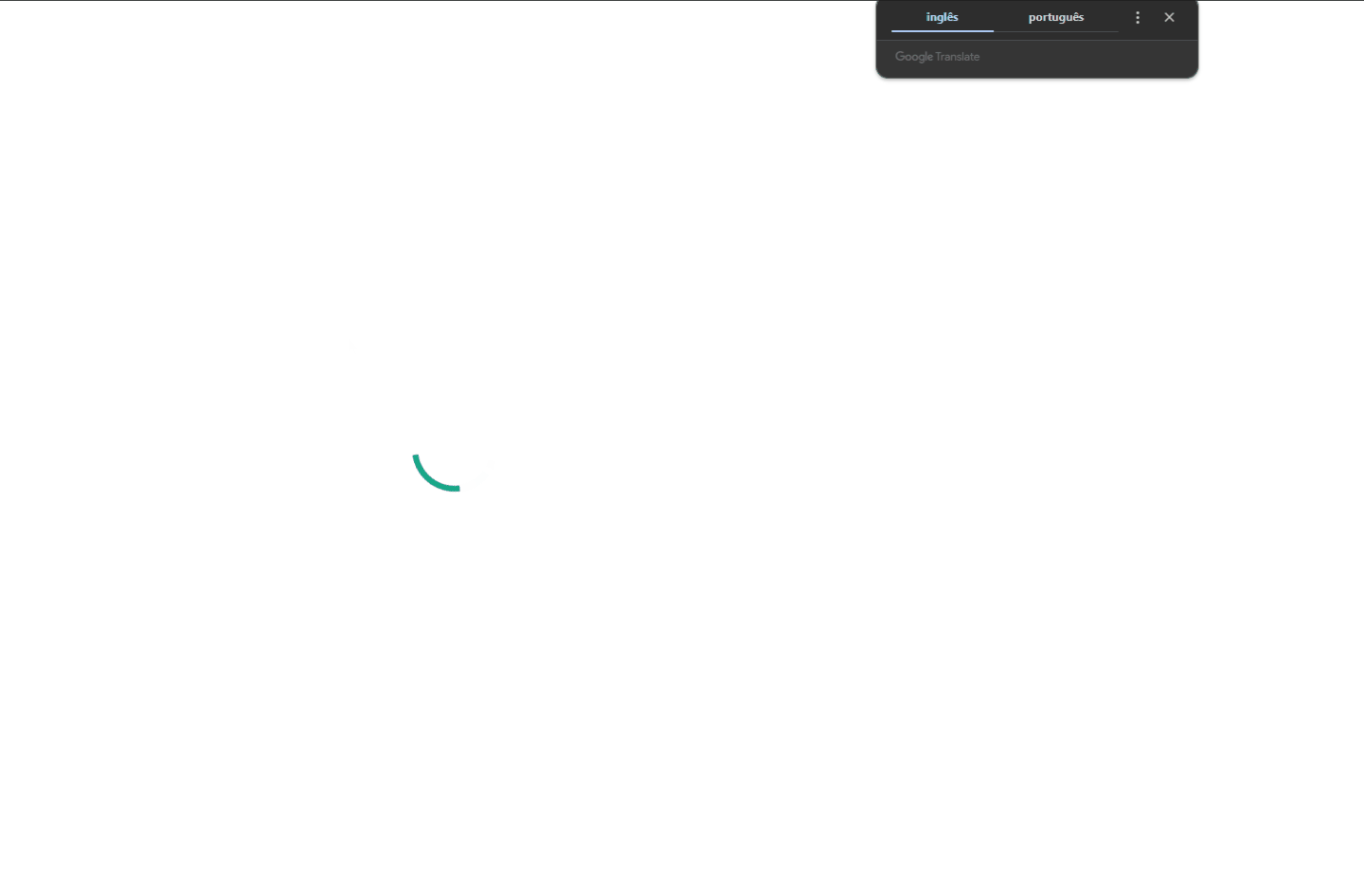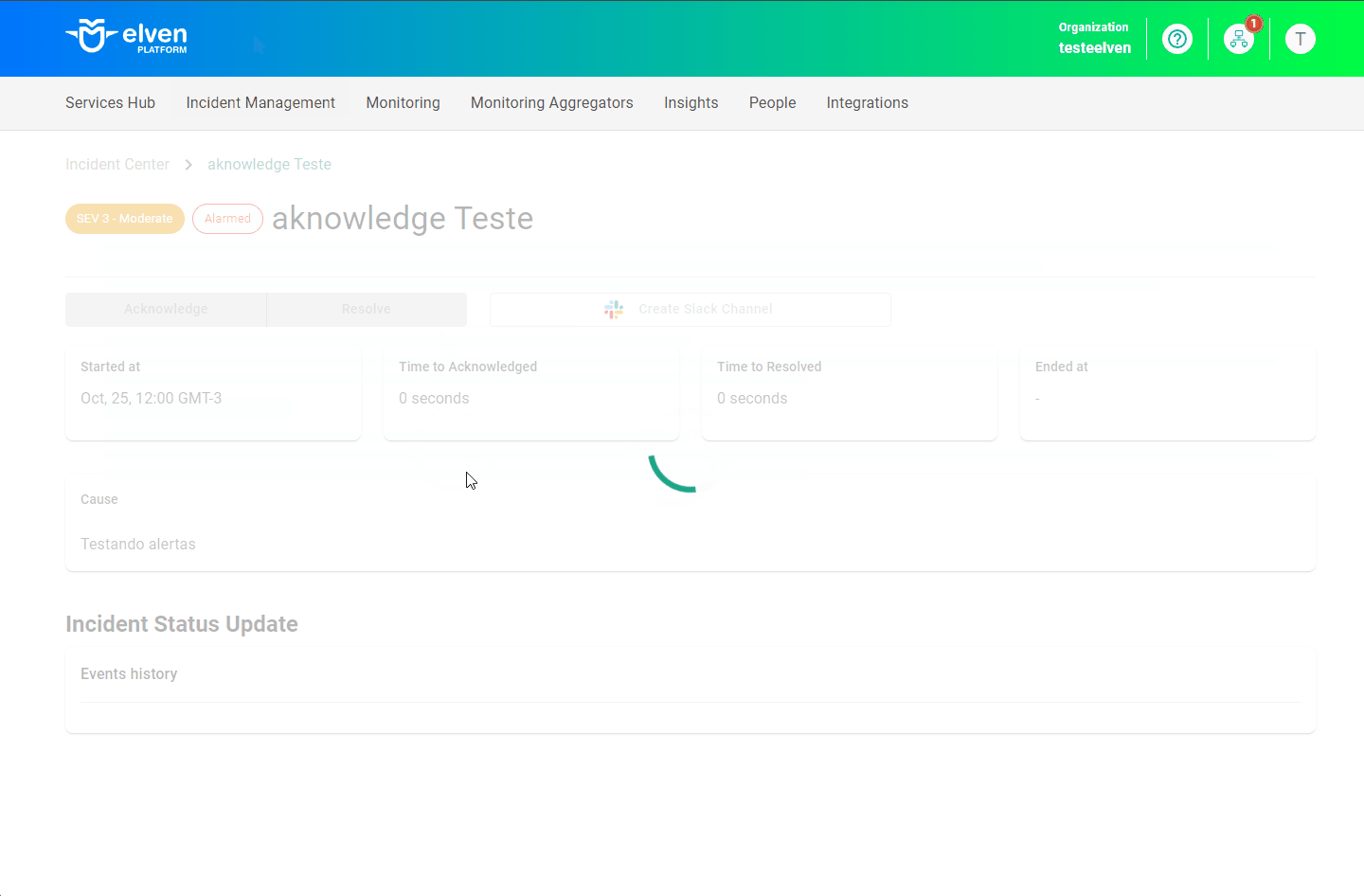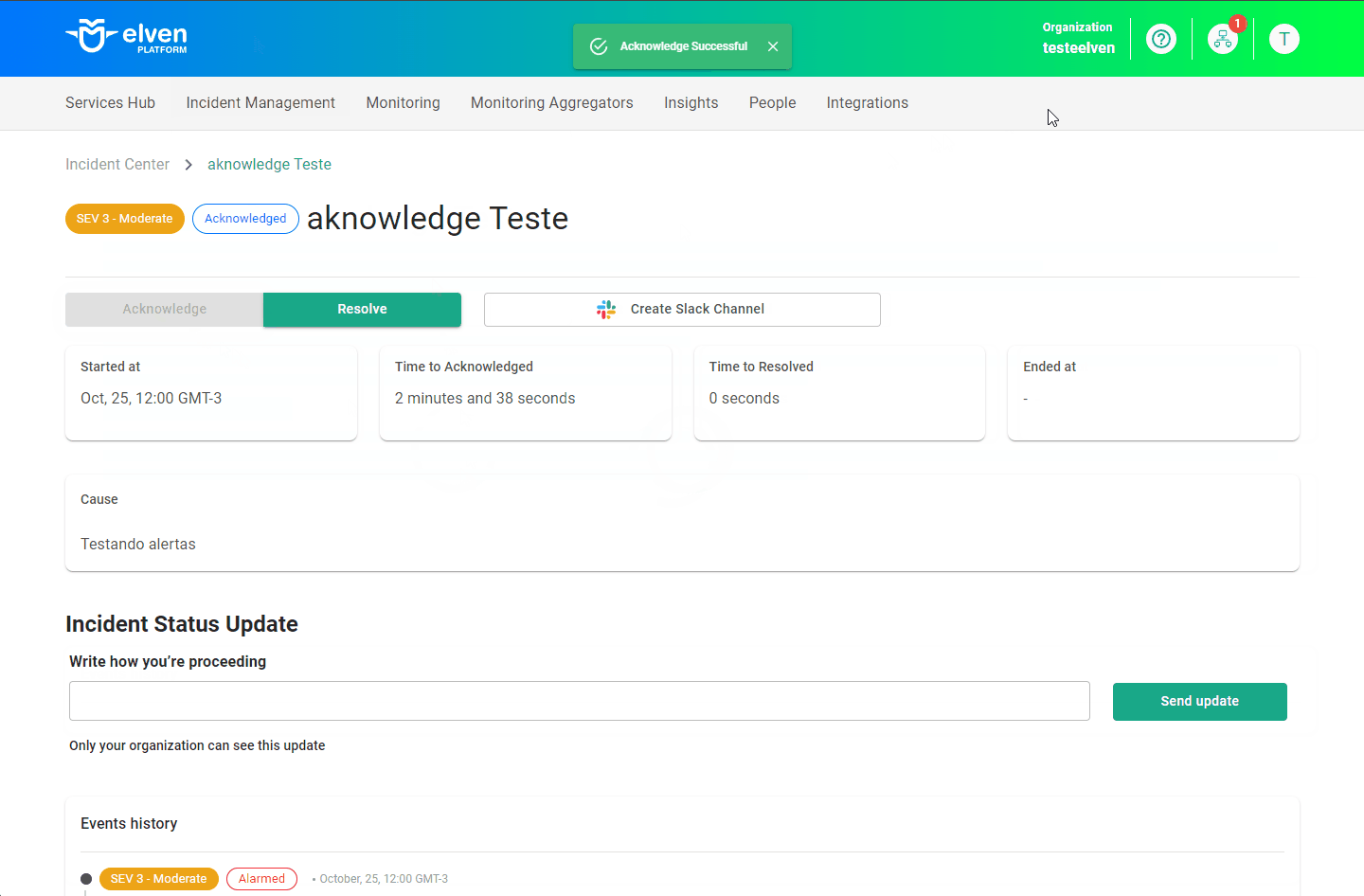
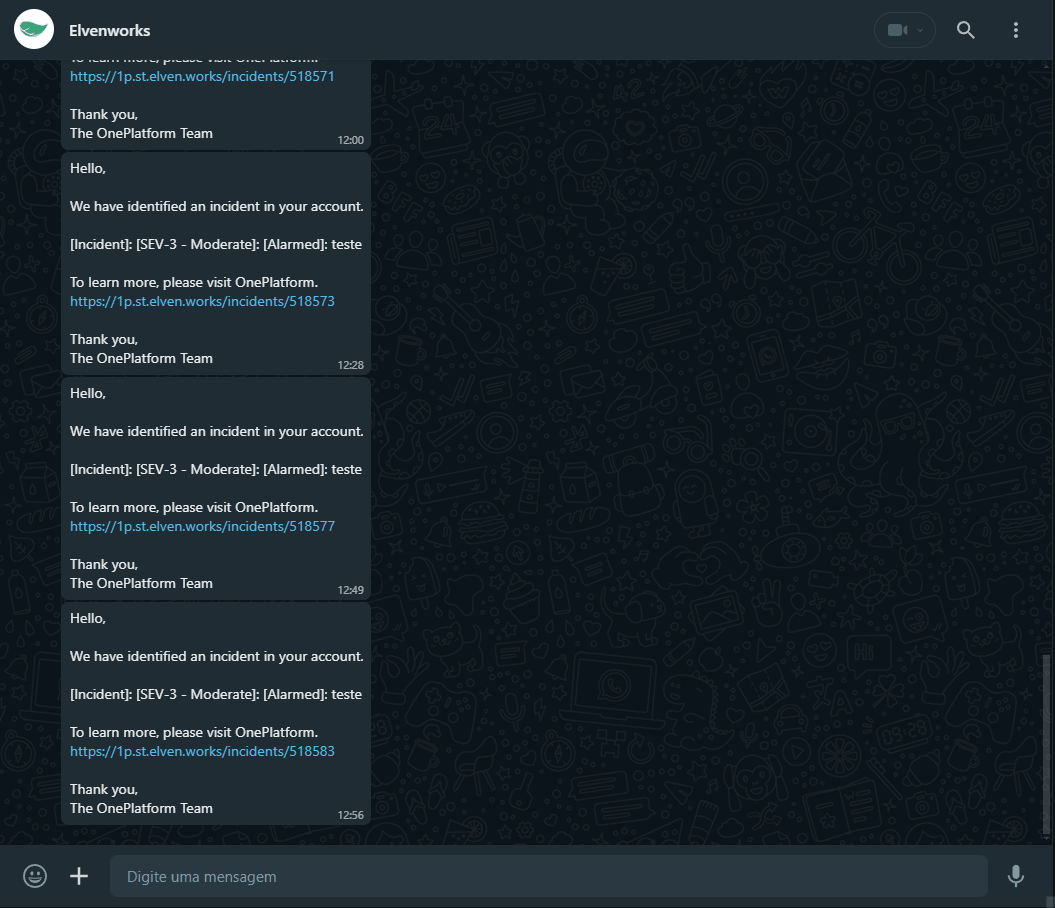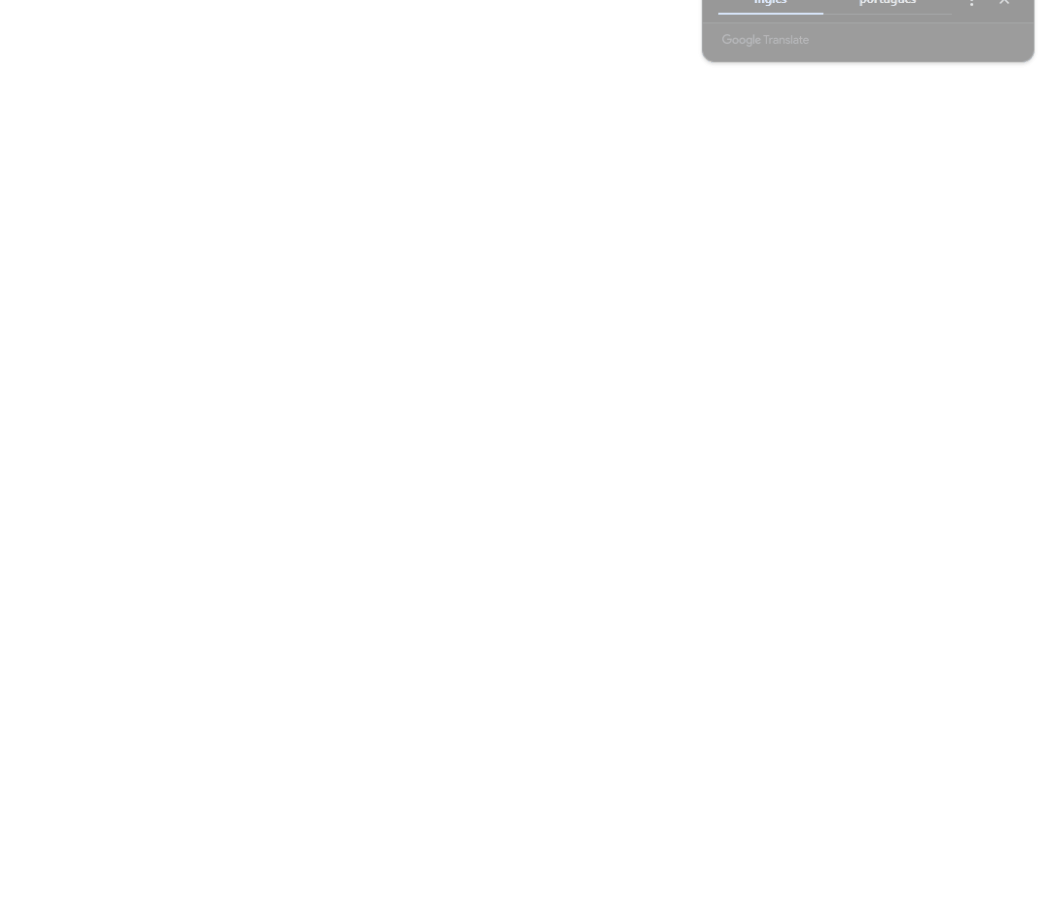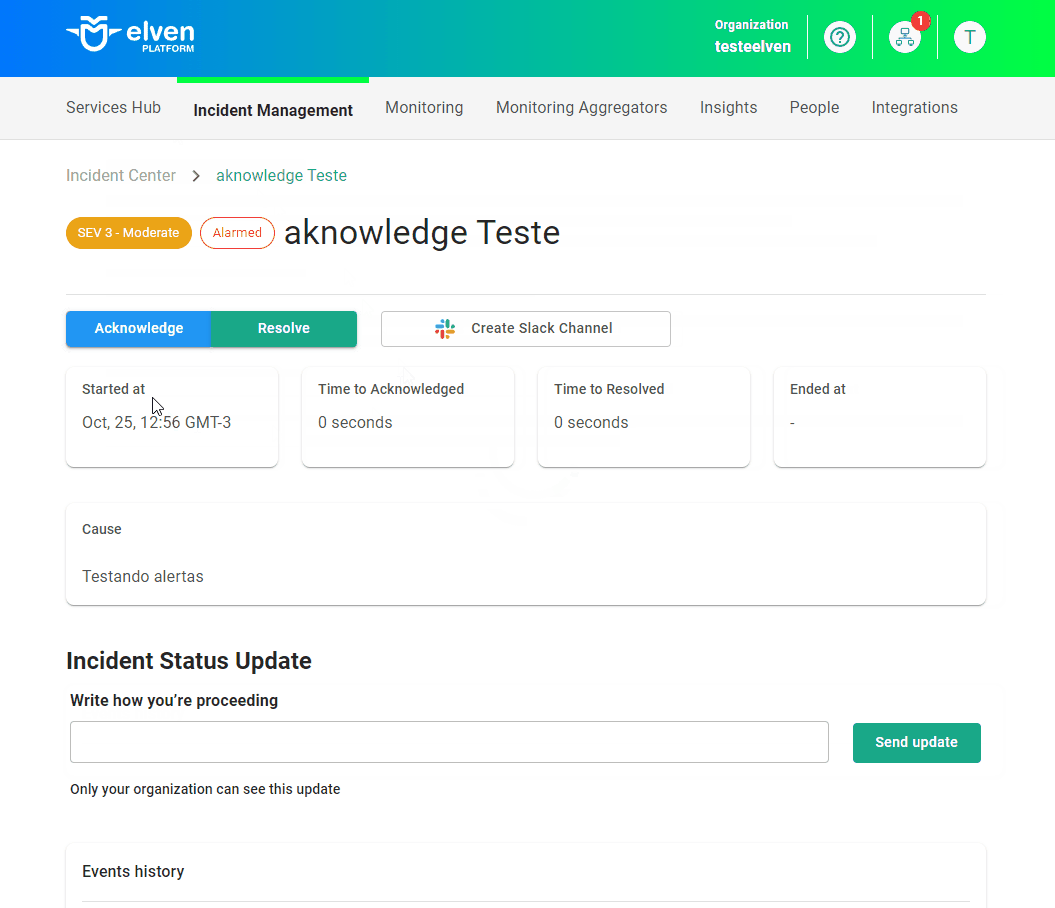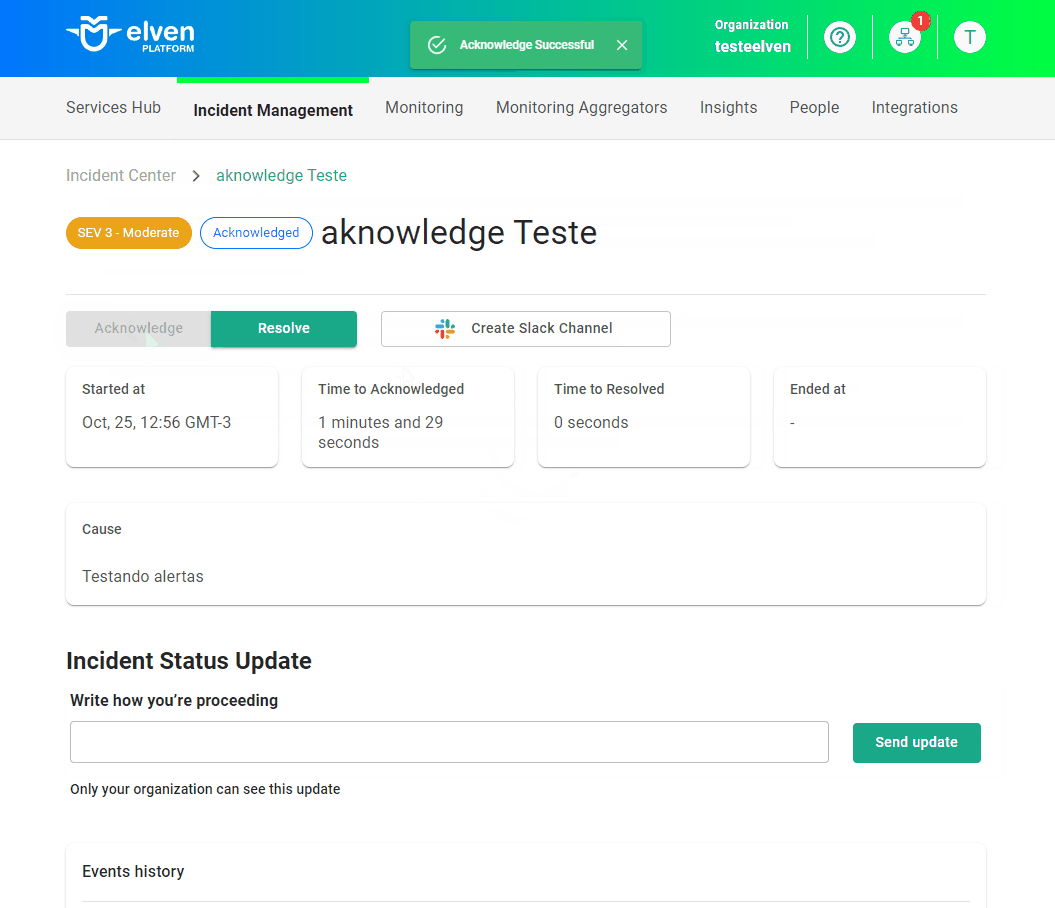
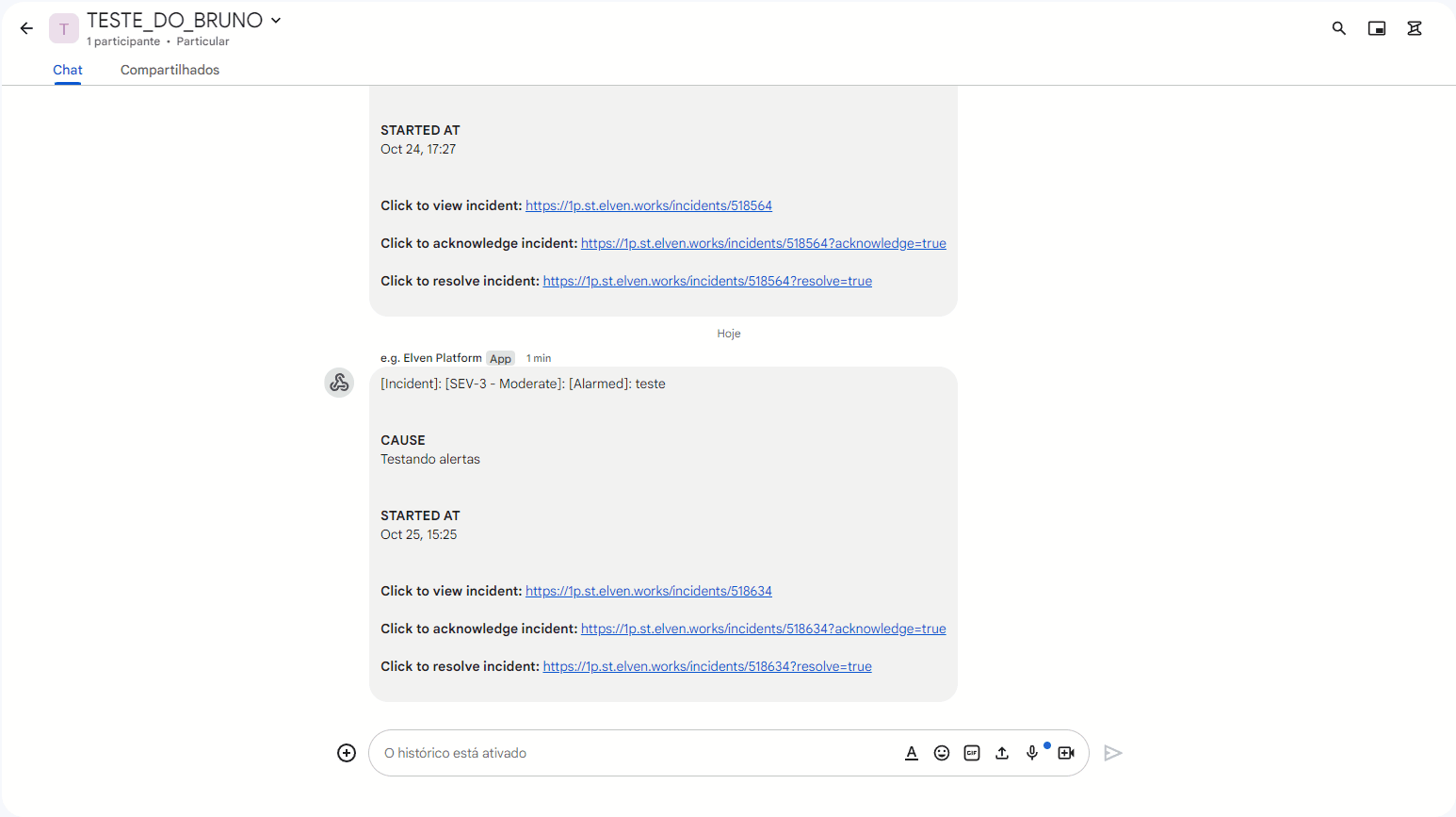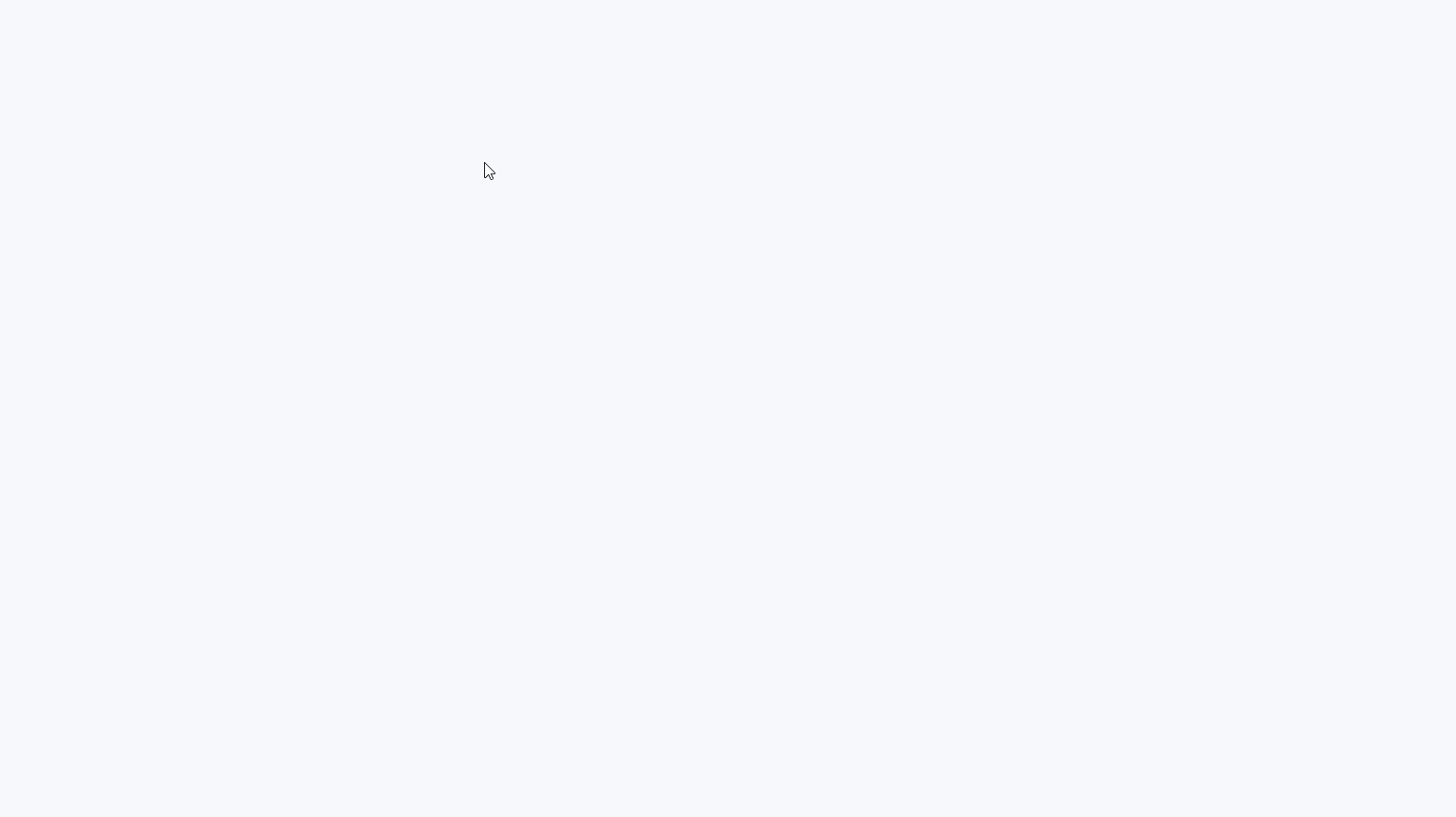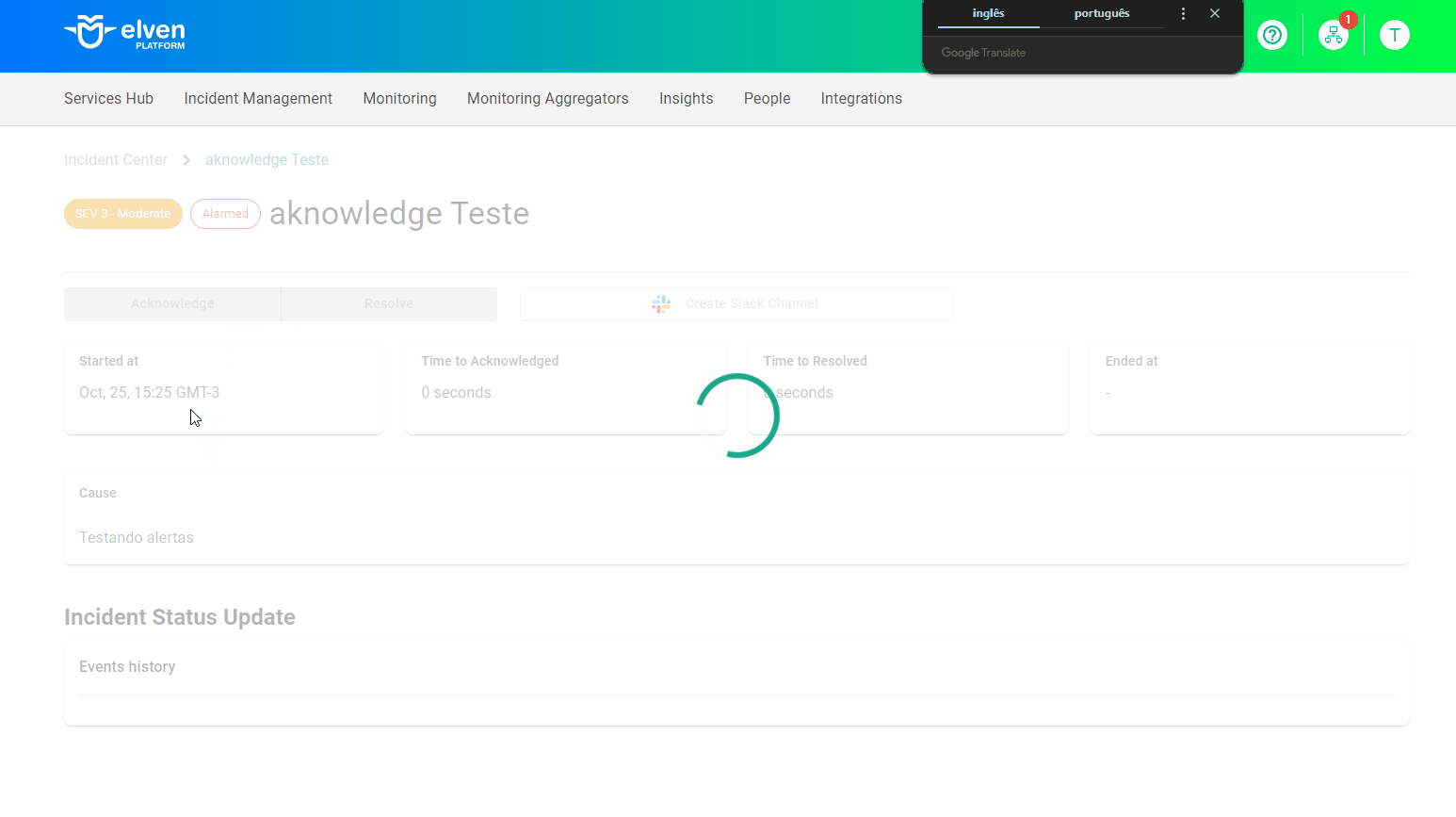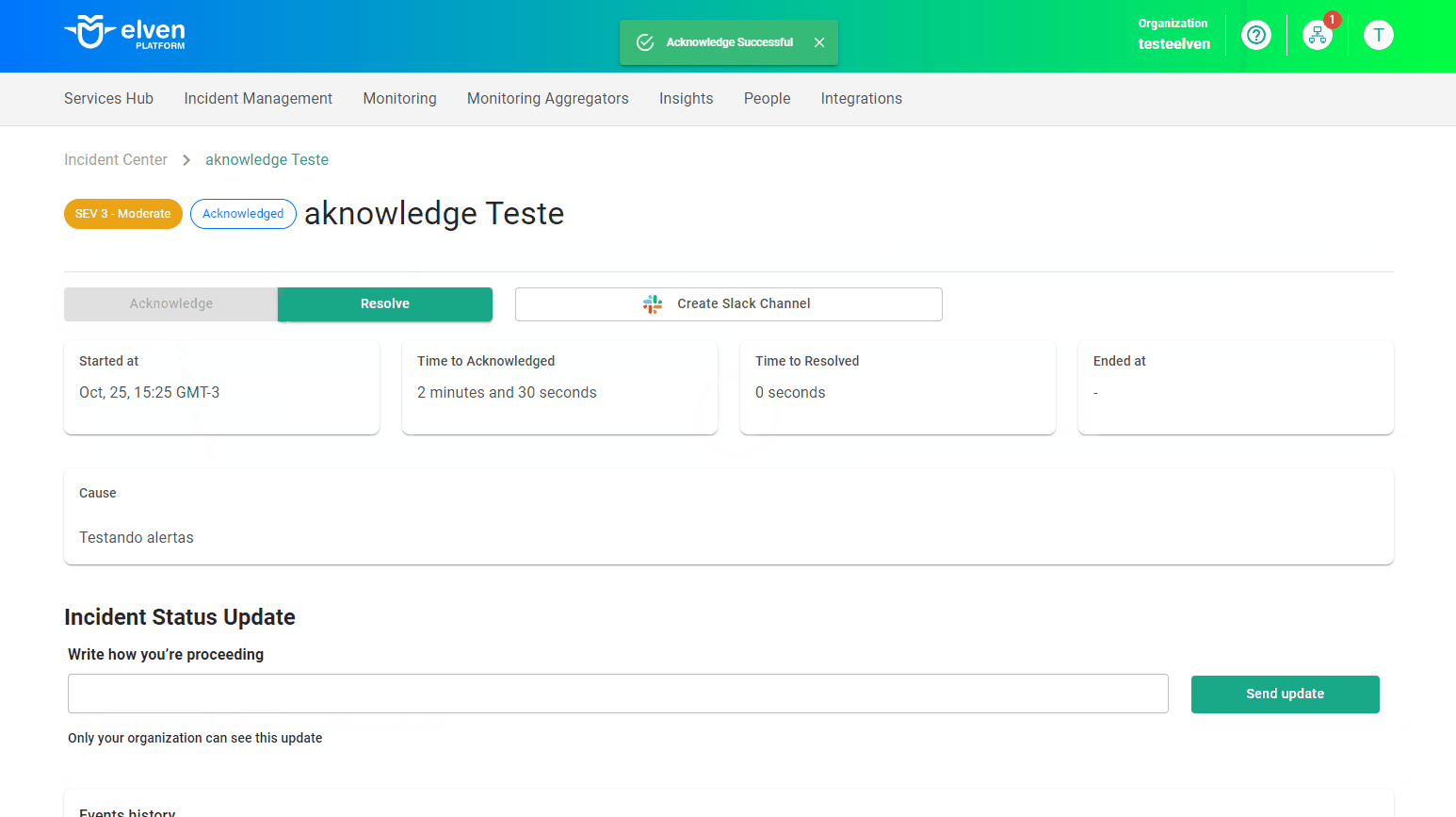
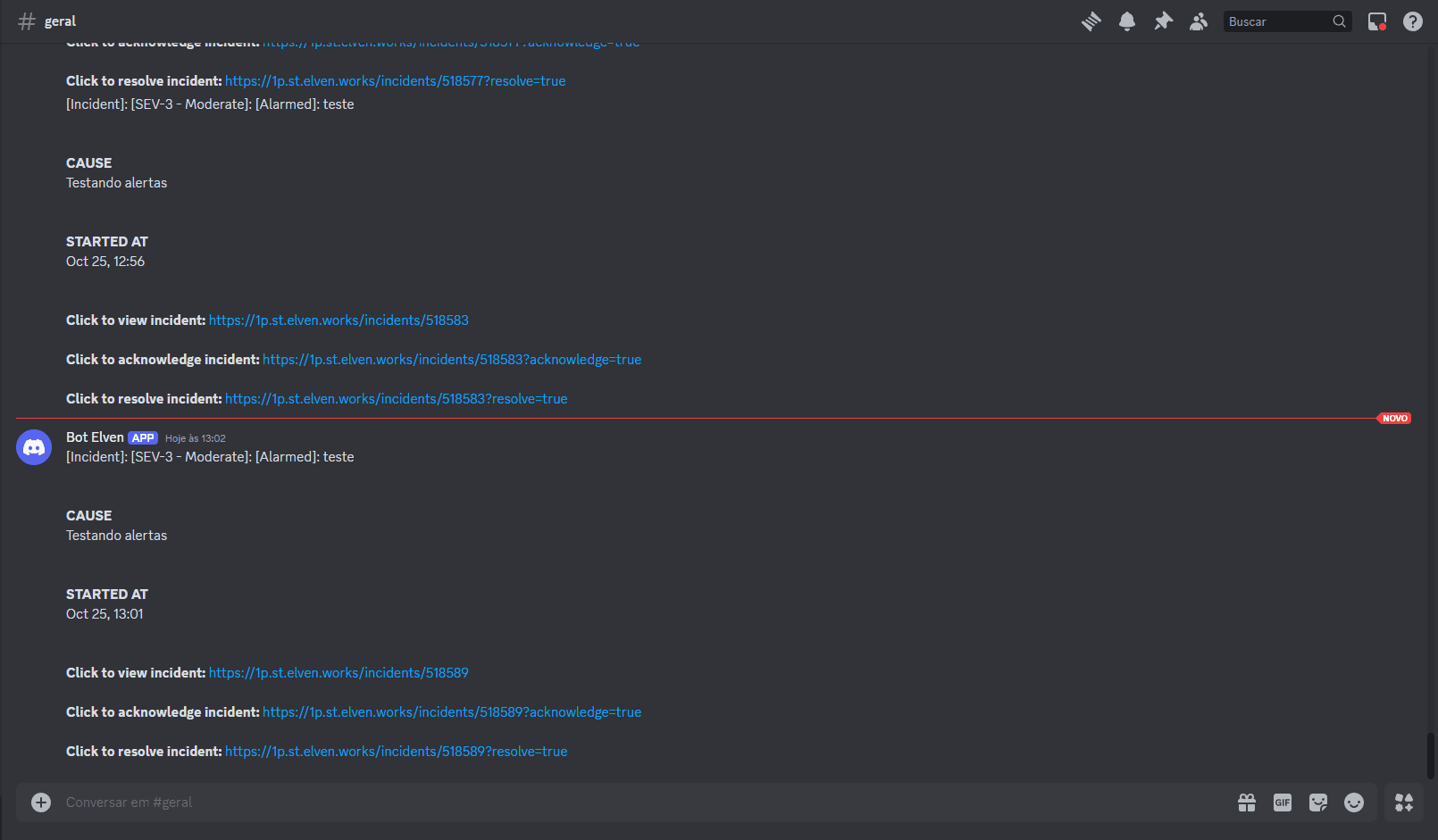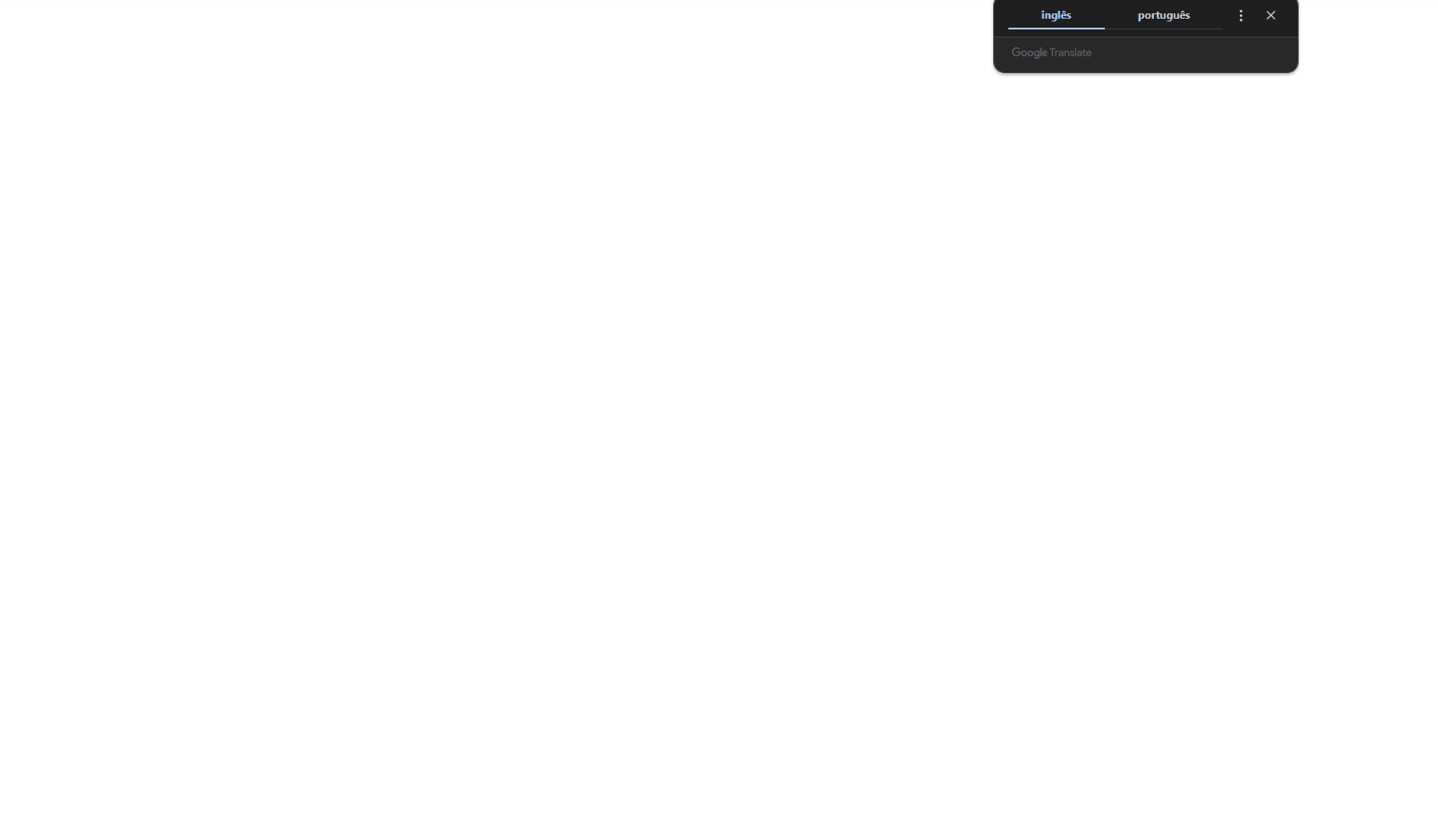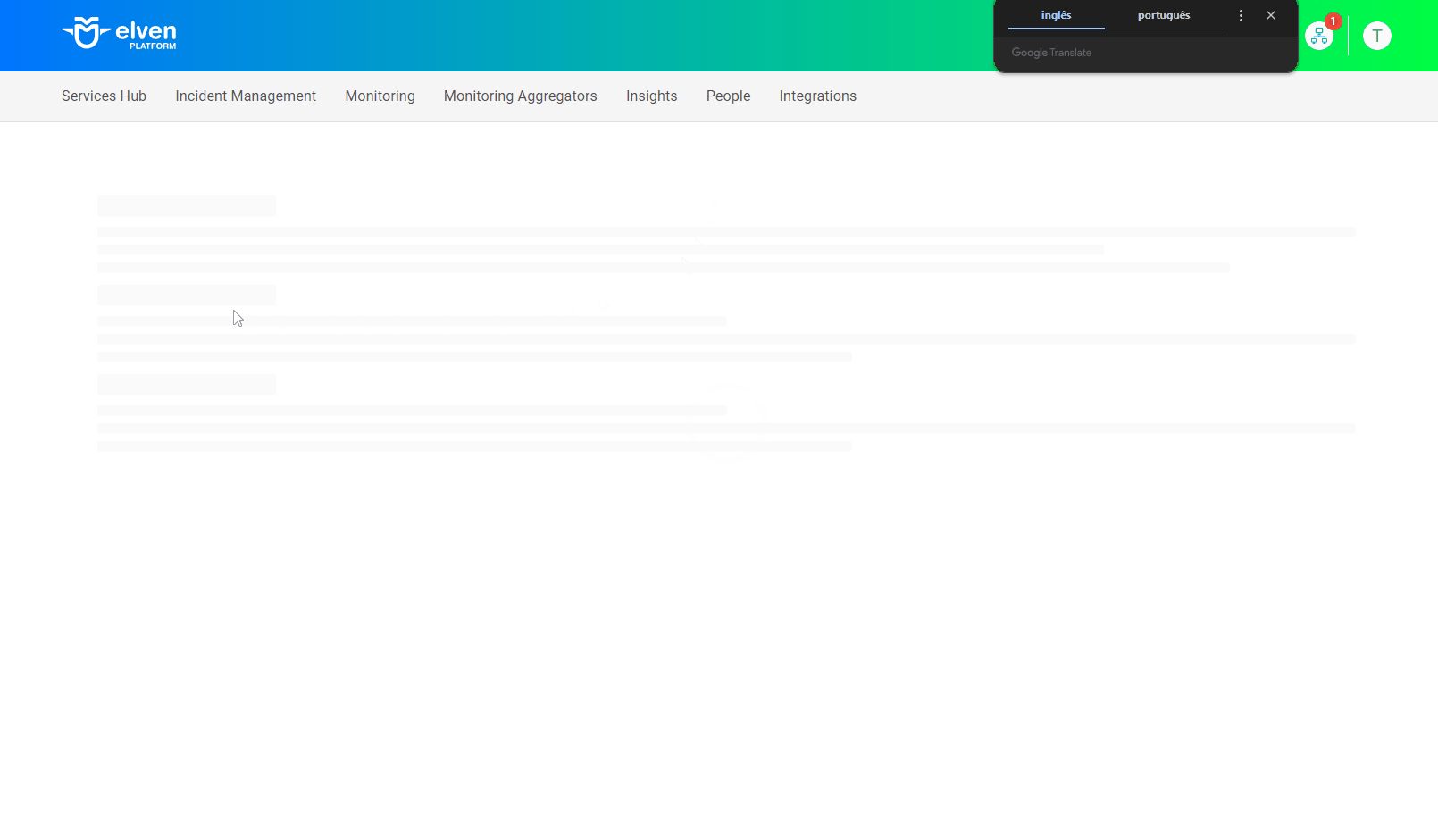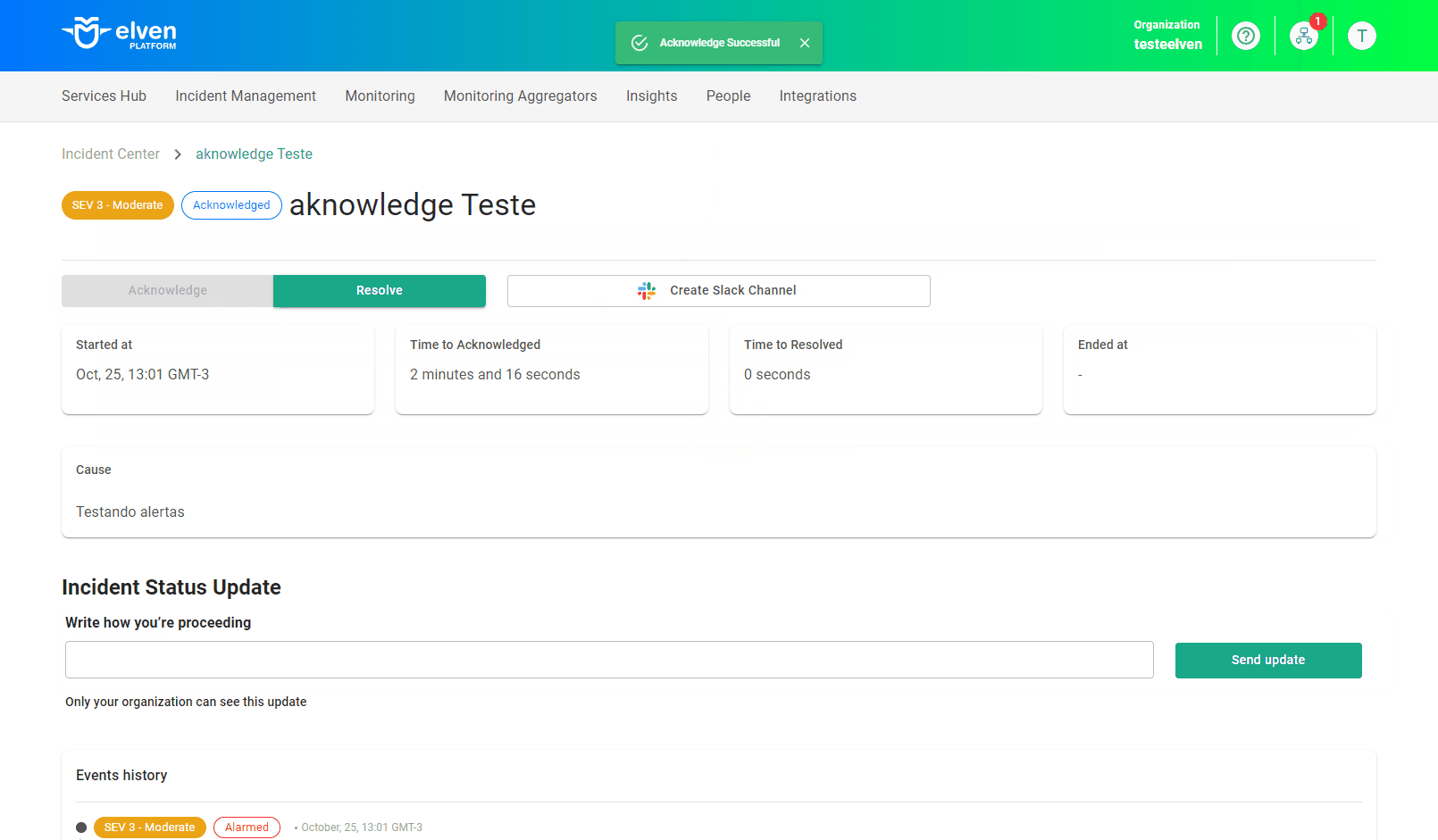
- Aplicacao test usando auto-instrumentação JAVA
https://opentelemetry.io/docs/kubernetes/operator/automatic/
 na linha do usuário que deseja editar.
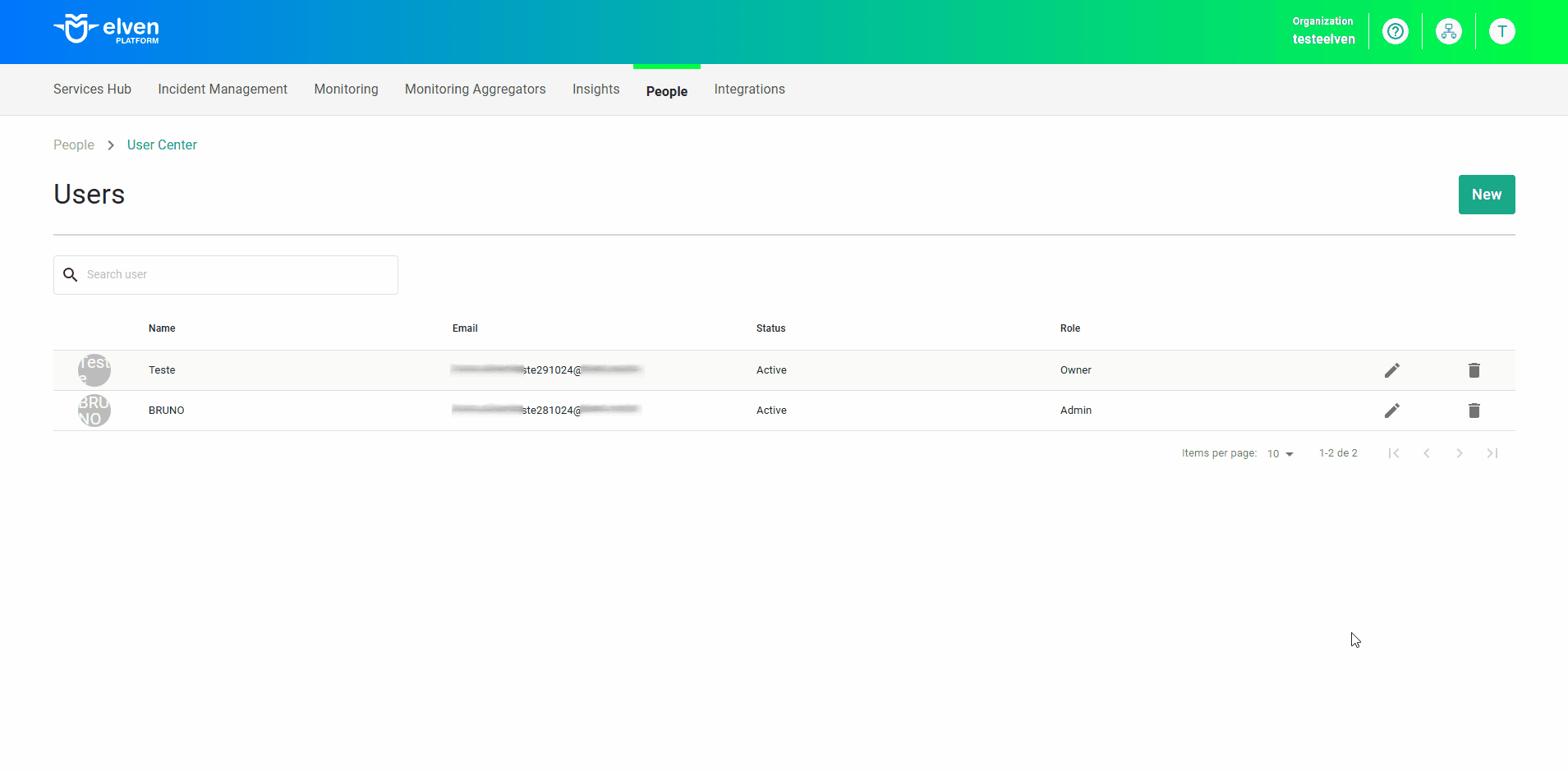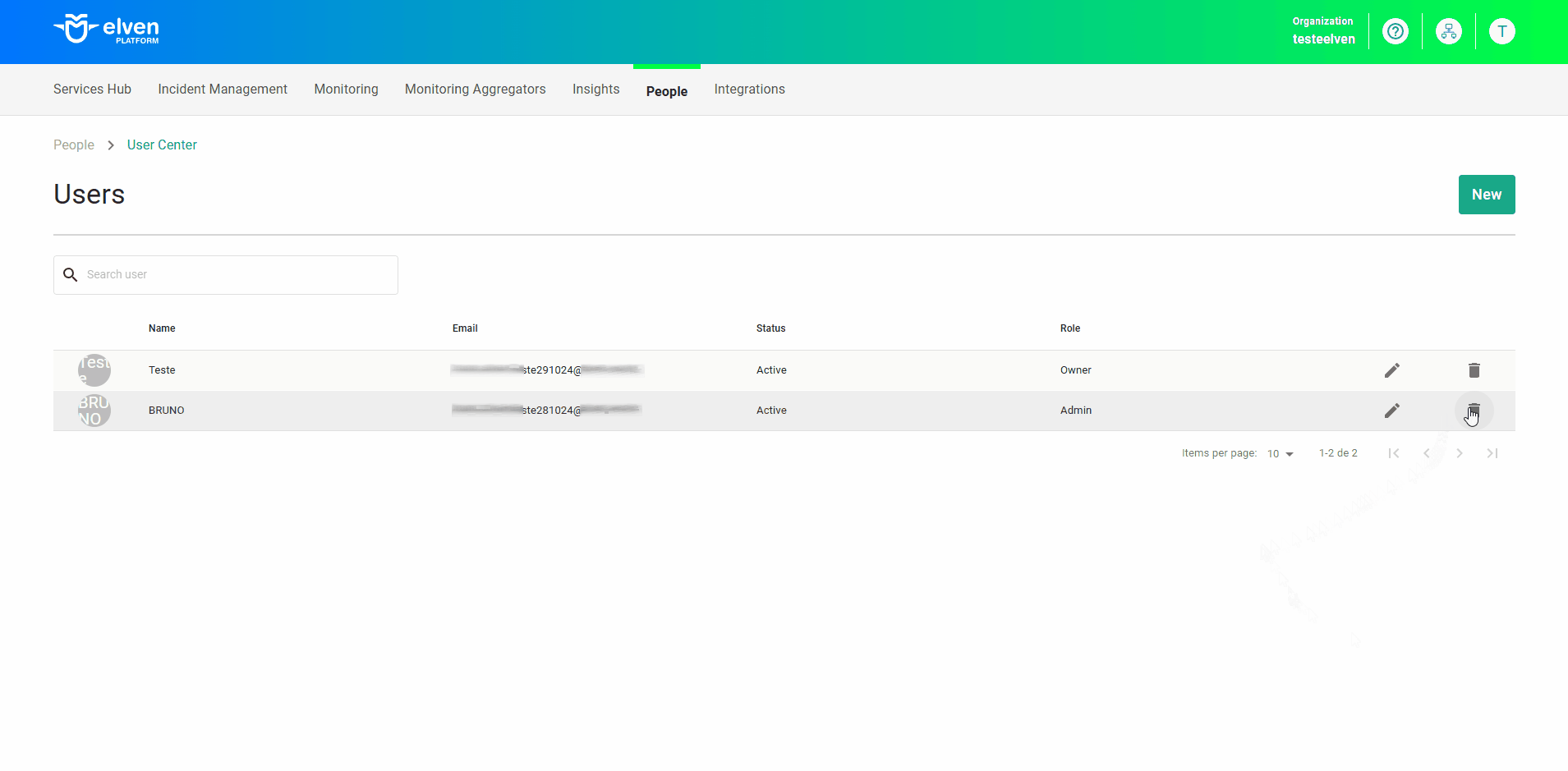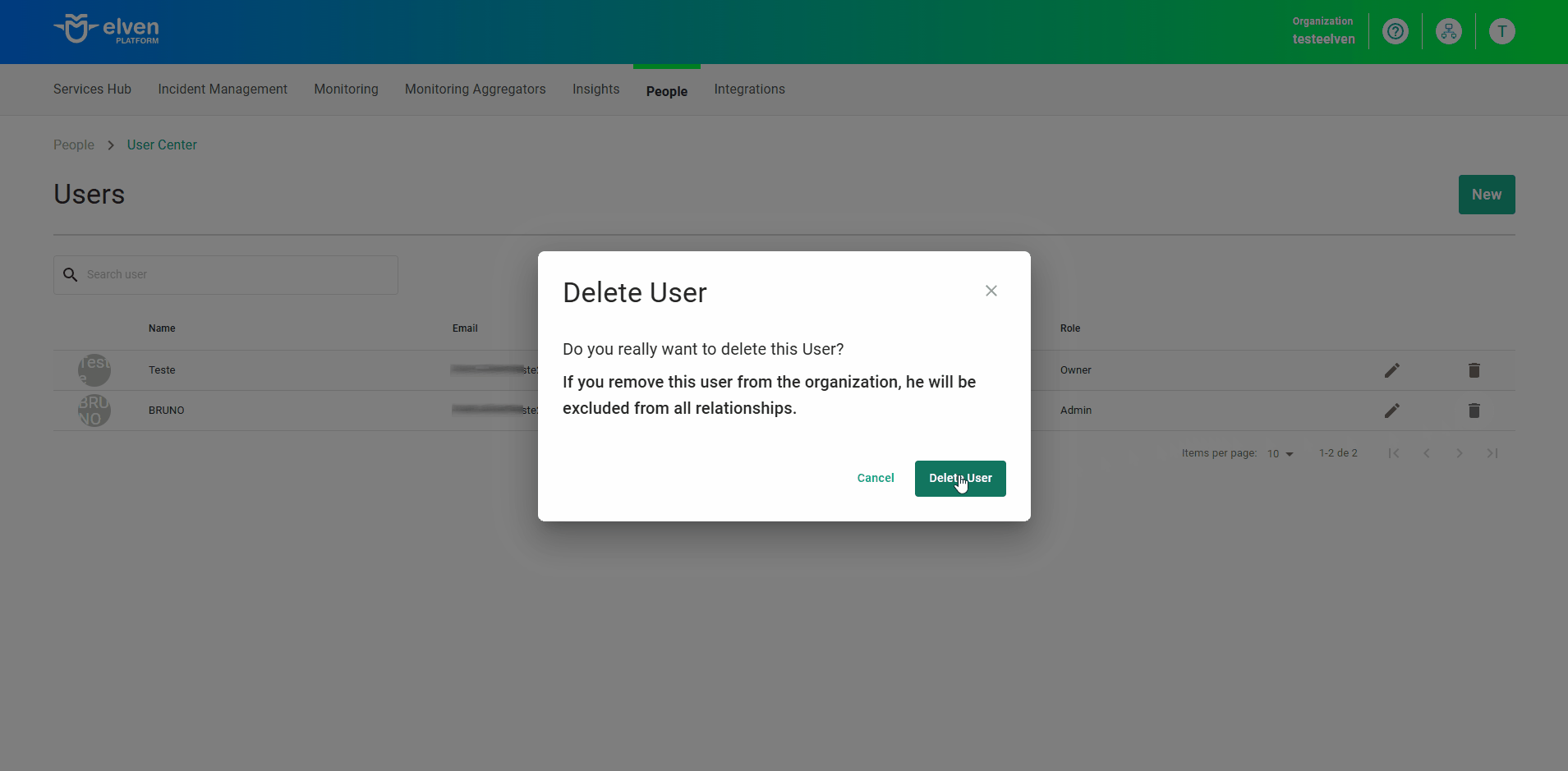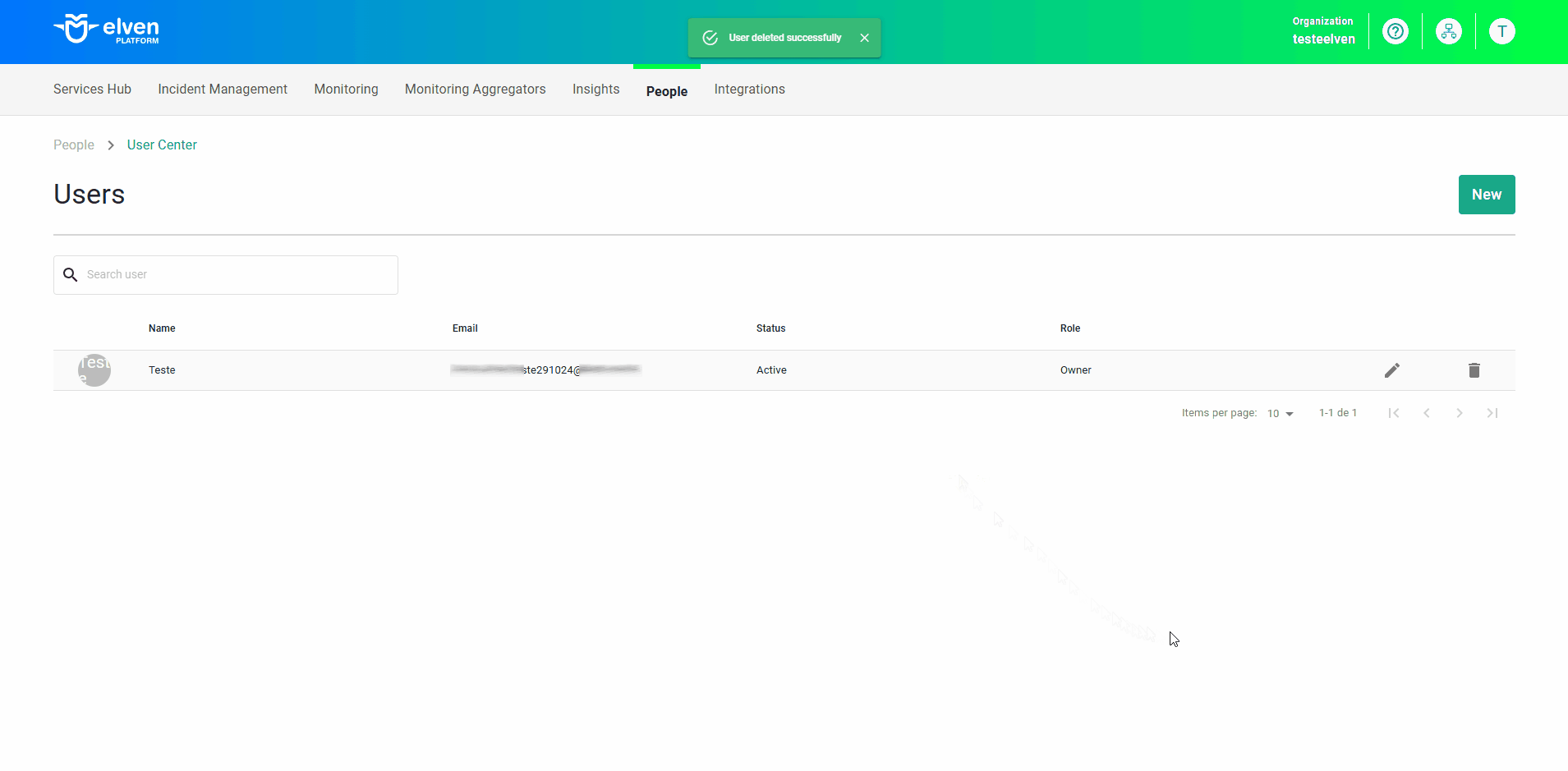
na linha do usuário que deseja editar.